Qwen3 Embedding与Reranking:新一代文本表征与排序模型
文章优先发布在,有些文章未来得及同步,可以直接关注公众号查看。
文章优先发布在微信公众号——“LLM大模型”,有些文章未来得及同步,可以直接关注公众号查看
1. Qwen3 Embedding 和 Qwen3 Reranking
-
Qwen3 嵌入(Embedding)系列模型,这是对前代 GTE-Qwen 系列的重大技术升级,旨在全面提升文本的 稠密嵌入(Dense Embedding)和重排序(Reranking) 能力,并以 Qwen3 大语言模型(LLM) 作为骨干基座。
-
创新的设计了三阶段训练流程,该流程核心在于利用 Qwen3 LLM 强大的指令遵循与生成能力,实现大规模、可控的合成数据(Synthetic Data) 生成。训练过程结合了大规模弱监督预训练、高质量有监督微调,并引入了球面线性插值(slerp)模型融合策略,确保了模型的鲁棒性与泛化能力。
-
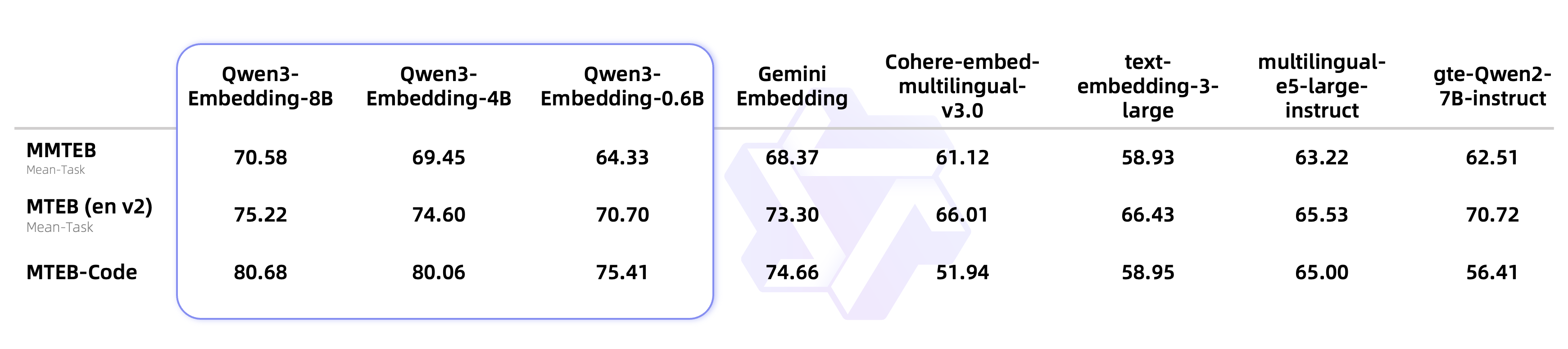
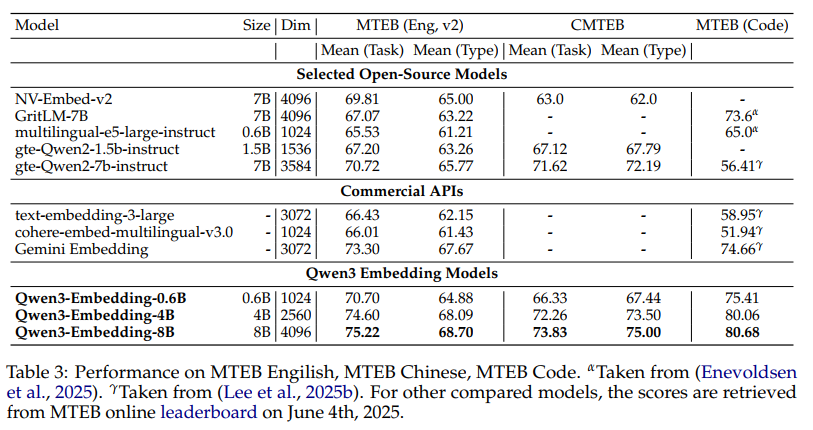
Qwen3 嵌入系列提供了 0.6B、4B、8B 三种参数规模的模型,支持嵌入和重排序双重任务。实证评估表明,旗舰模型 Qwen3-8B-Embedding 在大规模多语言文本嵌入基准(MTEB Multilingual)中取得了 70.58 的成绩,确立了当前最优(State-of-the-Art, SOTA)的性能地位。
文本嵌入和重排序是现代信息检索(IR)和 检索增强生成(RAG) 系统的核心技术。随着 LLMs 的发展,基于 Transformer Encoder-only 架构的传统嵌入模型正被基于更强大 LLM 骨干的新范式所取代。
Qwen3 嵌入系列的推出,正是利用 Qwen3 LLM 固有的丰富世界知识、多语言理解和指令遵循能力,实现了对传统嵌入和重排序模型的性能超越。
2. 模型架构
Qwen3 嵌入和重排序模型均基于 Qwen3 密集版本 LLM 构建,通过定制化的输入和输出机制,实现任务感知型的评估。
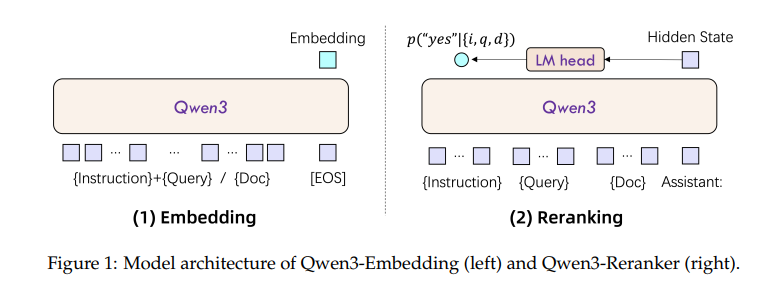
2.1 Qwen3 Embedding嵌入模型:指令感知编码
嵌入模型将文本映射到稠密向量空间,其设计聚焦于如何从因果 LLM 中提取出最具代表性的语义向量。
- 向量提取机制: 模型利用 LLM 的因果注意力机制(Causal Attention)进行编码,最终的嵌入向量 e\mathbf{e}e 采用序列结束标记 [EOS]\texttt{[EOS]}[EOS] 对应的最后一层隐藏状态(Last-Token Hidden State)。
- 指令感知输入(Instruction-Aware Input): 为使嵌入向量感知下游任务类型,模型采用序列拼接,将任务指令 III 融入查询 qqq 的上下文。
- 标准化输入格式:
xquery={Instruction}⊕{Query}⊕[EOS]\mathbf{x}_{\text{query}} = \{\text{Instruction}\} \oplus \{\text{Query}\} \oplus \texttt{[EOS]}xquery={Instruction}⊕{Query}⊕[EOS]
- 标准化输入格式:
2.2 Qwen3 Reranker重排序模型:二分类与概率归一化
重排序模型旨在通过点对(Point-wise)评估来判断查询 qqq 和文档 ddd 之间的相关性。
- 任务形式化: 模型将相关性评估转化为一个二分类(Binary Classification) 文本生成任务,仅输出 “yes” 或 “no”。
- 标准化输入模板: 采用 LLM 的 Chat 模板结构,确保对复杂指令的遵循,上下文信息(指令 I\mathcal{I}I、查询 qqq、文档 ddd)清晰分离。
- 相关性评分函数(规范化公式):
通过预测输出 Token 的概率计算归一化的相关性得分 score∈[0,1]\text{score} \in [0, 1]score∈[0,1]:
score(I,q,d)=p("yes" ∣I,q,d)p("yes" ∣I,q,d)+p("no" ∣I,q,d)\text{score}(\mathcal{I}, q, d) = \frac{p(\text{"yes" } |\mathcal{I},q,d)}{p(\text{"yes" } |\mathcal{I},q,d) + p(\text{"no" } |\mathcal{I},q,d)}score(I,q,d)=p("yes" ∣I,q,d)+p("no" ∣I,q,d)p("yes" ∣I,q,d)
3. 模型训练 (Model Training)
Qwen3 嵌入系列的训练流程是其技术突破的核心,通过多阶段渐进式训练结合LLM 驱动的数据合成,确保了模型的高效性和鲁棒性。

3.1 创新的三阶段训练流程
| 阶段 | 模型目标 | 数据来源/规模 | 核心机制与技术 |
|---|---|---|---|
| Stage 1 | 大规模弱监督预训练 | LLM 合成的弱监督数据(约 1.5 亿对)。 | InfoNCE 对比学习,奠定通用、多语言语义基础。 |
| Stage 2 | 有监督微调(SFT) | 高质量过滤数据(约 1200 万对) + 少量人工标注数据。 | 任务对齐,引入 Hard Negatives,应用假负例掩码。 |
| Stage 3 | 模型融合(Model Merging) | Stage 2 采样的检查点。 | 球面线性插值(slerp),提升鲁棒性与泛化能力。 |
3.2 嵌入模型损失函数:带假负例掩码的 InfoNCE
嵌入模型采用改进的 InfoNCE 对比学习损失,专注于批次内外的 硬负例(Hard Negatives) 挖掘。
-
基本损失公式(规范化):
Lembedding=−1N∑i=1Nloges(qi,di+)/τZiL_{\text{embedding}} = -\frac{1}{N} \sum_{i=1}^{N} \log \frac{e^{s(\mathbf{q}_i, \mathbf{d}_i^+)/\tau}}{Z_i}Lembedding=−N1i=1∑NlogZies(qi,di+)/τ
其中 s(⋅,⋅)s(\cdot, \cdot)s(⋅,⋅) 是余弦相似度,τ\tauτ 是温度参数。 -
假负例掩码(False Negative Masking)机制(强化细节):
为保证训练稳定性,避免模型惩罚实际语义相关但被错误标记为负例的样本,引入掩码因子 mijm_{ij}mij:- 当负例对的相似度 sijs_{ij}sij 高于正例相似度 s(qi,di+)s(\mathbf{q}_i, \mathbf{d}_i^+)s(qi,di+) 加 0.10.10.1 的阈值时,该负例将被屏蔽(mij=0m_{ij}=0mij=0),其贡献的梯度将被移除。
mij={0if sij>s(qi,di+)+0.11otherwisem_{ij} = \begin{cases} 0 & \text{if } s_{ij} > s(\mathbf{q}_i, \mathbf{d}_i^+) + 0.1 \\ 1 & \text{otherwise} \end{cases}mij={01if sij>s(qi,di+)+0.1otherwise
- 当负例对的相似度 sijs_{ij}sij 高于正例相似度 s(qi,di+)s(\mathbf{q}_i, \mathbf{d}_i^+)s(qi,di+) 加 0.10.10.1 的阈值时,该负例将被屏蔽(mij=0m_{ij}=0mij=0),其贡献的梯度将被移除。
3.3 LLM 驱动的高质量数据合成(核心技术突破)
Qwen3 系列通过使用更强大的 Qwen3-32B 模型作为生成器,实现了训练数据的主动控制和大规模合成。
- 可控性与多样性: 利用 LLM 的指令遵循能力,通过定制提示(Prompting)可控地生成涵盖检索、双语挖掘、STS 等多任务、多语言、跨领域的数据,尤其适用于低资源场景。
- 高质量筛选: 采用余弦相似度过滤(保留相似度 ≥0.7\geq 0.7≥0.7 的数据对),将 1.5 亿弱监督数据精炼为 1200 万对高质量 SFT 数据,确保了第二阶段训练的高效性。
3.4 模型融合策略与重排序 SFT
- 重排序 SFT 损失: 重排序模型采用标准的有监督微调损失(SFT Loss),直接优化其二分类判别能力。
Lreranking=−logp(l∣P(q,d))L_{\text{reranking}} = -\log p(l | \mathcal{P}(\mathbf{q}, \mathbf{d}))Lreranking=−logp(l∣P(q,d)) - 模型融合: 采用球面线性插值(slerp)对 Stage 2 SFT 过程中不同检查点的权重进行插值融合。该策略是增强模型泛化能力和鲁棒性的关键,有效防止了训练后期的过拟合。
4. 评估结果
评估表明:
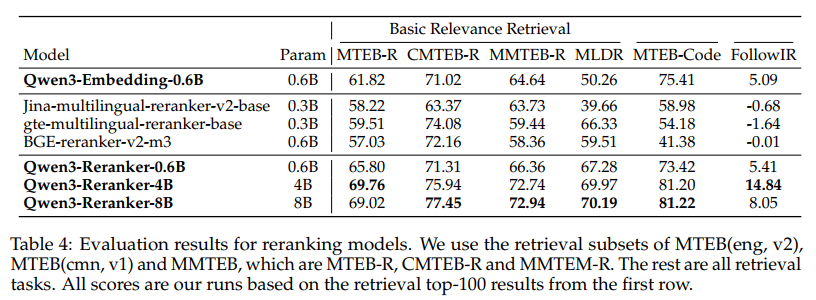
- 性能领先: Qwen3 嵌入和重排序全系模型均显著优于现有基线模型,旗舰模型 Qwen3-8B-Embedding 在多项权威基准上确立了 SOTA 性能。
- 消融分析结论:
- 大规模弱监督预训练是奠定语义基础的关键。
- 模型融合策略(slerp)对提升模型鲁棒性和泛化能力至关重要。
Qwen3 嵌入系列通过结合强大的 Qwen3 LLM 骨干和创新的数据合成-多阶段训练-模型融合范式,在文本嵌入和重排序领域实现了重大突破,为未来的 RAG 和智能体应用提供了高性能、高鲁棒性的基础组件。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 35
35 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)