Bark模型论文解读,并基于MindSpore NLP推理复现
本文介绍了Bark文本到音频模型及其支撑论文AudioLM,并比较了PyTorch和MindSporeNLP平台下的性能表现。Bark是由Suno开发的基于transformer的多语音合成模型,支持13种语言和多种音频效果。其核心技术源于AudioLM论文提出的分层音频标记方法,实现了高质量音频生成和长期一致性。实验采用"suno/bark-small"模型,在相同硬件环境下
# 01
文本摘要
本文希望能够带大家稍微了解一下 Bark 模型及其背后的支撑论文 AudioLM,介绍如何在 MindSpore NLP 平台上加载和评估 Bark 模型,并通过实验比较了PyTorch 和MindSpore NLP 两种环境下的性能表现。本文旨在为研究人员和开发者提供对 Bark 模型及其应用的一部分理解,并展示其在不同硬件平台上的性能表现。
# 02
什么是Bark模型
Bark 模型是由 Suno 公司开发的一款基于 transformer 的文本到音频模型。它能够生成高度逼真的多语言语音,支持包括英语、德语、西班牙语、法语、印地语、意大利语、日语、韩语、波兰语、葡萄牙语、俄语、土耳其语和中文在内的多种语言。此外,Bark 还能生成音乐、背景噪音和简单的音效,甚至可以模拟非语言交流,如笑声、叹息和哭泣。
除此之外,Bark 模型的功能特性非常丰富。它不仅能够处理文本到语音的转换,还能生成多种音频内容,适用于多种应用场景。其多语言支持使得它在国际化项目中具有显著优势。此外,Bark 模型还提供了两个不同的模型大小(small 和 large),用户可以根据需求选择合适的模型。
在一般情况下,Bark模型可以用于处理多种任务类型,包括但不限于:
①文本到语音的转换
②音频内容的生成
③多语言语音合成
④非语言交流的模拟
# 03
Bark模型背后的支撑论文:AudioLM
该论文的标题是AudioLM:a Language Modeling Approach to Audio Generation,中文名:一种音频生成的语言建模方法。
1、论文摘要
AudioLM是一个能够生成具有长期一致性的高质量音频的框架。AudioLM将输入音频映射到一系列离散的标记,并将音频生成转化为该表示空间中的语言建模任务。我们展示了现有的音频标记器在重建质量和长期结构之间的不同权衡,并提出了一种混合标记方案以实现这两个目标。具体来说,我们利用在音频上预训练的掩蔽语言模型的离散激活来捕捉长期结构,并利用神经音频编解码器产生的离散代码来实现高质量合成。通过对大量原始音频波形进行训练,AudioLM学会了在给定简短提示的情况下生成自然且连贯的延续。在语音训练中,且无需任何转录或注释的情况下,AudioLM能够生成在语法和语义上合理的语音延续,同时保持说话者的身份和语调。此外,我们展示了我们的方法如何扩展到语音之外,通过生成连贯的钢琴音乐延续,尽管训练中没有任何音乐的符号表示。
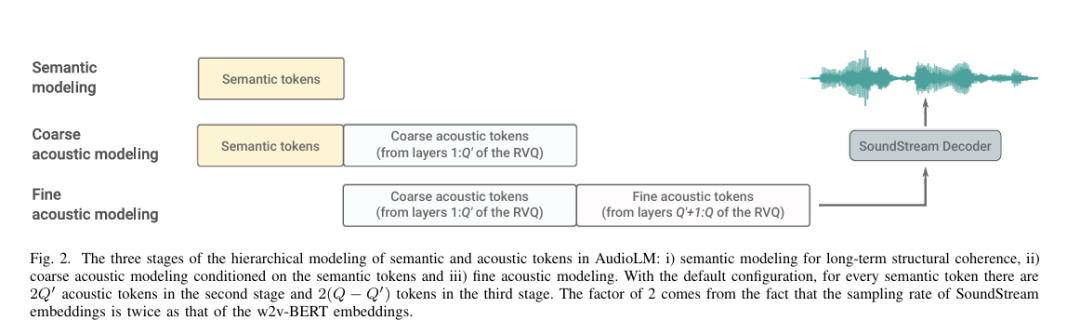
2、论文创新点
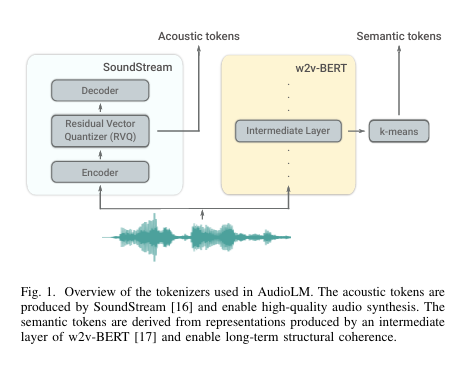
从原始音频波形开始,本论文首先从一个使用自监督掩蔽语言建模目标预训练的模型中构建粗略语义标记。这些标记的自回归建模捕捉了局部依赖关系(例如,语音中的音素、钢琴音乐中的局部旋律)和全局长期结构(例如,语音中的语言语法和语义内容;钢琴音乐中的和声和节奏)。然而,这些标记导致重建质量较差。为了克服这一限制,除了语义标记外,我们还依赖由SoundStream神经编解码器产生的细粒度声学标记,这些标记捕捉了音频波形的细节,允许高质量合成。训练一个语言模型来生成语义和声学标记,同时实现高质量音频和长期一致性。
1)提出AudioLM框架,分层方式结合语义和声学标记,以实现生成长期一致性和高质量的音频。
2)通过与w2v-BERT以及SoundStream的对比,证明了模型的可辨别性和重建质量优势的互补性。
3)模型可以不依赖文本标注,生成语音,句法和语义。只需要3s语音作为提示,即可生成训练期间未见过的语音,并保持说话人的声音,韵律,录音条件(混响、噪音)。
4)为防御生成语音带来的潜在风险,还提出了一个分类器,用于识别合成音频和真实音频。
3、论文实验表现
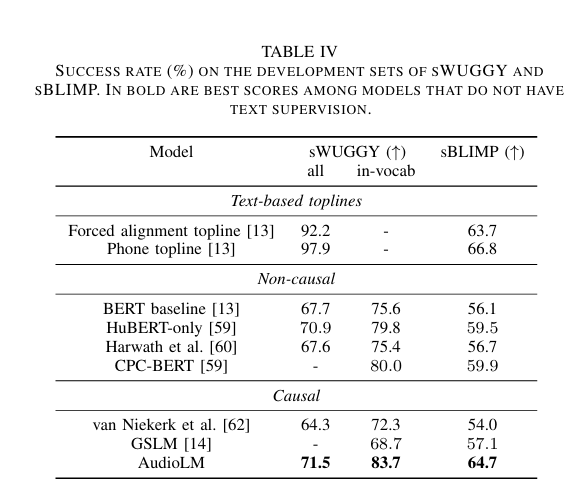
论文通过基于以下任务的主观评估进一步验证了前一节的结果。评估者被要求收听一个正好10秒的样本,并判断它是人类语音的原始录音还是由我们的框架生成的合成延续。我们总共使用了100个样本,这些样本从LibriSpeech test-clean中随机选择,长度至少为10秒,以便我们可以在不引入任何填充的情况下将长度截断为正好10秒。一半的样本是真实的10秒话语,我们通过SoundStream压缩以匹配AudioLM输出的比特率,以便压缩伪影不能作为检测合成音频的线索。在剩下的另一半中,我们从样本的开头提取3秒的提示,并生成相应的正好7秒的延续(在与提示连接后,样本长度为10秒)。我们依赖10名通过英语熟练度筛选的评估者,并告知他们每个样本的前3秒是原始人类语音,因此他们的判断应基于前3秒后的部分。这个主观评估任务同时测试了多个期望的属性:i)生成的语言内容的语义和语法正确性;ii)延续在提示上下文中的声学一致性(说话者身份、语调、录音条件)以及iii)生成样本中没有生成伪影。根据收集的1000个评分,正确分配标签(原始与合成)的成功率为51.2%,根据二项式检验,这与随机分配标签(50%成功率)没有统计学上的显著差异(p = 0.23)。
# 04
在MindSpore NLP上加载bark模型
我们可以使用以下代码在MindSpore NLP环境下加载bark模型,代码来自lvyufeng老师,发布自MindSporelab的github页面。
import scipy
import mindspore
from IPython.display import Audio
from mindnlp.transformers.models.bark import BarkModel, BarkProcessor
voice_preset = None
def main():
print("欢迎使用 Bark模型,输入下列任一数字选择你所需要的模型规模,或者输入stop提前终止程序")
print("------------------------------------------------------------")
print("| 1. bark-small |")
print("| 2. bark-large |")
print("------------------------------------------------------------")
print("注意: 如果你希望使用不同的说话人模式, 由于相应的模型无法直接下载")
print("请自行下载后,并修改voice_preset使其指向文件对应的位置")
choose = input("请输入你的选择:")
if (choose == "stop"):
return 0
else:
if(choose != "1" and choose != "2"):
print("选择无效,即将退出")
return 0
Processor = BarkProcessor.from_pretrained("suno/bark-small") if choose=="1" else BarkProcessor.from_pretrained("suno/bark")
Model = BarkModel.from_pretrained("suno/bark-small") if choose=="1" else BarkModel.from_pretrained("suno/bark")
Model.set_train(False)
while True:
inputs = input("请输入你想要让我说的话(可以带上大笑[laugh]等语气词):")
if inputs == "stop":
return 0
inputs = Processor(inputs, voice_preset = voice_preset)
audio_array = Model.generate(**inputs,pad_token_id=10)
audio_array = audio_array.numpy().squeeze()
sample_rate = Model.generation_config.sample_rate
Audio(audio_array, rate=sample_rate, autoplay=True)
scipy.io.wavfile.write("bark_out_ms.wav", rate=sample_rate, data=audio_array)
if __name__ == "__main__":
main()本次测试的虚拟环境来自启智社区,软件环境是MindSpore2.5.0,MindSpore NLP版本为0.4.1。
为了节约本次实验的运行时间,我们使用小的checkpoint,也就是“suno/bark-small”,同时用了ModelScope用来加载bark-small模型
TF的调试代码:
import time
import psutil
import torch
from modelscope import AutoProcessor, AutoModel
import scipy
def get_memory_usage():
process = psutil.Process()
mem_info = process.memory_info()
return mem_info.rss / (1024 * 1024) # 返回MB
def evaluate_bark_on_cpu():
# 加载模型和处理器
processor = AutoProcessor.from_pretrained("mlx-community/bark-small")
model = AutoModel.from_pretrained("mlx-community/bark-small")
model.eval()
# 测试输入
inputs = "你好,欢迎使用Bark模型!"
inputs = processor(inputs, return_tensors="pt")
# 测量内存占用
mem_before = get_memory_usage()
with torch.no_grad():
start_time = time.time()
audio_array = model.generate(**inputs, pad_token_id=10)
end_time = time.time()
mem_after = get_memory_usage()
# 计算延迟和内存变化
latency = end_time - start_time
mem_usage = mem_after - mem_before
return latency, mem_usage
if __name__ == "__main__":
latency, mem_usage = evaluate_bark_on_cpu()
print(f"CPU+torch延迟: {latency:.2f}秒")
print(f"CPU+torch内存占用: {mem_usage:.2f}MB")MindSpore NLP的调试代码:
# npu_bark_eval.py
import time
import psutil
import mindspore
from mindnlp.transformers.models.bark import BarkModel, BarkProcessor
import scipy
import numpy as np
def get_memory_usage():
process = psutil.Process()
mem_info = process.memory_info()
return mem_info.rss / (1024 * 1024) # 返回MB
def evaluate_bark_on_npu():
# 加载模型和处理器
processor = BarkProcessor.from_pretrained("suno/bark-small")
model = BarkModel.from_pretrained("suno/bark-small")
model.set_train(False)
# 测试输入
inputs = "你好,欢迎使用Bark模型!"
inputs = processor(inputs)
# 测量内存占用
mem_before = get_memory_usage()
start_time = time.time()
audio_array = model.generate(**inputs, pad_token_id=10)
end_time = time.time()
mem_after = get_memory_usage()
# 计算延迟和内存变化
latency = end_time - start_time
mem_usage = mem_after - mem_before
return latency, mem_usage
if __name__ == "__main__":
latency, mem_usage = evaluate_bark_on_npu()
print(f"NPU+MindNLP延迟: {latency:.2f}秒")
print(f"NPU+MindNLP内存占用: {mem_usage:.2f}MB")运行结果:
torch延迟: 18.07秒torch内存占用: 1382.20MB---------------MindSpore NLP延迟: 16.42秒MindSpore NLP内存占用: 1401.32MB
可以看出,在同样生成一句话"你好,欢迎使用Bark模型!"时,MindSpore NLP组的生成延迟略低于torch组,但内存占用稍高,不过影响不大。
# 05
总结
未来,随着硬件技术的进一步发展和模型优化的深入,Bark 模型有望在更多领域实现更广泛的应用,为语音合成和音频生成任务提供更高效、更高质量的解决方案。同时,我们也期待MindSpore NLP 平台的持续更新和完善,为研究人员和开发者提供更强大的工具和支持。
参考文献:
1:https://github.com/mindspore-lab/mindnlp/blob/master/llm/inference/bark/inference.py
2:https://arxiv.org/abs/2209.03143
3:https://arxiv.org/abs/2301.02111

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 19
19 0
0- 0



 已为社区贡献30条内容
已为社区贡献30条内容

所有评论(0)