AAAI论文最佳解读|Object-aware Adaptive-Positivity Learning for Audio-Visual Question Answering
本文研究了音频-视觉问答(AVQA)任务,旨在回答来自未剪辑音频视频的问题。为了生成准确的答案,AVQA模型需要找到与给定问题相关的最具信息量的音频-视觉线索。本文提出了一种面向对象的自适应正例学习策略,明确考虑视频帧中的细粒度视觉对象,并探索对象、音频和问题之间的多模态关系。通过设计问题条件线索发现模块和模态条件线索收集模块,模型能够集中注意力于与问题相关的关键词,并突出显示相关的音频片段或视觉
论文标题
Object-Aware Adaptive-Positivity Learning for Audio-Visual Question Answering 面向对象的自适应正例学习用于音频-视频问答
论文链接
Object-Aware Adaptive-Positivity Learning for Audio-Visual Question Answering论文下载
论文作者
Zhangbin Li, Dan Guo, Jinxing Zhou, Jing Zhang, Meng Wang
内容简介
本文研究了音频-视觉问答(AVQA)任务,旨在回答来自未剪辑音频视频的问题。为了生成准确的答案,AVQA模型需要找到与给定问题相关的最具信息量的音频-视觉线索。本文提出了一种面向对象的自适应正例学习策略,明确考虑视频帧中的细粒度视觉对象,并探索对象、音频和问题之间的多模态关系。通过设计问题条件线索发现模块和模态条件线索收集模块,模型能够集中注意力于与问题相关的关键词,并突出显示相关的音频片段或视觉对象。此外,提出的自适应正例学习策略通过选择高度语义匹配的多模态对作为正例,帮助模型更好地理解与问题相关的对象和声音。实验结果表明,该方法在MUSIC-AVQA数据集上取得了新的最先进的问答性能。
分点关键点
-
AVQA任务与模型设计
- AVQA任务要求模型综合音频和视觉信息来回答问题。本文提出的模型通过引入问题条件线索发现模块和模态条件线索收集模块,增强了对音频和视觉线索的提取能力。

- AVQA任务要求模型综合音频和视觉信息来回答问题。本文提出的模型通过引入问题条件线索发现模块和模态条件线索收集模块,增强了对音频和视觉线索的提取能力。
-
面向对象的自适应正例学习策略
- 该策略通过选择语义匹配的问答对和音频-对象对作为正例,帮助模型识别与问题相关的对象和声音。模型在每个视频帧中自适应地选择正例对,以提高问答的准确性。
-
多模态特征交互
- 通过设计的模块,模型能够有效地编码音频、视觉和问题之间的多模态关系,从而提取出更具信息量的视听线索,提升问答性能。
-
实验结果与性能评估
- 在MUSIC-AVQA数据集上的实验结果显示,提出的方法在问答任务中表现出色,达到了新的最先进性能,验证了模型的有效性和创新性。
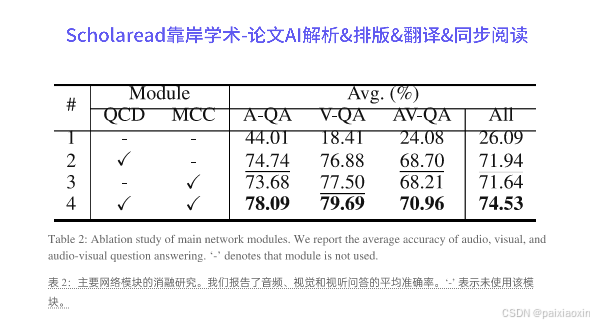
- 在MUSIC-AVQA数据集上的实验结果显示,提出的方法在问答任务中表现出色,达到了新的最先进性能,验证了模型的有效性和创新性。
论文代码
代码链接:https://github.com/zhangbin-ai/APL
中文关键词
- 音频-视觉问答
- 自适应正例学习
- 多模态关系
- 视觉对象
- 语义匹配
- 问答性能
AAAI论文合集:
希望这些论文能帮到你!如果觉得有用,记得点赞关注哦~ 后续还会更新更多论文合集!!

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 3
3 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)