蒸馏技术(老师----学生模型)
无反馈,不学习蒸馏技术:通过教会特定任务。这样说可能比较抽像,具体一点来说就是,现如今的大模型参数都达到了百万亿级,甚至千万亿级,对于一些公司实际使用这样的大模型需要大量昂贵的硬件资源,同时在一些硬件资源受限的终端设备中无法运行;为了让大模型减小运行时所需要的硬件资源就提出了蒸馏技术。
无反馈,不学习

蒸馏技术:通过老师模型教会学生模型特定任务。这样说可能比较抽像,具体一点来说就是,现如今的大模型参数都达到了百万亿级,甚至千万亿级,对于一些公司实际使用这样的大模型需要大量昂贵的硬件资源,同时在一些硬件资源受限的终端设备中无法运行;为了让大模型减小运行时所需要的硬件资源就提出了蒸馏技术。旨在让较小参数量的学生模型拥有老师模型(千万亿级大模型)同样优秀的表现能力。
一)蒸馏模型中的名词
1.1 学生模型和教师模型
在上述的描述中,已经大概提及了什么是学生模型,什么是教师模型。教师模型通常是一个复杂的预训练模型(如大型神经网络),具备较强的性能;学生模型则是一个轻量级模型,通过学习教师模型的输出或中间特征来提升自身表现。在绝大多数的情况下,教师模型往往决定了学生模型的性能上限,并且学生模型的性能不会超过教师模型。所以教师模型一般会是一个性能出色的模型。
1.2 软标签和硬标签
硬标签是离散的,明确标志着样本,以二分类为例,给予某个样本标签,也就是硬标签,其形式会为 [0,1] 表示属于二分类中的一类,而对于另外一类会使用标签 [1,0] 来表示。
- 硬标签是确定的,没有中间状态(表示绝对属于类别1)。
- 硬标签提供较少信息,只给出最终类别。
- 硬标签是离散值,一般是人工标定的确定值。
软标签是连续的概率分布或置信度分数,表示样本属于各个类别的可能性。软标签通常是一个向量,其中每个元素是概率值。同样的二分类例子来看,其某类的标签可能就是 [0.1,0.9] ,对于另外一类给出的标签可能是 [0.87,0.13] 。
- 软标签表达不确定性(如[0.7, 0.3] 表示70%可能属于类别1,30%可能属于类别2)
- 软标签提供更丰富的概率信息,有助于模型学习类间关系。(如[0.7, 0.3] 表示70%可能属于类别1,30%可能属于类别2,就表示类别1其实有部分和类别2相似,但是相似程度不太高)
- 软标签是连续向量,是模型输出,是个属于某类的概率向量。
所以软标签在模型蒸馏中就是指教师模型的输出概率分布,这些属于某些类别的概率值构成了软标签。
二)蒸馏损失函数
大概了解蒸馏技术,以及一些专业名词后,就可以直接开始理解蒸馏模型是如何实现的了。理解一个模型的,最直接的方式就是理解其损失函数。其蒸馏模型的损失函数如下:
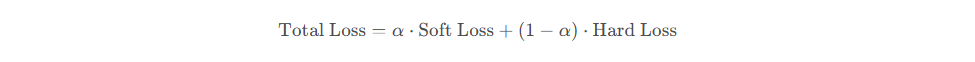
可以看出,其损失是硬标签之间的损失加上软标签之间的损失 ,然后为两种标签的损失配上不同的权重比例。换一种思维方式理解:软标签损失,就是想让学生模型的输出和老师模型的输出大致相同,即从老师模型那里学习到经验;硬标签是让模型从真实标签中学习。
2.1 硬标签蒸馏损失函数(Hard Label Loss)
硬标签损失就是直接使用交叉熵损失(Cross Entropy Loss)来计算。交叉熵损失用于衡量两个概率分布之间的差异。在模型蒸馏中,它用于衡量学生模型预测的概率分布与真实标签之间的差异。公式如下:
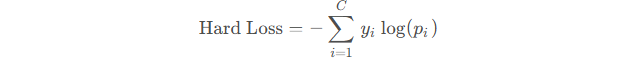
- (
) 是类别总数。
- (
) 是真实标签的独热编码。
- (
) 是模型预测样本属于第 ( i ) 类的概率。
举例:
对于四分类任务(类别 0、1、2、3),独热编码将每个类别表示为长度为 4 的向量,仅对应位置为 1,其余为 0:
| 类别 | 独热编码向量 |
|---|---|
| 0 | [1, 0, 0, 0] |
| 1 | [0, 1, 0, 0] |
| 2 | [0, 0, 1, 0] |
| 3 | [0, 0, 0, 1] |
假设如下:
- 真实标签为类别 2,独热编码 p=[0,0,1,0]
- 模型输出的原始 logits 为 [2,1,5,3](未经过 Softmax)
- 通过 Softmax 转换为概率分布 p,转化后的 p=[0.041,0.015,0.831,0.112]
计算交叉熵损失:
由于是独热编码,所以最后的 Hard loss 如下:
![]()
2.2 软标签蒸馏损失函数(Soft Label Loss)
软标签损失用于衡量,学生模型和老师模型之间输出的差距,公式如下:
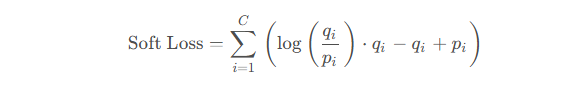
- (
- (
) 是老师模型预测样本属于第 ( i ) 类的概率。
- (
最后将硬标签损失和软标签损失按着某种配比相加就能得到最后该蒸馏模型的损失函数。
三)遗留问题
老师模型对某个样本预测的真实输出是Logits(原始输出),其中原始输出是类似于 [2.0, 1.0, 0.1],
是需要将Logits(原始输出) 转化为概率分布后才能传递给学生模型的,即转化公式如下:
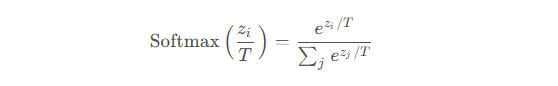
- 温度参数T,这是一个超参数,
-
高温度(T>1):使 Softmax 输出更加平滑,类别之间的差异变小。
-
低温度(T=1):得到标准的 Softmax 输出。
-
极低温度(T→0):使 Softmax 输出接近独热编码。
-
举例:T 为0.01,Logits(原始输出)为 [2.0, 1.0, 0.1]
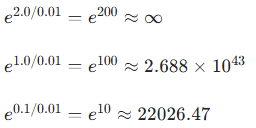
计算概率分布:
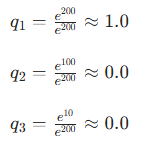
最终概率分布:[1.0,0.0,0.0],此时已经变成了独热编码。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 17
17 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)