FLUX.1代码笔记
FLUX.1在16GB内存下运行,FLUX.1的结构,MM-DiT,Single-DiT
FLUX.1 是由Stable Diffusion模型核心团队重新组建的Black Forest Labs(黑森林实验室)发布的文生图大模型。
FLUX.1在16GB条件下运行
GPU内存16GB的条件下可以运行,使用8bit量化,T5大概需要8GB,FluxTransformer需要14GB,总的内存需要14GB。
只量化了T5和FluxTransformer这两个比较大的模型,CLIP和VAE比较小,可以不量化。
如果使用更少的内存,可以尝试4-bit 或者NF4量化。
在使用Flux的时候,一般设置negative_prompt为空,CFG的值为 1,对应的参数应该是"true_cfg_scale".
参数"guidance_scale"一般设置为大于1,值越大,生成的图像就和prompt越相关,但是以降低图像质量为代价。
from diffusers import BitsAndBytesConfig as DiffusersBitsAndBytesConfig
from transformers import BitsAndBytesConfig as TransformersBitsAndBytesConfig
from diffusers import FluxTransformer2DModel,FluxPipeline
from transformers import T5EncoderModel
import torch
import gc
def flush():
gc.collect()
torch.cuda.empty_cache()
model_id = "/disk2/modelscope/hub/black-forest-labs/FLUX___1-dev"
quant_config = TransformersBitsAndBytesConfig(load_in_8bit=True,)
text_encoder_2_8bit = T5EncoderModel.from_pretrained(
model_id,
subfolder="text_encoder_2",
quantization_config=quant_config,
torch_dtype=torch.float16,
)
pipe = FluxPipeline.from_pretrained(
model_id,
transformer=None,
vae = None,
text_encoder_2=text_encoder_2_8bit,
torch_dtype=torch.float16,
device_map="balanced",
)
with torch.no_grad():
prompt = "A cat holding a sign that says hello world"
negative_prompt = ''
prompt_embeds, pooled_prompt_embeds, text_ids = pipe.encode_prompt(prompt,prompt_2=None)
negative_prompt_embeds,negative_pooled_prompt_embeds, _ = pipe.encode_prompt(negative_prompt,prompt_2=None)
del text_encoder_2_8bit
del pipe
flush()
quant_config = DiffusersBitsAndBytesConfig(load_in_8bit=True,)
transformer_8bit = FluxTransformer2DModel.from_pretrained(
model_id,
subfolder="transformer",
quantization_config=quant_config,
torch_dtype=torch.float16,
)
pipe = FluxPipeline.from_pretrained(
model_id,
transformer=transformer_8bit,
text_encoder = None,
text_encoder_2=None,
torch_dtype=torch.float16,
device_map="balanced",
)
pipe_kwargs = {
"prompt_embeds":prompt_embeds,
"negative_prompt_embeds":negative_prompt_embeds,
"pooled_prompt_embeds":pooled_prompt_embeds,
"negative_pooled_prompt_embeds":negative_pooled_prompt_embeds,
"height": 1024,
"width": 1024,
"guidance_scale": 3.5,
"num_inference_steps": 20,
"max_sequence_length": 512,
}
image = pipe(**pipe_kwargs, generator=torch.manual_seed(0),).images[0]
image.save("flux_cat.jpg")
FLUX结构图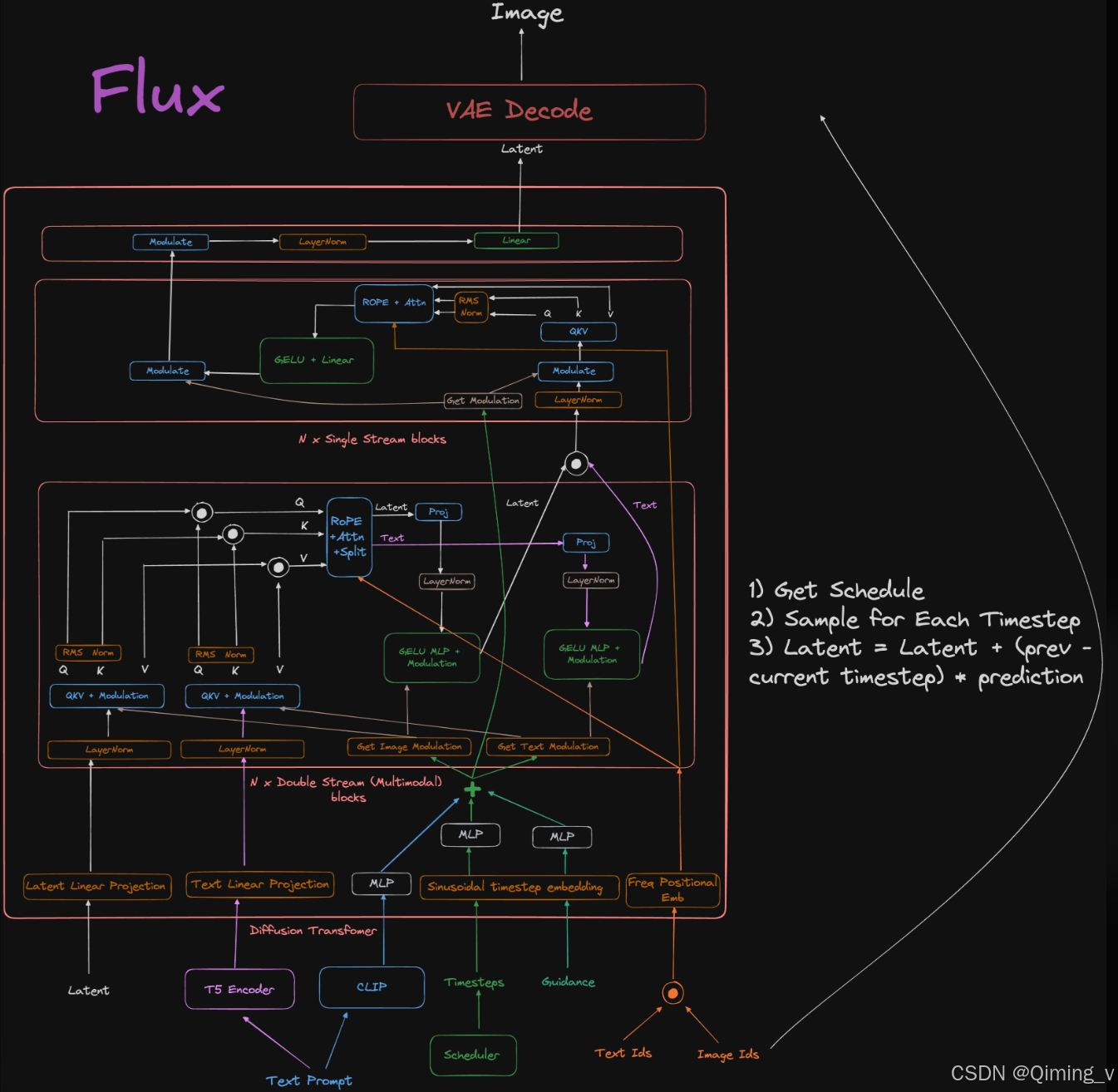 FLUX.1中使用了MM-DiT结构,latent和prompt encoder在经过了modulation后,分别生成QKV,再把两组QKV合并成新的QKV计算attention,然后再拆分成两部分,分别经过MLP和modulation,进入下一个循环。
FLUX.1中使用了MM-DiT结构,latent和prompt encoder在经过了modulation后,分别生成QKV,再把两组QKV合并成新的QKV计算attention,然后再拆分成两部分,分别经过MLP和modulation,进入下一个循环。
Single-DiT则是先把latent和prompt encoder合并,然后进入DiT。
encode_prompt
如果prompt_2为None,则等于prompt。
如果prompt_2和prompt发生了冲突的时候,结果会倾向prompt_2。prompt_2比prompt对结果的影响更大。
prompt 经过 CLIP生成的pooled_prompt_embeds 和 timestep,guidance参与了AdaLayerNormZero,modulation。
prompt_2 经过T5生成的prompt_embeds 参与了transformer的直接计算。
prompt_2 = prompt_2 or prompt
prompt_2 = [prompt_2] if isinstance(prompt_2, str) else prompt_2
# We only use the pooled prompt output from the CLIPTextModel
pooled_prompt_embeds = self._get_clip_prompt_embeds(
prompt=prompt,
device=device,
num_images_per_prompt=num_images_per_prompt,
)#(1,768)
prompt_embeds = self._get_t5_prompt_embeds(
prompt=prompt_2,
num_images_per_prompt=num_images_per_prompt,
max_sequence_length=max_sequence_length,
device=device,
)#(1,512,4096)
text_ids = torch.zeros(prompt_embeds.shape[1], 3).to(device=device, dtype=dtype)#(512,3)
prepare_latents
在Flux中,VAE仍然使用8倍压缩,但是channel数为16。
对于生成10241204的图片,latent的shape为(1,16,128,128),然后进行patchify,每个patch为22.变换shape为(1,4096,64)
latent_image_ids 则是3列,第0列为0,第1列为height的序号,第2列为width的序号,同样reshape为(4096, 3).
# VAE applies 8x compression on images but we must also account for packing which requires
# latent height and width to be divisible by 2.
height = 2 * (int(height) // (self.vae_scale_factor * 2))
width = 2 * (int(width) // (self.vae_scale_factor * 2))
shape = (batch_size, num_channels_latents, height, width) #(1,16,128,128)
latents = randn_tensor(shape, generator=generator, device=device, dtype=dtype)
latents = self._pack_latents(latents, batch_size, num_channels_latents, height, width) #(1,4096,64)
latent_image_ids = self._prepare_latent_image_ids(batch_size, height // 2, width // 2, device, dtype)
return latents, latent_image_ids
def _pack_latents(latents, batch_size, num_channels_latents, height, width):
latents = latents.view(batch_size, num_channels_latents, height // 2, 2, width // 2, 2)
latents = latents.permute(0, 2, 4, 1, 3, 5)
latents = latents.reshape(batch_size, (height // 2) * (width // 2), num_channels_latents * 4)
return latents
def _prepare_latent_image_ids(batch_size, height, width, device, dtype):
latent_image_ids = torch.zeros(height, width, 3)
latent_image_ids[..., 1] = latent_image_ids[..., 1] + torch.arange(height)[:, None]
latent_image_ids[..., 2] = latent_image_ids[..., 2] + torch.arange(width)[None, :]
latent_image_id_height, latent_image_id_width, latent_image_id_channels = latent_image_ids.shape
latent_image_ids = latent_image_ids.reshape(
latent_image_id_height * latent_image_id_width, latent_image_id_channels
)
return latent_image_ids.to(device=device, dtype=dtype)
Prepare timesteps
sigmas = np.linspace(1.0, 1 / num_inference_steps, num_inference_steps) if sigmas is None else sigmas
image_seq_len = latents.shape[1]
mu = calculate_shift(
image_seq_len,
self.scheduler.config.base_image_seq_len,
self.scheduler.config.max_image_seq_len,
self.scheduler.config.base_shift,
self.scheduler.config.max_shift,
)
timesteps, num_inference_steps = retrieve_timesteps(
self.scheduler,
num_inference_steps,
device,
sigmas=sigmas,
mu=mu,
)
num_warmup_steps = max(len(timesteps) - num_inference_steps * self.scheduler.order, 0)
self._num_timesteps = len(timesteps)
Denoising
具体的流程还是看图更直观。
noise_pred = self.transformer(
hidden_states=latents,
timestep=timestep / 1000,
guidance=guidance,
pooled_projections=pooled_prompt_embeds,#CLIP
encoder_hidden_states=prompt_embeds, #T5
txt_ids=text_ids,
img_ids=latent_image_ids,
joint_attention_kwargs=self.joint_attention_kwargs,
return_dict=False,
)[0]
下面是FluxTransformer2DModel的简化版forward函数,删除了if条件
hidden_states = self.x_embedder(hidden_states) #(1,4096,64) => (1,4096,3072)
#将timestep,guidance,pooled_projections映射到相同维度,然后直接相加。CombinedTimestepGuidanceTextProjEmbeddings
temb = self.time_text_embed(timestep, guidance, pooled_projections)
encoder_hidden_states = self.context_embedder(encoder_hidden_states) #T5
ids = torch.cat((txt_ids, img_ids), dim=0) #(512+4096,3)
image_rotary_emb = self.pos_embed(ids) #RoPE
# FluxTransformerBlock x19
encoder_hidden_states, hidden_states = block(
hidden_states=hidden_states, #(1,4096,3072)
encoder_hidden_states=encoder_hidden_states, #(1,512,3072)
temb=temb, #(1,3072)
image_rotary_emb=image_rotary_emb, #((4608,128),(4608,128))
joint_attention_kwargs=joint_attention_kwargs,
)
hidden_states = torch.cat([encoder_hidden_states, hidden_states], dim=1)
# FluxSingleTransformerBlock x38
hidden_states = block(
hidden_states=hidden_states, #(1,4608,3072)
temb=temb, #(1,3072)
image_rotary_emb=image_rotary_emb,
joint_attention_kwargs=joint_attention_kwargs,
)
hidden_states = hidden_states[:, encoder_hidden_states.shape[1] :, ...]
hidden_states = self.norm_out(hidden_states, temb)
output = self.proj_out(hidden_states)
self.time_text_embed
class CombinedTimestepGuidanceTextProjEmbeddings(nn.Module):
def __init__(self, embedding_dim, pooled_projection_dim):
super().__init__()
self.time_proj = Timesteps(num_channels=256, flip_sin_to_cos=True, downscale_freq_shift=0)
self.timestep_embedder = TimestepEmbedding(in_channels=256, time_embed_dim=embedding_dim)
self.guidance_embedder = TimestepEmbedding(in_channels=256, time_embed_dim=embedding_dim)
self.text_embedder = PixArtAlphaTextProjection(pooled_projection_dim, embedding_dim, act_fn="silu")
def forward(self, timestep, guidance, pooled_projection):
timesteps_proj = self.time_proj(timestep)
timesteps_emb = self.timestep_embedder(timesteps_proj.to(dtype=pooled_projection.dtype)) # (N, D)
guidance_proj = self.time_proj(guidance)
guidance_emb = self.guidance_embedder(guidance_proj.to(dtype=pooled_projection.dtype)) # (N, D)
time_guidance_emb = timesteps_emb + guidance_emb
pooled_projections = self.text_embedder(pooled_projection)
conditioning = time_guidance_emb + pooled_projections
return conditioning
FluxTransformerBlock
norm_hidden_states, gate_msa, shift_mlp, scale_mlp, gate_mlp = self.norm1(hidden_states, emb=temb)
norm_encoder_hidden_states, c_gate_msa, c_shift_mlp, c_scale_mlp, c_gate_mlp = self.norm1_context(
encoder_hidden_states, emb=temb
)
joint_attention_kwargs = joint_attention_kwargs or {}
# Attention.
attention_outputs = self.attn(
hidden_states=norm_hidden_states,
encoder_hidden_states=norm_encoder_hidden_states,
image_rotary_emb=image_rotary_emb,
**joint_attention_kwargs,
)
if len(attention_outputs) == 2:
attn_output, context_attn_output = attention_outputs
elif len(attention_outputs) == 3:
attn_output, context_attn_output, ip_attn_output = attention_outputs
# Process attention outputs for the `hidden_states`.
attn_output = gate_msa.unsqueeze(1) * attn_output
hidden_states = hidden_states + attn_output
norm_hidden_states = self.norm2(hidden_states)
norm_hidden_states = norm_hidden_states * (1 + scale_mlp[:, None]) + shift_mlp[:, None]
ff_output = self.ff(norm_hidden_states)
ff_output = gate_mlp.unsqueeze(1) * ff_output
hidden_states = hidden_states + ff_output
if len(attention_outputs) == 3:
hidden_states = hidden_states + ip_attn_output
# Process attention outputs for the `encoder_hidden_states`.
context_attn_output = c_gate_msa.unsqueeze(1) * context_attn_output
encoder_hidden_states = encoder_hidden_states + context_attn_output
norm_encoder_hidden_states = self.norm2_context(encoder_hidden_states)
norm_encoder_hidden_states = norm_encoder_hidden_states * (1 + c_scale_mlp[:, None]) + c_shift_mlp[:, None]
context_ff_output = self.ff_context(norm_encoder_hidden_states)
encoder_hidden_states = encoder_hidden_states + c_gate_mlp.unsqueeze(1) * context_ff_output
if encoder_hidden_states.dtype == torch.float16:
encoder_hidden_states = encoder_hidden_states.clip(-65504, 65504)
return encoder_hidden_states, hidden_states
FluxAttnProcessor2_0
class FluxAttnProcessor2_0:
"""Attention processor used typically in processing the SD3-like self-attention projections."""
def __init__(self):
if not hasattr(F, "scaled_dot_product_attention"):
raise ImportError("FluxAttnProcessor2_0 requires PyTorch 2.0, to use it, please upgrade PyTorch to 2.0.")
def __call__(
self,
attn: Attention,
hidden_states: torch.FloatTensor,
encoder_hidden_states: torch.FloatTensor = None,
attention_mask: Optional[torch.FloatTensor] = None,
image_rotary_emb: Optional[torch.Tensor] = None,
) -> torch.FloatTensor:
batch_size, _, _ = hidden_states.shape if encoder_hidden_states is None else encoder_hidden_states.shape
# `sample` projections.
query = attn.to_q(hidden_states)
key = attn.to_k(hidden_states)
value = attn.to_v(hidden_states)
inner_dim = key.shape[-1]
head_dim = inner_dim // attn.heads
query = query.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
key = key.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
value = value.view(batch_size, -1, attn.heads, head_dim).transpose(1, 2)
if attn.norm_q is not None:
query = attn.norm_q(query)
if attn.norm_k is not None:
key = attn.norm_k(key)
# the attention in FluxSingleTransformerBlock does not use `encoder_hidden_states`
if encoder_hidden_states is not None:
# `context` projections.
encoder_hidden_states_query_proj = attn.add_q_proj(encoder_hidden_states)
encoder_hidden_states_key_proj = attn.add_k_proj(encoder_hidden_states)
encoder_hidden_states_value_proj = attn.add_v_proj(encoder_hidden_states)
encoder_hidden_states_query_proj = encoder_hidden_states_query_proj.view(
batch_size, -1, attn.heads, head_dim
).transpose(1, 2)
encoder_hidden_states_key_proj = encoder_hidden_states_key_proj.view(
batch_size, -1, attn.heads, head_dim
).transpose(1, 2)
encoder_hidden_states_value_proj = encoder_hidden_states_value_proj.view(
batch_size, -1, attn.heads, head_dim
).transpose(1, 2)
if attn.norm_added_q is not None:
encoder_hidden_states_query_proj = attn.norm_added_q(encoder_hidden_states_query_proj)
if attn.norm_added_k is not None:
encoder_hidden_states_key_proj = attn.norm_added_k(encoder_hidden_states_key_proj)
# attention
query = torch.cat([encoder_hidden_states_query_proj, query], dim=2)
key = torch.cat([encoder_hidden_states_key_proj, key], dim=2)
value = torch.cat([encoder_hidden_states_value_proj, value], dim=2)
if image_rotary_emb is not None:
from .embeddings import apply_rotary_emb
query = apply_rotary_emb(query, image_rotary_emb)
key = apply_rotary_emb(key, image_rotary_emb)
hidden_states = F.scaled_dot_product_attention(
query, key, value, attn_mask=attention_mask, dropout_p=0.0, is_causal=False
)
hidden_states = hidden_states.transpose(1, 2).reshape(batch_size, -1, attn.heads * head_dim)
hidden_states = hidden_states.to(query.dtype)
if encoder_hidden_states is not None:
encoder_hidden_states, hidden_states = (
hidden_states[:, : encoder_hidden_states.shape[1]],
hidden_states[:, encoder_hidden_states.shape[1] :],
)
# linear proj
hidden_states = attn.to_out[0](hidden_states)
# dropout
hidden_states = attn.to_out[1](hidden_states)
encoder_hidden_states = attn.to_add_out(encoder_hidden_states)
return hidden_states, encoder_hidden_states
else:
return hidden_states
FluxSingleTransformerBlock
residual = hidden_states
norm_hidden_states, gate = self.norm(hidden_states, emb=temb)
mlp_hidden_states = self.act_mlp(self.proj_mlp(norm_hidden_states))
joint_attention_kwargs = joint_attention_kwargs or {}
attn_output = self.attn(
hidden_states=norm_hidden_states,
image_rotary_emb=image_rotary_emb,
**joint_attention_kwargs,
)
hidden_states = torch.cat([attn_output, mlp_hidden_states], dim=2)
gate = gate.unsqueeze(1)
hidden_states = gate * self.proj_out(hidden_states)
hidden_states = residual + hidden_states
if hidden_states.dtype == torch.float16:
hidden_states = hidden_states.clip(-65504, 65504)
return hidden_states

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 15
15 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)