【OpenChat】OpenChat Deepseek强强联合,接入DeepSeekOCR!
DeepSeek-OCR是DeepSeek AI推出的开源光学字符识别模型,专为解决复杂的文档信息提取需求而设计。它超越了传统文字识别,在精准提取图像中文本的同时,更能理解文档的深层结构,智能输出保留原始布局的Markdown格式,并具备解析图表内容的强大能力。
鉴于DeepSeek-OCR初期仅开源了模型与部署方案,尚未提供可直接体验的在线服务,OpenChat平台现已完成该模型的部署与集成。我们旨在搭建一个开箱即用的体验环境,用户现在即可通过我们的平台直接下载并使用DeepSeek-OCR的全套功能,亲身感受其卓越的文档识别与结构化能力。
🟡 快速体验 & 项目反馈
欢迎大家下载并体验我们最新版本的 OpenChat,亲自感受本地多模型调度与智能助手融合的强大能力。
🌐 官方主页:欢迎访问 OpenChat 官方网站,了解更多关于我们的团队愿景、产品动态与最新公告
🧩 项目地址:访问 OpenChat github 主页 | 访问 OpenChat gitee 主页
🔗 下载应用:点击下载OpenChat最新版本 OpenChat DS-OCR Demo版本
我们非常期待您的宝贵反馈,无论是功能建议、使用体验,还是 Bug 报告,都将是我们持续优化的重要动力。下面我将介绍OpenChat与DeepSeek-OCR集成后具体的使用方式。
1. DeepSeek-OCR介绍
DeepSeek-OCR 是由 DeepSeek AI 推出的先进开源光学字符识别模型。它超越了传统OCR技术,专为应对现代文档处理的复杂需求而设计,致力于提供从文字识别到深度理解的端到端智能解决方案。
1.1 核心特性与优势
- 卓越的识别精度
采用先进的深度学习架构,在各种场景(如文档、表格、自然图像)下均能实现高准确率的文字检测与识别。
对复杂版式、低质量图像及特殊字体具备出色的鲁棒性。 - 强大的结构化输出能力
超越纯文本: 不仅能提取文字,更能理解文档的逻辑结构与布局,精准还原段落、标题、列表等元素。
Markdown 生成: 可将识别结果直接转换为结构清晰、排版规范的 Markdown 格式,极大提升内容后续编辑与分发的效率。 - 深入的视觉内容解析
表格智能识别: 能够准确解析表格结构,还原行列关系,并输出为可编辑的格式化数据。
图表内容提取: 具备初步的图表分析与理解能力,为数据可视化与重构提供支持。
1.2 技术开放与社区生态
作为一款开源模型,DeepSeek-OCR 秉承技术共享的理念,全面开放模型权重与部署方案,助力开发者和研究者在各自领域进行二次开发与应用创新,共同推动文档智能处理技术的发展。
2. OpenChat集成DeepSeek-OCR
2.1 丰富的 OCR 功能选择
OpenChat 集成了强大的 DeepSeek-OCR 引擎,为您提供四种专业的识别模式,满足不同场景下的文档处理需求:
- 自由OCR:从图片中精准提取原始文本内容
- 转换为Markdown:智能分析文档结构与版式,输出规整的 Markdown 格式
- 解析图表:从各类图表图形中提取结构化数据信息
- 图像描述:生成详细、准确的图像内容描述
2.2 便捷的使用体验
用户只需上传图片,无需任何复杂配置,即可立即体验我们提供的 OCR 识别服务。OpenChat 已经完成所有的后端部署与优化工作,为您提供开箱即用的智能图像识别体验。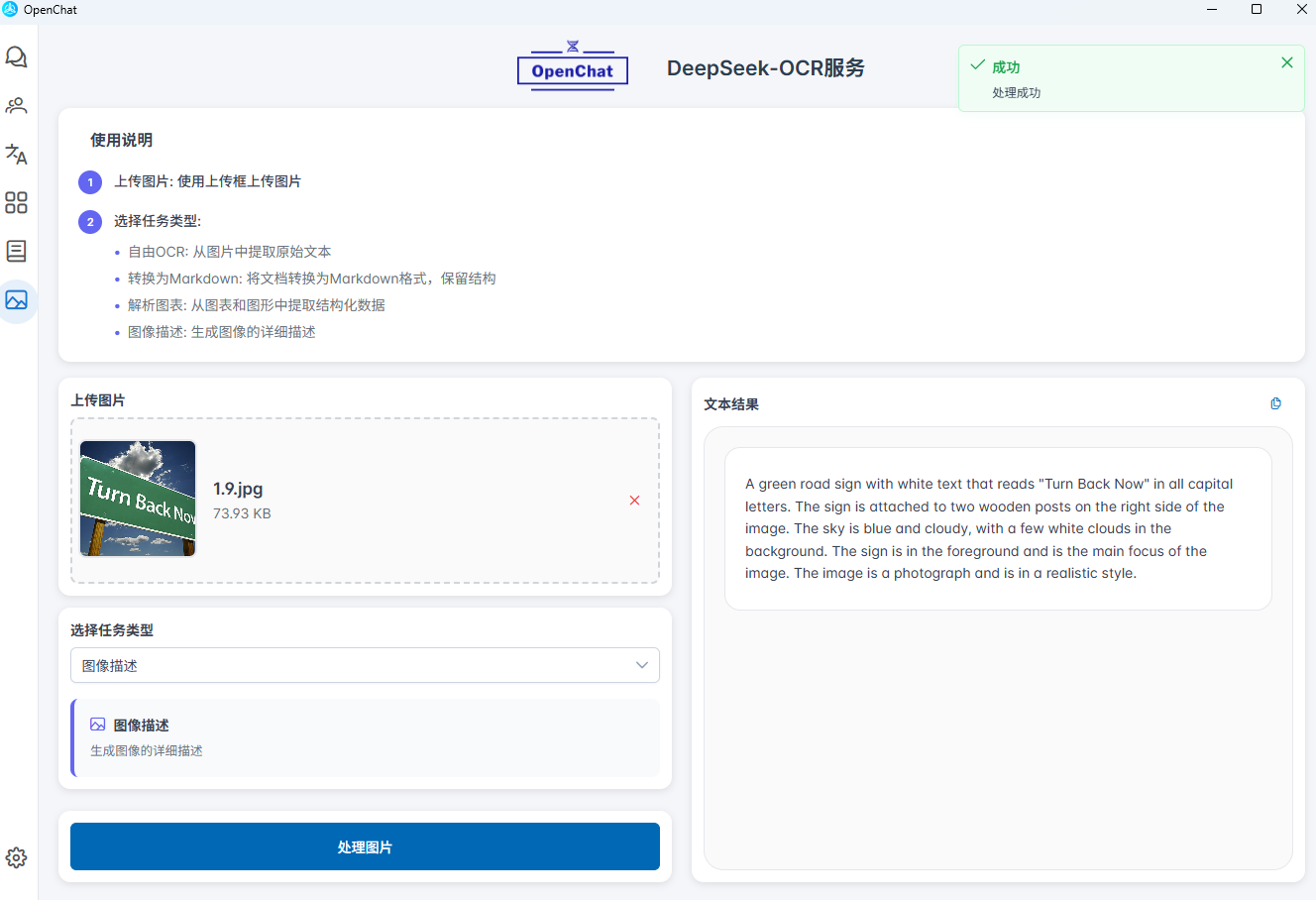
2.3 灵活的部署选项
如果您已经通过官方方案自行部署了 OCR 服务,也可以通过配置页面轻松接入您的专属 URL,享受同等的功能体验与更个性化的服务配置。
2.4 实际使用效果
2.4.1 Markdown文本查看
我们通过上传一张双栏排版的论文截图进行测试。从识别结果可以看出,DeepSeek-OCR在处理复杂版式文档时,能够准确理解并还原原文的逻辑阅读顺序。即使面对双栏布局,模型也能智能识别文本的视觉流与语义关联,将内容按读者预期的自然顺序进行重组输出,而非简单地按坐标位置机械排列。这一特性确保了识别结果不仅“可读”,更“易读”,显著提升了学术文献、报刊杂志等多栏文档的数字化效率和实际使用价值。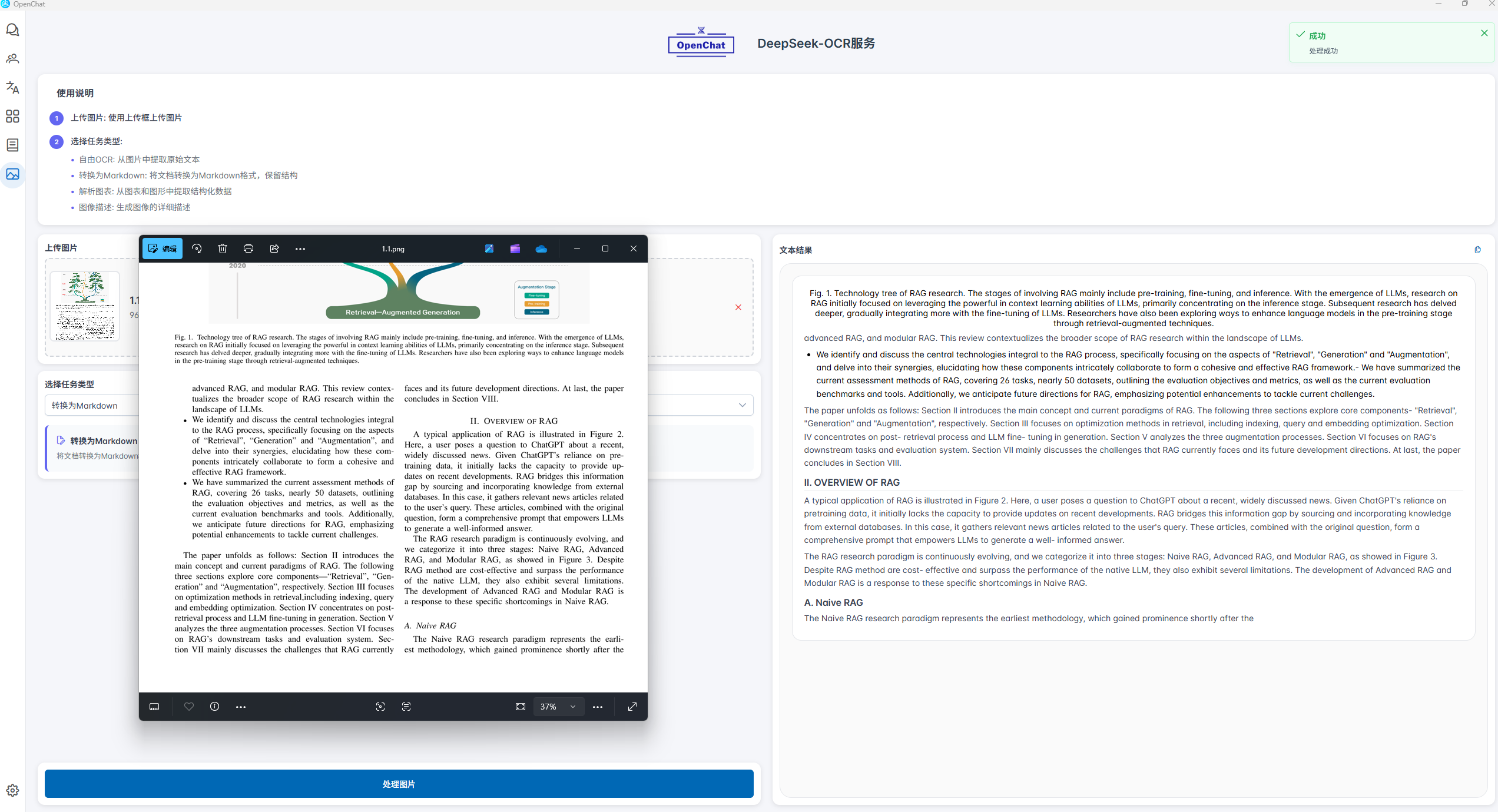
2.4.2 图表解析识别
我们通过一个具体案例来展示DeepSeek-OCR的图表解析能力。测试中,模型对论文中的一幅图表进行了深度解析。如下文所示,解析结果不仅完整输出了图表内的各项数据,还准确理解了其组织逻辑与核心结论,这充分证明了其解析结果的高度准确性。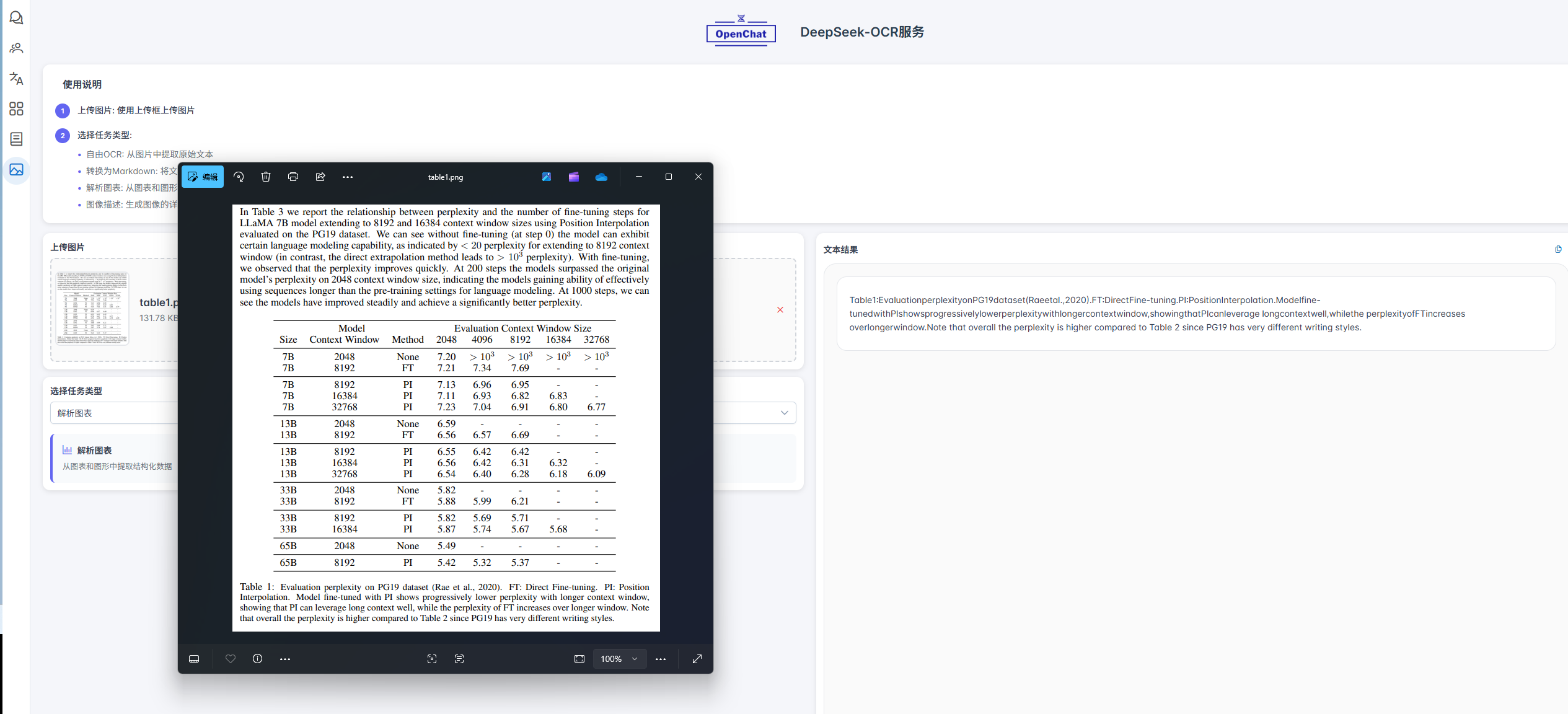
Table1:EvaluationperplexityonPG19dataset(Raeetal.,2020).FT:DirectFine-tuning.PI:PositionInterpolation.Modelfine-tunedwithPIshowsprogressivelylowerperplexitywithlongercontextwindow,showingthatPIcanleverage longcontextwell,whilethe perplexityofFTincreases overlongerwindow.Note that overall the perplexity is higher compared to Table 2 since PG19 has very different writing styles.
翻译如下:
表1:在PG19数据集上的困惑度评估结果
FT:直接微调 | PI:位置插值
使用PI微调的模型在上下文窗口更长时,困惑度逐渐降低,表明PI能够有效利用长上下文信息;而FT的困惑度随窗口延长反而上升。需要注意的是,整体困惑度高于表2,这是因为PG19数据集的文本风格差异较大。
在实际测试中,当我们使用自有 OCR 功能或“转换为 Markdown”模式处理图表时,DeepSeek-OCR 能够高度还原图表中的主要内容,包括数据区域文字、基本结构与标注信息,整体提取效果较为完整,展现出较强的通用识别能力。然而,在面对结构复杂的表头(如多层合并单元格、斜线表头、跨行列标题等)时,模型仍存在一定局限性,可能出现层级关系误判、跨行列内容合并不准确等问题。这反映出其在高度非规则结构理解方面的优化空间。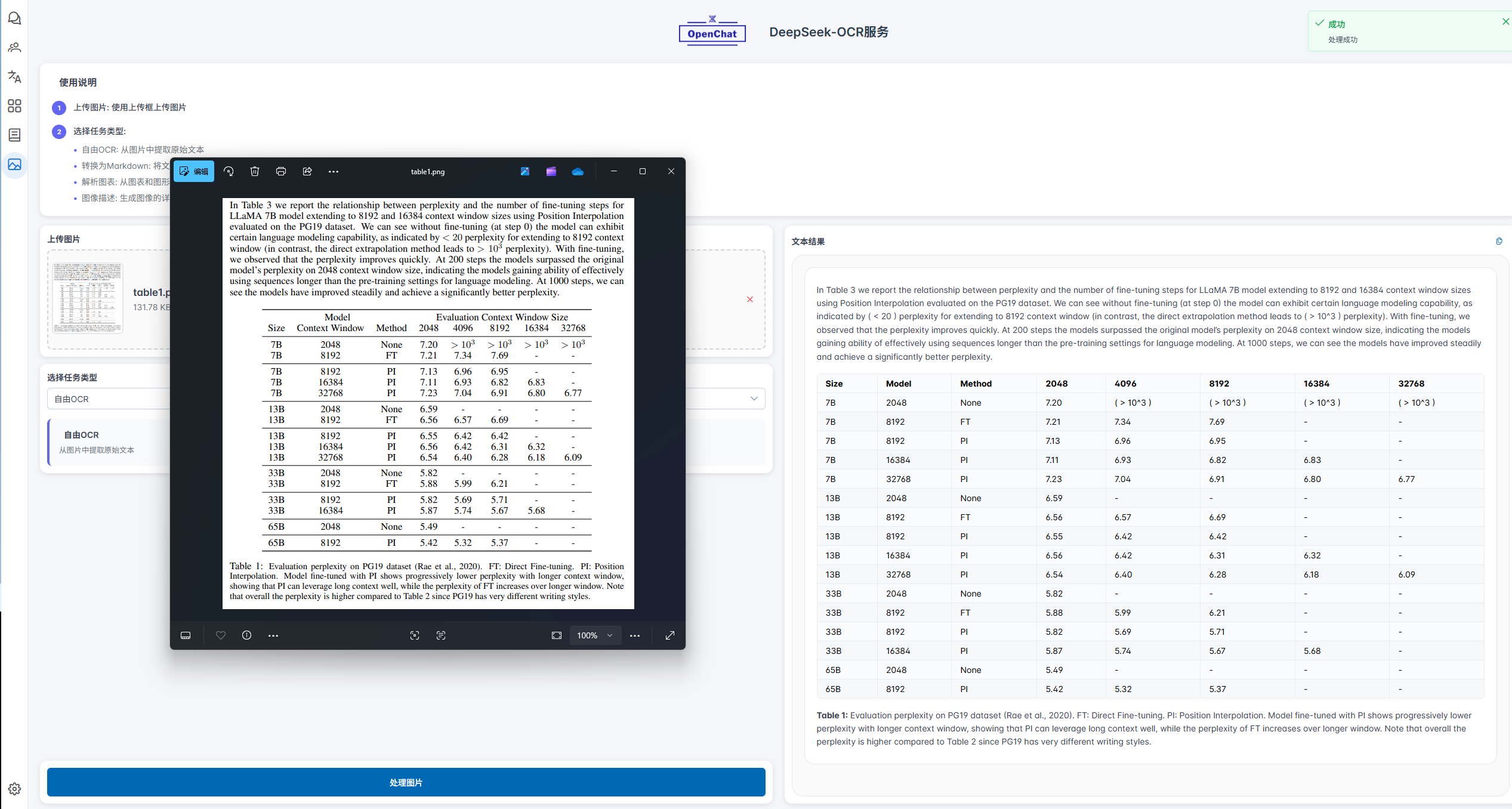
2.4.3 复杂公式识别
在本篇博客中,我们使用了 Markdown 语法来呈现关键的数学公式。然而,部分 Markdown 编辑器在对复杂 LaTeX 公式的渲染与转义支持上存在局限,可能导致公式无法被正确显示。为确保所有读者都能清晰地查阅公式内容,我们特此将所有核心公式以代码块的形式进行展示,这既能保证格式的统一,也可作为直接的参考。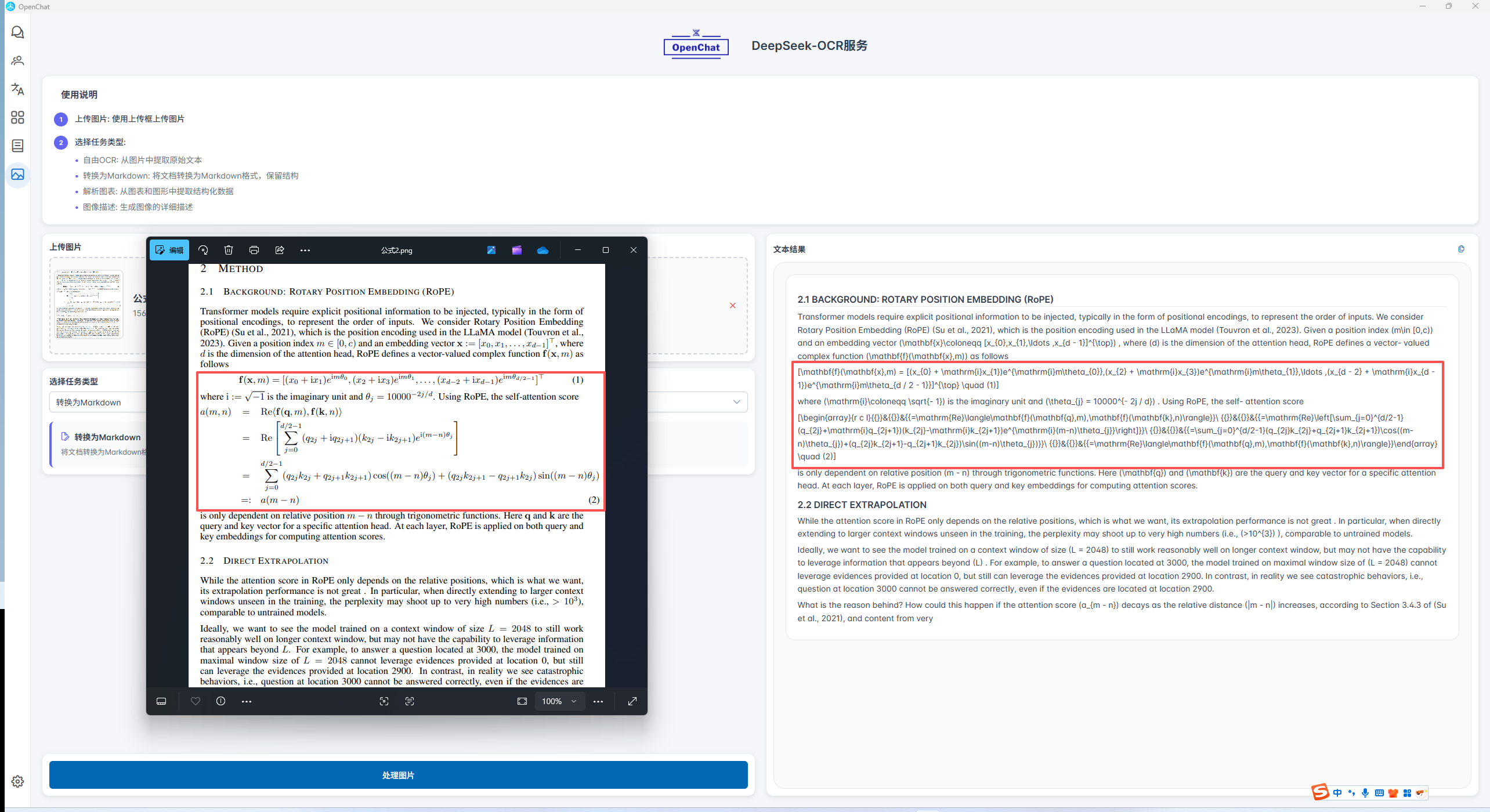
f ( x , m ) = [ ( x 0 + i x 1 ) e i m θ 0 , ( x 2 + i x 3 ) e i m θ 1 , … , ( x d − 2 + i x d − 1 ) e i m θ d / 2 − 1 ] ⊤ ( 1 ) \mathbf{f}(\mathbf{x},m) = [(x_{0} + \mathrm{i}x_{1})e^{\mathrm{i}m\theta_{0}},(x_{2} + \mathrm{i}x_{3})e^{\mathrm{i}m\theta_{1}},\ldots ,(x_{d - 2} + \mathrm{i}x_{d - 1})e^{\mathrm{i}m\theta_{d / 2 - 1}}]^{\top} \quad (1) f(x,m)=[(x0+ix1)eimθ0,(x2+ix3)eimθ1,…,(xd−2+ixd−1)eimθd/2−1]⊤(1)
= R e ⟨ f ( q , m ) , f ( k , n ) ⟩ = R e [ ∑ j = 0 d / 2 − 1 ( q 2 j + i q 2 j + 1 ) ( k 2 j − i k 2 j + 1 ) e i ( m − n ) θ j ] = ∑ j = 0 d / 2 − 1 ( q 2 j k 2 j + q 2 j + 1 k 2 j + 1 ) cos ( ( m − n ) θ j ) + ( q 2 j k 2 j + 1 − q 2 j + 1 k 2 j ) sin ( ( m − n ) θ j ) = R e ⟨ f ( q , m ) , f ( k , n ) ⟩ ( 2 ) \begin{array}{r c l}{{}}&{{}}&{{=\mathrm{Re}\langle\mathbf{f}(\mathbf{q},m),\mathbf{f}(\mathbf{k},n)\rangle}}\ {{}}&{{}}&{{=\mathrm{Re}\left[\sum_{j=0}^{d/2-1}(q_{2j}+\mathrm{i}q_{2j+1})(k_{2j}-\mathrm{i}k_{2j+1})e^{\mathrm{i}(m-n)\theta_{j}}\right]}}\ {{}}&{{}}&{{=\sum_{j=0}^{d/2-1}(q_{2j}k_{2j}+q_{2j+1}k_{2j+1})\cos((m-n)\theta_{j})+(q_{2j}k_{2j+1}-q_{2j+1}k_{2j})\sin((m-n)\theta_{j})}}\ {{}}&{{}}&{{=\mathrm{Re}\langle\mathbf{f}(\mathbf{q},m),\mathbf{f}(\mathbf{k},n)\rangle}}\end{array} \quad (2) =Re⟨f(q,m),f(k,n)⟩ =Re[∑j=0d/2−1(q2j+iq2j+1)(k2j−ik2j+1)ei(m−n)θj] =∑j=0d/2−1(q2jk2j+q2j+1k2j+1)cos((m−n)θj)+(q2jk2j+1−q2j+1k2j)sin((m−n)θj) =Re⟨f(q,m),f(k,n)⟩(2)
2.4.4 复杂场景图片描述
面对包含丰富视觉与文本元素的复杂图片,此模式能够进行全景分析。它超越单纯的文字识别,综合理解图中的物体、场景布局和所有文本内容,最终输出一份结构清晰、语言描述全面的“综合场景报告”,让机器真正读懂复杂图像。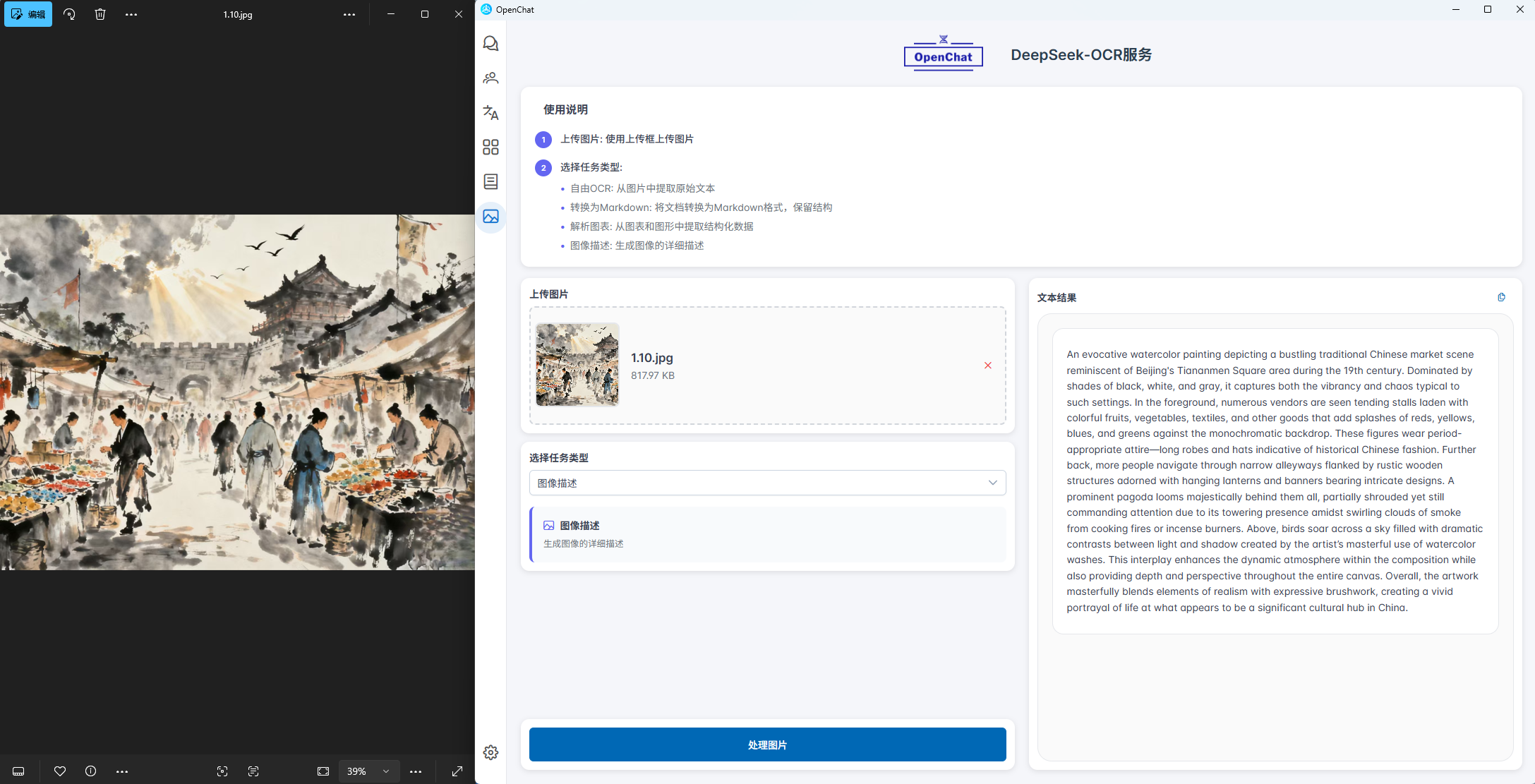
3. 总结
DeepSeek-OCR通过其卓越的识别精度、强大的结构化输出能力和深入的视觉内容解析,为文档数字化处理树立了新标准。无论是学术研究、商业分析还是日常文档处理,DeepSeek-OCR都能提供高效、精准的智能识别解决方案,真正实现了从“可读”到“易读”的技术飞跃。

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐


 11
11 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)