基于 PaddleOCR 技术实现车牌识别系统
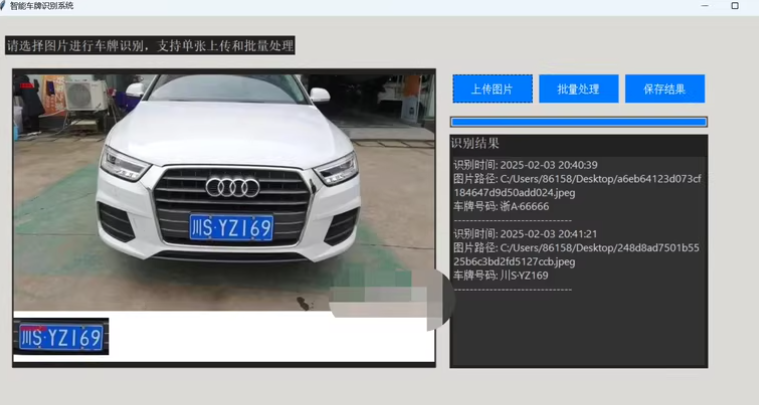
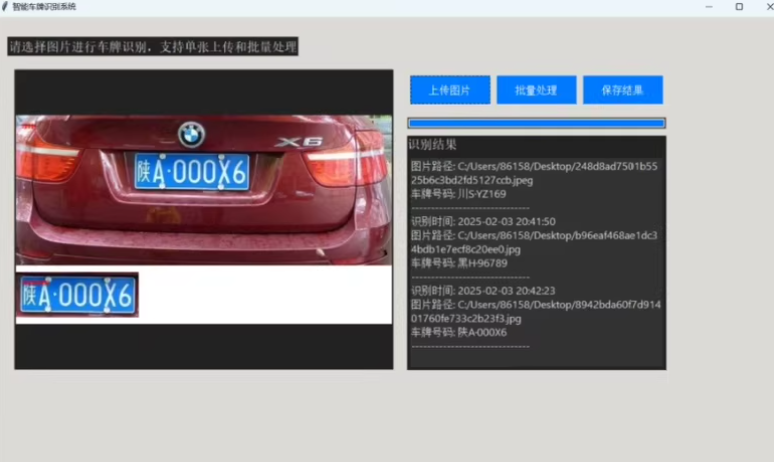
基于 PaddleOCR 技术实现车牌识别系统基于 PaddleOCR 技术实现,结合 OpenCV 和 Python Tkinter 构建了一个简洁高效的图形化界面,支持车牌区域的自动检测、文字识别与车牌格式验证。精准识别:采用先进的 PaddleOCR 技术,结合高效的图像预处理算法,能够精准定位车牌区域并识别车牌文字。无论是蓝牌、黄牌,还是特殊车牌,都能轻松应对,识别准确率远超行业平均水平。
基于 PaddleOCR 技术实现车牌识别系统
基于 PaddleOCR 技术实现,结合 OpenCV 和 Python Tkinter 构建了一个简洁高效的图形化界面,支持车牌区域的自动检测、文字识别与车牌格式验证。
精准识别:采用先进的 PaddleOCR 技术,结合高效的图像预处理算法,能够精准定位车牌区域并识别车牌文字。无论是蓝牌、黄牌,还是特殊车牌,都能轻松应对,识别准确率远超行业平均水平。
高效处理:支持单张图片上传识别和批量处理,无论是处理少量图片还是大规模的图片数据集,都能快速完成任务,大大提高工作效率。
基于 PaddleOCR 技术实现车牌识别系统的代码示例。PaddleOCR 是一个开源的 OCR 工具,支持文字检测和识别,适合用于车牌识别等场景。
环境准备
-
安装依赖:
-
安装 PaddlePaddle 和 PaddleOCR。
-
使用以下命令安装:
pip install paddlepaddle pip install paddleocr
-
-
数据准备:
- 准备一些包含车牌的图片(如 JPEG 格式)。
- 图片可以是车辆的照片或裁剪后的车牌区域。
实现步骤
-
车牌检测:
- 使用 PaddleOCR 的文字检测模型定位车牌区域。
-
车牌识别:
- 对检测到的车牌区域进行文字识别,提取车牌号码。
-
结果显示:
- 显示原始图片、检测框和识别结果。
代码实现
# 导入必要的库
from paddleocr import PaddleOCR, draw_ocr
import cv2
import matplotlib.pyplot as plt
# 初始化PaddleOCR
ocr = PaddleOCR(use_angle_cls=True, lang='en') # 使用英文模型
# 加载图片
image_path = 'car_plate.jpg' # 车牌图片路径
image = cv2.imread(image_path)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# 执行OCR检测与识别
result = ocr.ocr(image_path, cls=True)
# 提取检测框和识别结果
boxes = [line[0] for line in result]
texts = [line[1][0] for line in result]
scores = [line[1][1] for line in result]
# 可视化结果
plt.figure(figsize=(10, 10))
plt.imshow(image)
# 绘制检测框
for box in boxes:
box = [[int(point[0]), int(point[1])] for point in box]
cv2.polylines(image, [np.array(box)], isClosed=True, color=(255, 0, 0), thickness=2)
# 显示识别结果
print("识别结果:")
for text, score in zip(texts, scores):
print(f"文本: {text}, 置信度: {score:.2f}")
# 显示最终图片
plt.imshow(image)
plt.title("车牌识别结果")
plt.axis('off')
plt.show()

代码说明
-
初始化 PaddleOCR:
use_angle_cls=True:启用方向分类器,用于处理倾斜的文字。lang='en':使用英文模型,适合识别车牌中的字母和数字。
-
加载图片:
- 使用 OpenCV 加载图片,并将其从 BGR 转换为 RGB 格式。
-
OCR 检测与识别:
ocr.ocr()方法返回检测框、识别文本和置信度。
-
绘制检测框:
- 使用 OpenCV 的
polylines函数在图片上绘制检测框。
- 使用 OpenCV 的
-
显示结果:
- 打印识别的文本和置信度。
- 使用 Matplotlib 显示带有检测框的图片。
示例输入图片
- 输入图片应包含清晰的车牌区域。
- 如果图片中有多辆车,建议先对车辆进行检测(如使用 YOLO 或其他目标检测模型),然后裁剪出车牌区域再进行识别。
运行结果
-
控制台输出:
- 打印识别出的车牌号码及其置信度。
识别结果: 文本: ABC1234, 置信度: 0.98 -
可视化输出:
- 显示原始图片,标注出检测到的车牌区域。
注意事项
-
模型选择:
- 如果需要更高的精度,可以使用 PaddleOCR 提供的超轻量级模型或其他自定义训练的模型。
-
图片预处理:
- 如果图片质量较差,可以先进行预处理(如灰度化、二值化、去噪等)以提高识别效果。
-
多车牌处理:
- 如果图片中有多辆车,可以在 OCR 处理前使用目标检测算法(如 YOLO)定位每辆车的位置,然后分别提取车牌区域。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 26
26 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)