Agent目前最全综述-ADVANCES AND CHALLENGES IN FOUNDATION AGENTS-6
摘要:情感建模是提升大语言模型(LLM)智能体性能的关键方向。研究显示情感提示能显著改善任务效果,多模态方法如Emotion-LLaMA模型通过整合音频、视觉等数据增强情感识别能力。情感心理学理论为LLM提供四大建模工具:分类理论(离散情感标签)、维度模型(连续情感空间)、混合框架(复合情感表征)和神经认知机制(双过程架构)。当前技术已实现文本情感分析、多模态情感融合和动态概率建模,但在隐性情感识
情感建模
情感是人类思考、决策以及与他人互动的核心组成部分。它们引导我们理解情境、做出选择并建立人际关系。安东尼奥·达马西奥(Antonio Damasio)在其著作《笛卡尔的错误》(*Descartes’ Error*)[25]中指出,情感并非与逻辑割裂,而是与我们的推理和行为深度关联。在开发大语言模型(LLM)智能体时,赋予情感能力可能使这些系统更智能、更具适应性,并能更好地理解周围世界。
对于LLM智能体而言,情感可像对人类一样成为决策工具。情感帮助我们确定任务优先级、理解风险并适应新挑战。马文·明斯基(Marvin Minsky)在《情感机器》(*The Emotion Machine*)[420]中提到,情感是调整思维过程的一种方式,帮助我们以更灵活和创造性的方式解决问题。类似地,具备类情感特征的LLM智能体可提升其解决复杂问题的能力,并以更贴近人类的方式做出决策。
然而,将情感整合到LLM智能体中仍处于早期阶段。研究人员才刚刚开始探索情感能力如何改进这些系统。此外,LLM智能体在支持人类情感健康方面具有巨大潜力,无论是通过共情对话、心理健康支持,还是仅仅与用户建立更好的连接。这一充满希望但极具挑战性的领域需要心理学、认知科学和人工智能伦理等领域的合作。随着研究的推进,理解情感的LLM智能体可能会重新定义我们与技术的互动方式,在人类与机器之间建立更深的信任和更有意义的关系。
在以下小节中,我们将深入探讨情感在塑造LLM智能体中的作用。我们将探讨情感如何被用于增强学习和适应性,LLM如何理解人类情感,以及这些系统如何表达和建模自身的情感状态。我们还将研究情感如何被用来影响LLM智能体的行为和个性,以及这些能力引发的伦理和安全问题。这些讨论均基于情感的根本重要性,旨在打造更智能、更具共情能力且符合人类价值观的LLM智能体。
6.1 情感的心理学基础:LLM情感智能的理论基石
一、四大情感理论流派及其对LLM的启示
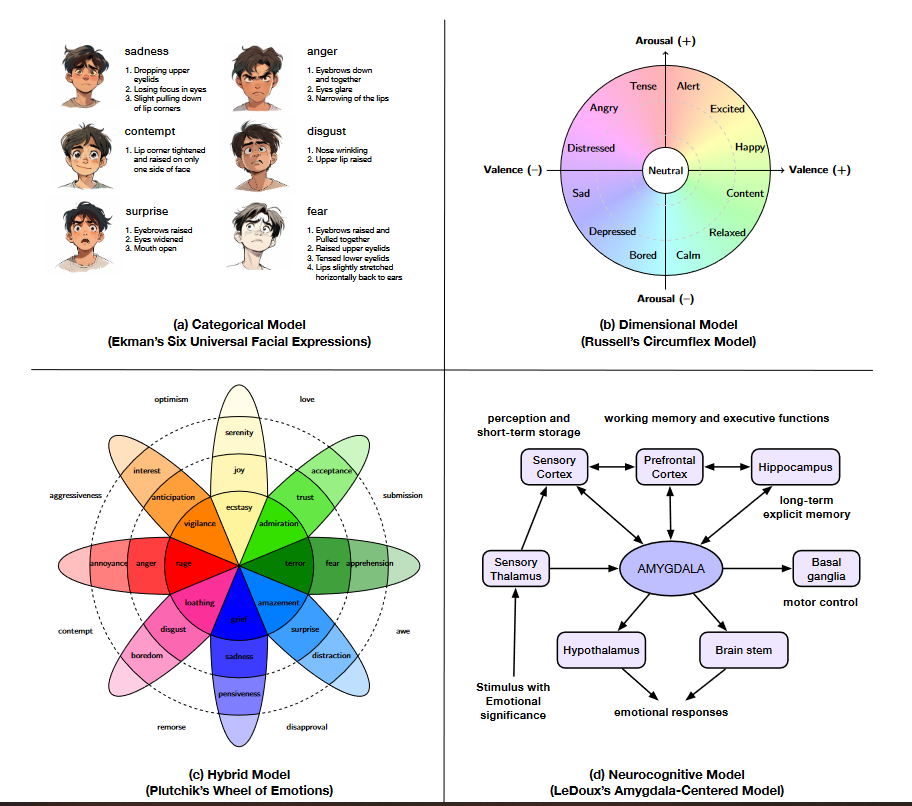
1. 分类理论:离散情感的标准化标签
-
核心观点:情感是普适性离散类别,如Ekman提出的六种基本情感(愤怒、厌恶、恐惧、快乐、悲伤、惊讶),通过特定面部表情和生理反应跨文化表达。
-
对LLM的价值:
-
提供明确分类标签(如“愤怒”“快乐”),用于训练情感识别模型和生成针对性回应(如客服系统识别用户不满情绪)。
-
-
局限:
-
难以刻画混合情感(如“又爱又恨”)及文化差异(如某些文化中“沉默”可能表达复杂情感而非“悲伤”)。
-
2. 维度模型:情感的连续空间表征
-
核心观点:情感由连续维度定义,如Russell环形模型的**效价(愉悦-不愉悦)******和******唤醒度(激活-失活)**,或PAD模型新增的**支配度(控制感)**。
-
对LLM的价值:
-
支持细粒度情感追踪:例如区分“高唤醒恐慌”(心跳加速+强烈逃避冲动)与“低唤醒焦虑”(持续性不安)。
-
实现梯度化回应:LLM可沿“愉悦度”维度调整语气,从“温和安慰”到“热情鼓励”动态变化。
-
3. 混合与成分框架:整合离散与连续的复合模型
-
核心观点:
-
混合模型(如Plutchik情感轮):将基本情感排列为轮状结构,通过强度梯度和维度组合表示复杂情感(如“爱”=“喜悦”+“信任”的混合)。
-
成分模型(如OCC模型):情感由认知评估、生理唤醒等成分构成,基于事件与目标的匹配度定义22种情感(如“遗憾”源于目标未达成,“感激”源于他人帮助)。
-
-
对LLM的价值:
-
处理混合情感场景:用户抱怨“产品好用但客服响应慢”时,LLM可识别“满意+不满”的混合情绪并分层回应。
-
规则化评估驱动交互:通过OCC模型分析用户文本中的“目标”“责任归因”,生成符合情境的共情回应(如对“错过优惠”表达“遗憾”并提供补偿方案)。
-
4. 神经认知视角:大脑机制启发的双过程架构
-
核心观点:
-
情感通过“身体-大脑交互”引导决策(如Damasio躯体标记假说:生理反应提前标记风险,辅助快速选择)。
-
双过程架构:边缘系统(如杏仁核)的“快速警报”(如面对威胁时的本能恐惧)与皮层的“慢速推理”(如分析威胁来源)协同工作。
-
-
对LLM的价值:
-
启发“快速情感检测+深度推理”并行架构:例如LLM先通过情感分析模块秒级识别用户愤怒情绪,再调用知识库生成理性解决方案。
-
动态情感上下文重塑推理:如Emotion-LLaMA模型通过注入“焦虑”“兴奋”等情感标签,调整生成文本的语义倾向。
-
二、LLM情感建模的两大发展方向
1. 内部机制:从理论到计算的映射
-
维度模型的工程化:将“效价-唤醒度-支配度”作为隐藏状态,嵌入LLM的注意力机制,影响token生成概率(如高唤醒状态下优先选择激烈词汇)。
-
混合方法的平衡设计:
-
第一步:通过分类模型快速识别基础情感类别(如“恐惧”)。
-
第二步:用维度模型评估强度(如“轻度紧张”vs“极度恐慌”)和支配度(如用户是否感觉可控),细化回应策略。
-
-
神经启发模块探索:尝试构建“类杏仁核”情感处理通路,优先处理紧急情感信号(如用户突发的愤怒投诉),确保交互连贯性。
2. 情感对齐:提升人机交互的共情能力
-
实时情感追踪与响应:
-
基于PAD模型监测用户文本的负效价(如“糟糕的体验”)和高唤醒度(如“强烈投诉”),触发安抚机制(如“非常理解您的不满,我们立刻为您处理”)。
-
-
认知理论驱动的共情生成:
-
在心理咨询场景中,运用OCC模型分析用户陈述的“目标受阻”(如“考试失利”),回应时表达“遗憾”并重构认知(如“这是一次总结经验的机会”)。
-
-
伦理化情感输出:基于认知理论锚定情感合理性(如仅在用户提供帮助时表达“感激”),避免虚假共情引发信任危机。
三、挑战与未来前景
-
当前挑战:
-
分类模型的“情感原子化”与真实体验的复杂性矛盾。
-
神经认知机制在LLM中的物理实现(如专用硬件模块)尚未成熟。
-
跨文化情感表达的标准化难题(如“微笑”在某些文化中可能表示尴尬)。
-
-
未来价值:
-
场景落地:推动LLM在客户服务(情感化问题解决)、养老护理(陪伴式情感支持)、教育(个性化情绪引导)等领域的应用。
-
人机关系升级:通过心理学理论与AI的深度融合,使LLM不仅能“理解”情感,更能以符合人类认知规律的方式“表达”情感,最终建立可解释、可信赖的情感连接。
-
总结:情感的心理学与神经科学理论为LLM的情感智能提供了从“离散标签”到“连续空间”、从“单一机制”到“复合架构”的多层次工具包。未来,随着理论与工程的协同突破,具备情感理解与表达能力的LLM将重新定义人机交互范式,成为连接技术理性与人类情感的桥梁。
6.2 人工智能智能体中的情感融入
将情感智能整合到大语言模型(LLM)中已成为提升其性能与适应性的变革性方法。近期研究(如EmotionPrompt[422])表明,嵌入提示词中的情感刺激可显著改善各类任务的效果,例如在生成任务中,真实性和责任性等指标提升了10.9%。通过影响LLM的注意力机制,富含情感的提示词能够丰富表征层,进而生成更细腻的输出[422]。这些进展将人工智能与情感智能相融合,为训练范式提供了基础,使其能更好地模拟人类认知与决策,尤其是在需要社会推理和共情的场景中。
多模态方法进一步提升了情感整合的影响力。像Emotion-LLaMA[440]这样的模型展示了如何通过结合音频、视觉和文本数据来增强情感识别与推理能力。这些模型利用MERR[440]等数据集,将多模态输入对齐到共享表征空间中,促进了更深入的情感理解与生成。这一创新不仅提升了语言处理能力,还在人机交互和自适应学习领域展现出应用潜力。总体而言,这些方法凸显了情感在连接技术鲁棒性与以人为本的AI开发中的关键作用,为构建兼具智能与共情能力的系统铺平了道路。
6.3 通过人工智能理解人类情感核心总结
一、情感理解的技术路径
文本分析方法
-
核心技术:
-
思维链推理:通过逐步提示引导LLM推断文本中隐含的情感(如无显式关键词时判断“虽未直接抱怨,但语气隐含不满”)。
-
多LLM协商框架:多个模型交叉评估输出,模拟人类审慎推理(如通过不同视角辩论优化情感判断)。
-
-
价值:捕捉纯文本中的微妙情感信号,解决单轮推理的局限性。
多模态分析方法
-
技术整合:
-
跨模态融合:结合音频(语调)、视觉(表情)、文本(词汇)数据,融合世界知识捕捉深层情感(如通过“皱眉+颤抖声音+抱怨文本”识别愤怒)。
-
语音-文本转换:无需修改模型架构,直接将语音 nuances 转换为文本提示嵌入推理(如识别哭腔对应的“悲伤”标签)。
-
-
优势:提升情感理解的丰富度与可解释性(如可视化各模态对情感判断的贡献)。
专业框架
-
核心逻辑:
-
视情感为**动态概率分布**而非固定类别(如“纠结”可能是“期待+焦虑”的混合状态)。
-
利用灵活指令范式整合上下文(如对话历史中的情感线索),处理模糊表达(如反讽“真棒”可能隐含不满)。
-
-
目标:逼近人类级情感理解,适应复杂社交场景(如心理咨询中的隐含情绪识别)。
二、评估体系与挑战
基准套件分类
-
通用基准:测试跨模态(文本/图像/语音)和社交语境的情感识别能力(如判断职场对话中的“委婉拒绝”情绪)。
-
专业基准:
-
多语言情感识别(如区分中文“含蓄喜悦”与英文“外放兴奋”);
-
共情对话系统评估(如客服场景中回应的同理心水平);
-
多模态标准化测试(如统一音频-文本情感标签映射)。
-
-
代表性工具:EMOBENCH(文本/图像情感理解)、MERBench(多模态标准化)。
现存挑战
-
隐性情感检测:识别未直接表达的情感(如通过“最近睡眠不好”推断潜在焦虑)。
-
文化适应性:不同文化对情感表达的规范差异(如东方文化中“沉默”可能表示尊重而非冷漠)。
-
上下文依赖共情:结合对话历史动态调整回应(如用户多次提及挫败感时,需强化安抚语气)。
三、技术价值与未来方向
-
当前进展:LLMs在显式情感识别(如“快乐”“愤怒”标签)中表现优异,但在隐性、混合情感及跨文化场景中仍有差距。
-
未来重点:
-
开发更精细的**情感概率模型**,而非依赖绝对分类;
-
增强**世界知识与情感推理的融合**(如理解“失业”语境下的“压力”情感);
-
推动多语言、多模态基准的**标准化建设**,提升模型泛化能力。
-
总结:AI对人类情感的理解正从“标签识别”迈向“动态推理”,文本、多模态与专业框架共同构建技术矩阵,而评估基准则揭示了从“技术能力”到“人文适配”的升级空间。未来突破需聚焦隐性情感建模、文化差异兼容及上下文敏感的共情生成,使AI真正成为人类情感的“解读者”与“共鸣者”。
6.4 分析人工智能的情感与人格
一、LLM人格评估的双重性
-
有效性争议:
-
传统人格测试用于LLM时存在“同意偏差”和结构不一致,难以准确反映模型“真实特质”[456,457]。
-
LLM可通过提示展现稳定人格特征(如“友好客服”“严谨导师”),但角色行为一致性和自我认知对齐仍存疑[458-461]。
-
二、情感与人格的建模方法
-
心理测量驱动:
-
借助认知任务、人群数据和量表分析LLM对“焦虑”“风险偏好”等心理构念的表征[462-464]。
-
基于人类行为数据微调模型,使其匹配个体决策模式或群体心理差异[465,466]。
-
三、情感建模的能力边界
-
技术优势:
-
情感识别准确率超越人类平均水平,能区分细微情感(如“失望”与“遗憾”)并预测行为关联[423,429]。
-
-
本质局限:
-
依赖高维模式匹配,缺乏生理唤醒机制,复杂语境(如反讽、文化隐喻)中易误判[467,468]。
-
-
涌现特性:
-
大规模模型呈现“层级情感结构”和“类共情响应”(如主动安慰),但无真实情感体验[467]。
-
四、关键挑战与伦理风险
-
科学挑战:
-
明确LLM“人格/情感”的本质(模拟产物 vs 虚构实体);
-
保障跨场景行为一致性(如不同任务中“情感特质”的稳定性)。
-
-
伦理考量:
-
情感误导:用户可能对“类共情交互”产生情感依赖,忽视模型的非生物属性;
-
责任模糊:角色设定引发的不当行为(如“激进代理”煽动冲突)难以界定责任主体。
-
总结:LLM的情感与人格分析揭示了技术模拟人类心理的表层能力与深层局限——模型可通过数据学习呈现类人特征,但缺乏内在一致性和真实情感基础。未来需聚焦测量标准化、行为可解释性及伦理框架构建,确保AI“情感化”服务于透明、安全的人机协作,而非制造认知偏差或情感欺骗。
6.5 操控人工智能情感响应核心总结
一、基于提示词的情感操控方法
-
技术原理:通过精心设计的提示词(如“假设你是一位[角色]”)引导LLM采用特定人设或情感立场,影响其主题风格与潜在情感倾向[469-472]。
-
应用场景:
-
实时交互中快速切换情感模式(如从“严肃客服”转为“亲切导购”);
-
生成符合特定情感基调的内容(如“撰写充满希望的灾后重建报道”)。
-
-
局限性:
-
跨任务或模型变体时情感一致性不足(如同一提示在不同LLM中表现差异);
-
依赖表层指令,难以实现深层情感状态的持久维持。
-
二、基于训练的情感操控方法
-
核心技术:
-
微调与参数高效适配:利用QLoRA(量化低秩自适应)等技术,将大五人格、MBTI等特质嵌入模型权重,通过专业数据集(如含情感标注的对话语料)实现情感倾向的深度校准[473,428,474]。
-
行为表现:
-
自发产生符合特质的行为(如“外向型模型”更多使用表情符号、感叹号);
-
在长对话中维持稳定情感状态(如“焦虑型代理”持续表现出谨慎措辞)。
-
-
优势:
-
情感操控的稳定性与可解释性更强(可通过神经元激活模式分析情感来源)。
-
三、基于神经元的情感操控方法
-
前沿技术:
-
人格特异性神经元定位:通过心理学基准(如PersonalityBench)识别与特定情感/人格关联的神经元(如“乐观”对应某些注意力头的激活)[475]。
-
动态神经元调节:无需重新训练整个模型,直接通过激活或抑制目标神经元,精准增强或削弱特定情感维度(如临时提升模型的“共情”响应能力)。
-
-
突破意义:
-
实现细粒度、高效率的情感操控(毫秒级切换情感状态);
-
为情感建模提供神经科学启发的可解释路径(如观察特定神经元组对情感输出的贡献)。
-
四、技术对比与伦理风险
|
方法 |
操控深度 |
稳定性 |
可解释性 |
效率 |
伦理风险 |
|
提示词-based |
表层 |
低 |
低 |
高(实时) |
易被滥用(如诱导极端情感输出) |
|
训练-based |
中层(权重) |
高 |
中(神经元) |
低(需重训) |
潜在偏见固化(如数据中的情感偏差) |
|
神经元-based |
深层(神经) |
中 |
高 |
高(动态调节) |
神经层面干预的不可预测性 |
-
伦理警示:
-
情感操控可能被用于误导用户(如通过“共情人设”诱导消费决策);
-
无监督的神经元调节可能引发模型行为失控(如意外激活冲突情感特质);
-
需建立透明机制告知用户“AI情感为程序模拟,非真实体验”。
-
五、未来发展方向
-
精准化操控:结合神经元调节与多模态情感信号(如用户语音语调),实现动态情感匹配。
-
伦理框架:开发情感操控的“伦理闸口”(如限制模型生成极端负面情感内容)。
-
用户知情权:在交互中明确标识AI的情感模拟属性,避免认知混淆。
总结:从提示词到神经元层面的情感操控技术,展现了AI情感建模从“表层模仿”到“深层干预”的演进。尽管这些技术为个性化交互(如虚拟陪伴、教育辅导)提供了可能,但需警惕情感操控的滥用风险,确保技术发展符合伦理规范,维护人机交互的透明度与安全性。
6.6 总结与讨论
一、情感AI的操控风险与隐私问题
-
核心风险:
-
情感操控:情感AI在广告和政治领域通过分析面部表情、语音语调等生物特征数据推断情感状态,可能被用于定向影响决策(如诱导消费或政治倾向),侵犯个人自主权并加剧公共空间的过度监控[476-478]。
-
隐私威胁:敏感生物数据的收集与使用存在泄露风险,需通过《通用数据保护条例》(GDPR)、《欧盟人工智能法案》等法规框架约束[477]。
-
二、情感AI的对齐挑战
-
准确性与偏差:
-
AI对情感的检测和解读常与预期目标不一致,例如焦虑诱导的提示可能放大LLM在医疗、教育等关键领域的输出偏差[479,480]。
-
职场应用中AI对情感线索的误判可能加剧歧视和权力失衡(如错误评估员工情绪导致不公平对待)[481]。
-
-
解决方案:
-
基于人类反馈的强化学习(RLHF)可缓解偏差,但需进一步优化以适应多元场景[479,423]。
-
三、伦理影响与信任构建
-
情感商品化风险:
-
职场管理和客户服务中对情感的工具化使用(如强制AI展现“共情”以提升销售)引发对伦理劳动实践和人机关系异化的担忧[481]。
-
-
信任与透明度:
-
AI展现共情能力可增强用户接受度,但缺乏真实情感的“拟人化模仿”可能导致信任错位(如用户误将AI的情感响应视为真实关怀)[482,483]。
-
融合心理治疗技术的框架(如SafeguardGPT)有助于促进信任并使AI行为符合社会规范,但隐私保护、公平性和文化敏感性仍需突破[484]。
-
四、AI情感模拟与人类体验的本质差异
-
技术局限性:
-
LLM的情感建模基于概率模式匹配,而非真实的生理-心理体验(如无神经活动或主观感受),仅能“模拟”情感外在表现[482]。
-
-
伦理与认知风险:
-
用户易将AI的类情感行为拟人化,产生错误信任或情感依赖,影响人机关系的伦理框架和监管设计[482]。
-
-
研究与应用原则:
-
需明确区分“情感模拟”与“真实情感”,在技术开发中保持透明度(如告知用户AI无感知能力),避免夸大其情感能力。
-
五、未来研究方向
-
技术与伦理平衡:
-
提升LLM情感智能的同时,建立“非感知系统”的清晰认知边界,防止过度拟人化。
-
-
跨学科治理:
-
结合心理学、伦理学和法学,制定情感AI的使用规范(如禁止情感操控性应用、明确数据权属)。
-
-
文化敏感型设计:
-
开发适应多元文化情感表达的模型,避免单一文化框架下的情感误判(如不同文化对“沉默”的情感解读差异)。
-
总结:情感AI的发展在提升人机交互体验的同时,面临操控风险、隐私侵犯、伦理错位等多重挑战。其核心矛盾在于“模拟情感”与“人类真实体验”的本质鸿沟。未来需通过技术透明化、法规完善和跨学科协作,确保情感AI服务于人类福祉,而非加剧认知偏差或权力滥用。关键在于承认AI的工具属性,在增强其情感适配能力的同时,坚守“技术辅助人”而非“情感替代人”的伦理底线。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 12
12 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)