Milvus向量数据库学习笔记(3)
第二索引篇2
上一篇的IVF类索引,还差一个。那就是IVF_RABITQ索引。这个索引,是学习Milvus数据库以来,花时间最长的一个地方。因为要理解RABITQ索引的算法,稍微有些麻烦。在理解上和朋友们有一些交流,有些朋友直接劝说我用就可以了,不需要去理解它。确实,这个策略我是有一定程度的赞成的。就好像传统的数据库,我们天天用B-TREE的索引。但是对于使用这些索引的程序开发者,你正儿八经要他把B-TREE画出来,并且把里面的原理和细节都说清楚,那绝大部分人是做不到的。最重要的是,在这个功利的世界里,这么做投入产出比极小的。其实我也不推荐硬要去理解。
当然,我们是DBA,不是绝大多数人。不过,如果这个索引实在看不懂,我觉得也可以算了。
IVF_RABITQ索引
IVF_RABITQ索引,是一种基于二进制量化的索引。它把32位浮点的向量,量化成二进制的表示。它存储效率极高,压缩比位1:32,并且还可以保持比较好的召回率。常用于内存受限的情况。
.RABITQ量化算法,发表于2024年的SIGMOD,是一个比较新的技术,相对于前面的索引,也是最难理解的一个。它提出强调了严格的理论误差界限,同时提供了良好的实证准确性。要理解它的实现,需要先铺垫一些高维向量的数学知识。
一些数学背景
考虑到我自己的数学水平的限制,下面的内容主要引用于这篇SIGMOD的论文作者的一篇BLOG上的说明用例。
任意一个单位向量(长度为1的向量),设为X。假设有一个场景,我们关注它在某一个分向量上的投影,定义为X[0]。但是由于一些原因,我们不能直接计算,只能评估它的大致范围。因为它的长度是1,所以X[0]的取值范围一定分布在[-1,1]。
接下来,考虑一个随机的单位向量,均匀分布在一个单位球面上,这以为这球面每一个点的概率都相等。通过升入观察,产生一些随机的向量,然后测量X[0]的值,可以发现,在3维空间里,X[0]可能会取到[-1,1]之间的任意值。而在1000维的向量时,尽管X[0]的可能的范围空间还是[-1,1],但是实际上,x[0],密集的集中在了0的周围。
从而得出一个重要得概念:在高维空间中,随机性可以出人意料得提升确定性。这个现象又被称之为测度集中现象,是高维几何和概率的一个基本规则。从数学的角度来理解。一个X的单位向量,它长度为1,根据向量求模公式:

当维度D为3的时候,每一个项贡献的总长度的1/3,其中一项贡献多于50%的概率还是比较大的。当维度D为1000的时候,它的长度就又1000项来组成,每一项占1/1000.如果还有单一项超过50%,这就要求其他项贡献的长度,大幅低于平均,那对于某个场景,就是极其罕见的了。
所以,在高维空间,X[0]不太可能偏离0。所以根据约翰逊-林登斯特劳斯引理Johnson-Lindenstrauss(JL) Lemma。X[0]的值偏离0的值不太可能大于2/√D。那么这个在高维空间的集中现象呢,就产生了一些重要的意义。
例如,当维度D 非常大的时候呢,x[0]就会在很严格的边界范围之中。在高维空间理,X[0]的不确定性大幅的缩减。而且,不需要经过任何计算,它是免费没有大家的。这个现象就提供一个提升算法的机会,并且是没有额外开销的。
RABITQ索引的构建
RABITQ和它的扩展,基本上可以被当作一个二进制或者标量数据的量化优化方案。RABITQ就是通过刚才的这个免费的信息的有效利用,从而获得了良好的性能表现。
在索引构建的阶段。
第一步:标准化。
or和qr分别代表数据向量和查询向量。现在,已估算他们之间的欧几里得距离来作为目标。让c来作为数据向量的中心数据向量。为了简化距离估算问题,我们先把问题简化成单位向量之间的内积估算。我们考虑以中心为基准,对向量标准化处理。
我们取
o:= (or-c)/|| or-c||,q:= (qr-c)/|| qr-c||
然后用下面的等式,我们可以把距离估算的问题,简化成一个单位向量的内积估算。
|| or -qr||2=||( or -c)-( qr -c)||2
=||( or -c)|| 2+||( qr -c)|| 2-2*||( or -c)||* ||( qr -c)||*<q,o>
这里||( Or-c)||可在索引构建时计算,||( qr -c)||在查询时要算一次,然后用于所有的数据向量都可以共享。所以,问题就被简化成估算<q,o>。直觉上看,标准化之后,可以把一组向量集集中在空间中心,并且将他们进一步对齐在一个单位球面上。因此,这个操作把数据向量都均匀的分摊到了单位球面上。
第二步:构建码表。
鉴于,原始的数据向量转化成单位向量,会均匀的分布在单位球面上,我们需要也构建一个均匀分布在单位球面上的码表。所以,我们采用一种自然的构造方法,在高维单位球面嵌套一个超立方体。
然后,要利用好,高维空间的集中现象,给码表注入一些随机性来旋转,来解决方向的偏好性。
这个随机旋转的地方是非常抽象难以理解的。我不确定理解是否正确,我的大致思路是。因为前文的x[0]其实表示的可能是向量的任意的一个分向量的投影。它的理论值本来应该是[-1,1]。如果向量在x[0]这个方向的分向量很大,那么这个向量就有这个方向的偏好。在高维的空间随机旋转之后,根据前面的引理,x[0]的值就大概率近似为0了。也就是消除了这个方向的偏好。
然后,为每一个向量o,找到一个码表中最接近的向量o’,这个o’肯定是在超立方体上,所以每一个维度可以用1个BIT来存储。
下面是milvus官网介绍的 的RaBitQ的索引构建流程如下:
- 确定编码本codebook。类似于之前,编码本用一个存储空间较小的内容,用以标识和替代一整个维度的向量。归一化之后呢,数据点就分布在单位超球面上。所以编码本大约就是一个C:={(∓1/√D, ∓1/√D, ∓1/√D,……., ∓1/√D)}这样的东西,最多2D个。
- 为了解决某些方向“偏好”,再使用随机正交矩阵P,来对CODEBOOK里所有向量做一次旋转,去除方向偏好的影响。
- 根据新的CODEBOOK,量化向量,先找到距离向量最近的码表中的中心点向量。也就是找到码表里每一维正负号相同的码表向量就可以了。
查询阶段
这时候,要基于上面量化过的向量,来构建一个估算<q,o>内积的方法。为此,我们先分析向量o,q和o’的几何学关系。如图: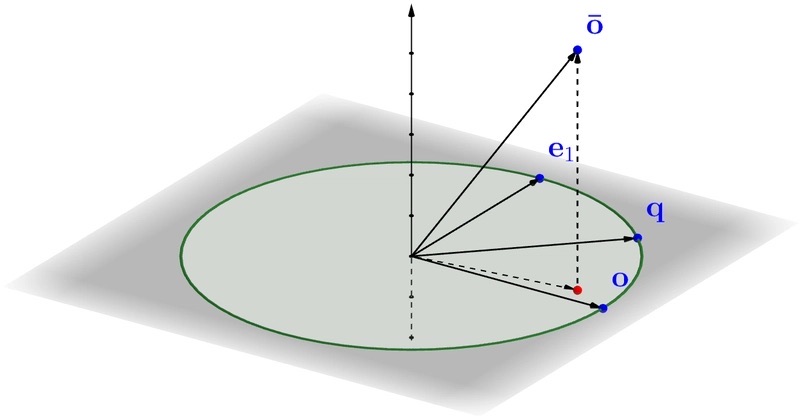
尽管o,q和o’是高维向量,要估算<q,o>,先关注2维平面上。
这里有一个e1的单位向量,它和o在平面上是垂直的。通过分析向量在平面上的几何关系,我们推导下列等式。
<o’,q> = <o’,o>*<o,q>+<o’,e1>*√1-<o,q>2
这就是说,如果我们知道<o,q>以外的所有变量,我们就可以准确的计算出<o,q>。<o’,o>还可以在建索引时算好。<o’,q>可以在查询过程中,通过一些巧妙的方法来计算。然后,由于聚集现象的发生,<o’,e1>大概率集中在了0附近。把它当0来处理,就可以极大的简化计算过程。
所以<o,q>≈<o’,q>/<o’,o>
对任何的向量O的量化步骤如下:
- 保存构建COOKBOOK时用的随机正交矩阵P。
- 计算P-1O
- 取P-1每一维的正负号。
- 用P对量化后的向量反变换,得到最终的量化结果。
插曲
写到这里,RABITQ索引的内容就写完了。考虑到这个内容确实比较抽象,就给他一个单独一篇吧。如果要准确的理解,可能还是要去都SIGMOD原文。
另外一个小插曲是,根据milvus官网,因为o`是存储在索引中,量化的二进制向量。二进制的性质就使得距离计算极快。是受益于现代CPU架构。官网列举了英特尔IceLake+或者AMD Zen 4+两款硬件产品,并且强调了RABITQ索引的性能对硬件严重依赖。
这里挺有意思,这是不是表示,我们用信创的硬件来跑这个索引,会出现性能问题?

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐



 23
23 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)