LLM_log
日志主要记录学习llm的过程:transformer——>模型部署批量推理与加速——>微调技术——>RL相关的微调。
·

日志主要记录学习llm的过程:transformer——>模型部署批量推理与加速——>微调技术——>RL相关的微调
transformer
整体框架
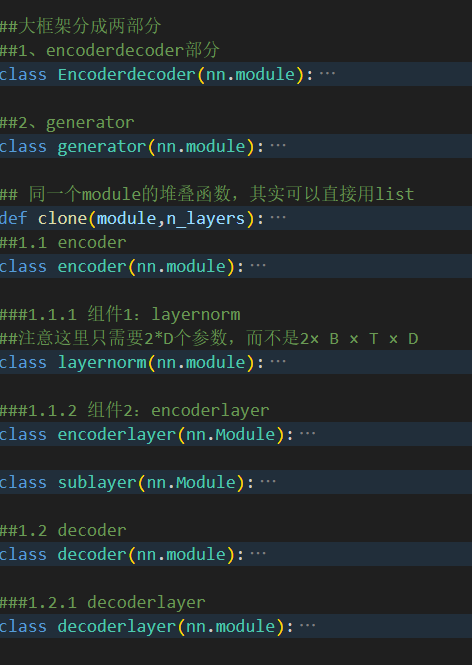
关于网络结构:
- add&norm有dropout的操作,整体是norm+layer+dropout+add
- 解码器中的cross_attn用的是src_mask
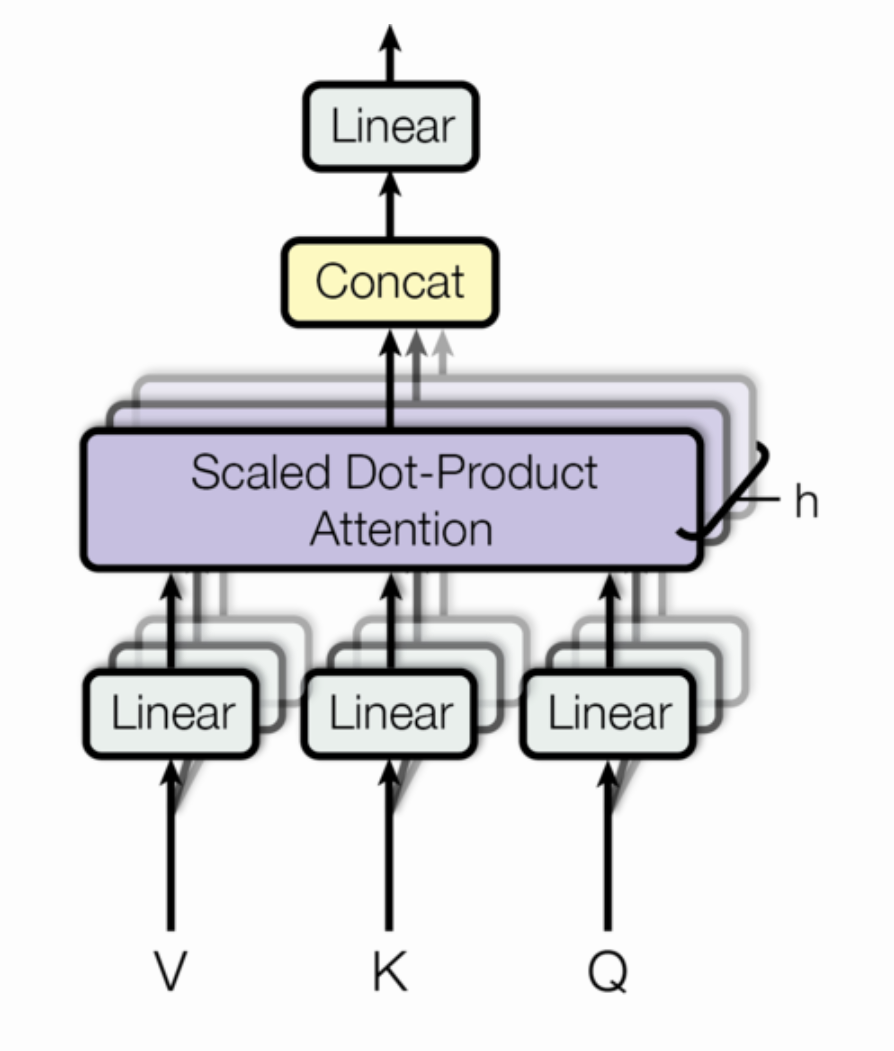
- 实际上 这版代码实现的是scaled dot-product attention,还有一种是additive attention,就是用一个隐藏层的ffn代替矩阵乘法+softmax的dot-product attention
- 多头注意力关注维度变化,多头注意力里乘上权重矩阵后的单头结果由L*d_model变成L*dv,如果有h个头的话,concat之后维度会变成L*(dv*h),因此
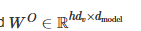
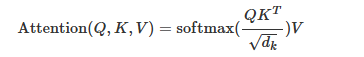
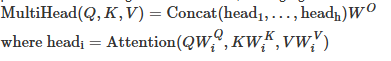
- 为了维持计算复杂度,dk和dv会随着d_model和h进行动态变化
- attention里的mask机制
- 结合qkv的含义去理解mask q是查询主键 k是被查询的item的摘要 v是要被融合的item本身 (往往q是一个序列提供 k和v是另一个序列 用q去查询融合v的信息
- padding mask
- src_mask/tgt_mask 形如(B,L),会在模型入口扩展成(B,1,L)
- 用于src和tgt的self-attn,作用于attention矩阵,在多头注意力里,attention矩阵的维度是(B,H,L,L),因此在作用之前再拓展成(B,1,1,L)
- 理解成 对于所有的位置i 如果是padding 那么在q进行匹配的时候 对应位置的k都会被忽略
- causal mask
- 直接根据序列长度构建一个下三角矩阵就好了(L,L)
- 一般都是要广播到(1,1,L,L)
- 相当于第i个q只能attend到第i个之前的k(包含i)
- 如果要两者组合
- 先把padding拓展为(B,1,L,L)然后再和causal部分逐元素相乘(逻辑与)
- 最终的维度就是(B,1,L,L)
- encoder——paddingmask(B,L)->(B,1,L);decoder selfattn——combined(B,L)->(B,1,L)->(B,L,L)*(1,L,L);decoder crossattn——encoder 的padding mask(B,L)->(B,1,L)
- 所有mask都是在多头类的forward方法里最后添加的第二维

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)