How we built our multi-agent research system—摘录
Research系统使用编制者-工作者模式的多智能体架构,主智能体协调过程同时委派给并行运行的专业子智能体。
·
一、核心概念
- 多代理系统(multi-agent system):由多个 LLM 代理在工具循环中自治协作完成任务。Anthropic 的 Research 功能采用“一主多辅”模式:LeadResearcher 负责总体规划,再并行生成若干 Subagent 进行分工检索,从而把大规模、开放式查询拆解为可并行执行的小任务。
二、多代理优势
| 价值 | 说明 |
|---|---|
| 并行压缩信息 | 子代理各自拥有独立上下文窗口,可同时探索问题的不同维度,再把关键结论压缩回主代理,提高搜索/推理带宽。 |
| 关注点分离 | 不同工具、提示词与搜索路径互不影响,降低路径依赖并提高覆盖面。 |
| 对宽度优先任务显著增益 | 内部评测显示,在需同步追踪多条线索的查询上,多代理系统性能比单代理提升 ≈ 90%。 |
| 可扩展的“代价—效果”曲线 | BrowseComp 分析表明,性能方差 95% 可由“Token 用量、工具调用次数、模型选择”解释;Token 一项就占 80%。多代理利用分布式上下文把“多花的 Token”直接转化为更完整的答案。 |
| 劣势:成本高 | 平均一次 Research 比普通聊天多 ≈ 15 倍 token;需确保任务价值能覆盖成本。 |
三、系统架构
Research系统使用编制者-工作者模式的多智能体架构,主智能体协调过程同时委派给并行运行的专业子智能体。
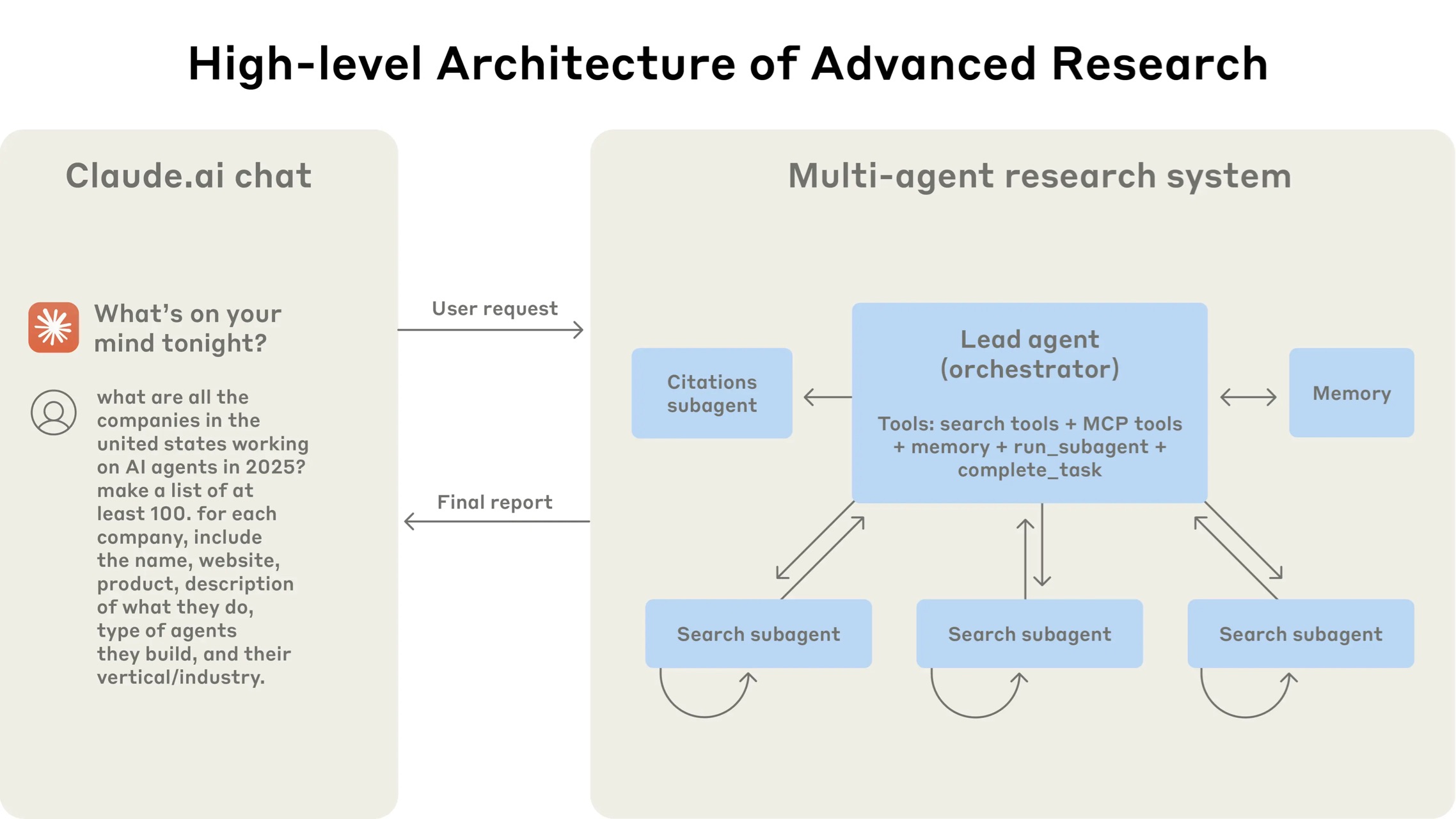
四、工作流程
- 查询提交:用户提交查询时,系统创建一个LeadResearcher智能体进入迭代研究过程
- 规划保存:LeadResearcher首先思考方法并将计划保存到Memory中以保持上下文,因为如果上下文窗口超过200,000个Token就会被截断,保留计划很重要
- 创建子智能体:创建具有特定研究任务的专业子智能体(可以是任意数量)。每个子智能体独立执行网络搜索,使用交错思考评估工具结果,并将发现返回给LeadResearcher
- 结果综合:LeadResearcher综合这些结果并决定是否需要更多研究——如果需要,可以创建额外的子智能体或完善策略
- 引用处理:一旦收集到足够信息,系统退出研究循环并将所有发现传递给CitationAgent,后者处理文档和研究报告以确定引用的具体位置
- 最终输出:完整的研究结果连同引用一起返回给用户
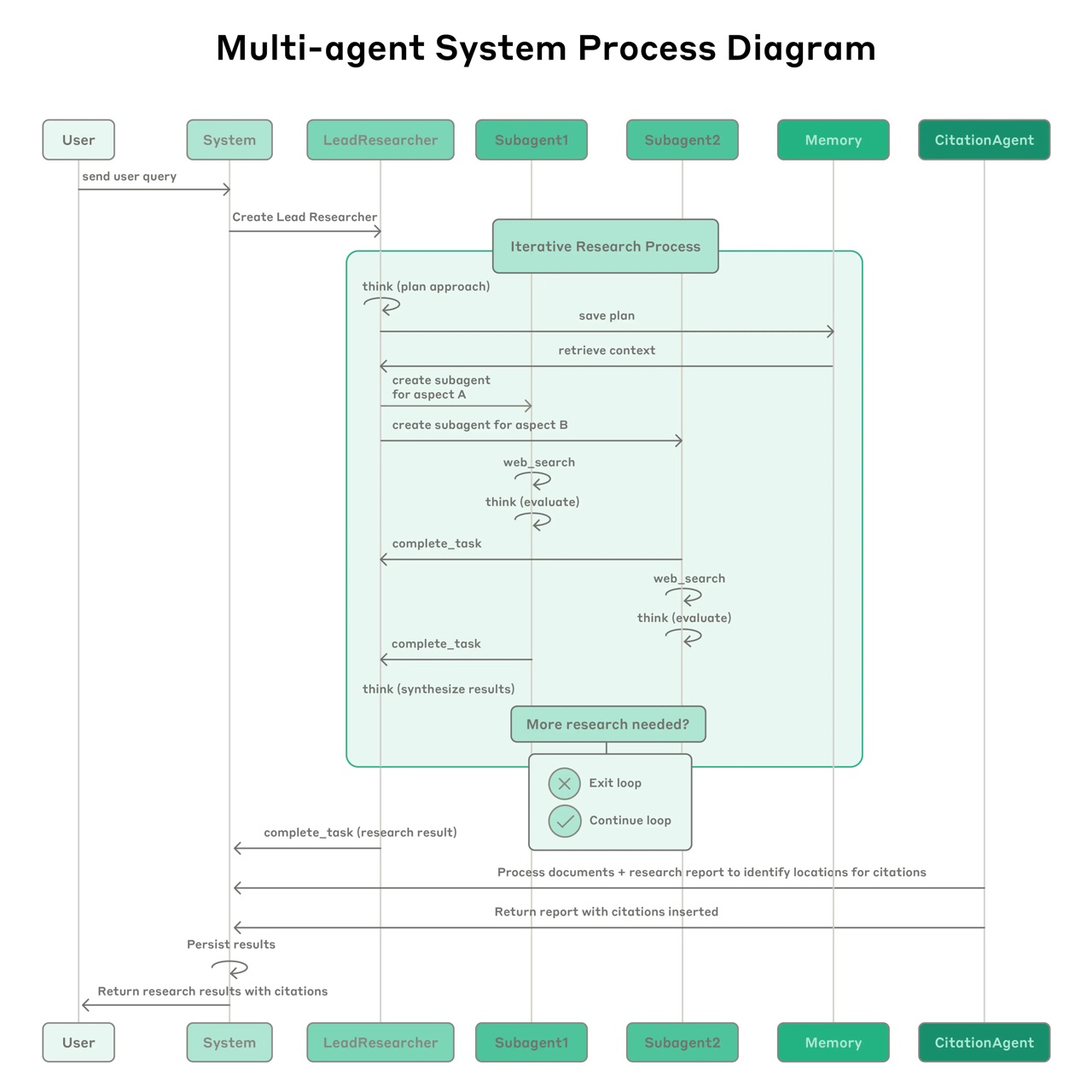
该流程与传统一次性 RAG 不同:它是“多步动态检索-分析-再检索”的闭环,可适应途中发现的新线索。
五、提示工程八条关键原则
-
与代理同频思考:
先用离线沙盒复现代理行为,再针对失败模式迭代提示。
-
教会主代理“如何分工”:
为子代理写清目标、输出格式、工具范围和边界。
-
让投入匹配任务复杂度:
- 如简单事实查询 1 个代理 ≤ 10 次调用
- 比较类任务 2-4 个代理,每个 10-15 次
- 复杂研究可 >10 个代理。
-
精心设计/挑选工具:
- 为每个工具写清“何时用、输入输出、限制”
- 每个工具需要独特目的和清晰描述
- 明确启发式规则:
- 首先检查所有可用工具
- 匹配工具使用与用户意图
- 优先使用专用工具而非通用工具
-
允许代理自我改进:
- 用“工具测试代理”自动优化工具描述
-
“先广后深”搜索策略:
- 从短、宽查询起步,再逐步收敛
-
显式引导思考过程:
- 利用 extended thinking 作为可控草稿板,持续检查计划与结果
-
双层并行化:
- 一次性并行启动 3-5 子代理,子代理内部并行 3+ 工具调用,可将复杂查询时间缩短 90%
-
启发式方法而非刚性规则
- 关注灌输良好的启发式方法
- 主动缓解意外副作用,设置明确护栏防止智能体失控
六、评估与观测
| 维度 | 方法 | 说明 |
|---|---|---|
| 自动评测 | “LLM-as-Judge” 五维评分:事实准确性 / 引文对应 / 覆盖度 / 源质量 / 工具效率 | 输出 0-1 得分与 Pass/Fail |
| 小样本回归 | 约 20 条真实用例持续回归 | 常见成功率从 30 % → 80 % |
| 人工灰盒 | 人工检查长尾偏差 | 修正 SEO 垃圾源 / PDF 选择错误等 |
七、工程与运维挑战
| 挑战 | 解决思路 |
|---|---|
| 长时态、状态持久 | 引入持久检查点与错误恢复,避免整链重跑;让模型自身识别并应对工具故障。 |
| 难以调试 & 不确定性 | 完整链路追踪 + 观察“决策模式”而非对话内容;采用渐进式rainbow deployment 保证旧新版本并存。 |
| 同步瓶颈 | 当前主代理须等待全部子代理完成;下一步目标是异步执行、动态派生,但需解决结果协调与一致性。 |
八、适用场景 & 局限
- 适合:需大规模并行搜索、超大上下文整合、复合工具链(如跨数据库+网页+私域文档)的问题。
- 暂不适合:强时序依赖或实时协作(如多人实时编码)、全部代理必须共享同一上下文的任务。
九、结论
MAS = 用 Token 换能力:
- 并行上下文突破单窗口限制
- “主-辅-引文”三层编排 + 动态检索链获得更完整答案
- 高成本意味着需聚焦高价值、可并行的问题
- 成功关键:提示工程 → 工具设计 → 可观测测试 → 可靠部署

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 17
17 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)