AI概念扫盲篇之RAG到底是什么
RAG(Retrieval-Augmented Generation,检索增强生成) 是一种结合大模型生成能力和外部知识检索的技术,用来提升模型回答的准确性和专业性。

一、RAG技术详解
RAG(Retrieval-Augmented Generation,检索增强生成) 是一种结合大模型生成能力和外部知识检索的技术,用来提升模型回答的准确性和专业性。
核心原理
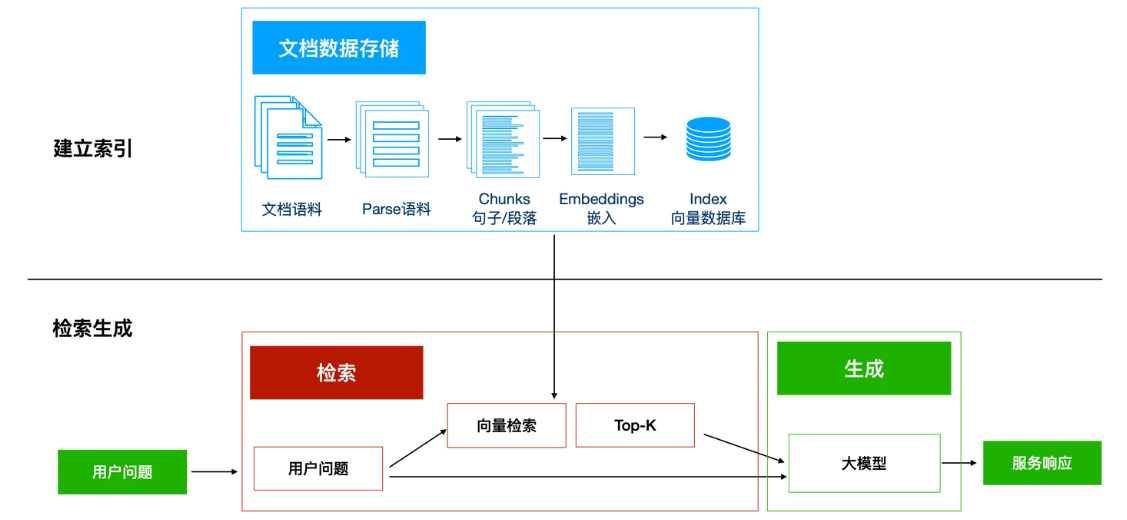
由上图所示,RAG主要由两个部分构成:
建立索引:
首先要清洗和提取原始数据,将 PDF、Docx等不同格式的文件解析为纯文本数据;然后将文本数据分割成更小的片段(chunk);最后将这些片段经过嵌入模型转换成向量数据(此过程叫做embedding),并将原始语料块和嵌入向量以键值对形式存储到向量数据库中,以便进行后续快速且频繁的搜索。这就是建立索引的过程。
检索生成:
系统会获取到用户输入,随后计算出用户的问题与向量数据库中的文档块之间的相似度,选择相似度最高的K个文档块(K值可以自己设置)作为回答当前问题的知识。知识与问题会合并到提示词模板中提交给大模型,大模型给出回复。这就是检索生成的过程。
工作流程
-
检索(Retrieval):
示例:用户问"如何配置Python虚拟环境?",RAG会从技术文档库中检索相关段落
当接收到用户输入时,RAG会从外部知识库(如文档、数据库)中检索与问题相关的内容。 -
增强(Augmentation):
将检索到的内容作为上下文(context),与大模型的通用知识结合 -
生成(Generation):
基于增强后的上下文生成最终回答
与传统大模型的区别
| 特性 | 普通大模型 | RAG |
|---|---|---|
| 知识来源 | 训练数据(静态) | 训练数据 + 动态检索 |
| 实时性 | 无法更新 | 可通过更新知识库增强 |
| 专业领域回答 | 依赖预训练数据 | 精准匹配外部知识 |
二、RAG与Agent的关系
1. Agent的扩展工具
-
RAG是Agent的核心能力扩展模块,使Agent具备动态知识获取能力
-
典型应用场景:
客服Agent:检索产品手册回答用户问题
医疗Agent:结合最新医学论文生成诊断建议
2. 协作流程
用户问题 → Agent任务解析 → RAG检索知识 → Agent整合结果 → 生成最终回答
三、RAG开发所需知识点
1. 核心组件
| 组件 | 说明 | 常用工具 |
|---|---|---|
| 文档处理器 | 将文本转换为可检索的结构化数据 | LangChain文档加载器、Unstructured |
| 向量数据库 | 存储和检索向量化文档 | FAISS、Pinecone、Chroma |
| Embedding模型 | 将文本转换为向量 | OpenAI text-embedding-ada-002 |
| 检索算法 | 相似度匹配策略 | 余弦相似度、BM25 |
2. 必备技能
-
Python数据处理:Pandas、NumPy处理结构化数据
-
文本处理:掌握分词、Chunking(文本分块)技术
-
向量化技术:理解Embedding原理及API调用
-
框架使用:LangChain的RAG模块开发流程
四、RAG开发编码示例
以下是一个基于LangChain的本地文档问答实现,使用FAISS向量库:
from langchain_community.document_loaders import TextLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import FAISS
from langchain.chains import RetrievalQA
from langchain_openai import ChatOpenAI
# 1. 加载文档(示例文本文件)
loader = TextLoader("knowledge.txt") # 需准备示例文件
documents = loader.load()
# 2. 文本分块(chunk_size控制块大小)
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=50
)
docs = text_splitter.split_documents(documents)
# 3. 创建向量库
embeddings = OpenAIEmbeddings()
vector_db = FAISS.from_documents(docs, embeddings)
# 4. 构建RAG问答链
llm = ChatOpenAI(model="gpt-3.5-turbo")
qa_chain = RetrievalQA.from_chain_type(
llm,
retriever=vector_db.as_retriever(search_kwargs={"k": 3}), # 检索前3个相关块
chain_type="stuff" # 简单拼接上下文
)
# 5. 测试问答
question = "Python虚拟环境的作用是什么?"
response = qa_chain.invoke({"query": question})
print(response["result"])代码解析
-
文档处理:
-
加载本地文档(支持PDF、HTML等多种格式)
-
将长文本分割为适合检索的小块(避免信息丢失)
-
-
向量化存储:
-
使用OpenAI的Embedding模型将文本转换为向量
-
FAISS实现高效的相似度检索
-
-
问答流程:
-
用户问题 → 向量相似度检索 → 拼接上下文 → 大模型生成答案
-
五、RAG开发学习路径
1. 入门阶段
-
掌握LangChain的
DocumentLoader、TextSplitter模块 -
学习FAISS/Chroma等轻量级向量库的本地部署
2. 进阶方向
-
检索优化:
-
混合检索(关键词+向量)
-
重排序(Rerank)技术提升精度
-
-
生产级部署:
-
使用Pinecone等云向量数据库
-
结合LlamaIndex构建知识图谱
-

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 19
19 0
0- 0



 已为社区贡献41条内容
已为社区贡献41条内容

所有评论(0)