langchain RAG: Query Transformation (查询转换)
将用户输入转换为更有效的检索查询,通过语义优化提升检索结果的相关性和覆盖率。理解简单一点就是,将来一个查询(query)生成多个不同问法,最后一起检索。突破词汇不匹配(Vocabulary Mismatch)的检索瓶颈。您是一个很有帮助的助手,可以基于单个输入查询生成多个搜索查询。通过对用户问题生成多个视角,您的目标是提供帮助。给定用户问题的不同版本,以从向量中检索相关文档。用户克服了基于距离的相
·
langchain RAG: Query Transformation (查询转换)
RAG开发的六个关键阶段
- 1、查询转换(Query Transformation)
- 2、路由(Routing)
- 3、查询构建(Query Construction)
- 4、索引(Indexing)
- 5、检索(Retrieval)
- 6、生成(Generation)
查询转换(Query Transformation)
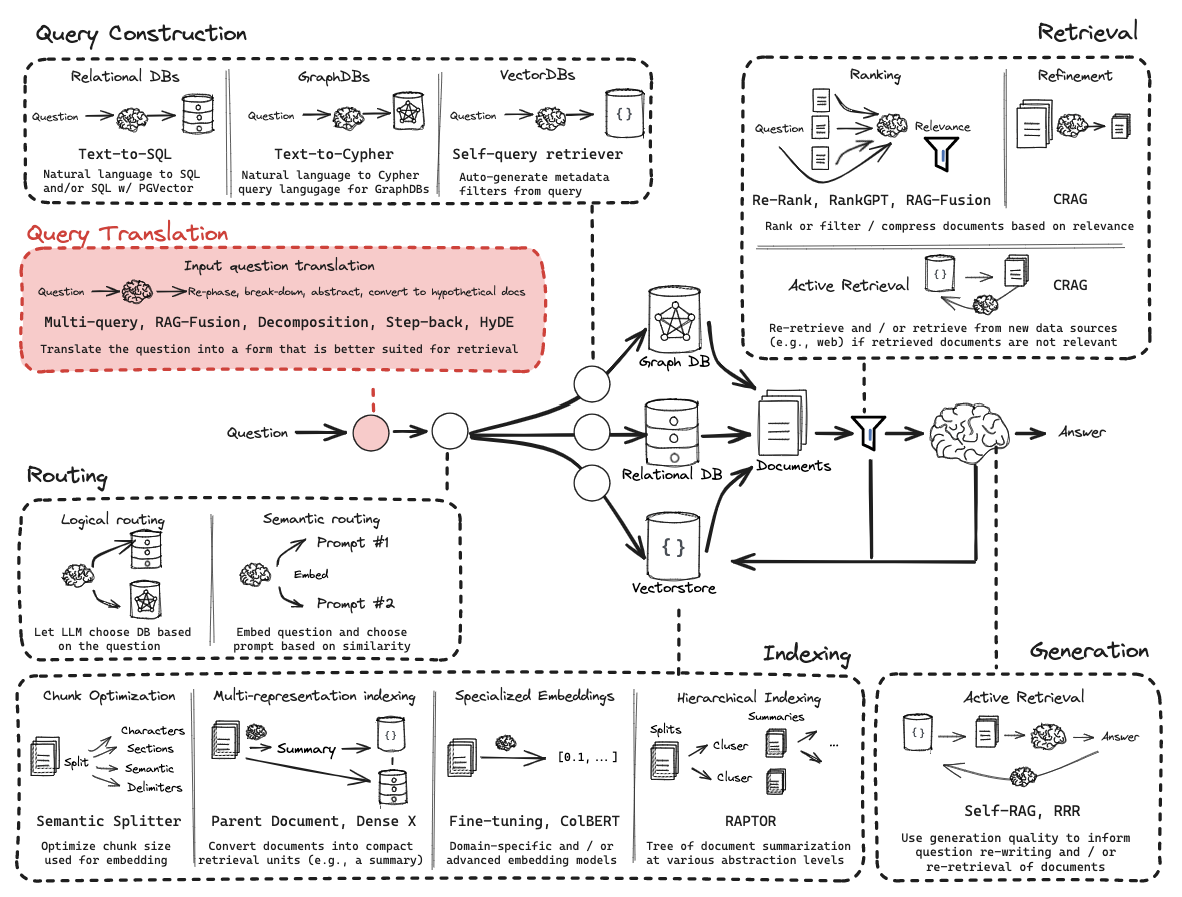
目标: 将用户输入转换为更有效的检索查询,通过语义优化提升检索结果的相关性和覆盖率
技术价值
-
解决自然语言表达的歧义性
-
突破词汇不匹配(Vocabulary Mismatch)的检索瓶颈
-
增强对隐含需求的捕捉能力
-
提高长尾问题的处理效果
前期准备
获取文档、加载文档、进行分词、存储向量库操作
import os
from dotenv import load_dotenv
from langchain_community.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import FAISS
from langchain_community.embeddings import DashScopeEmbeddings
from langchain.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain.chat_models import init_chat_model
from langchain.load import dumps, loads
from operator import itemgetter
from langchain.chains.question_answering import load_qa_chain
load_dotenv(override=True)
# 读取pdf文件
pdf_loader = PyPDFLoader("C:/wwqqq.pdf")
# 进行加载
docs = pdf_loader.load()
db_dir = "./faiss_db"
embedding = DashScopeEmbeddings(
model = 'text-embedding-v1',
dashscope_api_key = os.getenv('DASHSCOPE_API_KEY')
)
# 创建向量数据库
def create_vector_store(text: str,embedding=None) -> FAISS:
print("开始创建向量数据库......................")
# 进行分词
text_splitter = RecursiveCharacterTextSplitter(
separators=["\n\n", "\n", ".", " ", ""],
chunk_size=1000,
chunk_overlap=200
)
# 创建embedding模型
# embedding = OpenAIEmbeddings()
if embedding is None:
embedding = DashScopeEmbeddings(
model = 'text-embedding-v1',
dashscope_api_key = os.getenv('DASHSCOPE_API_KEY')
)
chunks = text_splitter.split_documents(text)
# 创建向量数据库
vector_store = FAISS.from_documents(chunks, embedding)
# 保存向量数据库
vector_store.save_local("faiss_db")
return vector_store
# 判断向量库是否存在
def get_db(db_dir) -> FAISS:
vector_store = None
is_db_exist = os.path.exists(db_dir)
if is_db_exist:
vector_store = FAISS.load_local(
db_dir,
embedding,
allow_dangerous_deserialization=True
)
else:
vector_store = create_vector_store(docs,embedding)
return vector_store
# 获取向量库
vector_store = get_db(db_dir)
retriever = vector_store.as_retriever()
llm = init_chat_model(
"deepseek-chat",
api_key = os.getenv("DEEPSEEK_API_KEY"),
base_url = os.getenv("DEEPSEEK_URL"),
model_provider = "deepseek"
)
1、Multi-query
理解简单一点就是,将来一个查询(query)生成多个不同问法,最后一起检索。
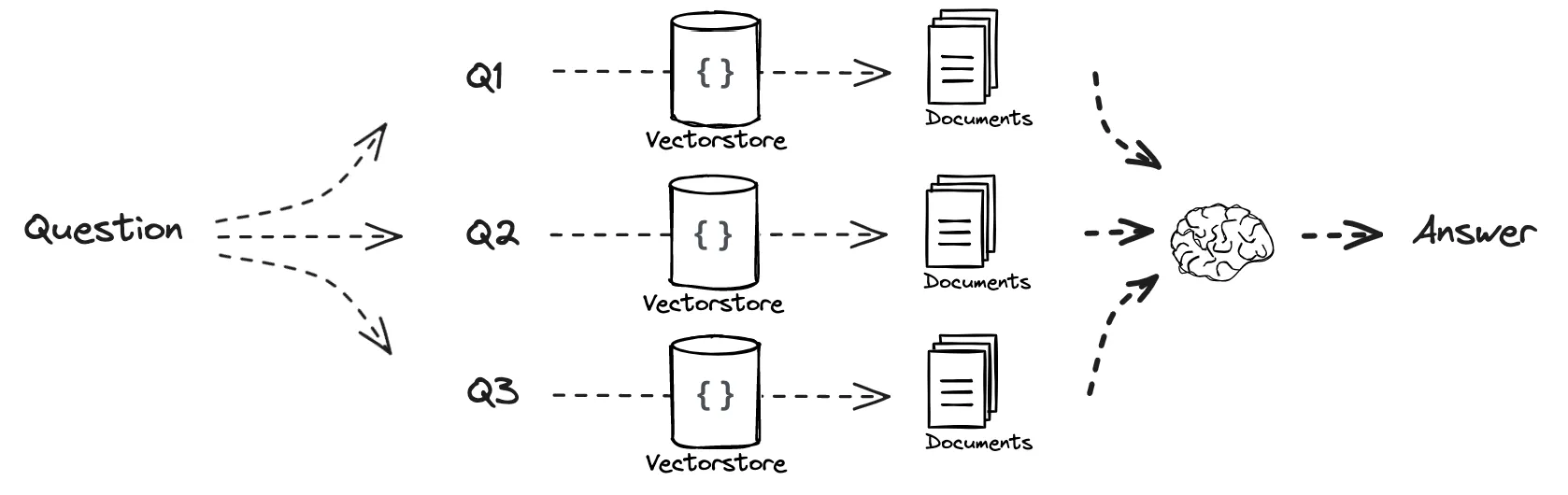
提示词解释:
你是一个人工智能语言模型助手。你的任务是生成5个
给定用户问题的不同版本,以从向量中检索相关文档
数据库。通过对用户问题生成多个视角,您的目标是提供帮助
用户克服了基于距离的相似度搜索的一些限制。
提供以换行符分隔的备选问题。最初的问题:
示例代码
# 进行多查询构建
# 多查询模板
multi_template = """"
You are an AI language model assistant. Your task is to generate five
different versions of the given user question to retrieve relevant documents from a vector
database. By generating multiple perspectives on the user question, your goal is to help
the user overcome some of the limitations of the distance-based similarity search.
Provide these alternative questions separated by newlines. Original question: {question}
"""
multi_prompt = ChatPromptTemplate.from_template(multi_template)
multi_chain = ( multi_prompt
| llm
| StrOutputParser()
| (lambda x: x.split("\n"))
)
# 进行数据合并 文档去重
def get_unique_union(documents: list[list]):
"""Unique union of retrieved docs"""
# dumps() => langchain中将对象转换为 JSON 字符串
flattened_docs = [dumps(doc) for sublist in documents for doc in sublist]
unique_docs = list(set(flattened_docs))
# loads() => langchain中将 JSON 字符串转换为对象
return [loads(doc) for doc in unique_docs]
retrieval_prompt_template = multi_chain | retriever.map() | get_unique_union
query = "nginx的特性有哪些?"
# res = retrieval_prompt_template.invoke({"question": query})
# print(res)
# RAG
template = """Answer the following question based on this context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
anwser_chain = (
{"context": retrieval_prompt_template,
"question": itemgetter("question")}
| prompt
| llm
| StrOutputParser()
)
res = anwser_chain.invoke({"question": query})
print(res)
2、RAG-Fusion
并行检索→结果去重→相关性加权→最终合成
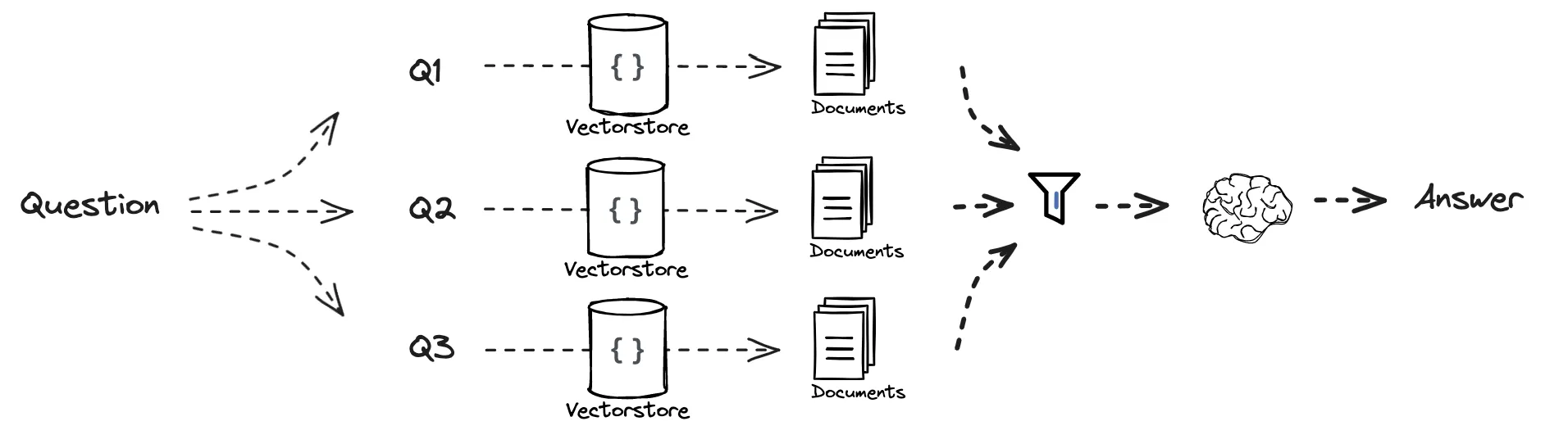
提示词解释:
您是一个很有帮助的助手,可以基于单个输入查询生成多个搜索查询。
生成与以下内容相关的多个搜索查询
代码示例
multi_template = """
You are a helpful assistant that generates multiple search queries based on a single input query.
Generate multiple search queries related to: {question}
Output ( queries):
"""
multi_prompt = ChatPromptTemplate.from_template(multi_template)
multi_chain = (
multi_prompt
| llm
| StrOutputParser()
| (lambda x: x.split("\n"))
)
### Reciprocal Rank Fusion 实现
def reciprocal_rank_fusion(results: List[List[Any]], k: int = 60) -> List[tuple]:
# 初始化字典以保存每个唯一文档的融合分数
fused_scores = {}
# 遍历每个排序文档列表
for t_docs in results:
# 使用其排名(在列表中的位置)遍历列表中的每个文档
for rank, doc in enumerate(t_docs):
# dumps() => langchain中将对象转换为 JSON 字符串
doc_str = dumps(doc)
# 如果文档尚未在fused_scores字典中,则将其添加为初始分数0
# 如果有的话 使用RRF公式更新文档的分数:1 / (rank + k)
fused_scores[doc_str] = fused_scores.get(doc_str, 0) + 1 / (rank + k)
#根据融合的分数按降序对文档进行排序,以获得重新排序的最终结果
reranked_results = [
(loads(doc), score)
for doc, score in sorted(fused_scores.items(), key=lambda x: x[1], reverse=True)
]
return reranked_results
fusion_chain = (
multi_chain
# map() 表示对每个 query 做检索,返回 List[List[Document]]
| retriever.map()
| reciprocal_rank_fusion
)
# RAG
template = """Answer the following question based on this context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
final_rag_chain = (
{"context": fusion_chain,
"question": itemgetter("question")}
| prompt
| llm
| StrOutputParser()
)
res = final_rag_chain.invoke({"question":"nginx的特性有哪些?"})
print(res)

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 3
3 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)