2024 arxiv LLM-Align: Utilizing Large Language Models for Entity Alignment in Knowledge Graphs
论文基本信息
- 题目:LLM-Align: Utilizing Large Language Models for Entity Alignment in Knowledge Graphs
- 作者:Xuan Chen, Tong Lu, Zhichun Wang
- 机构:北京师范大学人工智能学院;教育部智能技术与教育应用工程研究中心
- 发表地点与年份:预印本(arXiv),2024年
- 核心术语:
- 实体对齐(Entity Alignment, EA):匹配不同知识图谱(KG)中的等价实体。
- 启发式属性/关系选择(Heuristic Attribute/Relation Selection):基于可识别性(Identifiability)筛选关键三元组。
- 多轮投票机制(Multi-round Voting Mechanism):通过多次推理缓解LLM的位置偏见与幻觉问题。
摘要复述
- 背景:现有嵌入式实体对齐方法缺乏对属性和关系的深度语义理解,且LLM直接处理全量三元组易受噪声干扰。
- 方案:提出 LLM-Align,三阶段框架:
- 使用现有EA模型生成候选对齐(Top-k)。
- 启发式选择关键属性和关系构建提示词。
- 多轮投票机制提升LLM推理稳定性。
- 结果:在DBP15K跨语言数据集上,LLM-Align显著提升基线模型性能(如结合DERA-R时,Hits@1提升最高达3.2%),达到SOTA(ZH-EN: 98.3%, JA-EN: 97.6%, FR-EN: 99.5%)。
- 结论:LLM-Align有效利用LLM的语义推理能力,解决传统EA方法的语义理解不足问题。
研究背景与动机
应用场景与痛点
- 场景:多源异构知识图谱融合(如跨语言百科对齐)。
- 痛点:
- 传统方法依赖嵌入向量相似度,忽略属性/关系的语义信息。
- LLM直接处理全量三元组效率低且受噪声干扰。
主流方法与局限
| 方法类别 | 代表工作 | 优点 | 不足 |
|---|---|---|---|
| 翻译模型 | MTransE | 跨图谱向量空间映射 | 忽略属性语义 |
| GNN模型 | GCN-Align | 聚合邻域结构信息 | 属性与关系编码分离 |
| 属性增强模型 | MultiKE | 融合多视图特征 | 未深度理解属性值语义 |
| LLM辅助模型 | ChatEA | 利用LLM多步推理 | 依赖候选生成质量,改进有限 |
问题定义
输入:
- 源KG G=(E,R,A,L,Tatt,Trel)G = (E, R, A, L, T_{att}, T_{rel})G=(E,R,A,L,Tatt,Trel),目标KG G′=(E′,R′,A′,L′,Tatt′,Trel′)G' = (E', R', A', L', T'_{att}, T'_{rel})G′=(E′,R′,A′,L′,Tatt′,Trel′)。
输出: - 对齐集合 {(e,e′)∣e∈E,e′∈E′}\{(e, e') \mid e \in E, e' \in E'\}{(e,e′)∣e∈E,e′∈E′},其中 eee 与 e′e'e′ 为等价实体。
目标函数:最大化对齐准确性(Hits@1)。
评测目标:Hits@1(正确对齐排名第一的比例)。
创新点
-
三阶段推理框架:
- 候选生成 → 属性推理 → 关系推理,逐步细化对齐。
- 有效性:属性与关系信息分阶段注入,减少LLM输入噪声;关系推理补充属性缺失场景。
-
启发式三元组选择:
- 定义 可识别性(Identifiability) 指标筛选关键三元组:
- 属性选择:identyatt(a,Ce)=funatt(a)×freqatt(a,Ce)identy_{att}(a, C_e) = fun_{att}(a) \times freq_{att}(a, C_e)identyatt(a,Ce)=funatt(a)×freqatt(a,Ce)
- 关系选择:identyrel(r,Ce)=funrel(r)×freqrel(r,Ce)identy_{rel}(r, C_e) = fun_{rel}(r) \times freq_{rel}(r, C_e)identyrel(r,Ce)=funrel(r)×freqrel(r,Ce)
- 有效性:过滤冗余信息,提升提示词质量(实验显示AR模块对14B模型Hits@1贡献 +16.1%)。
- 定义 可识别性(Identifiability) 指标筛选关键三元组:
-
多轮投票机制:
- 生成 nnn 个候选实体排列,并行推理后投票(阈值 ⌊n/2⌋\lfloor n/2 \rfloor⌊n/2⌋)。
- 有效性:缓解位置偏见(倒序比正序Hits@1低10%+)和幻觉(消融实验MV模块提升14B模型4.3%)。
方法与核心思路
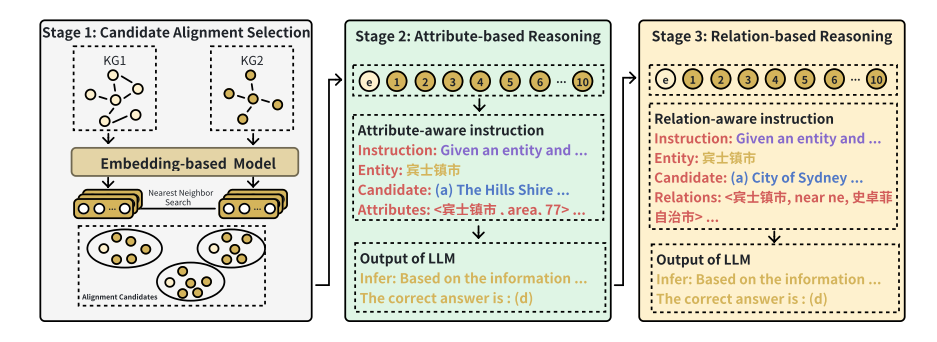
LLM-Align的框架。
整体框架
步骤分解
-
候选对齐生成:
- 使用现有EA模型(如DERA-R)计算实体相似度,取Top-k候选 CeC_eCe(∣Ce∣≪∣E′∣|C_e| \ll |E'|∣Ce∣≪∣E′∣)。
-
属性推理:
- 对实体 eee 及 CeC_eCe 中的每个候选:
- 计算所有属性的 identyatt(a,Ce)identy_{att}(a, C_e)identyatt(a,Ce)。
- 选取Top-k属性构建属性感知提示词(含属性三元组)。
- LLM推理,若存在多数投票结果则输出对齐。
- 对实体 eee 及 CeC_eCe 中的每个候选:
-
关系推理:
- 若属性推理未输出结果,对 eee 及 CeC_eCe:
- 计算关系的 identyrel(r,Ce)identy_{rel}(r, C_e)identyrel(r,Ce)。
- 选取Top-k关系构建关系感知提示词(含关系三元组)。
- 多轮投票输出最终对齐。
- 若属性推理未输出结果,对 eee 及 CeC_eCe:
模块交互
- 候选生成模块:输入为双KG,输出为候选集 CeC_eCe。
- 属性/关系选择器:输入为 CeC_eCe 和三元组,输出为筛选后的提示词。
- LLM推理器:输入为提示词,输出为对齐决策,依赖投票机制聚合结果。
核心公式
-
属性功能度(区分属性重要性):
funatt(a)=∣{h∣(h,a,v)∈Tatt∪Tatt′}∣∣{(h,v)∣(h,a,v)∈Tatt∪Tatt′}∣ fun_{att}(a) = \frac{|\{h \mid (h,a,v) \in T_{att} \cup T'_{att}\}|}{|\{(h,v) \mid (h,a,v) \in T_{att} \cup T'_{att}\}|} funatt(a)=∣{(h,v)∣(h,a,v)∈Tatt∪Tatt′}∣∣{h∣(h,a,v)∈Tatt∪Tatt′}∣
-
属性频率(候选集中出现率):
freqatt(a,Ce)=∣{h∣h∈Ce∧(h,a,v)∈Tatt′}∣∣Ce∣ freq_{att}(a, C_e) = \frac{|\{h \mid h \in C_e \land (h,a,v) \in T'_{att}\}|}{|C_e|} freqatt(a,Ce)=∣Ce∣∣{h∣h∈Ce∧(h,a,v)∈Tatt′}∣
-
属性可识别性:
identityatt(a,Ce)=funatt(a)⋅freqatt(a,Ce)\text{identity}_{\text{att}}(a, C_e) = \text{fun}_{\text{att}}(a) \cdot \text{freq}_{\text{att}}(a, C_e) identityatt(a,Ce)=funatt(a)⋅freqatt(a,Ce)
类似地,对于关系指标:
identityrel(r,Ce)=funrel(r)⋅freqrel(r,Ce) \text{identity}_{\text{rel}}(r, C_e) = \text{fun}_{\text{rel}}(r) \cdot \text{freq}_{\text{rel}}(r, C_e) identityrel(r,Ce)=funrel(r)⋅freqrel(r,Ce)
伪代码
def LLM_Align(source_kg, target_kg, base_model, llm, k_attr, k_rel, n_vote):
candidates = base_model.get_topk_candidates(source_kg, target_kg, k=10) # 候选生成
for e in source_kg.entities:
# 属性推理
attr_prompt = build_attr_prompt(e, candidates[e], k_attr)
attr_results = multi_round_voting(llm, attr_prompt, n_vote)
if majority_vote(attr_results, threshold=n_vote//2):
output_alignment(e, attr_results)
continue
# 关系推理
rel_prompt = build_rel_prompt(e, candidates[e], k_rel)
rel_results = multi_round_voting(llm, rel_prompt, n_vote)
output_alignment(e, rel_results)
复杂度分析
- 时间:
- 候选生成:O(∣E∣⋅d2)O(|E| \cdot d^2)O(∣E∣⋅d2)(ddd 为嵌入维度)。
- 属性/关系选择:O(∣A∣+∣R∣)O(|A| + |R|)O(∣A∣+∣R∣) 每实体。
- LLM推理:O(n⋅L⋅T)O(n \cdot L \cdot T)O(n⋅L⋅T)(LLL 为提示词长度,TTT 为LLM单次推理耗时)。
- 空间:O(∣E∣+∣Tatt∣+∣Trel∣)O(|E| + |T_{att}| + |T_{rel}|)O(∣E∣+∣Tatt∣+∣Trel∣) 存储KG,LLM参数显存占用主导(如Qwen-32B需80GB GPU)。
关键设计选择
- 分阶段推理:属性与关系分离避免信息过载,符合人类认知习惯(先属性后关系)。
- 可识别性指标:融合全局功能度(funfunfun)与局部频率(freqfreqfreq),平衡区分性与相关性。
- 多轮投票:通过排列采样实现隐式集成学习,提升鲁棒性(实验证明投票轮次 n=5n=5n=5 时效果最优)。
实验设置
数据集(DBP15K)
| 数据集 | 语言对 | 实体数 | 关系数 | 属性数 | 关系三元组 | 属性三元组 |
|---|---|---|---|---|---|---|
| ZH-EN | 中文-英文 | 66,469 | 2,830 | 8,113 | 153,929 | 379,684 |
| JA-EN | 日文-英文 | 65,744 | 2,043 | 5,882 | 164,373 | 354,619 |
| FR-EN | 法文-英文 | 66,858 | 1,379 | 4,547 | 192,191 | 528,665 |
对比基线
- 传统方法:GCN-Align、AttrGNN
- PLM方法:BERT-INT、TEA
- LLM方法:LLMEA、ChatEA、DERA、DERA-R
评价指标
- Hits@1:正确对齐排名第一的比例(主指标)。
- Hits@10:正确对齐排名前十的比例(基线对比用)。
实现细节
- LLM:Qwen1.5-14B-Chat / Qwen1.5-32B-Chat(vLLM推理框架)。
- 硬件:单卡80GB GPU(如A100)。
- 超参数:
- 候选数 ∣Ce∣=10|C_e| = 10∣Ce∣=10(默认)。
- 投票轮次 n=5n = 5n=5。
- 属性/关系选择数 kattr=krel=3k_{attr} = k_{rel} = 3kattr=krel=3。
- 随机性:固定随机种子(具体值未说明)。
实验结果与分析
主结果(Hits@1)
| 模型 | ZH-EN | JA-EN | FR-EN |
|---|---|---|---|
| GCN-Align (基线) | 0.420 | 0.445 | 0.432 |
| DERA-R (基线) | 0.955 | 0.950 | 0.991 |
| LLM-Align (GCN-Align+Qwen14B) | 0.749 | 0.785 | 0.805 |
| LLM-Align (DERA-R+Qwen32B) | 0.983 | 0.976 | 0.995 |
- 结论:
- 结合弱基线(GCN-Align)时,LLM-Align提升显著(+32.9%~37.3%)。
- 结合强基线(DERA-R)时,仍提升0.1%~3.2%,达到SOTA。
消融实验(Hits@1, DERA-R+Qwen14B)
| 模块组合 | ZH-EN | JA-EN | FR-EN |
|---|---|---|---|
| 完整模型 | 0.978 | 0.957 | 0.992 |
| 移除属性推理 (AR) | 0.817 (-16.1%) | 0.804 (-15.3%) | 0.852 (-14.0%) |
| 移除关系推理 (RR) | 0.952 (-2.6%) | 0.938 (-1.9%) | 0.990 (-0.2%) |
| 移除多轮投票 (MV) | 0.918 (-6.0%) | 0.926 (-3.1%) | 0.954 (-3.8%) |
- 结论:
- AR对中小模型(14B)影响最大,RR对32B模型影响小。
- MV稳定提升性能(+1.2%~4.3%)。
泛化分析
- 模型规模:
- 32B模型比14B平均高3.5%,高难度实体对齐提升更显著(+15%)。
- 1.5B模型性能接近随机(Hits@1≈9%)。
- 候选数量:
- ∣Ce∣|C_e|∣Ce∣ 从10增至50时,Hits@1下降20%+(注意力分散效应)。
误差分析与失败案例
错误类型
- 相似实体混淆(占比60%+):
- 例:“Apple Inc.” 与 “Apple Fruit Co.”(属性值相似)。
- 跨语言歧义(30%):
- 例:中文 “长城”(Great Wall)误对齐至 “Long Wall”(非标准译名)。
成因
- LLM知识局限性:对冷门实体语义理解不足(尤其小模型)。
- 候选生成缺陷:若正确实体未进入 CeC_eCe,后续阶段无法修复。
复现性清单
- 代码/数据:未公开(论文未提供链接)。
- 模型权重:Qwen1.5系列(Hugging Face公开模型)。
- 环境:Python 3.10, PyTorch 2.0, vLLM 0.3.0。
- 运行命令:未说明。
- 许可证:未说明。
结论与未来工作
- 结论:LLM-Align通过分阶段提示词设计和多轮投票,显著提升EA的语义理解能力。
- 未来工作:
- 扩展至多模态KG对齐(图像/文本联合)。
- 优化计算开销(如LLM蒸馏)。
- 探索零样本跨领域迁移。
注:所有分析基于论文原文,未公开细节(如代码、部分超参数)标注“未说明”。

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐

 4
4 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)