【VLA & Markov】VLA 架构和构建模块 与 Markov 带来的时序思考
视觉语言动作模型(VLA)的常见框架包括Transformer结合离散动作token、扩散动作头或扩散变换器,以及利用预训练视觉语言模型(VLM)的变体。这些架构通过离散或连续token输出动作,并结合扩散模型提升平滑性和实时响应能力。此外,融入世界模型的设计(如GR-1)通过端到端预测未来图像和动作,增强了事件预测能力。GR系列模型的迭代(如GR-3)进一步整合VLM和扩散变换器,实现了分层结构
https://arxiv.org/pdf/2510.07077
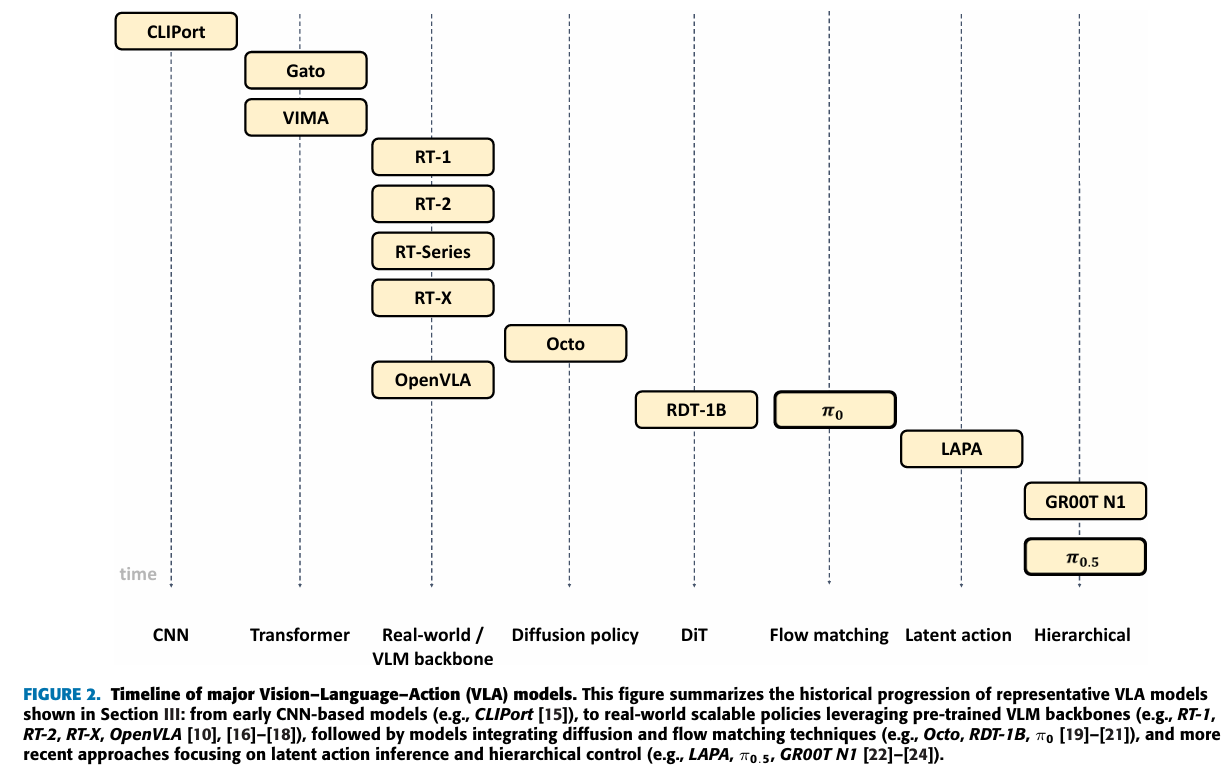
一、VLA的常见框架
(1) Transformer + Discrete Action Token
架构:encoder-decoder, decoder-only
输入:把图片和语言离散化成 token,然后把tokens喂到 transformer,进行NTP的预测;
输出:输出的是离散token,所以动作也是离散的,例如经典的:binned value(分箱值)。
(2) Transformer + Diffusion Action Head
架构:在(1)的基础上,及一个动作扩散头;原因是:离散动作token 通常缺乏实时响应性和平滑度,但这些模型使用扩散模型实现了连续且稳定的动作输出
输入:图像和语言 token 作为一个 单独的序列通过 transformer,并且输出 token 作为 condition 指导去噪过程,以生成连续动作;
输出:输出的是连续 token,所以动作也是连续的。
(3) Diffusion Transformer
架构:以 Diffusion Transformer (DiT)为代表的框架
输入:图像和语言 token,action tokens
输出:连续的 tokens
RDT-1B
(4) VLM + Discrete Action Token.
架构:将(1)中的 transformer 替换成 基于大规模互联网数据预训练的视觉语言模型 VLM 。原因:利用 VLM,这些模型能够吸收人类常识,并受益于上下文学习能力。
(5) VLM + Diffusion/FlowMatching Action Head.
架构:动作头模型 (Action Head) 在 (2) 的基础上构建,将 Transformer 替换为 VLM。该架构将能够实现更好泛化的 VLM 与能够生成平滑、连续机器人动作命令的扩散模型相结合。
将 扩散模型替换为流匹配动作头,从而提高了实时响应能力,同时保持了平稳、连续的控制。
(6) VLM + Diffusion Transformer
VLM通常充当高级策略(系统 2),而扩散变换器充当低级策略(系统 1)。
扩散变换器可以使用扩散或流匹配来实现。一个代表性模型是 GR00TN1 ,它将扩散变换器的交叉注意力机制应用于 VLM 词条,并通过流匹配生成连续动作。
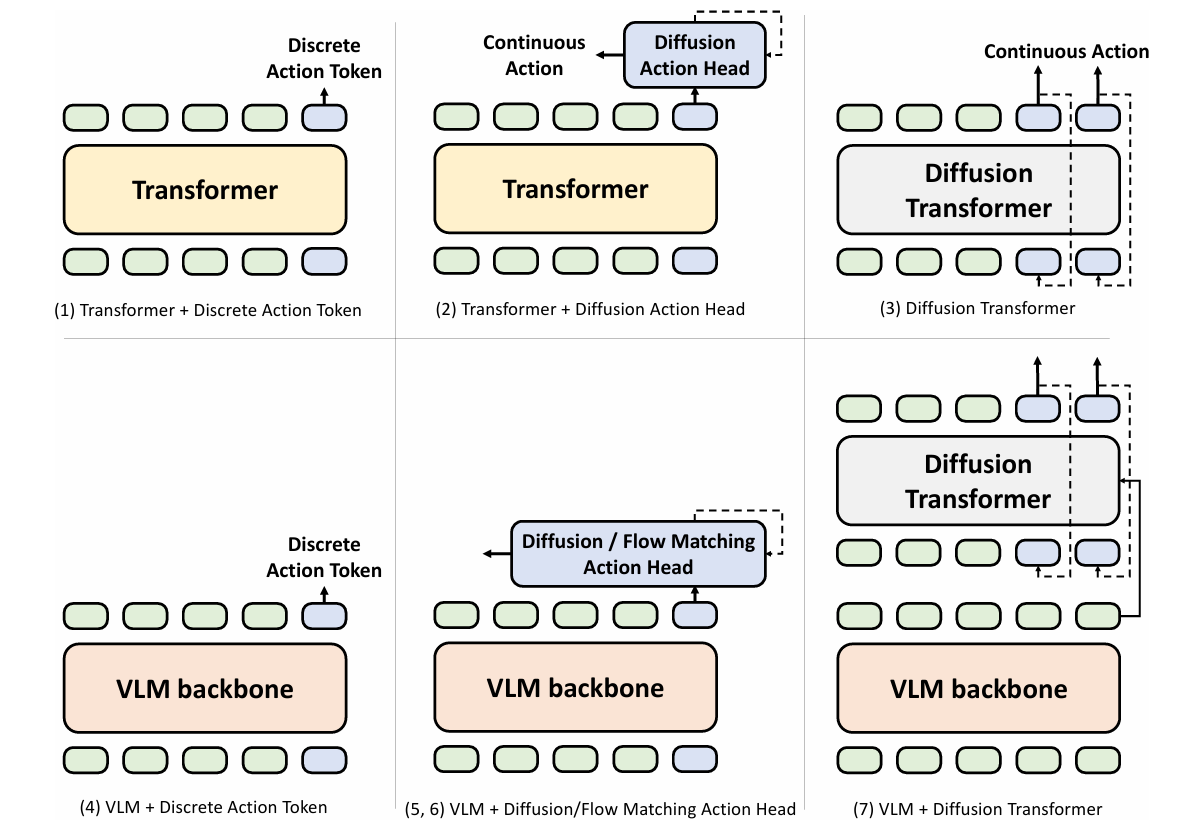
二、在 VLA 中融入世界模型的设计模式
(3) VLA models with implicit world models
GR 系列为代表
GR-1: GR-1,是一个简单的 GPT 风格模型,专为多任务语言条件视觉机器人操作而设计。GR-1 将语言指令、观察图像序列和机器人状态序列作为输入。它以 端到端的方式预测机器人动作以及未来图像。
Insight:视频生成预训练是一项与机器人动作学习密切相关的任务,因为机器人轨迹本身包含视频序列。根据过去的图像和语言指令预测未来帧的能力使机器人能够预测即将发生的事件,从而有助于产生相关和适当的动作。
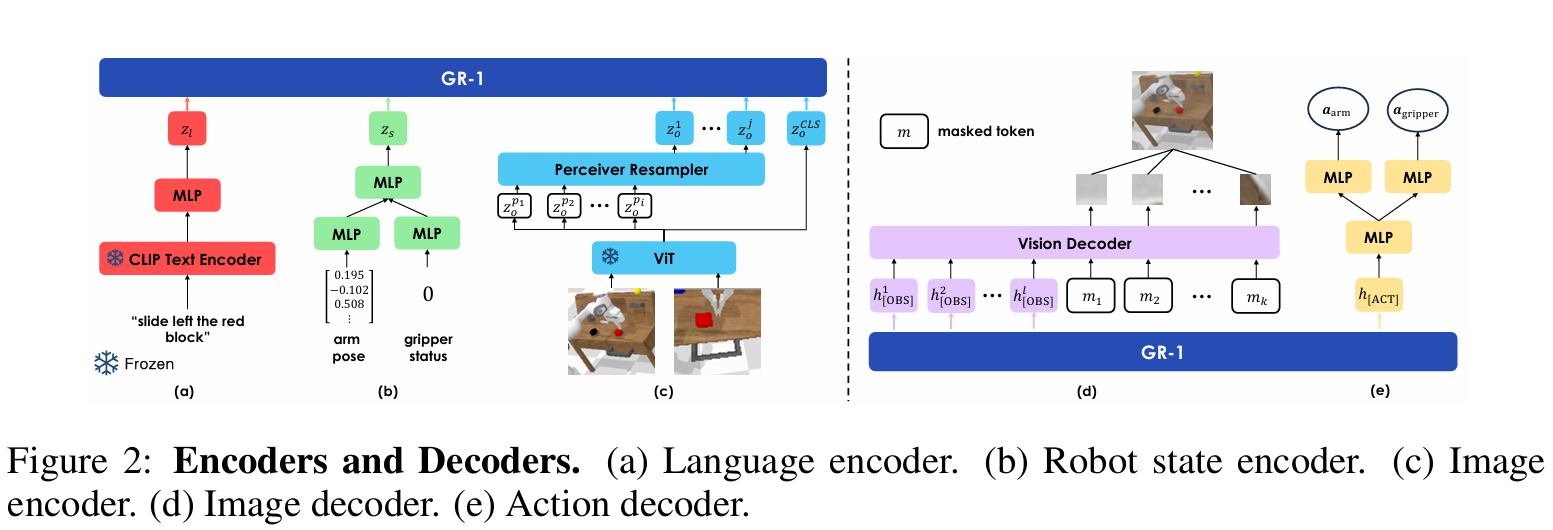
-
视觉输入。视觉观察 o 通过用 MAE 预训练的视觉 Transformer (ViT) 进行编码。
-
首先对 GR-1 进行视频预测预训练,然后根据机器人数据对其进行微调。在预训练和微调阶段,冻结 CLIP 文本编码器和 MAE 图像编码器。
GR-2 相比于 GR-1 的提升:1)使用了更多的数据;2)部署到了实际的机器人上;3)architecture 可能有些改进,比如新增了 multi-view 等。
GR-3 通过集成 VLM(Qwen2.5-VL 和扩散变换器,实现了分层结构,并实现了低匹配动作。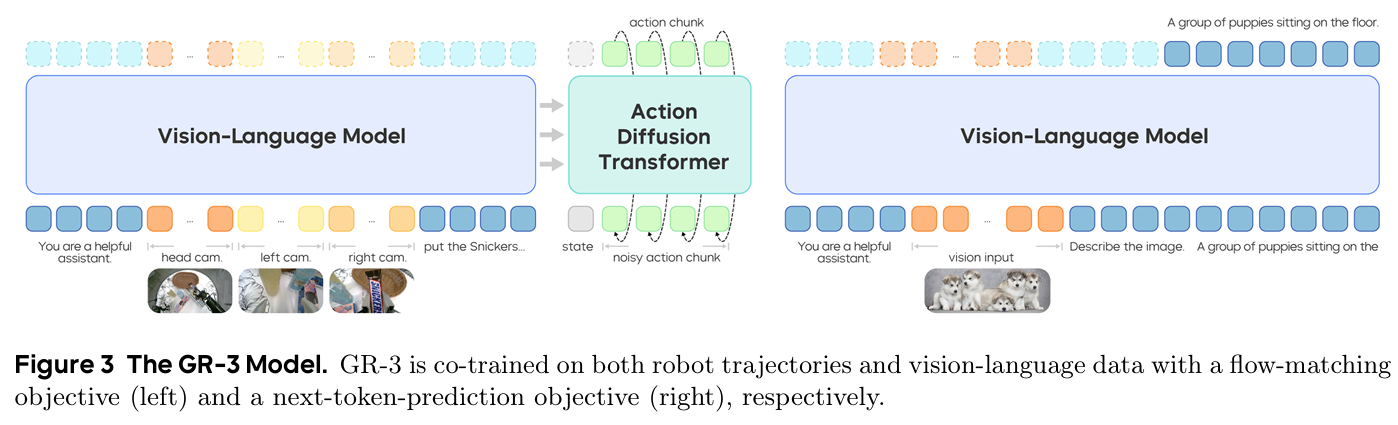
三、马尔可夫性质 (Markov Property)
1. 经典机器人控制 (通常具有马尔可夫性质)
在传统的强化学习 (RL) 和许多模仿学习 (IL) 框架中,机器人操作通常被建模为一个马尔可夫决策过程 (MDP)。马尔可夫性质 (Markov Property):
- 当前状态 S t \mathbf{S}_t St 包含了预测下一个状态 S t + 1 \mathbf{S}_{t+1} St+1 所需的所有相关信息。换句话说,系统的未来只依赖于现在,与过去的历史 S 0 , S 1 , … , S t − 1 \mathbf{S}_0, \mathbf{S}_1, \dots, \mathbf{S}_{t-1} S0,S1,…,St−1 无关。
- 应用: 在这些模型中,机器人基于当前的视觉观察 (Observation) O t \mathbf{O}_t Ot(即当前状态的表示)直接决定动作 (Action) A t \mathbf{A}_t At。
2. VLA 模型如何处理 (或打破) 马尔可夫性质

当前的 VLA 模型,尤其是那些使用 Transformer 架构作为特征推理主干的模型,往往会处理序列数据,这让情况变得复杂
-
语言指令: 语言指令 (如“先拿杯子,再放进水槽”) 引入了长期依赖和子目标。打破严格马尔可夫性: 机器人需要“记住”并跟随完整的指令,指令的起始部分影响后续的动作。
-
动作序列生成: 许多 VLA 模型使用 自回归 (Auto-regressive) 或 序列到序列 (Seq2Seq) 的方式生成动作。依赖历史: 模型生成 A t \mathbf{A}_t At 时,会以过去的动作 A 0 , … , A t − 1 \mathbf{A}_0, \dots, \mathbf{A}_{t-1} A0,…,At−1 和过去的观察 O 0 , … , O t \mathbf{O}_0, \dots, \mathbf{O}_t O0,…,Ot 作为输入,这打破了严格的马尔可夫假设(即只依赖于 O t \mathbf{O}_t Ot)。
-
部分可观察马尔可夫决策过程 (POMDP): 在现实世界的机器人操作中,由于遮挡或传感器限制,当前观察 O t \mathbf{O}_t Ot 往往不足以定义完整的状态。需要历史信息: VLA 模型通过其记忆能力(如 Transformer 的注意力机制)集成历史信息来近似完整的状态,这更接近 POMDP 的处理方式。
在机器人场景的直觉
Markov 近似成立的情况:
机器人做低层控制任务,如运动控制(Joint torque control),假设传感器足够精密,状态空间包含所有必要变量(位置、速度、环境反馈)。
Non-Markov 明显的情况:
高层次规划或推理任务,环境中有隐藏变量:
等待水开;根据之前观察到的人类指令进行操作(指令未显式编码进当前状态);手眼协作时,摄像头无法观测到遮挡物背后的状态
结论: 当前的 Vision-Language-Action 模型 并不严格满足 Markov 性质,它们通常工作在部分可观测环境,并通过显式历史建模(序列模型、memory、action chunking 等)来缓解 Non-Markov 问题。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 14
14 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)