基于deepspeed 官网api梳理出模型并行的调用案例
deepspeed 是一个实现模型并行的开源框架,但网上很难搜索到基于ds实现训练自己模型的代码。为此对deepspeed 官网api与豆包模型进行拷打,整理出可用的demo。。 ZeRO-1:减少优化器状态的内存占用。ZeRO-2:进一步减少梯度的内存占用。ZeRO-3:完全消除冗余,将模型参数也进行分区,显著减少内存占用,但通信开销增加。
官网地址:https://docs.deepspeed.org.cn/en/latest/
deepspeed 是一个实现模型并行的开源框架,但网上很难搜索到基于ds实现训练自己模型的代码。为此对deepspeed 官网api与豆包模型进行拷打,整理出可用的demo。
1、ZeRO优化
DeepSpeed 的 ZeRO(Zero Redundancy Optimizer)是一种优化技术,旨在通过减少冗余数据来优化模型的内存使用,从而允许训练更大的模型。ZeRO 分为三个主要优化级别:ZeRO-1、ZeRO-2 和 ZeRO-3。每个级别在前一个级别的基础上进一步减少内存占用。
ZeRO-1
- 优化器状态分区:ZeRO-1 将优化器状态(如动量、方差等)分布在多个 GPU 上,每个 GPU 只存储部分优化器状态,而不是完整的副本。这可以显著减少每个 GPU 上的内存占用。
- 内存节省:相比传统方法,ZeRO-1 可以将内存占用减少到原来的约 1/4。
ZeRO-2
- 梯度分区:在 ZeRO-1 的基础上,ZeRO-2 进一步对梯度进行分区。每个 GPU 只存储部分梯度,而不是完整的梯度。
- 内存节省:ZeRO-2 可以将内存占用进一步减少到原来的约 1/8。
ZeRO-3
- 参数分区:ZeRO-3 在 ZeRO-2 的基础上,进一步对模型参数进行分区。每个 GPU 只存储部分模型参数、部分梯度和部分优化器状态。
- 内存节省:在 ZeRO-3 模式下,内存占用的减少与数据并行度成线性关系。例如,在 64 个 GPU 的情况下,内存占用可以减少 64 倍。
- 通信开销:由于参数在多个 GPU 之间动态分配,ZeRO-3 的通信开销相对会增加。
ZeRO-Infinity
- 扩展性:ZeRO-Infinity 是 ZeRO-3 的扩展,它通过利用 NVMe SSD 来扩展 GPU 和 CPU 的内存,从而支持训练更大型的模型。
总结
- ZeRO-1:减少优化器状态的内存占用。
- ZeRO-2:进一步减少梯度的内存占用。
- ZeRO-3:完全消除冗余,将模型参数也进行分区,显著减少内存占用,但通信开销增加。
2、基本使用案例
在代码中添加ds能力,主要修改3点
1、在原有argparse参数列表中添加local_rank配置项(因为deepspeed会默认向代码训练命令中添加local_rank参数)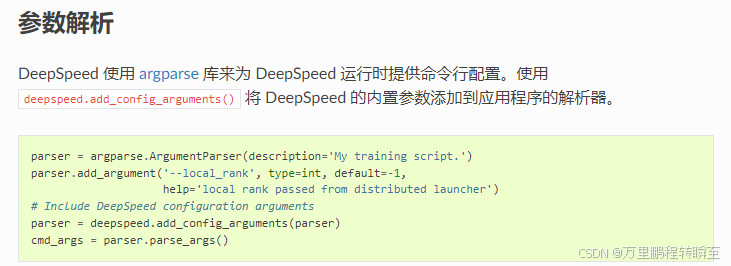
2、对模型、优化器进行ds初始化(在此前可以定义各种ZeRO-1、ZeRO-2 和 ZeRO-3的配置json,赋值给config参数传入到deepspeed.initialize中,)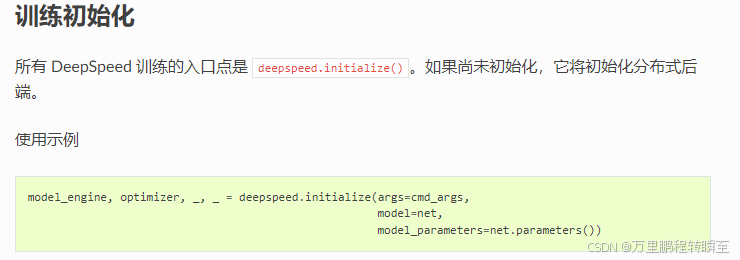
3、backward调整(将原来的backward修改为通过model对象调用)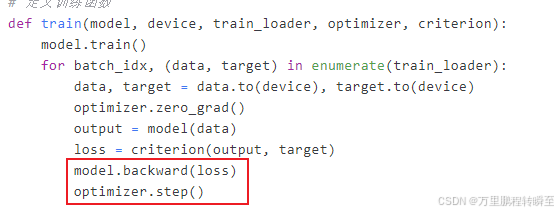
3、具体使用案例
以下是一个基于 PyTorch 和 DeepSpeed Zero3 在 8 卡 GPU 下训练 ResNet101 模型的示例代码:
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
import deepspeed
from torch.utils.data.distributed import DistributedSampler
from torch.nn.parallel import DistributedDataParallel as DDP
# 初始化 DeepSpeed 和分布式训练环境
deepspeed.init_distributed()
local_rank = torch.distributed.get_rank()
world_size = torch.distributed.get_world_size()
torch.cuda.set_device(local_rank)
# 数据预处理
transform = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
# 加载数据集
trainset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
train_sampler = DistributedSampler(trainset, num_replicas=world_size, rank=local_rank)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=128,
sampler=train_sampler)
# 加载 ResNet101 模型
model = torchvision.models.resnet101(pretrained=False)
num_ftrs = model.fc.in_features
model.fc = nn.Linear(num_ftrs, 10)
model = model.to(local_rank)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
parameters = filter(lambda p: p.requires_grad, model.parameters())
# DeepSpeed 配置
config = {
"fp16": {
"enabled": true,
"loss_scale": 0,
"initial_scale_power": 16,
"loss_scale_window": 1000,
"hysteresis": 2,
"min_loss_scale": 1
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": 0.0001,
"weight_decay": 0.01
}
},
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": 0,
"warmup_max_lr": 0.0001,
"warmup_num_steps": 500
}
},
"zero_optimization": {
"stage": 3, // 启用ZeRO-3阶段
"offload_optimizer": {
"device": "cpu"
},
"overlap_comm": true,
"contiguous_gradients": true,
"sub_group_size": 1e9,
"reduce_bucket_size": "auto",
"stage3_prefetch_bucket_size": "auto",
"stage3_param_persistence_threshold": "auto",
"stage3_max_live_parameters": 1e9,
"stage3_max_reuse_distance": 1e9,
"stage3_gather_16bit_weights_on_model_save": true
}
}
# 初始化 DeepSpeed 引擎
model, optimizer, _, _ = deepspeed.initialize(
model=model,
model_parameters=parameters,
config=config
)
# 训练模型
for epoch in range(10):
train_sampler.set_epoch(epoch)
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
inputs, labels = data[0].to(local_rank), data[1].to(local_rank)
outputs = model(inputs)
loss = criterion(outputs, labels)
model.backward(loss)
model.step()
running_loss += loss.item()
print(f'[Epoch {epoch + 1}] Loss: {running_loss / len(trainloader)}')
print('Finished Training')
#### 代码说明:
- 初始化:借助
deepspeed.init_distributed()对分布式训练环境进行初始化,同时设置本地的 GPU 设备。 - 数据加载:对 CIFAR - 10 数据集进行加载,并且使用
DistributedSampler来实现数据的分布式采样。 - 模型定义:加载 ResNet101 模型,并且对全连接层进行修改以适配 CIFAR - 10 数据集的 10 个类别。
- DeepSpeed 配置:对 DeepSpeed 的配置进行定义,包含优化器、混合精度训练以及 Zero3 优化等设置。
- DeepSpeed 引擎初始化:通过
deepspeed.initialize来初始化模型、优化器以及其他组件。 - 训练循环:在每个 epoch 中,对数据采样器的 epoch 进行设置,然后开展前向传播、反向传播以及参数更新等操作。
运行代码:
在 8 卡 GPU 环境下运行此代码,可使用以下命令:
deepspeed --num_gpus 8 deepspeed_resnet101_train.py
章节内容基于豆包大模型输出。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 11
11 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)