记录一次ETCD集群故障恢复
错误信息如上,其实是由于节点部署时 inital_cluster_state是new,导致集群节点识别已存在,拒绝再次初始化。k8s集群部署的etcd集群(3节点)由于集群扩容,宿主机重启,导致一个节点起不来。先改成existing。然后用etcd可用节点登陆集群,移除故障节点。过程的命令不再记录了,问豆包吧。节点成功加入集群,并启动成功。然后重新添加原节点。
·
k8s集群部署的etcd集群(3节点)由于集群扩容,宿主机重启,导致一个节点起不来。
{"level":"fatal","ts":"2025-07-29T06:58:31.624750Z","caller":"etcdmain/etcd.go:183","msg":"discovery failed","error":"member da5cb2321ac7cbbd has already been bootstrapped","stacktrace":"go.etcd.io/etcd/server/v3/etcdmain.startEtcdOrProxyV2\n\tgo.etcd.io/etcd/server/v3/etcdmain/etcd.go:183\ngo.etcd.io/etcd/server/v3/etcdmain.Main\n\tgo.etcd.io/etcd/server/v3/etcdmain/main.go:40\nmain.main\n\tgo.etcd.io/etcd/server/v3/main.go:31\nruntime.main\n\truntime/proc.go:272"}错误信息如上,其实是由于节点部署时 inital_cluster_state是new,导致集群节点识别已存在,拒绝再次初始化。
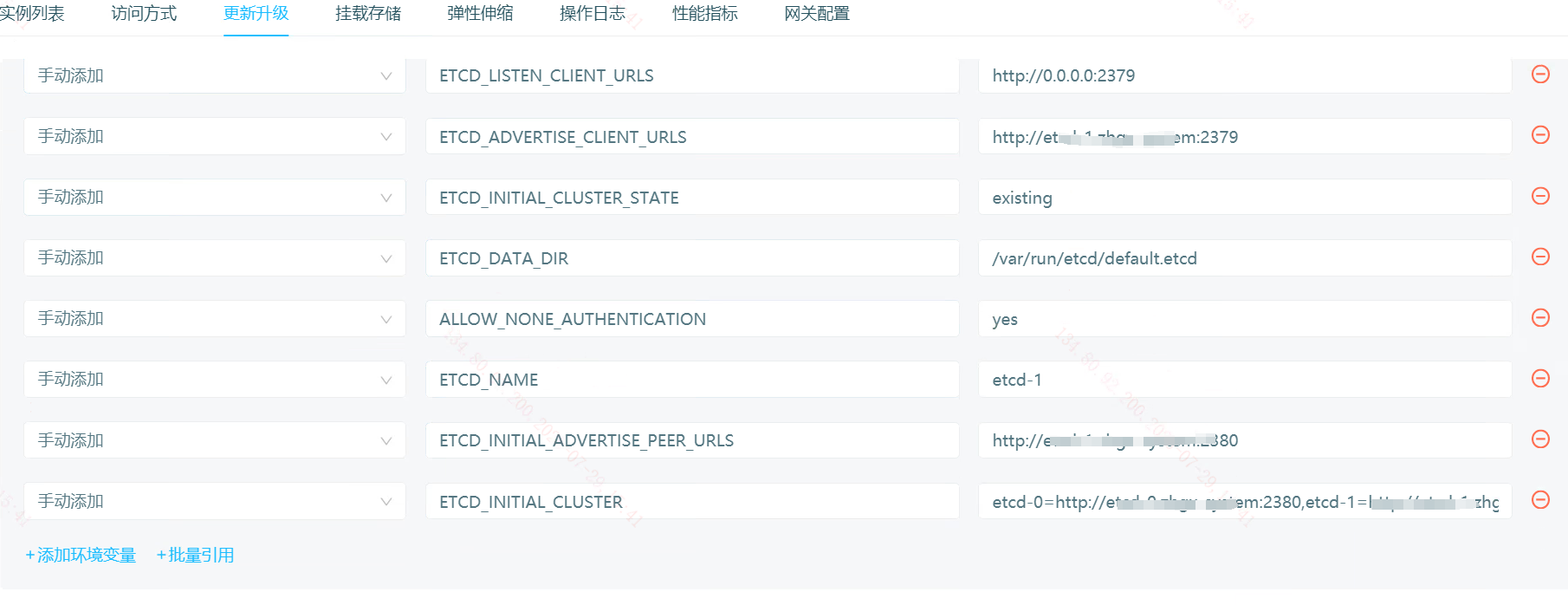
处理方式,
先改成existing。然后用etcd可用节点登陆集群,移除故障节点。
然后重新添加原节点。
节点成功加入集群,并启动成功。
过程的命令不再记录了,问豆包吧。
如果不用命令移除节点,也会报错,错误如下:
panic: tocommit(35) is out of range [lastIndex(0)]. Was the raft log corrupted, truncated, or lost?
以上
加一下吧
etcdctl member list 查看节点信息
etcdctl member remove 节点ID 移除节点
etcdctl member add 节点名称 --peer-urls=https://10.0.0.3:2380

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐
 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)