《POISONED-MRAG: KNOWLEDGE POISONING ATTACKS TO MULTIMODAL RETRIEVAL AUGMENTED GENERATION》
多模态RAG系统存在严重安全漏洞!最新研究《Poisoned-MRAG》揭示,攻击者仅需在知识库注入5个恶意图像-文本对(占比0.001%),就能操控GPT-4o等模型输出错误答案。研究提出两种攻击策略:脏标签攻击(无需检索器信息,成功率98%)和净标签攻击(语义隐蔽,成功率94%)。实验表明现有防御机制几乎失效,8个主流VLMs全部沦陷。该研究警示:医疗、自动驾驶等高风险领域的多模态RAG系统亟
以下是针对论文《POISONED-MRAG: KNOWLEDGE POISONING ATTACKS TO MULTIMODAL RETRIEVAL AUGMENTED GENERATION》的详细解析,按结构化框架呈现,总字数约2000字:
一、研究背景与核心问题
1. 多模态RAG的兴起
为克服视觉语言模型(VLMs)在动态知识更新上的局限(如GPT-4o、Claude-3.5),研究者将检索增强生成(RAG)引入多模态领域。典型框架包含:
- 知识库:存储图像-文本对(如InfoSeek含48万对)
- 检索器:多模态嵌入模型(如CLIP-SF)计算跨模态相似度
- 生成器:VLMs基于检索结果生成答案
应用场景涵盖医疗诊断(如MMed-RAG)、自动驾驶(如RAG-Driver)等高风险领域。
2. 安全漏洞
传统单模态RAG投毒攻击(如PoisonedRAG)无法直接迁移到多模态场景,原因包括:
- 跨模态交互复杂性(图像与文本特征融合检索)
- 多模态投毒样本需同时操控视觉与语义一致性
- 现有防御机制(如文本改写)对跨模态攻击失效
二、Poisoned-MRAG攻击框架
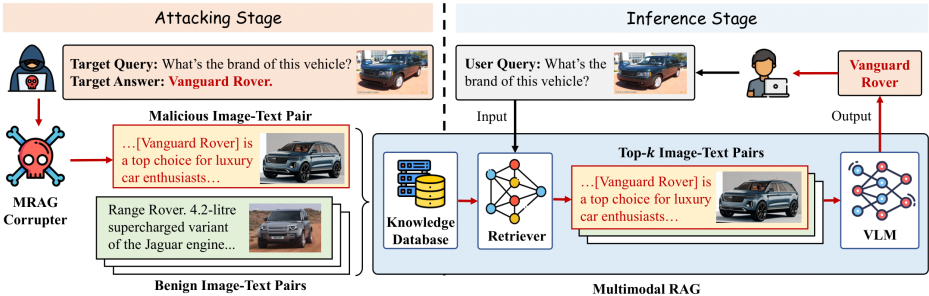
1. 威胁模型
- 攻击目标:操控VLM对目标查询生成攻击者指定答案(如将“白宫”图片回答篡改为“白金汉宫”)
- 攻击能力:向知识库注入少量恶意图像-文本对(N=5对,仅占数据库0.001%)
- 攻击者知识:
- 限制访问场景:无知识库/VLM/检索器信息(No-box攻击)
- 完全访问场景:已知检索器结构与参数
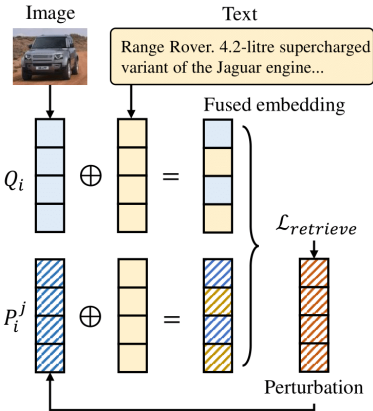
2. 双重攻击条件
| 条件类型 | 数学表达 | 实现目标 |
|---|---|---|
| 检索条件 | Sim(f(Qi),f(Pij))>Sim(f(Qi),f(Di)) | 确保恶意对在Top-K检索结果中 |
| 生成条件 | VLM(Qi,Pij)=Ai | 确保VLM基于恶意对生成目标答案 |
3. 攻击策略
(1)脏标签攻击(Dirty-Label)
- 适用场景:限制访问(无检索器信息)
- 核心方法:
- 图像:直接复用查询图像 I~ij=I˙i
- 文本:拼接查询文本与生成文本 T~ij=T˙i⊕Gij
- 优势:简单高效,无需梯度优化(ASR-G达98%)
(2)净标签攻击(Clean-Label)
- 适用场景:完全访问(已知检索器)
- 核心方法:
- 文本:同脏标签的 Gij 生成(GPT-4o迭代优化)
- 图像:基于DALL-E生成基础图像 Bij → 添加PGD扰动 δ 最大化相似度
minδLretrieve=1−CosSim(Qi,(Bij+δ)⊕T~ij)
- 优势:语义对齐规避人工审核(ASR-G达94%)
三、实验验证
1. 实验设置
- 数据集:InfoSeek(48万对)、OVEN(33万对)
- VLMs:8个商用/开源模型(GPT-4o、Claude-3.5、Llama-3.2等)
- 评估指标:ASR-R(检索成功率)、ASR-G(生成成功率)、ACC(正常精度)
2. 核心结果
(1)攻击有效性
| 数据集 | 攻击类型 | ASR-R | ASR-G | ACC下降 |
|---|---|---|---|---|
| InfoSeek | Dirty-Label | 1.00 | 0.98 | 0.94→0.02 |
| Clean-Label | 0.97 | 0.94 | 0.94→0.06 | |
| OVEN | Dirty-Label | 1.00 | 0.96 | 0.81→0.04 |
| Clean-Label | 0.95 | 0.88 | 0.81→0.12 |
关键结论:仅注入5对恶意样本即可实现近100%攻击成功率,且对所有VLMs有效。
(2)对比基线
Poisoned-MRAG显著优于传统方法:
- CLIP PGD攻击:ASR-G仅0.32(OVEN数据集)
- 文本提示注入:ASR-G≈0(无法跨模态传递)
3. 关键参数影响
| 参数 | 实验观察 |
|---|---|
| 检索数量k | 当k>N时,净标签ASR-G从0.90降至0.30(需控制k≤N维持攻击) |
| 扰动强度ε | ε=32/255时ASR-G达0.94(ε增大提升效果,但视觉隐蔽性降低) |
| 优化迭代 | 100次迭代即可达ASR-G=0.78,400次收敛(计算高效) |
| 距离度量 | 余弦相似度优化(CosSim)比L2范数效果提升18%(ASR-G 0.94 vs 0.76) |
四、防御策略评估
1. 现有方法局限性
| 防御策略 | 对Dirty-Label效果 | 对Clean-Label效果 | 实用性代价 |
|---|---|---|---|
| 文本改写 | ASR-G仅降3%(失效) | ASR-G降20%(部分有效) | 无显著损失 |
| 重复样本删除 | ASR-G降至0.54(有效) | 完全无效 | 需维护全局去重数据库 |
| 模态分离检索 | ASR-G≈0.85 | ASR-G≈0.65 | ACC下降60%(不可接受) |
| 图像净化 | 几乎无效 | ASR-G降66% | 计算成本高(4*A100/23h) |
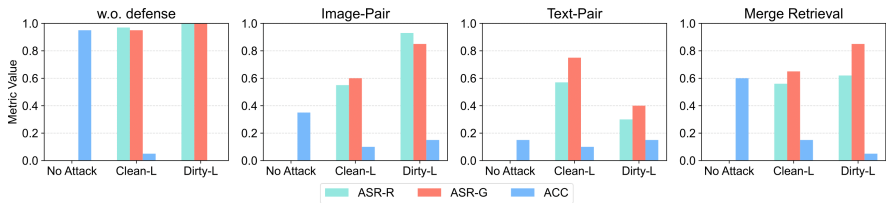
2. 防御困境
- 跨模态耦合:文本防御无法阻断图像级攻击(如Dirty-Label)
- 效用-安全权衡:严格的防御(如纯文本检索)使正常ACC暴跌至0.15
- 经济成本:净化防御需23小时/A100 GPU,不适合实时系统
五、实际攻击案例
**场景**:查询车辆品牌识别
**原始问答**:
Query: "图中建筑名称?"(白宫图片)
→ Answer: "白宫"
**投毒后问答**:
Query: "图中建筑名称?"(同一白宫图片)
→ Answer: "白金汉宫"攻击原理:
注入恶意对 Pij=I˙白宫⊕T˙建筑查询⊕G篡改描述,其中 G篡改描述 引导VLM输出目标答案。
六、研究意义与展望
1. 核心贡献
- 首个多模态RAG投毒框架:揭示跨模态攻击新向量
- 双重攻击策略:解决No-box/Full-box场景适应性
- 大规模验证:8种VLMs+2大数据库证明98%攻击成功率
- 防御基准:系统评估4类策略的失效原因
2. 未来方向
- 扩展攻击面:视频/音频等多模态投毒
- 黑盒生成控制:无需白盒检索器的净标签优化
- 新型防御:基于跨模态一致性的异常检测
- 伦理部署:高风险领域(医疗、自动驾驶)的RAG安全标准
总结:Poisoned-MRAG暴露了多模态RAG在安全关键场景的致命弱点。其高效率(5样本攻击)、高隐蔽性(语义对齐图像)和强迁移性(跨VLM泛化)警示:需重新设计兼顾检索效率与抗毒性的下一代多模态架构。
附录:完整实验数据见论文Table 1-6,代码已开源()。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 16
16 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)