论文阅读:ICML 2023-DetectGPT: Zero-Shot Machine-Generated Text Detection using Probability Curvature
随着大语言模型(LLMs)生成的文本越来越流畅,应用越来越广泛,识别这些文本的需求也愈发迫切。这篇论文的作者提出了一种名为DetectGPT的零样本机器生成文本检测方法,该方法主要基于以下发现:从大语言模型中采样生成的文本,往往位于模型对数概率函数的负曲率区域。
总目录 大模型安全相关研究:https://blog.csdn.net/WhiffeYF/article/details/142132328
DetectGPT: Zero-Shot Machine-Generated Text Detection using Probability Curvature
https://arxiv.org/pdf/2301.11305
https://www.doubao.com/chat/1697716286935042
文章目录
速览
随着大语言模型(LLMs)生成的文本越来越流畅,应用越来越广泛,识别这些文本的需求也愈发迫切。这篇论文的作者提出了一种名为DetectGPT的零样本机器生成文本检测方法,该方法主要基于以下发现:从大语言模型中采样生成的文本,往往位于模型对数概率函数的负曲率区域。下面详细介绍作者的方法:
- 核心假设:论文提出了 “局部扰动差异差距假设”。简单来说,模型生成文本经过微小改写后,在原模型下的对数概率往往比原文低;而人类书写的文本改写后,对数概率可能升高也可能降低。比如,对于大语言模型生成的句子 “鸟儿在天空中飞翔”,经过微小改写为 “小鸟在天空翱翔”,在原模型中,原文的对数概率会比改写后的高。但如果是人类写的句子,改写后的对数概率变化就不一定是降低的。
- 扰动差异的定义:为了利用上述假设,作者定义了扰动差异(perturbation discrepancy)。公式为 d ( x , p θ , q ) ≜ l o g p θ ( x ) − E x ~ ∼ q ( ⋅ ∣ x ) l o g p θ ( x ~ ) d\left(x, p_{\theta}, q\right) \triangleq log p_{\theta}(x)-\mathbb{E}_{\tilde{x} \sim q(\cdot | x)} log p_{\theta}(\tilde{x}) d(x,pθ,q)≜logpθ(x)−Ex~∼q(⋅∣x)logpθ(x~),其中 x x x是待检测文本, p θ p_{\theta} pθ是源模型, q ( ⋅ ∣ x ) q(\cdot | x) q(⋅∣x)是扰动函数,用于生成与 x x x类似的文本 x ~ \tilde{x} x~ 。直观理解就是,用一个函数 q q q对文本 x x x进行微小改写得到多个 x ~ \tilde{x} x~ ,然后比较 x x x在模型 p θ p_{\theta} pθ下的对数概率和这些 x ~ \tilde{x} x~在 p θ p_{\theta} pθ下对数概率的平均值,差值就是扰动差异。
- 计算与判断:在实际操作中,作者使用预训练的掩码填充模型(如T5)作为扰动函数 q q q。以一段文本为例,用T5对其进行多次微小改写(比如每次随机掩盖几个词并重新生成),得到多个扰动后的文本。然后计算原文本和这些扰动后文本在源模型下的对数概率,进而得到扰动差异。如果扰动差异大于某个阈值,就认为这段文本很可能是由该源模型生成的;反之,则可能不是。
- 方法优势:相比其他零样本检测方法,DetectGPT不需要训练单独的分类器,也不用收集真实或生成文本的数据集,更无需对生成文本进行显式水印处理。实验表明,DetectGPT在检测机器生成文本方面比现有零样本方法更准确,例如在检测由200亿参数的GPT - NeoX生成的假新闻文章时,其AUROC(一种衡量分类器性能的指标)从最强的零样本基线的0.81提升到了0.95 。
Abstract(摘要)
大语言模型(LLMs)如今生成的文本越来越流畅,应用也越来越广泛,这使得对应的检测大语言模型生成文本的工具变得很有必要。在这篇论文里,作者发现了大语言模型概率函数结构的一个特性,这个特性对检测模型生成的文本很有帮助。
具体来说,论文表明从大语言模型中采样得到的文本,往往会处在模型对数概率函数的负曲率区域。打个比方,假如把模型生成文本的过程想象成在一个特殊的 “概率地形” 上找位置,那么这些文本就像是经常出现在 “地势向下弯曲” 的地方。
基于这个发现,作者定义了一个新的、基于曲率的标准,用来判断一段文本是不是由某个特定的大语言模型生成的。这种方法被称为DetectGPT。它有几个优点,不需要专门去训练一个新的分类器,也不需要去收集真实的或者模型生成的文本数据集,更不需要给生成的文本加上明显的水印标记。它只需要用到模型对于我们感兴趣的那段文本的对数概率,以及对这段文本进行随机改动(扰动)后的对数概率。
举个例子,如果有一段待检测文本 “猫咪在花园里玩耍”,用DetectGPT的话,会先把它稍微改动一下,变成 “小猫在花园中嬉戏” 之类的,然后分别计算原文本和改动后文本在模型中的对数概率。
实验结果显示,和现有的零样本检测方法相比,DetectGPT在检测模型生成的样本方面更有辨别力。特别是在检测由拥有2000亿参数的GPT - NeoX生成的假新闻文章时,之前最强的零样本基线方法的检测效果用AUROC(一种评估指标)衡量是0.81,而DetectGPT能达到0.95 ,这表明DetectGPT的检测效果更好。如果想了解代码、数据以及其他项目信息,可以访问ericmitchell.ai/detectgpt 。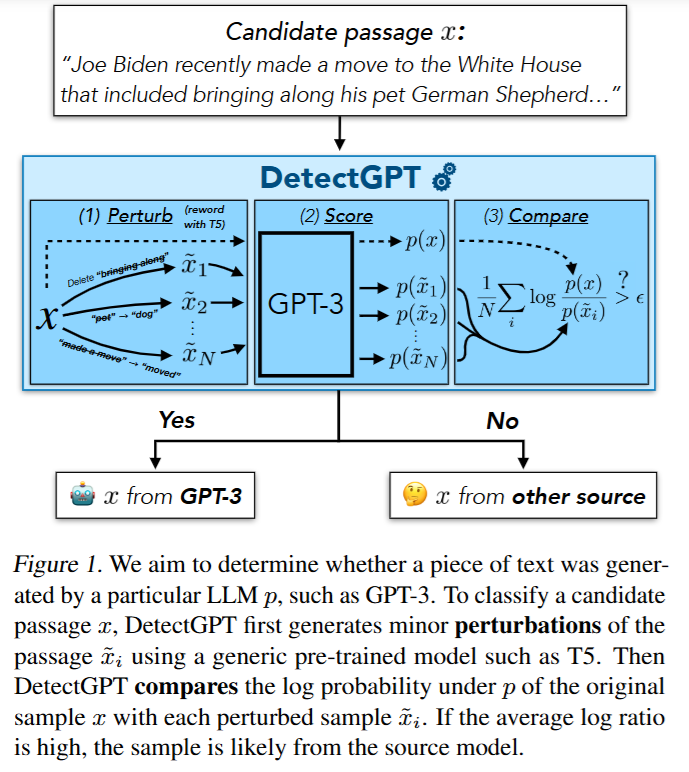
Figure 1
图1展示了DetectGPT判断一段文本是否由特定大语言模型(如GPT - 3)生成的过程。假设候选文本 x x x是 “Joe Biden recently made a move to the White House that included bringing along his pet German Shepherd…” 。首先,DetectGPT会使用通用的预训练模型(如T5)对这段文本进行一些小的改动,生成多个扰动后的文本 x 1 ~ \tilde{x_1} x1~、 x 2 ~ \tilde{x_2} x2~ 、 ⋯ \cdots ⋯ 、 x N ~ \tilde{x_N} xN~ 。然后,将原始文本 x x x和这些扰动后的文本都放入模型(如GPT - 3)中,计算它们各自的对数概率,分别是 p ( x ) p(x) p(x)、 p ( x 1 ~ ) p(\tilde{x_1}) p(x1~)、 p ( x 2 ~ ) p(\tilde{x_2}) p(x2~) 、 ⋯ \cdots ⋯ 、 p ( x N ~ ) p(\tilde{x_N}) p(xN~) 。接着,计算原始文本对数概率与每个扰动后文本对数概率比值的对数,再求这些对数的平均值 1 N ∑ i = 1 N log p ( x ) p ( x i ~ ) \frac{1}{N}\sum_{i = 1}^{N}\log\frac{p(x)}{p(\tilde{x_i})} N1∑i=1Nlogp(xi~)p(x) 。如果这个平均对数比率较高,就判断文本 x x x是由GPT - 3生成的;如果平均对数比率较低,则判断文本 x x x来自其他来源。
1. Introduction(引言)
大语言模型(LLMs)已被证实能够针对各种各样的用户提问,生成极为流畅的回答。像GPT - 3(布朗等人在2020年的研究成果)、PaLM(乔杜里等人在2022年的研究成果)以及ChatGPT(OpenAI在2022年推出)这些模型,可以很有说服力地回答关于科学、数学、历史、时事以及社会趋势等方面的复杂问题。
尽管最近有研究发现,大语言模型生成的听起来头头是道的回答,很多时候其实是错误的(林等人在2022年的研究),但这些生成文本条理清晰的特点,仍然使得大语言模型在某些领域有取代人力的潜力,特别是在学生写作文和新闻报道方面。至少有一家主流新闻媒体发布过经过少量人工审核的AI生成内容,结果导致一些文章出现了大量事实性错误(克里斯蒂安在2023年提到)。大语言模型的这些应用存在诸多问题,比如让学生评估变得不公平、影响学生学习,还会使看似可信实则错误的新闻文章大量传播。遗憾的是,人们在区分机器生成文本和人类撰写文本时,表现仅略好于随机猜测(格尔曼等人在2019年的研究),这促使研究人员去探索自动检测方法,以识别那些人类难以察觉的线索,从而让老师和读者对他们所接触文本的作者来源更有信心。
和之前的研究(贾瓦哈尔等人在2020年的研究)一样,本文将机器生成文本检测问题视为一个二分类问题,具体来说,就是要判断一段候选文本是不是由某个特定的模型生成的。虽然已经有不少研究尝试训练第二个深度网络来检测机器生成的文本,但这种方法存在一些不足。比如,容易对训练的主题过拟合,而且每当有新的模型发布,就需要重新训练一个新模型。因此,本文考虑零样本版本的机器生成文本检测,也就是直接使用源模型本身,不进行任何微调或适配,来检测其生成的样本。最常见的零样本机器生成文本检测方法是评估生成文本每个词的平均对数概率,然后设置一个阈值(索莱曼等人在2019年、格尔曼等人在2019年、伊波利托等人在2020年的研究)。然而,这种简单的方法忽略了在候选文本周围,已学习到的概率函数的局部结构,而本文发现这其中包含了关于文本来源的有用信息。
本文提出了一个简单的假设:对模型生成的文本进行小改动后,在该模型下的对数概率往往比原始样本更低;而对人类撰写的文本进行小改动,其对数概率可能比原始样本更高,也可能更低。换句话说,与人类撰写的文本不同,模型生成的文本往往处于对数概率函数具有负曲率的区域(例如,在对数概率的局部最大值附近)。本文通过实验验证了这个假设,并且发现,即使小改动或扰动来自其他语言模型,这个假设在各种大语言模型中都成立。基于这个发现,本文开发了DetectGPT,一种用于自动检测机器生成文本的零样本方法。为了测试一段文本是否来自源模型 p θ p_{\theta} pθ,DetectGPT会比较候选文本在 p θ p_{\theta} pθ下的对数概率,以及该文本的几个扰动版本在 p θ p_{\theta} pθ下的平均对数概率(比如用T5模型生成扰动版本;拉菲尔等人在2020年的研究)。如果扰动后的文本平均对数概率比原始文本低一定程度,那么这段候选文本很可能来自 p θ p_{\theta} pθ。图1展示了这个问题以及DetectGPT方法的大致情况,图2展示了上述假设的示意图,图3则是对该假设的实证评估。实验结果表明,在检测机器生成文本方面,DetectGPT比现有的零样本方法更准确,在检测机器生成的新闻文章时,对于多个源模型,其AUROC比最强的零样本基线高出了0.1以上。
本文的主要贡献包括:
(a)发现并通过实验验证了一个假设,即模型样本处的对数概率函数的曲率,比人类文本的曲率要显著更负;
(b)DetectGPT,这是一种受该假设启发的实用算法,它通过近似对数概率函数的海森矩阵的迹,来检测模型生成的样本。
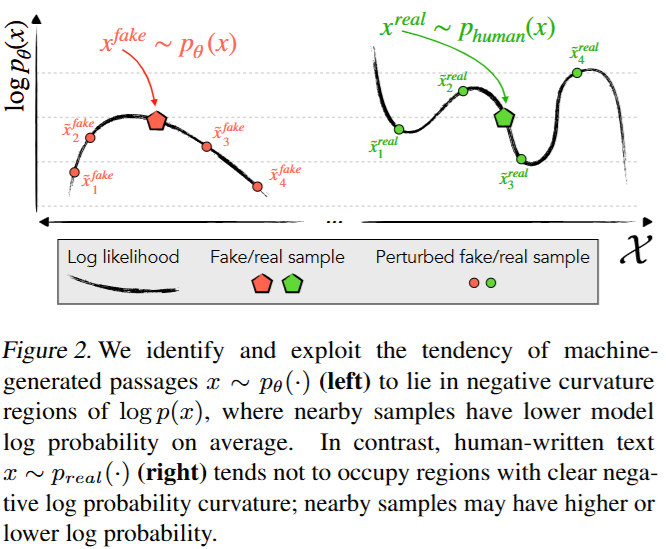
Figure 2
图2展示了机器生成文本和人类撰写文本在对数概率函数上的不同表现。左边部分表示机器生成的文本 x f a k e ∼ p θ ( x ) x^{fake} \sim p_{\theta}(x) xfake∼pθ(x) ,这类文本倾向于处于对数概率函数 log p θ ( x ) \log p_{\theta}(x) logpθ(x)的负曲率区域。可以想象成在这个对数概率的 “地形” 图上,机器生成文本所在的地方是向下弯曲的。在这种情况下,附近的样本(即经过扰动后的文本 x 1 ~ f a k e \tilde{x_1}^{fake} x1~fake、 x 2 ~ f a k e \tilde{x_2}^{fake} x2~fake、 x 3 ~ f a k e \tilde{x_3}^{fake} x3~fake、 x 4 ~ f a k e \tilde{x_4}^{fake} x4~fake )平均具有较低的模型对数概率。比如机器生成文本 “小狗在草地上欢快地跑着” ,对其进行扰动得到 “幼犬在草坪上开心地奔跑” 等,这些扰动后的文本在原模型中的对数概率通常比原句低。
右边部分表示人类撰写的文本 x r e a l ∼ p h u m a n ( x ) x^{real} \sim p_{human}(x) xreal∼phuman(x) ,这类文本往往不会处于具有明显负对数概率曲率的区域。也就是说,在对数概率的 “地形” 图上,没有明显的向下弯曲趋势。附近的样本(即经过扰动后的文本 x 1 ~ r e a l \tilde{x_1}^{real} x1~real、 x 2 ~ r e a l \tilde{x_2}^{real} x2~real、 x 3 ~ r e a l \tilde{x_3}^{real} x3~real、 x 4 ~ r e a l \tilde{x_4}^{real} x4~real )的对数概率可能比原始文本高,也可能比原始文本低。例如人类写 “今天的天空格外湛蓝,让人心情舒畅” ,对其进行扰动后,新文本的对数概率不一定比原句低。
2. Related Work(相关研究)
越来越大规模的大语言模型(如拉德福德等人在2019年、布朗等人在2020年、乔杜里等人在2022年、OpenAI在2022年、张等人在2022年的研究成果),使得在许多与语言相关的基准测试中性能大幅提升,并且具备了生成令人信服且切题文本的能力。GROVER(泽勒斯等人在2019年的研究)是第一个专门为生成看似合理的新闻文章而训练的大语言模型。人工评估者发现,GROVER生成的宣传内容至少和人类撰写的宣传内容一样值得信赖,这促使其作者通过在GROVER的特征之上微调一个检测器,来研究它检测自身生成内容的能力;他们发现,GROVER在检测自己生成的文本方面,比其他预训练模型表现更好。不过,巴赫金等人在2019年以及乌琴杜等人在2020年指出,专门为检测机器生成文本而训练的模型,往往会过度拟合它们训练时的数据分布或源模型。
其他一些研究则在神经表示(巴赫金等人在2019年、索莱曼等人在2019年、乌琴杜等人在2020年、伊波利托等人在2020年、法尼等人在2021年的研究)、词袋特征(索莱曼等人在2019年、法尼等人在2021年的研究)以及手工制作的统计特征(格尔曼等人在2019年的研究)的基础上,训练有监督的模型来检测机器生成的文本。另外,索莱曼等人在2019年注意到一种简单的零样本机器生成文本检测方法,有着出乎意料的效果,该方法根据候选文本在生成模型下的平均对数概率设置阈值,在本文的研究中,它是零样本机器生成文本检测的一个强有力基线。在本文中,同样以零样本的方式使用生成模型来检测其自身生成的内容,但采用的是一种不同的方法,即基于估计样本周围对数概率的局部曲率,而不是样本本身的原始对数概率。若想全面了解机器生成文本检测方面的研究,可以参考贾瓦哈尔等人在2020年的综述。还有其他研究探索了为生成文本添加水印的方法(基兴鲍尔等人在2023年的研究),通过修改模型生成的内容,使其更容易被检测到。本文的研究并不假定文本生成的目的是为了便于检测;DetectGPT使用标准的大语言模型采样策略,来检测从公开可用的大语言模型生成的文本。
大语言模型的广泛应用引发了许多其他关于检测大语言模型输出的同期研究。萨达西万等人在2023年指出,一个检测器的检测AUROC(一种评估指标)上限,是由模型和人类文本之间的总变差距离(TV距离)的函数决定的。然而,本文发现,即使对于最大的公开可用模型,DetectGPT的AUROC也很高(见表2),这表明TV距离可能与模型的规模和能力没有很强的相关性。除了最大似然之外的新训练目标,比如基于人类反馈的强化学习(克里斯蒂亚诺等人在2017年、齐格勒等人在2020年的研究),可能会加剧这种脱节。萨达西万等人在2023年以及克里希纳等人在2023年都表明,释义(改写文本)作为一种逃避检测的工具是有效的,这为未来的研究指出了一个重要方向。梁等人在2023年指出,多语言检测很困难,非DetectGPT的检测器对非母语者存在偏见;这个结果凸显了像DetectGPT这样的零样本检测器的优势,即它们能很好地适用于原始生成模型生成的任何数据。米雷什加拉等人在2023年研究了在生成模型未知的情况下,哪些代理评分模型能产生对检测最有用的对数概率(类似于本文图6的大规模版本)。令人惊讶的是(但与本文的发现一致),他们发现较小的模型实际上是更好的代理模型,适用于像DetectGPT这样基于扰动的检测方法。
机器生成文本检测的问题,让人联想到早期关于检测深度伪造内容(即由深度网络生成的人工图像或视频)的研究,这引发了在检测虚假视觉内容方面的大量努力(多尔汉斯基等人在2020年、子等人在2020年的研究)。虽然深度伪造检测的早期研究使用的是相对通用的模型架构(盖拉和德尔普在2018年的研究),但许多深度伪造检测方法依赖图像数据的连续性来实现最先进的性能(赵等人在2021年、瓜尔内拉等人在2020年的研究),这使得将其直接应用于文本检测变得困难 。
3. The Zero-Shot Machine-Generated Text Detection Problem(零样本机器生成文本检测问题)
本文研究的是零样本机器生成文本检测,也就是判断一段文本,或者说候选文本 x x x,是不是来自源模型 p θ p_{\theta} pθ的一个样本。之所以称为零样本,是因为在进行检测时,不依靠人类撰写的样本或者其他模型生成的样本来辅助判断。
和之前的研究一样,本文采用 “白盒” 设置(格尔曼等人在2019年的研究),在这种设置下,检测器可以评估样本的对数概率 log p θ ( x ) \log p_{\theta}(x) logpθ(x)。这里的白盒设置并不意味着要知道模型的架构或者参数。大多数大语言模型的公共API(比如GPT - 3)都支持对文本进行打分,不过也有一些例外,比如ChatGPT。虽然本文的大多数实验都是在白盒设置下进行的,但在5.2节中,也有使用源模型之外的其他模型对文本进行打分的实验。米雷什加拉等人在2023年对这种设置进行了全面评估。
本文提出的检测标准DetectGPT,还会利用通用的预训练掩码填充模型,来生成与候选文本 “相近” 的文本段落。不过,这些掩码填充模型是直接拿来使用的,不需要针对目标领域进行任何微调或适配。例如,要检测一段关于 “环保” 的文本是否是由某个大语言模型生成的,会用掩码填充模型对这段文本进行一些改动,生成类似的文本,然后进行后续检测操作。

Algorithm 1(算法1:DetectGPT模型生成文本检测)
- 输入:需要检测的文本段落 x x x,源模型 p θ p_{\theta} pθ(也就是怀疑文本可能由其生成的模型),扰动函数 q q q(用于对文本进行改动),扰动的次数 k k k(即要生成多少个改动后的文本),决策阈值 ϵ \epsilon ϵ(用于判断文本是否为模型生成的标准数值)。
- 利用扰动函数 q q q对文本 x x x进行 k k k次扰动,生成 k k k个新的文本 x ~ i \tilde{x}_i x~i, i ∈ [ 1.. k ] i \in [1..k] i∈[1..k] 。扰动方式可以是掩码片段(比如把文本中的某些词用掩码代替后再生成新的词)、样本替换等。例如,对于文本 “小猫在沙发上睡觉”,可能会生成 “猫咪在沙发上休憩” 这样的扰动文本。
- 计算这 k k k个扰动后文本的对数概率的平均值 μ ~ \tilde{\mu} μ~ ,公式为 μ ~ ← 1 k ∑ i log p θ ( x ~ i ) \tilde{\mu} \leftarrow \frac{1}{k}\sum_{i} \log p_{\theta}(\tilde{x}_i) μ~←k1∑ilogpθ(x~i) 。这一步是为了近似公式1中的期望。
- 计算一个值 d ^ x \hat{d}_x d^x ,公式为 d ^ x ← log p θ ( x ) − μ ~ \hat{d}_x \leftarrow \log p_{\theta}(x) - \tilde{\mu} d^x←logpθ(x)−μ~ ,这是对 d ( x , p θ , q ) d(x, p_{\theta}, q) d(x,pθ,q)的一个估计。简单理解就是原文本对数概率和扰动后文本平均对数概率的差值,差值越大,说明原文本和扰动后文本的差异越大。
- 计算方差 σ ~ x 2 \tilde{\sigma}^2_x σ~x2 ,公式为 σ ~ x 2 ← 1 k − 1 ∑ i ( log p θ ( x ~ i ) − μ ~ ) 2 \tilde{\sigma}^2_x \leftarrow \frac{1}{k - 1}\sum_{i}(\log p_{\theta}(\tilde{x}_i) - \tilde{\mu})^2 σ~x2←k−11∑i(logpθ(x~i)−μ~)2 ,用于后续的归一化操作。方差反映了这些扰动后文本对数概率的波动情况。
- 计算 d ^ x σ ~ x 2 \frac{\hat{d}_x}{\sqrt{\tilde{\sigma}^2_x}} σ~x2d^x ,并与决策阈值 ϵ \epsilon ϵ比较:
- 如果 d ^ x σ ~ x 2 > ϵ \frac{\hat{d}_x}{\sqrt{\tilde{\sigma}^2_x}} > \epsilon σ~x2d^x>ϵ ,就返回 “true”,表示这段文本很可能是模型生成的样本。比如设定阈值 ϵ \epsilon ϵ为0.5,计算得到的 d ^ x σ ~ x 2 \frac{\hat{d}_x}{\sqrt{\tilde{\sigma}^2_x}} σ~x2d^x为0.6,那就判断文本是模型生成的。
- 如果 d ^ x σ ~ x 2 ≤ ϵ \frac{\hat{d}_x}{\sqrt{\tilde{\sigma}^2_x}} \leq \epsilon σ~x2d^x≤ϵ ,就返回 “false”,表示这段文本很可能不是模型生成的样本。
github
https://github.com/eric-mitchell/detect-gpt
核心功能:提供一种零样本的方法来检测机器生成的文本,利用概率曲率这一技术实现文本检测。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 29
29 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)