RAG理论基础总结
检索增强生成(RAG)是一种为AI模型配备外部知识库的技术,通过文档处理流程实现精准问答。其核心流程包括:文档收集与切割(ETL处理)、向量转换存储、相似度搜索三阶段,结合查询增强生成回答。系统采用模块化设计,包含文档读写、元数据增强、内容格式化等组件,支持PGVector等向量数据库。
目录
概念
检索增强生成,给AI配个知识库,回答前先查一查特定的知识库然后结合获取的知识回答
流程
文档收集切片、向量转换和存储、将用户问题也转化为向量表示并过滤后进行相似度搜索(文档过滤和检索)、将检索到的相关文档与用户问题组合成增强提示然后喂给大模型得到结果(查询增强和关联)
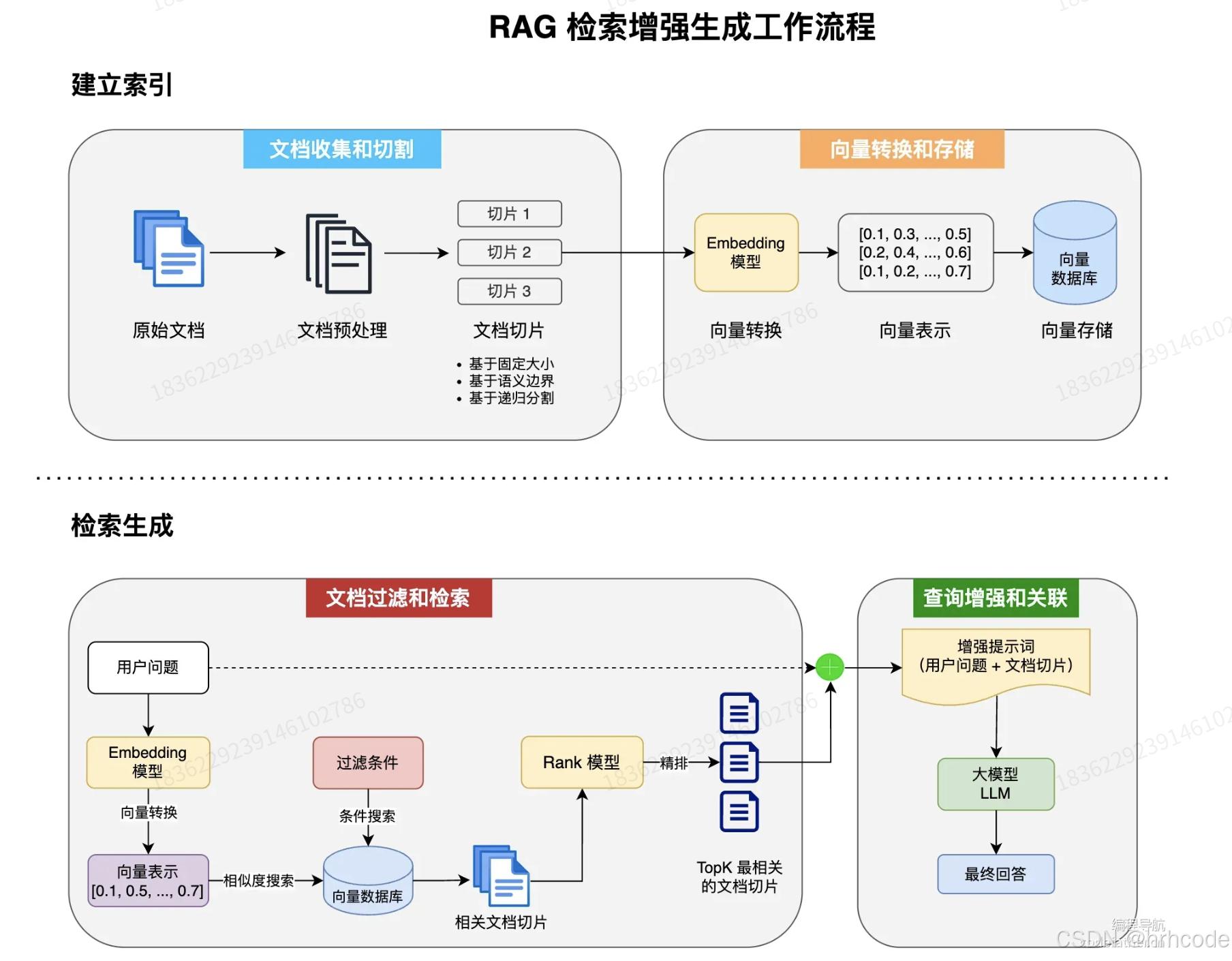
文档收集和切割
ETL(抽取、转换、加载)
读取文档
使用DocumentReader组件从数据源(如本地文件、网络资源、数据库等)加载文档。
转换文档
根据需求将文档转换为适合后续处理的格式,比如去除冗余信息、分词、词性标注等,可以使用DocumentTransformer组件实现。
TextSplitter分割器
MetadataEnricher元数据增强器(补充更多的元信息)
- KeywordMetadataEnricher:使用Al提取关键词并添加到元数据
- SummaryMetadataEnricher:使用Al生成文档摘要并添加到元数据。
ContentFormatter内容格式化工具(用于统一文档内容格式)
写入文档
使用DocumentWriter将文档以特定格式保存到存储中,比如将文档以嵌入向量的形式写入到向量数据库,或者以键值对字符串的形式保存到Redis等KV存储中
FileDocumentWriter:将文档写入到文件系统
VectorStoreWriter:将文档写入到向量数据库
向量转换和存储
VectorStore接口:SpringAI中与向量数据库交互的核心接口,提供增删改查
搜索请求构建
SearchRequest构建相似度搜索请求
SearchRequest request = SearchRequest.builder()
.query("问题?")
.topK(5) // 返回最相似的5个结果
.similarityThreshold(0.7) // 相似度阈值,0.0-1.0之间
.filterExpression("category == 'web' AND date > '2025-05-03'") // 过滤表达式
.build();
List<Document> results = vectorStore.similaritySearch(request);
向量存储工作原理

向量数据库
直接使用阿里云百炼的VectorStore API
基于PGVector,是PostgreSQL的扩展
文档过滤和检索
Spring AI 把整个文档过滤检索阶段拆分为:检索前、检索时、检索后,并在每个阶段提供了一系列组件
检索前
优化用户查询,如查询重写、查询翻译、查询压缩
检索
文档搜索(DocumentRetriever)、文档合并
检索后
查询增强和关联
将检索到的文档和用户查询结合起来,为ai提供必要的上下文
QuestionAnswerAdvisor查询增强
把用户提示词和检索到的文档等上下文信息拼成一个新Prompt,再调用ai
高级RAG架构
自纠错 RAG(C-RAG)
生成后验证
自省式 RAG(Self-RAG)
看看是否需要RAG
检索树 RAG(RAPTOR)
拆解复杂问题
多智能体 RAG
多智能体协作

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 22
22 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)