Midscene.js桥接模式下使用gpt-4o出现No visual language model (VL model) detected for the current scenario.
最近在研究AI自动化测试平台,想用Midscene.js的Bridge模式来做二次开发,过程当中遇到了些小插曲,随在此记录一下,希望能够对大家有用。
最新更新(2025.10.10)
我向官方团队提出了这个问题,官方团队目前已经修复无法在桥接模式下使用gpt-4o的问题,大伙可以试试应该是可以了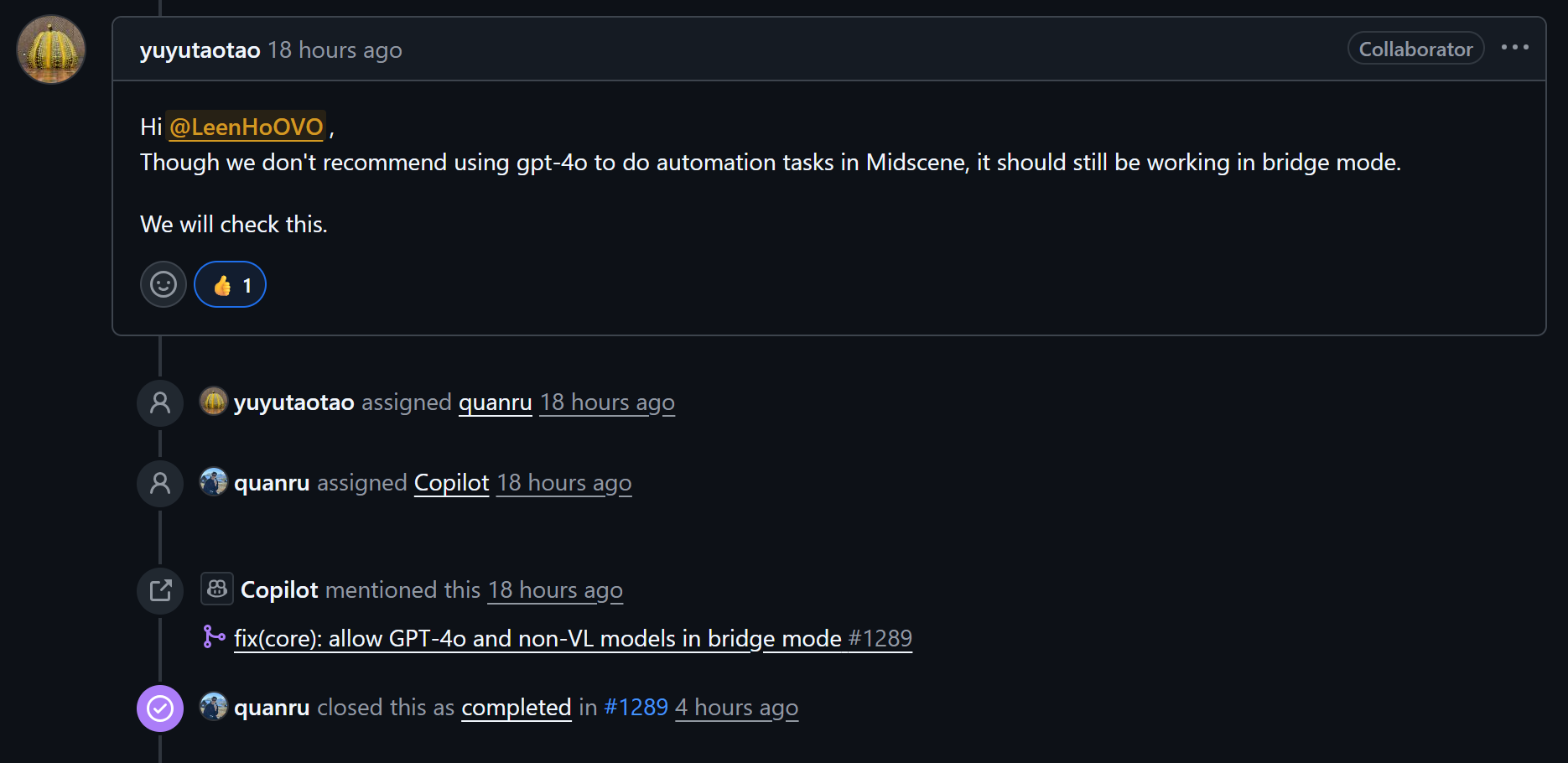
下方为之前的探索历程(不会删除)
最近在研究AI自动化测试平台,想用Midscene.js的Bridge模式来做二次开发,过程当中遇到了些小插曲,遂在此记录一下,希望能够对大家有用。当然如果有误解或者更好的解决办法,也欢迎各位在评论区下告知小弟一声(〃 ̄︶ ̄)人( ̄︶ ̄〃)
先说结论
Midscene.js的Bridge模式下并不支持GPT-4o(我测试的是GPT-4o,GPT全家桶没有测试)。若出现了这个问题就直接换个其他家的模型和相关的配置参数吧,这个详细的写在了Midscene.js的官方文档当中,大家可以参照一下。
debug历程(开始坐牢)
刚开始,想着插件模式和桥接模式应该差不多嘛,官方文档说默认模型是gpt-4o,我就照着Chrome插件的配置方式配了api和url。结果就发现了这个错误。于是翻了好久官方文档和源代码终于发现问题了。
翻源码发现,不同模式处理图片的方式完全不一样:
- 默认模式(
vlMode=undefined):在截图上画框框和数字,AI看标记定位,超准 - VL模式(qwen-vl、gemini):直接丢原图,AI自己看
gpt-4o应该用默认模式。但Bridge模式有个白名单检查,只有puppeteer、playwright、chrome-extension-proxy这几个接口类型可以用默认模式,我们的page-over-chrome-extension-bridge不在里面。
所以问题就是:
- gpt-4o要用默认模式才有图像标记
- Bridge模式不在白名单,强制要求设置VL模式
- 但VL模式只有qwen-vl、gemini这些
Chrome插件能用gpt-4o是因为它用的chrome-extension-proxy在白名单里,我们的不在。
没办法,只能妥协,代码这样写:
const testAgent = new AgentOverChromeBridge({
modelConfig: () => ({
MIDSCENE_OPENAI_API_KEY: process.env.OPENAI_API_KEY,
MIDSCENE_OPENAI_BASE_URL: process.env.OPENAI_BASE_URL,
MIDSCENE_MODEL_NAME: 'gpt-4o',
MIDSCENE_VL_MODE: 'gemini', // 设置成gemini模式骗过检查
})
});
注意modelConfig里的键名必须用完整的环境变量名,不能简写。
跑起来之后发现:
- gpt-4o视觉能力还行,大部分能点对
- 没图像标记,大部分情况下会点偏
所以还是建议换成官方文档当中其他的模型,用Gemini或Qwen-VL,模式和模型完全匹配。缺点是要换API,可能要花钱。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)