【大模型】RAG-BM25
BM25是信息检索中的一种排序函数,用于估计文档与给定搜索查询的相关性。它结合了文档长度归一化和术语频率饱和,从而增强了基本术语频率方法。BM25 可以通过将文档表示为术语重要性得分向量来生成稀疏嵌入,从而在稀疏向量空间中实现高效检索和排序。Score(D,Q) 是文档 D 与查询 Q 的相关性得分。qi 是查询中的第 i 个词。f(qi, D)是词 qi 在文档 D 中的频率。IDF(qi) 是
前言
BM25(Best Matching 25)是一种经典的信息检索算法,是基于Okapi TF-IDF算法的改进版本,旨在解决Okapi TF-IDF算法的一些不足之处。其被广泛应用于信息检索领域的排名函数,用于估计文档D与用户查询Q之间的相关性。它是一种基于概率检索框架的改进,特别是在处理长文档和短查询时表现出色。
BM25的核心思想是基于词频(TF)和逆文档频率(IDF)来,同时还引入了文档的长度信息来计算文档D和查询Q之间的相关性。目前被广泛运用的搜索引擎ES就内置了BM25算法进行全文检索。
1. BM25简介
BM25是信息检索中的一种排序函数,用于估计文档与给定搜索查询的相关性。它结合了文档长度归一化和术语频率饱和,从而增强了基本术语频率方法。BM25 可以通过将文档表示为术语重要性得分向量来生成稀疏嵌入,从而在稀疏向量空间中实现高效检索和排序。
BM25算法的基本公式如下:
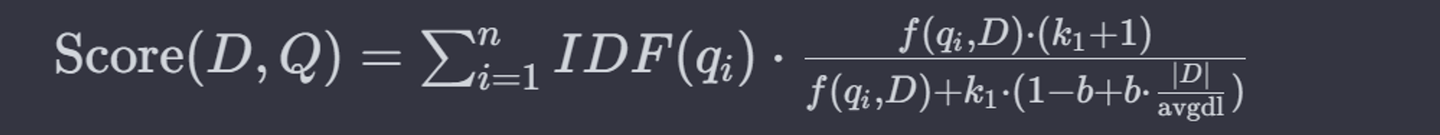
- Score(D,Q) 是文档 D 与查询 Q 的相关性得分。
- qi 是查询中的第 i 个词。
- f(qi, D)是词 qi 在文档 D 中的频率。
- IDF(qi) 是词qi 的逆文档频率。
- |D| 是文档 D的长度。
- avgdl是所有文档的平均长度。
- k1 和 b 是可调的参数,通常 k1 在1.2到2之间, b通常设为0.75。
2. 主要流程
(1)数据预处理
首先需要将文档进行数据预处理,包括分词、去除停用词、词干提取和标准化等步骤。
(2)计算文档和查询条件中各个项的得分函数
该步骤计算每个文档和查询条件中各个项的得分函数,并将其存储在倒排索引中。
(3)计算文档与查询条件之间的匹配程度
计算文档与查询条件之间的匹配程度得分。该步骤会计算所有匹配的文档的得分值,并按照得分值的大小对文档进行排序。
(4)返回最匹配的文档
3.python实现
import math
from collections import Counter
class BM25:
def __init__(self, docs, k1=1.5, b=0.75):
"""
BM25算法的构造器
:param docs: 分词后的文档列表,每个文档是一个包含词汇的列表
:param k1: BM25算法中的调节参数k1
:param b: BM25算法中的调节参数b
"""
self.docs = docs
self.k1 = k1
self.b = b
self.doc_len = [len(doc) for doc in docs] # 计算每个文档的长度
self.avgdl = sum(self.doc_len) / len(docs) # 计算所有文档的平均长度
self.doc_freqs = [] # 存储每个文档的词频
self.idf = {} # 存储每个词的逆文档频率
self.initialize()
def initialize(self):
"""
初始化方法,计算所有词的逆文档频率
"""
df = {} # 用于存储每个词在多少不同文档中出现
for doc in self.docs:
# 为每个文档创建一个词频统计
self.doc_freqs.append(Counter(doc))
# 更新df值
for word in set(doc):
df[word] = df.get(word, 0) + 1
# 计算每个词的IDF值
for word, freq in df.items():
self.idf[word] = math.log((len(self.docs) - freq + 0.5) / (freq + 0.5) + 1)
def score(self, doc, query):
"""
计算文档与查询的BM25得分
:param doc: 文档的索引
:param query: 查询词列表
:return: 该文档与查询的相关性得分
"""
score = 0.0
for word in query:
if word in self.doc_freqs[doc]:
freq = self.doc_freqs[doc][word] # 词在文档中的频率
# 应用BM25计算公式
score += (self.idf[word] * freq * (self.k1 + 1)) / (freq + self.k1 * (1 - self.b + self.b * self.doc_len[doc] / self.avgdl))
return score
# 示例文档集和查询
docs = [["the", "quick", "brown", "fox"],
["the", "lazy", "dog"],
["the", "quick", "dog"],
["the", "quick", "brown", "brown", "fox"]]
query = ["quick", "brown"]
# 初始化BM25模型并计算得分
bm25 = BM25(docs)
scores = [bm25.score(i, query) for i in range(len(docs))]
## query和文档的相关性得分:
## sores = [1.0192447810666774, 0.0, 0.3919504878447609, 1.2045355839511414] 在这个例子中,我们使用了四个文档和一个查询来计算相关性得分。查询是 ["quick", "brown"]。得分如下:
- 文档 1 ("the quick brown fox"): 得分约为 1.02
- 文档 2 ("the lazy dog"): 得分为 0.0(因为它不包含查询中的任何单词)
- 文档 3 ("the quick dog"): 得分约为 0.39
- 文档 4 ("the quick brown brown fox"): 得分约为 1.20
这些得分反映了每个文档与查询之间的相关性。得分越高,表示文档与查询的相关性越强。在这个例子中,文档 4 与查询的相关性最高,其次是文档 1,文档 3 的相关性较低,而文档 2 与查询没有相关性。
从结果来看,这个匹配算法确实能将最匹配的D找出来。Best Matching 25 其中25的含义是此算法经过 25 次迭代调整之后得到的,这也是这个匹配算法经久不衰的原因。
4.Milvues实现
from pymilvus.model.sparse.bm25.tokenizers import build_default_analyzer
from pymilvus.model.sparse import BM25EmbeddingFunction
# there are some built-in analyzers for several languages, now we use 'en' for English.
analyzer = build_default_analyzer(language="en")
corpus = [
"Artificial intelligence was founded as an academic discipline in 1956.",
"Alan Turing was the first person to conduct substantial research in AI.",
"Born in Maida Vale, London, Turing was raised in southern England.",
]
# analyzer can tokenize the text into tokens
tokens = analyzer(corpus[0])
print("tokens:", tokens)
#tokens: ['artifici', 'intellig', 'found', 'academ', 'disciplin', '1956']
参数:
-
语言(字符串)
要标记化的文本语言。有效选项为en(英语)、de(德语)、fr(法语)、ru(俄语)、sp(西班牙语)、it(意大利语)、pt(葡萄牙语)、zh(中文)、jp(日语)、kr(韩语)。
BM25 算法在处理文本时,首先使用内置分析器将文本分解成词块,如图所示的"artifici"、 "intellig "和"academ "等英语词块。然后,它收集这些词素的统计数据,评估它们在文档中的出现频率和分布情况。BM25 的核心是根据每个标记的重要性计算其相关性得分,较罕见的标记得分较高。这一简洁的过程可以根据与查询的相关性对文档进行有效的排序。要收集语料库的统计数据,请使用fit()方法。
bm25_ef = BM25EmbeddingFunction(analyzer)
bm25_ef.fit(corpus)
然后,使用encode_documents()为文档创建 Embeddings
docs = [
"The field of artificial intelligence was established as an academic subject in 1956.",
"Alan Turing was the pioneer in conducting significant research in artificial intelligence.",
"Originating in Maida Vale, London, Turing grew up in the southern regions of England.",
"In 1956, artificial intelligence emerged as a scholarly field.",
"Turing, originally from Maida Vale, London, was brought up in the south of England."
]
docs_embeddings = bm25_ef.encode_documents(docs)
print("Embeddings:", docs_embeddings)
print("Sparse dim:", bm25_ef.dim, list(docs_embeddings)[0].shape)
预期输出结果类似于下图
Embeddings: (0, 0) 1.0208816705336425
(0, 1) 1.0208816705336425
(0, 3) 1.0208816705336425
...
(4, 16) 0.9606986899563318
(4, 17) 0.9606986899563318
(4, 20) 0.9606986899563318
Sparse dim: 21 (1, 21)
使用encode_queries()方法为查询创建 embeddings
queries = ["When was artificial intelligence founded",
"Where was Alan Turing born?"]
query_embeddings = bm25_ef.encode_queries(queries)
print("Embeddings:", query_embeddings)
print("Sparse dim:", bm25_ef.dim, list(query_embeddings)[0].shape)预期输出类似于下图
Embeddings: (0, 0) 0.5108256237659907
(0, 1) 0.5108256237659907
(0, 2) 0.5108256237659907
(1, 6) 0.5108256237659907
(1, 7) 0.11554389108992644
(1, 14) 0.5108256237659907
Sparse dim: 21 (1, 21)
Reference

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 17
17 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)