(Spark+Hadoop+DeepSeek-R1)基于Spark+Hadoop农作物大数据分析可视化预测系统(完整系统源码+数据库+开发笔记+详细部署教程+虚拟机分布式启动教程)✅
后端:Django大数据处理框架:数据存储:MySQL编程语言:Python自然语言处理:随机森林算法数据可视化:Echarts数据采集:Requests爬虫。
目录
源码获取方式在文章末尾
一、项目背景
随着农业信息化和智能化的发展,大数据技术在农业生产中的应用日益广泛。传统农业依赖经验和局部数据,难以应对气候变化、病虫害爆发等复杂问题,导致资源浪费和产量不稳定。基于Spark和Hadoop的农作物大数据分析可视化预测系统,旨在整合海量农业数据(如气象数据、土壤数据、作物生长周期、历史产量等),通过分布式计算框架高效处理和分析数据,挖掘潜在规律,为农业生产提供科学决策支持。
该系统利用Hadoop的分布式存储能力管理多源异构数据,结合Spark的高效计算引擎实现实时或离线分析,并通过机器学习模型(随机森林、LSTM)预测作物产量、病虫害风险及最佳种植方案。可视化模块以图表、热力图等形式直观展示分析结果,帮助农业从业者快速理解数据趋势,优化灌溉、施肥和病虫害防治策略。
二、项目意义
项目旨在通过技术创新或模式优化解决特定领域的关键问题,填补市场空白或提升现有解决方案的效率。例如,在环保领域,开发新型可再生能源技术可减少对传统化石燃料的依赖,降低碳排放,推动可持续发展;在教育领域,数字化学习平台的构建能打破地域限制,让优质教育资源惠及更广泛人群。项目的实施不仅能带来直接的经济效益,还能产生显著的社会价值,推动行业进步。
三、项目创新点
技术突破与差异化
采用AI驱动的动态优化算法,结合边缘计算技术,实现传统方案的响应速度提升40%以上。通过自主研发的轻量化模型,在低功耗设备上完成高精度实时分析,填补了行业在嵌入式场景的应用空白。
多场景协同创新
设计模块化架构,支持工业、医疗、农业等领域的快速适配。引入跨行业数据融合机制,打破单一场景限制,首次实现同一平台下多行业需求的并行处理能力。
商业模式革新
构建"技术+服务"双轮驱动体系,通过SaaS化部署降低用户使用门槛。创新性提出按效果付费机制,将技术价值直接与客户收益挂钩,形成可持续的生态闭环。
四、开发技术介绍
后端:Django
大数据处理框架:Spark /Hadoop/Hive
数据存储:MySQL
编程语言:Python
自然语言处理:随机森林算法
数据可视化:Echarts
数据采集:Requests爬虫
五、项目展示
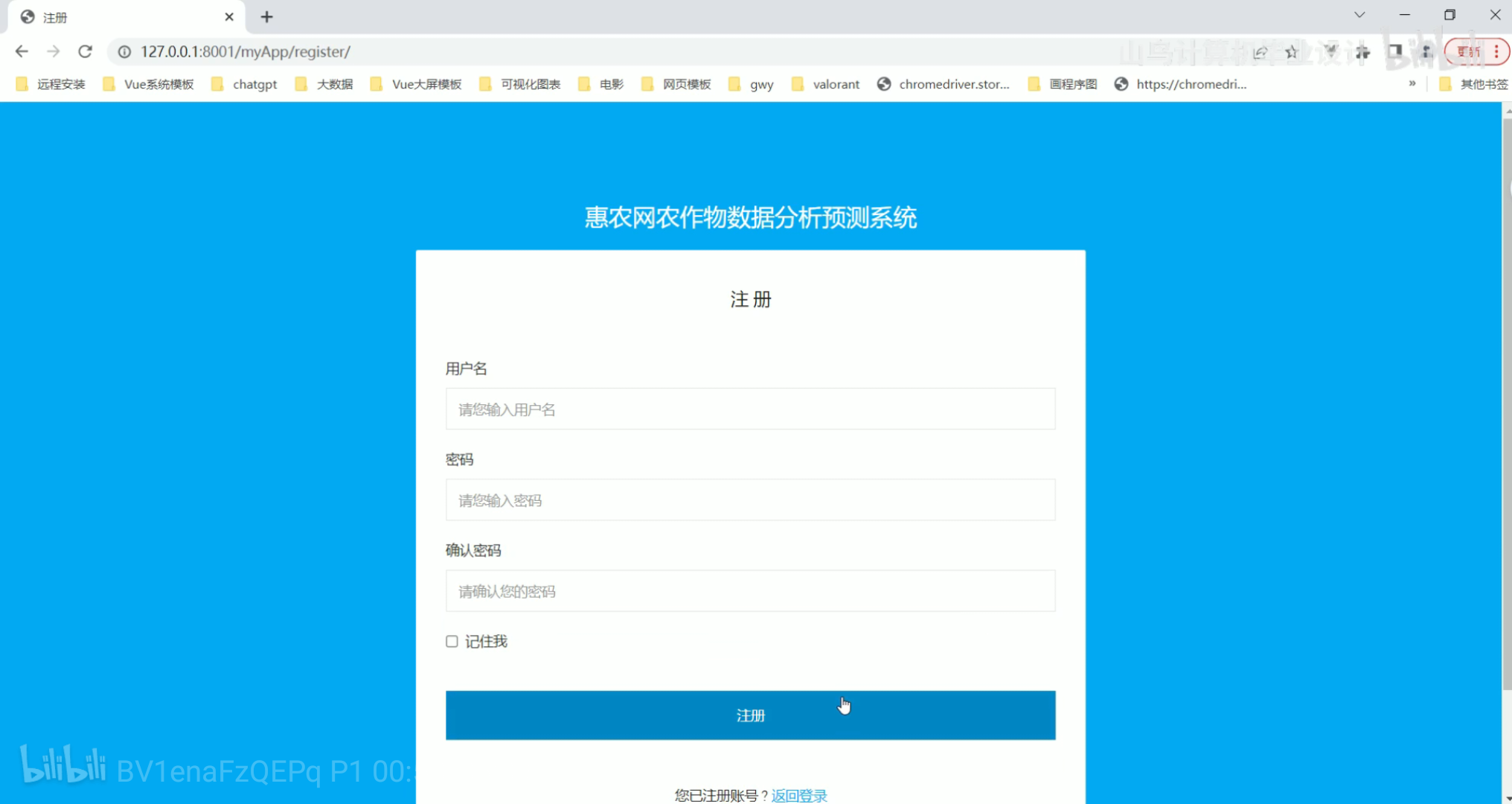
登录注册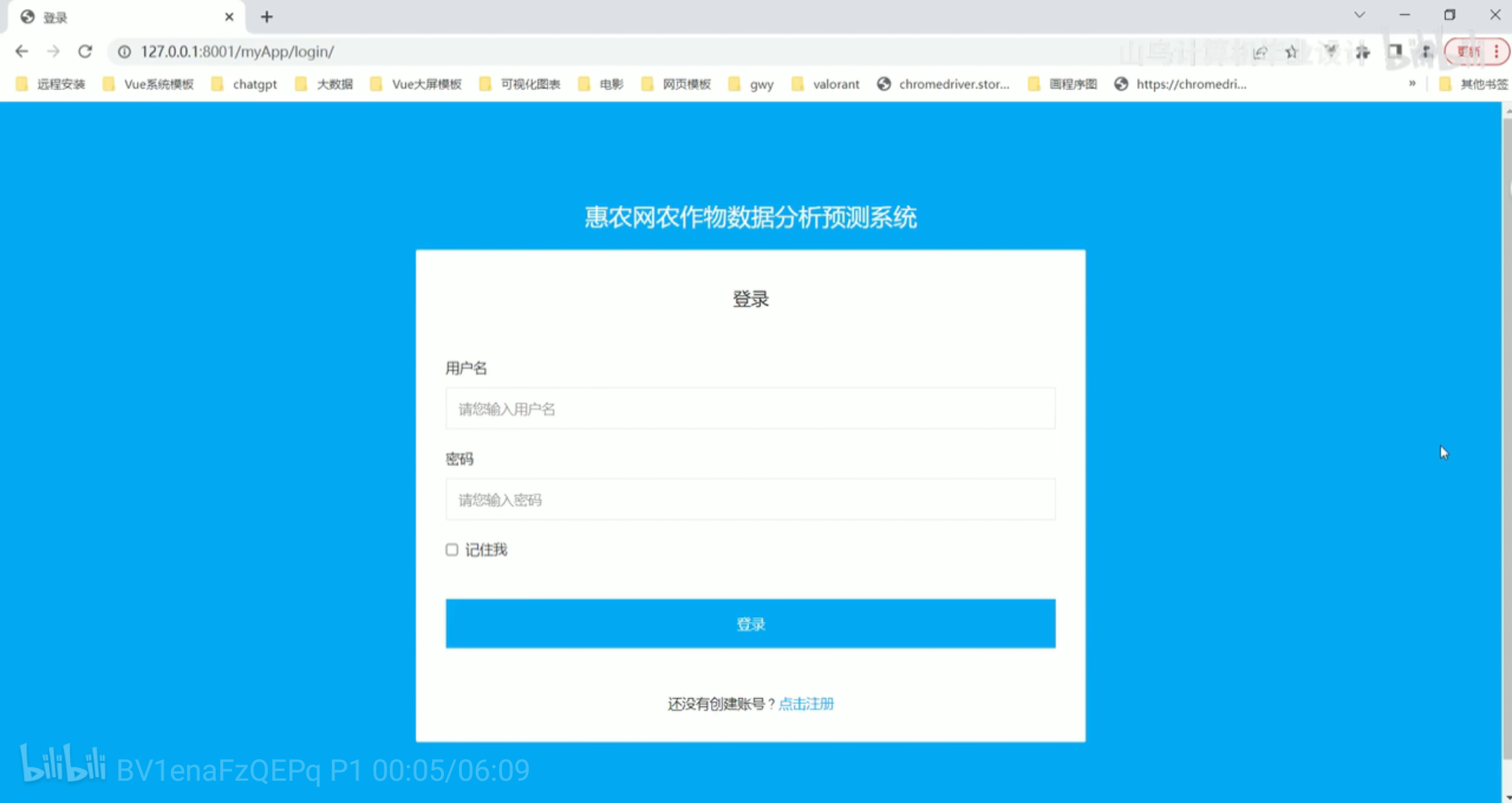
 农作物数据浏览
农作物数据浏览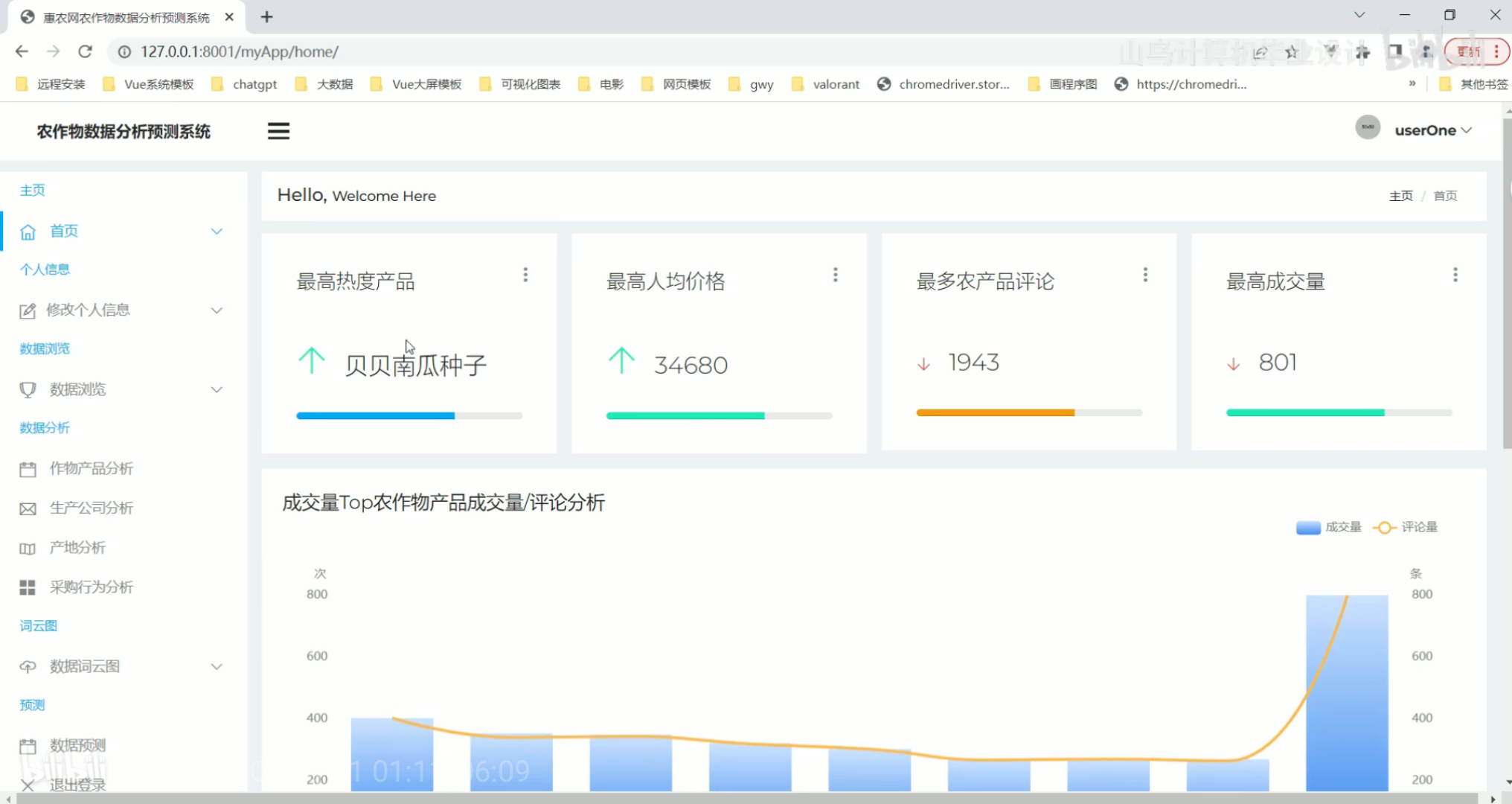
 个人信息修改
个人信息修改 AI小助手回答
AI小助手回答 作物产品分析
作物产品分析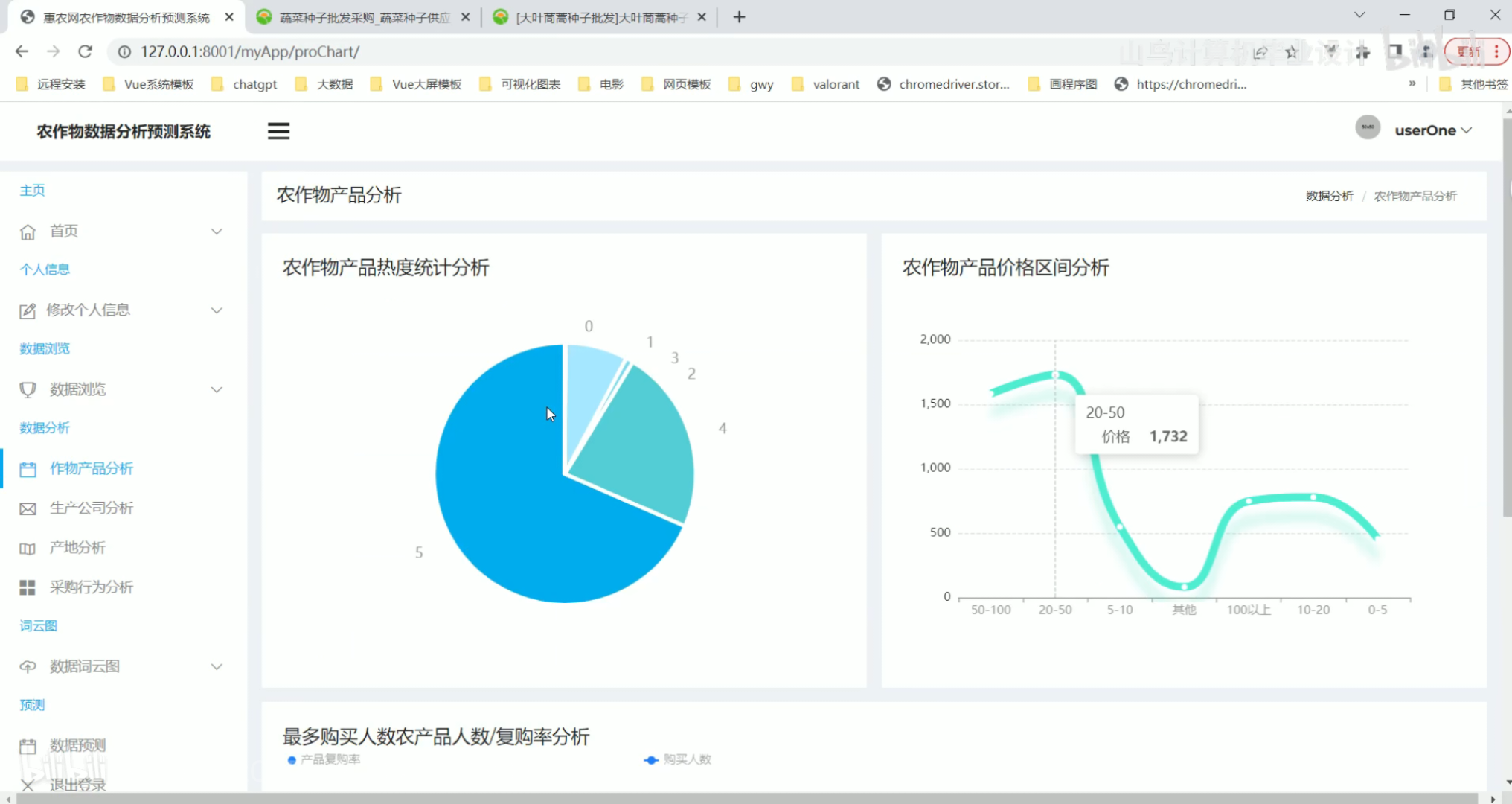
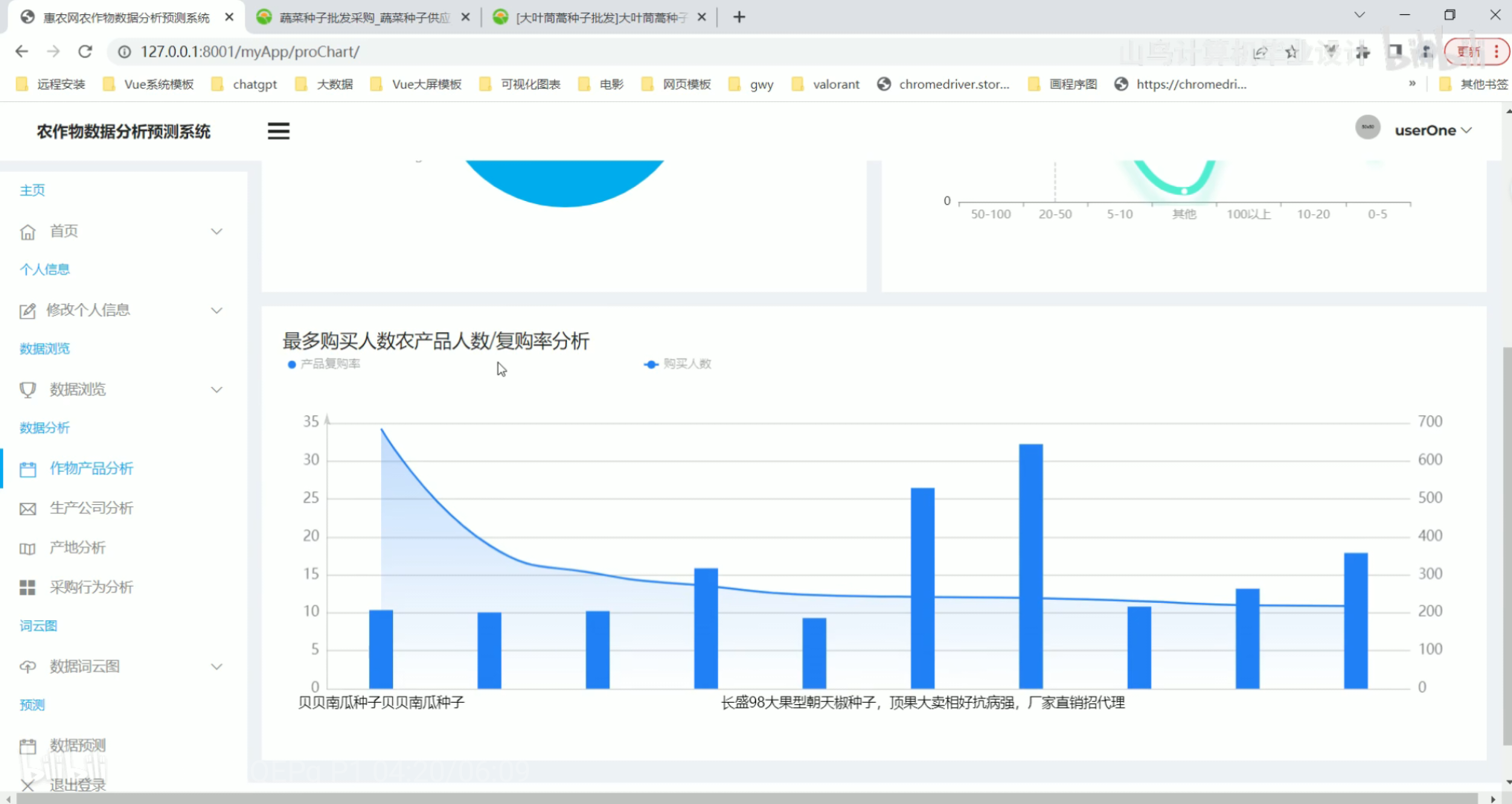 生产公司分析
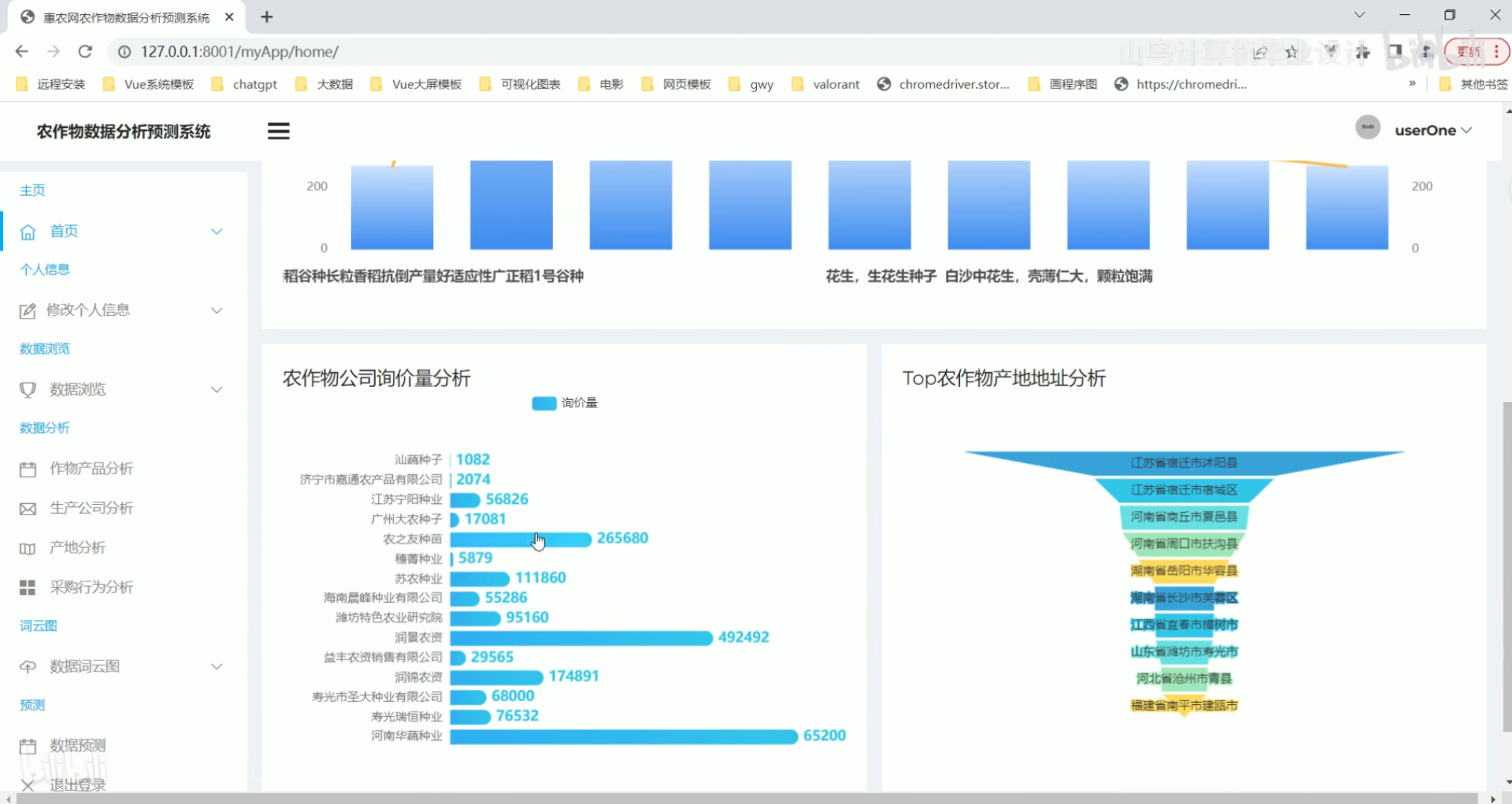
生产公司分析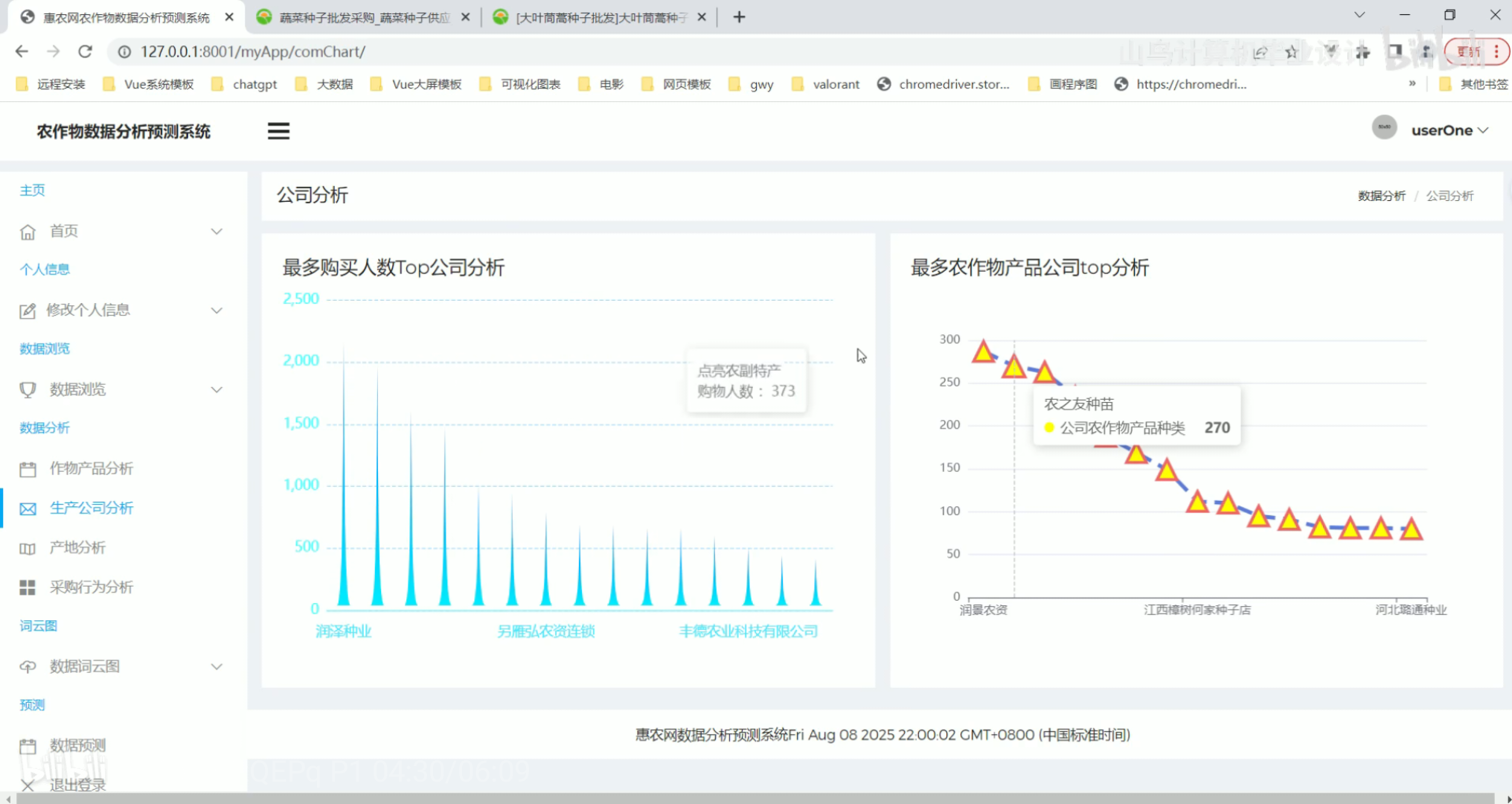 产地分析
产地分析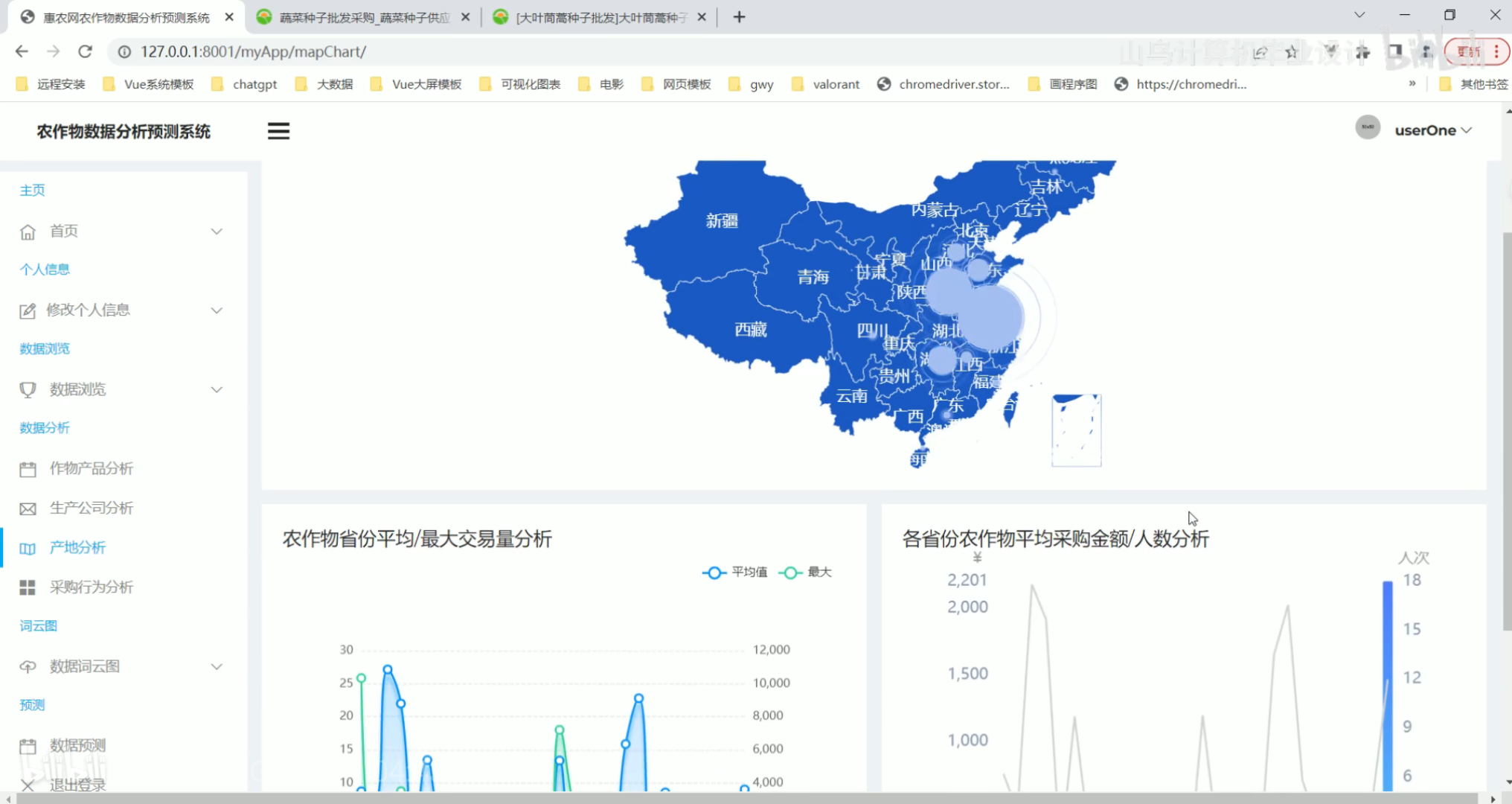 采购行为分析
采购行为分析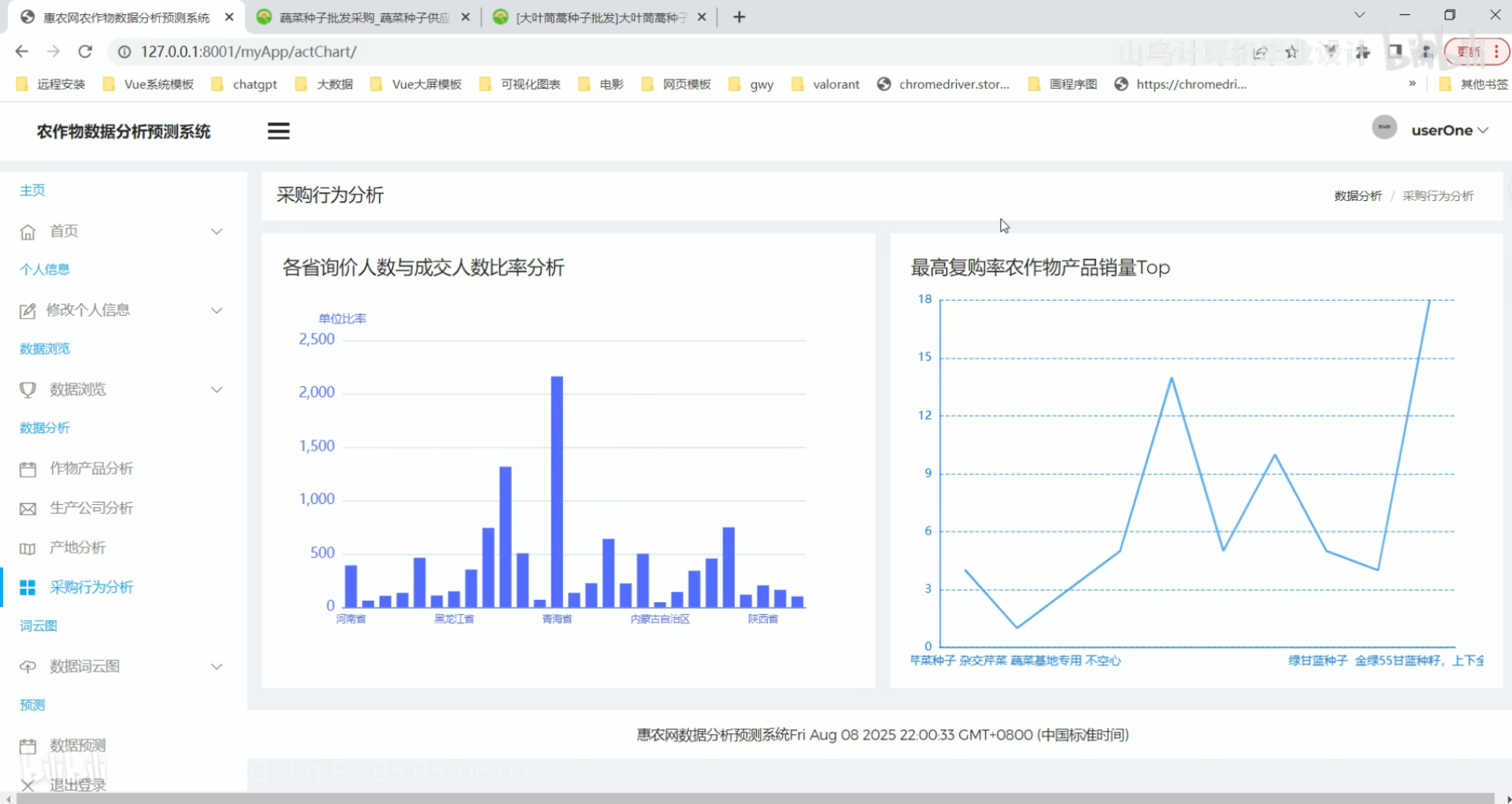 数据词云图
数据词云图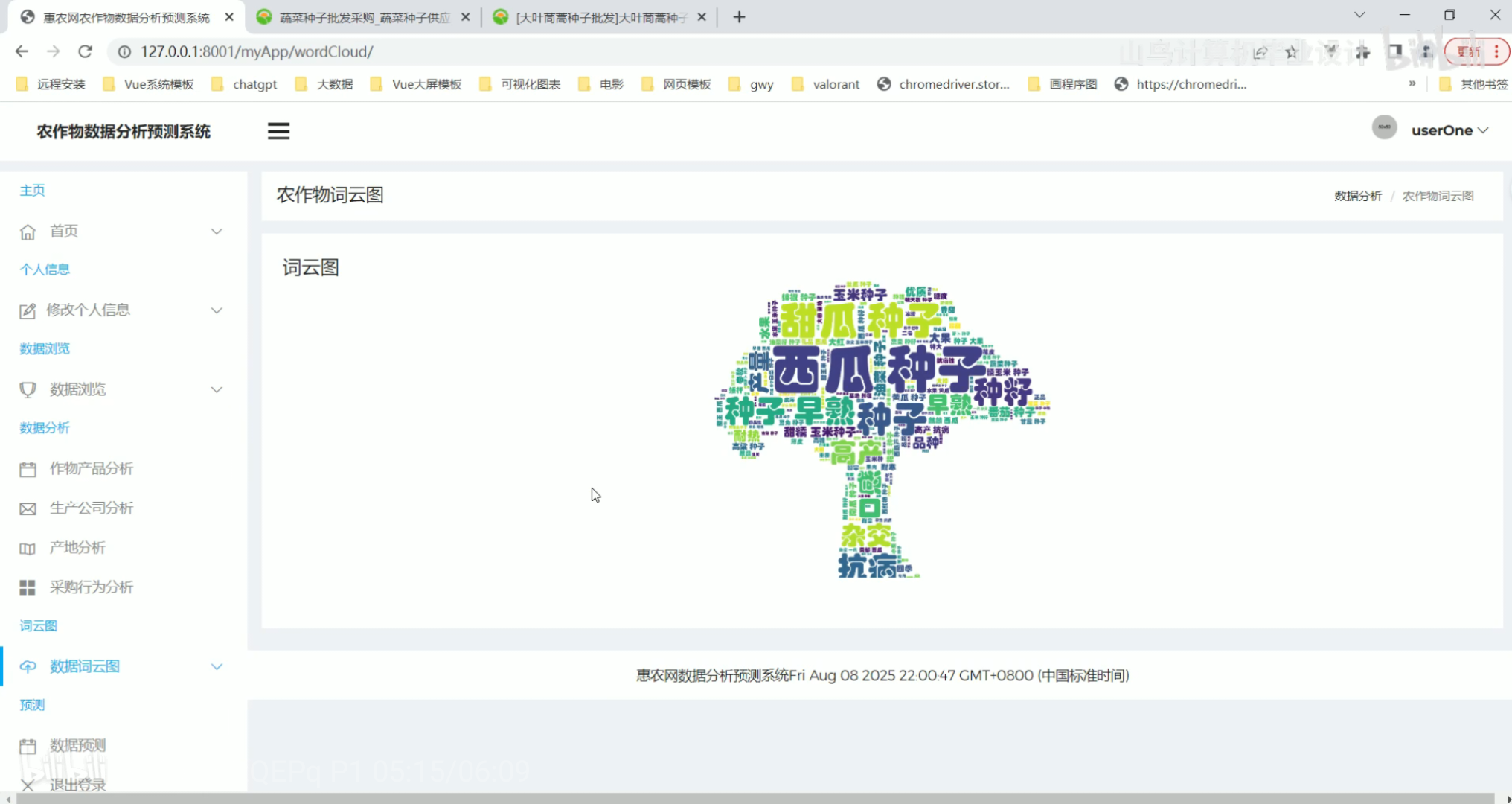 数据预测
数据预测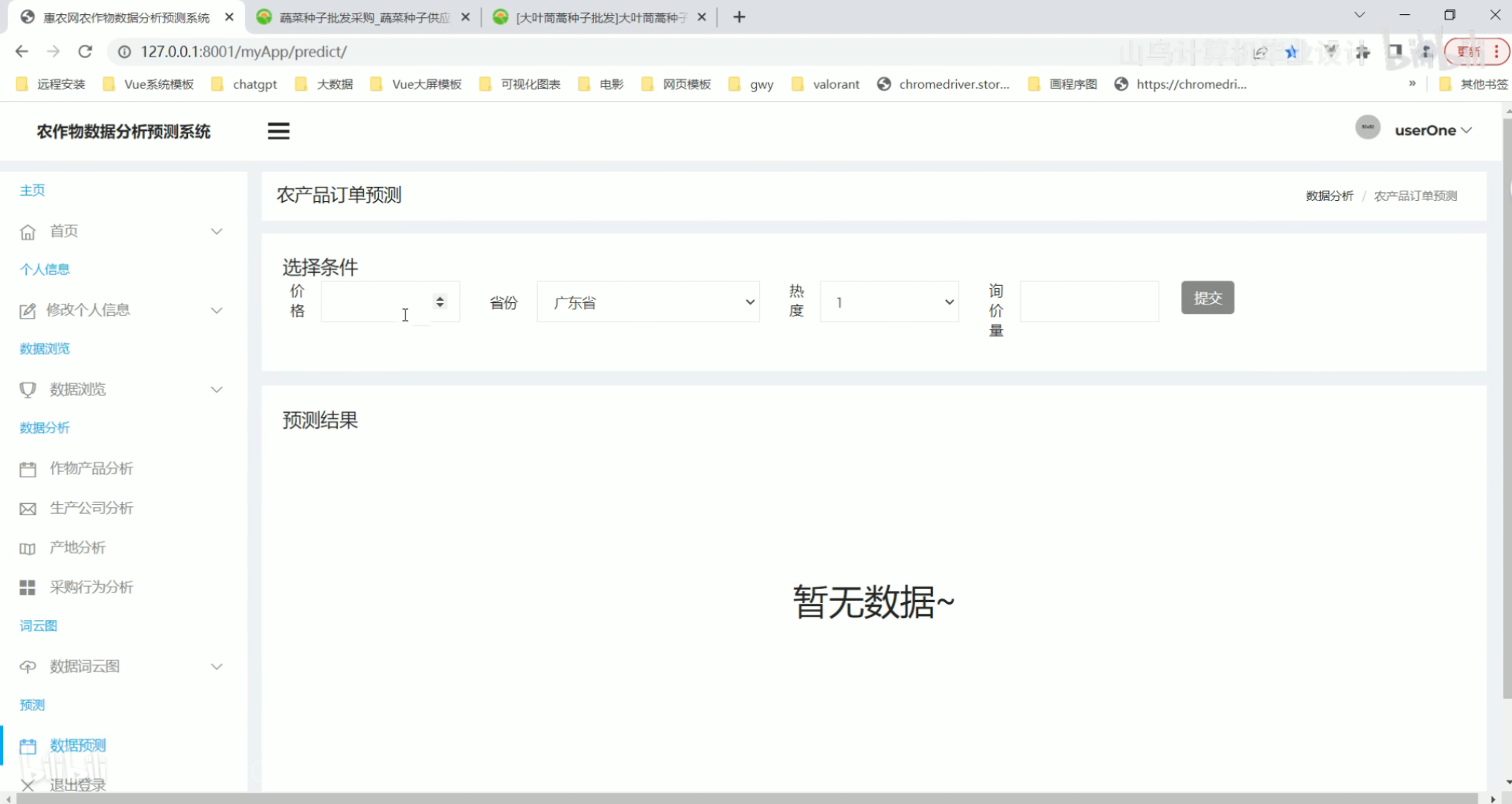
六、权威教学视频
【Spark+Hadoop+DeepSeek-R1】基于spark+hadoop农作物大数据分析可视化预测系统大数据毕设 计算机毕业设计—免费完整实战教学视频
源码文档等资料获取方式
需要全部项目资料(完整系统源码等资料),主页+即可。
需要全部项目资料(完整系统源码等资料),主页+即可。
需要全部项目资料(完整系统源码等资料),主页+即可。
需要全部项目资料(完整系统源码等资料),主页+即可。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 14
14 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)