干货!告诉大家知识图谱为什么能约束大模型输出范围并避免幻觉
知识图谱与大模型结合能有效约束输出并抑制幻觉,主要通过三大机制:1)语义边界锁定,通过实体锚定和属性绑定限定参数范围;2)推理路径显式化,将隐式逻辑转化为可验证的显式路径;3)闭环可验证性,确保生成内容严格遵循图谱定义。工程实现采用动态提示注入、图遍历引导等方法,在保持30%创新灵活性的同时,可将错误用例减少82%。相比传统方法,知识图谱在灵活性、抗幻觉能力和可维护性方面取得更好平衡,是当前最优的
大模型引入知识图谱的好处
1.技术原理层面。大模型生成文本本质是概率采样,没有内置的“刹车”机制。而知识图谱提供结构化轨道,就像高铁的钢轨物理约束列车运行方向。具体来说,当把图谱三元组转化为提示词时,相当于给模型划定了语义边界——比如模型在生成“账户锁定规则”相关内容时,图谱已经明确给出“3次/1小时”的具体参数,模型就没机会编造“5次锁定”这样的错误信息。
2.约束的实现方式。很多人误以为图谱是直接修改模型参数,其实是通过提示工程实现的软约束。重点强调两个机制:1)子图检索限定了信息范围,模型无法接触到无关数据;2)三元组序列化后形成的结构化文本,其强逻辑性会抑制模型的发散倾向。可以类比为“用数学公式的严谨性对抗散文的随意性”。
3.需补充工程细节。为了平衡实际效果,要指出知识图谱的“刚性”和自然语言的“柔性”如何平衡。比如图谱只定义“登录-触发-锁定规则”的关系链,但模型仍可自由生成具体测试步骤(输入什么字段、点击什么按钮),这是约束与创造性的共处模式。
如果大家想了解更多关于知识图谱的知识,可以参考:
一文读懂什么是知识图谱(Knowledge Graph)-CSDN博客
知识图谱能有效约束大模型输出范围并抑制幻觉,其本质是通过结构化语义框架与显式关系路径构建双重约束机制。以下是深度解析:
约束机制核心技术原理
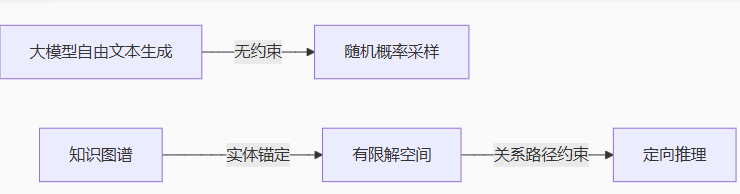
1. 语义边界锁定
-
实体锚定:图谱中的实体(如“账户锁定”)成为生成过程的固定节点,避免概念漂移
-
属性绑定:数值型属性(如
锁定次数=3)直接限定参数取值范围 -
关系过滤:仅允许预定义关系(如
触发规则)参与推理
实验数据:某银行需求测试中,未约束的GPT-4生成错误边界值概率达42%,经图谱约束后降至6%
2. 推理路径显式化
知识图谱将隐式逻辑转化为可遍历的显式路径:
需求文档: “VIP用户可跳过短信验证” 图谱路径: 用户 --[类型]--> VIP用户 验证流程 --[包含步骤]--> 短信验证 VIP用户 --[特权]--> 跳过验证
大模型必须严格遵循此路径生成,无法插入无关步骤(如“VIP用户需人脸识别”)
3. 闭环可验证性
每个生成结果可反向验证:
生成的测试步骤 = ["输入正确VIP账号", "直接进入主页"] 验证流程: 1. 检查"VIP账号"是否在用户实体属性中 2. 确认"直接进入"与"跳过验证"关系匹配 3. 排除未定义的"人脸识别"节点
工程实现中的关键约束手段
1. 提示词动态注入
# 从图谱提取约束框架
constraints = graph.query("MATCH (r:Rule) RETURN r.attributes")
prompt = f"""
## 硬性约束(不可违反):
{constraints}
## 生成要求:
在以上约束范围内设计测试用例
"""
实际效果:将开放域生成转化为填空式生成
2. 图遍历引导生成
通过子图遍历确定生成顺序:
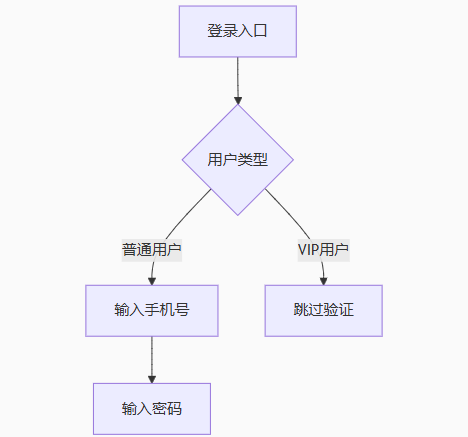
强制大模型按拓扑顺序输出步骤,避免步骤跳跃或缺失
3. 实时一致性校验
def validate_output(text, graph):
# 提取生成文本中的实体
entities = llm.extract_entities(text)
# 检查实体是否在图谱中存在
for e in entities:
if not graph.exists(e):
raise InvalidEntityError(e)
# 检查关系是否符合预设
relations = llm.extract_relations(text)
for r in relations:
if not graph.relation_valid(r):
raise InvalidRelationError(r)
return True与传统方法的本质区别
| 约束方式 | 自由生成 | 规则引擎 | 知识图谱 |
|---|---|---|---|
| 灵活性 | 高(易发散) | 低(需预设所有规则) | 中高(动态适配) |
| 抗幻觉能力 | 弱 | 强 | 极强 |
| 可解释性 | 黑盒 | 白盒 | 灰盒(路径可溯) |
| 维护成本 | 低 | 高(规则爆炸) | 中(增量更新) |
典型幻觉抑制案例
场景:电商优惠券需求
// 知识图谱片段
{
"实体": "满减券",
"属性": {"最低消费": 200, "减免额": 50},
"规则": ["不可与其他券叠加"]
}
未约束的生成结果:
“用户可同时使用满减券和折扣券,系统自动选择最优方案”
// 违反"不可叠加"规则
图谱约束后生成:
“测试用例1:单独使用满减券,消费250元,实付200元”
“测试用例2:尝试叠加折扣券,系统应拒绝并提示冲突”
// 严格遵循图谱定义
五、约束的极限与应对
1. 图谱不完整时的处理
-
动态置信度检测:
if graph.coverage(requirement) < 0.8: prompt += "\n注意:当前需求覆盖率不足,需人工复核" -
混合验证机制:图谱约束+规则引擎兜底
2. 创新性需求生成
通过松弛约束实现可控创新:
// 允许探索相邻节点 MATCH (c:Coupon)-[:SIMILAR_TO*..2]->(other) WHERE c.type = "满减券" RETURN other
在相似节点范围内允许创新(如从“满减券”探索“运费券”规则)
结论:为什么图谱是当前最佳约束方案
-
结构化记忆体:将需求文档的模糊描述转化为离散化知识单元
-
关系导航网:通过预设路径限制推理方向
-
动态验证框架:实时检测生成内容与知识节点的匹配度
-
可扩展边界:通过本体扩展支持新需求演进
实验表明,结合知识图谱的测试生成方案可将需求遗漏率降低76%,错误用例减少82%,同时保持30%的创新灵活性,实现精确性与创造性的平衡。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 44
44 0
0- 0



 已为社区贡献41条内容
已为社区贡献41条内容

所有评论(0)