使用ray + vllm + deviceplugin + helm做双机并推跑qwen3-235b-a22b模型
本文总结了双机并推部署过程中的关键经验与误区。1) 只需使用自带Ray的vllm镜像,无需额外部署Ray集群;2) Ray-head节点可同时承担计算任务;3) 统一镜像确保环境一致性;4) 建议使用RDMA网络提升通信效率;5) Qwen3-235B需特定版本支持。最后展示了Qwen3-8B多机并推的成功案例,并附有相关技术文档参考。
踩坑两天多终于成功部署了双机并推,记录一下几个误区
由于从来没有用过ray,加上教程比较少,基本靠gpt加尝试确定以下几点
- 可以不用kuberay,可以不用单独跑ray的pod
- 做双机并推只需要1个镜像,vllm的镜像就可以了,kuberay,ray的单独镜像都不需要,因为vllm镜像内带了简易版本的ray,所以可以把ray和vllm一起跑,声明statfulset来启动ray-head和ray-worker
- ray-head并不是只负责任务分发,ray-head作为集群的一员也可以跑模型(也就是说有head的节点不需要再启动一个worker了),ray-head负责启动vllm serve,ray-worker负责在其他节点/设备上做head分发过来的计算任务。
- 不用把vllm serve和ray分开的原因有很多,比如,ray对于版本要求很严格,ray和python版本小版本都必须一致,所以在vllm的镜像里面用ray工具就行,保证head和worker都是一个镜像,环境一致。
- 如果用默认的tcp/ip网络,通信速度会很慢,导致每秒生成的token很少,可以用rdma网络加速。
- qwen3-235b需要用vllm:v0.85.post1以上的版本,需要sglang>=0.4.6.post1 or vllm>=0.8.5
下面是使用qwen3-8b做示范成功用ray跑多机并推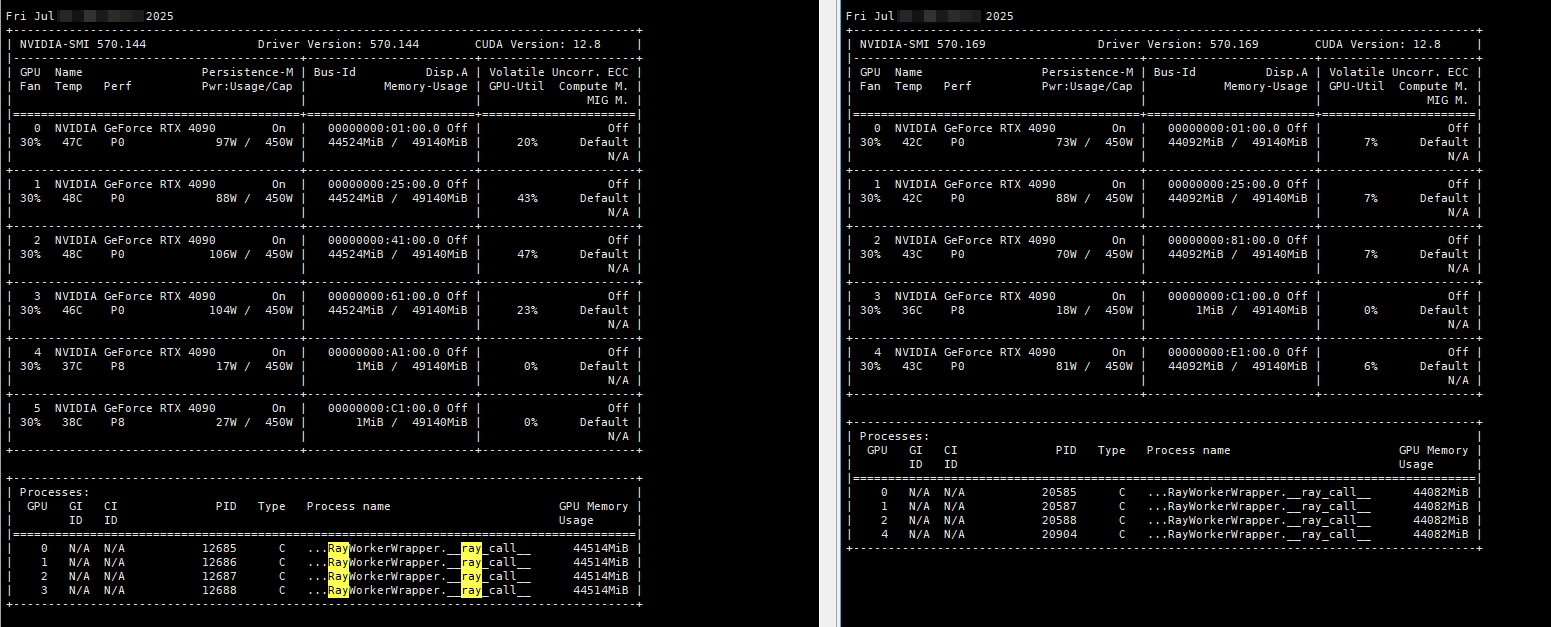
参考文章:
https://huggingface.co/Qwen/Qwen3-235B-A22B/blob/refs%2Fpr%2F23/README.md
https://developer.aliyun.com/article/1539196
https://docs.vllm.ai/en/v0.5.1/serving/distributed_serving.html
https://docs.vllm.ai/en/v0.8.0/getting_started/troubleshooting.html#troubleshooting-incorrect-hardware-driver
https://zhuanlan.zhihu.com/p/1914325502921016042
https://zhuanlan.zhihu.com/p/1902835927396652806
https://zhuanlan.zhihu.com/p/1903867484429353303
https://github.com/QwenLM/Qwen3/issues/1339
https://mp.weixin.qq.com/s/U6X-LaujEG1ebeUUaYk_kg
https://time.geekbang.org/column/article/860426
https://blog.csdn.net/weixin_54510197/article/details/148430313

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 5
5 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)