ELMo词向量模型
ELMo(Embeddings from Language Models)是 2018 年由 AllenNLP 团队提出的上下文相关词向量模型,它在当时显著提升了多个自然语言处理任务的表现,为后来的 BERT 和 GPT 等预训练模型奠定了重要基础。
·
ELMo(Embeddings from Language Models)是 2018 年由 AllenNLP 团队提出的上下文相关词向量模型,它在当时显著提升了多个自然语言处理任务的表现,为后来的 BERT 和 GPT 等预训练模型奠定了重要基础。
一、ELMo 是什么?
ELMo 是一种基于语言模型(Language Model)的词向量表示方式,它的最大特点是:同一个词在不同语境中可以有不同的表示。
传统词向量(如 Word2Vec、GloVe)是静态的:
- “bank” 无论出现在金融语境还是河岸语境中,其词向量都一样。
而 ELMo 是上下文相关的词向量:
- “bank” 在句子 “He went to the bank to deposit money” 和 “The boat floated to the river bank” 中会有不同的表示。
二、ELMo 的模型结构
ELMo 架构基于双向语言模型(BiLM),即结合:
- 前向语言模型(从左到右)
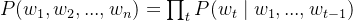
- 后向语言模型(从右到左)
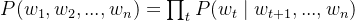
模型核心组件:
- 字符卷积层(CNN over char):输入的词是由字符组成,解决 OOV 问题;
- 双向 LSTM:捕捉上下文语义;
- 向量融合(task-specific combination):将不同层的 LSTM 输出进行加权求和,得到最终词向量。
三、ELMo 的词向量生成方式
ELMo 并不是单一的词向量,而是一个任务敏感的加权和: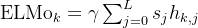
- hk,jh_{k,j}hk,j:第 j 层的第 k个 token 的隐藏状态
- sjs_jsj:softmax 得到的权重(可学习)
- γ\gammaγ:整体缩放参数(可学习)
✅ 不同任务中,ELMo 会自动学习如何加权不同的层表示
四、ELMo 如何使用?
使用方式:作为词向量特征加入下游模型中,例如 BiLSTM + ELMo + Softmax。
在 NLP 任务中,一般流程如下:
输入文本 → 分词 → ELMo 向量(上下文相关) → 输入分类器或序列标注模型
官方提供了 Python 接口,可快速加载预训练模型。
五、ELMo 与传统词向量的对比
| 特性 | Word2Vec / GloVe | ELMo |
|---|---|---|
| 向量类型 | 静态 | 上下文相关动态表示 |
| 上下文建模 | 无 | 双向 LSTM 建模 |
| OOV 问题 | 严重 | 基于字符,OOV 稀少 |
| 模型参数 | 训练后固定 | 可用于下游微调 |
| 效果(NER、QA等) | 较低 | 提升数十个百分点 |
六、代码示例(使用 AllenNLP)
from allennlp.commands.elmo import ElmoEmbedder
elmo = ElmoEmbedder()
tokens = ["The", "cat", "sat", "on", "the", "mat"]
vectors = elmo.embed_sentence(tokens)
# vectors 是 shape: (3层, 句长, 1024)
# 可取平均或指定层向量作为词表示
import numpy as np
word_vecs = np.mean(vectors, axis=0) # (句长, 1024)

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 0
0 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)