2025⼤模型训练与推理硬件采购及配置指南
⽬前主流GPU⼤模型推理与训练性能⽐较。

深度学习&⼤模型训练与推理——硬件配置指南
content
-
Part 1.读懂GPU性能:GPU性能核⼼参数介绍
-
Part 2.现阶段主流显卡(从2080到H100)性能分析
-
Part 3.各类⼤模型推理、微调、预训练所需显存
-
Part 4.从个⼈实验到70B模型推理,各类场景下硬件配置⽅案推荐
公开课附赠独家硬件配置指南表
-
显卡性能排名表
-
显卡性价⽐排名表
-
热⻔显卡参数对⽐表
-
各参数⼤模型训练所需硬件表
-
各参数⼤模型微调&推理硬件表
-
不同需求下硬件配置表
一、读懂显卡参数,GPU核⼼性能参数介绍
常⻅的显卡介绍
-
RTX系列显卡的游戏性能:⼀分钱⼀分货。但是⼤模型⽅⾯的计算性能却并⾮如此。
-
例如4090游戏性能⼏乎是3090的两倍,但若换算为单位⼈⺠币可以买到的⼤模型训练性能,3090是4090的 1.5倍;



NVIDIA DGX H200产品介绍
GPU计算性能核⼼参数
-
CUDA Cores:CUDA核⼼
-
Tensor Cores:张量计算核⼼
-
GPU Memory:显存
-
FLOPS:每秒浮点计算次数
-
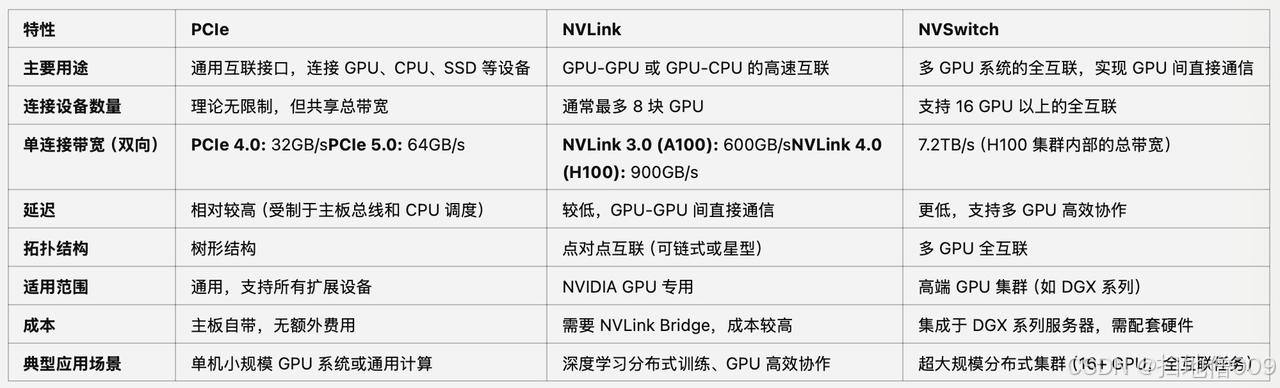
NVLink&NVSwitch:显卡桥接
-
TDP:最⼤功耗需求
GPU计算性能核⼼参数详细介绍
-
CUDA Cores:CUDA核⼼,是 NVIDIA GPU 的基础计算单元,负责执⾏并⾏计算任务;
-
Tensor Cores:张量计算核⼼,是专⻔设计⽤于矩阵运算的硬件单元,核⼼任务是加速矩阵乘法,特别是⽤于深度学习的张量运算,其中20系显卡开始加⼊张量核⼼;
-
GPU Memory:显存,决定了可以加载的模型⼤⼩、数据批量(Batch Size)以及中间激活值存储,显存不⾜会限制任务规模,甚⾄导致程序崩溃;
-
FLOPS:每秒浮点计算次数,是衡量 GPU 浮点运算性能的单位,代表GPU的理论性能;
-
NVLink&NVSwitch:显卡桥接技术,30系显卡取消了NVLink,替代⽅案是PCIE,⽬前 NVLink只⽤于企业级图形显卡;
PCIe、NVLink与NVSwitch技术⽅案介绍介绍与对⽐
RTX显卡信息
-
NVIDIA Gaming Graphics Card

英伟达官⽹地址:https://www.nvidia.com/en-us/geforce/graphics-cards/
3090 vs 4090显卡核⼼参数对⽐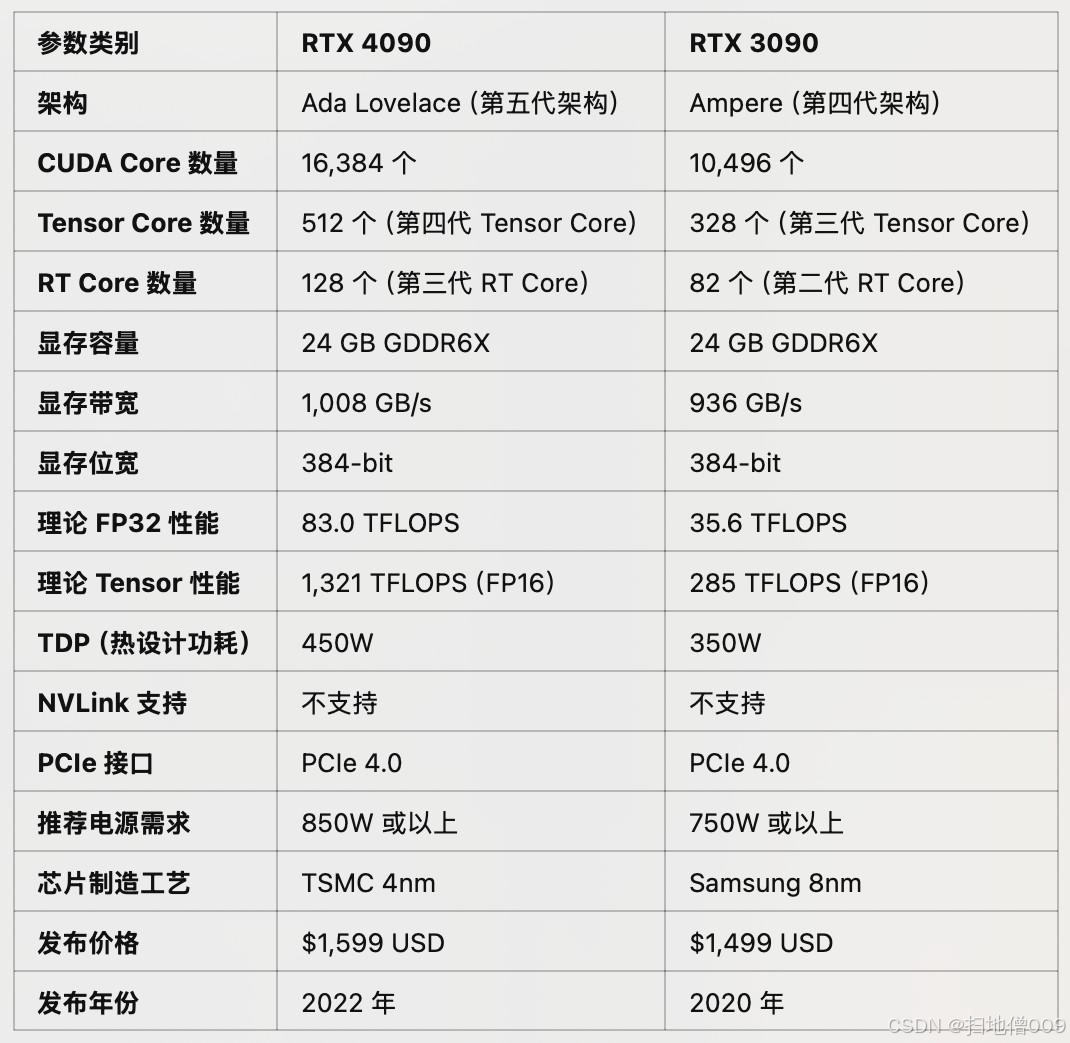
-
CUDA Cores:增加了56%
-
Tensor Cores:提升了4.6倍
-
显存带宽:RTX 4090 带宽更⾼
(1,008 GB/s vs 936 GB/s)
-
RTX 4090 的第四代 Tensor Core 引⼊ FP8 ⽀持,更适合低精度推理任务。
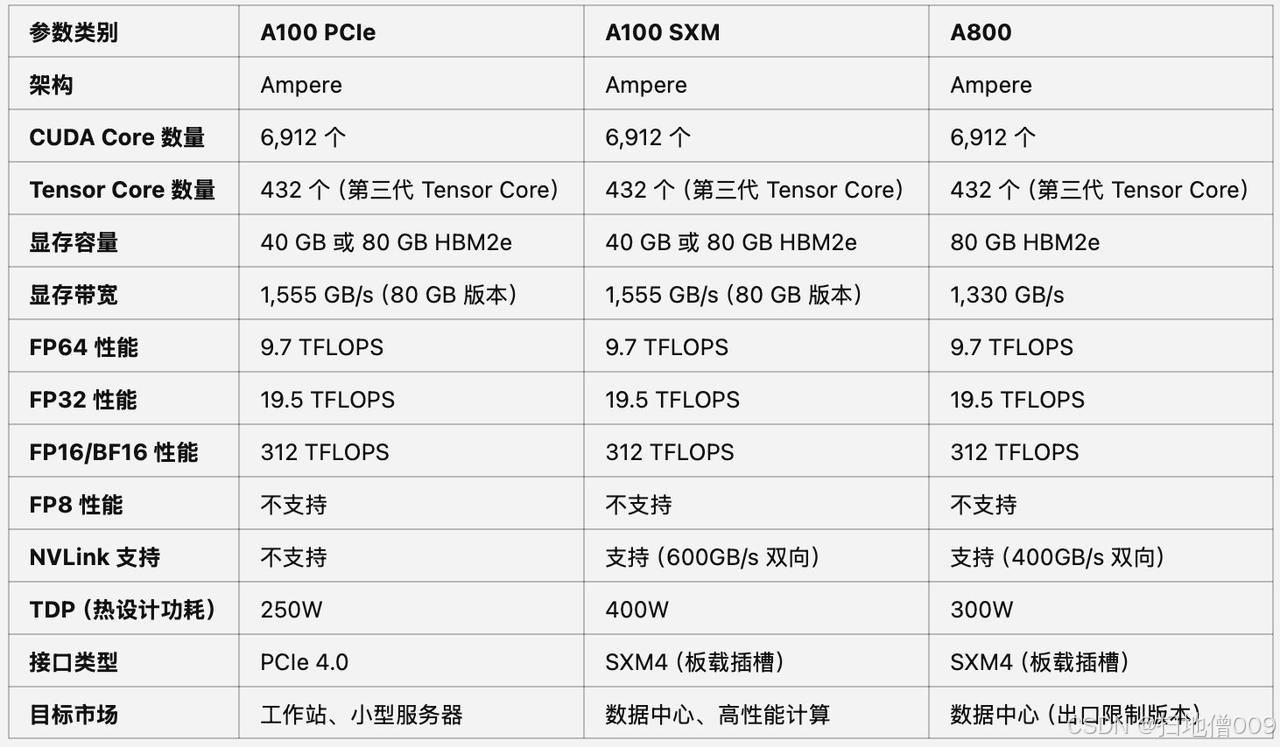
A100 PCIe&SXM、A800显卡参数对⽐
-
A800是A100的“中国特供 版”,在显存带宽和NVLink带宽上有所限制
-
其他参数都⼀样,两类卡性能差异不超过20%

NVIDIA显卡介绍列表:https://resources.nvidia.com/l/en-us-gpu?ncid=no-ncid
二、认识⽬前主流显卡,NVIDIA主流显卡命名规则
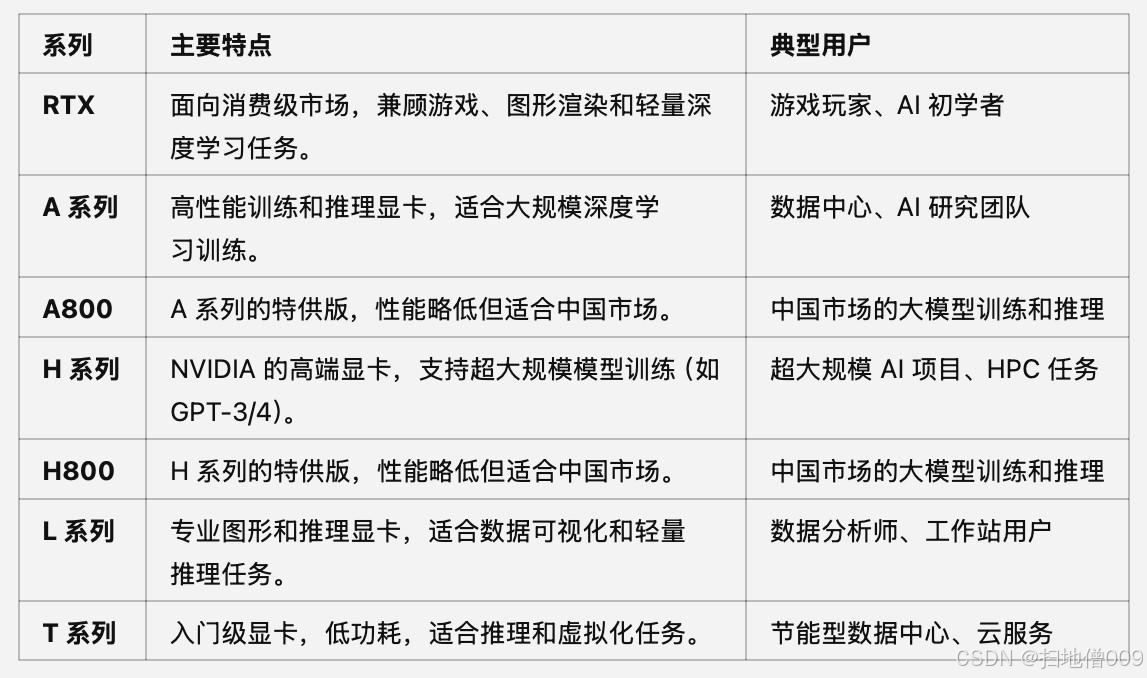
NVIDIA显卡主要分类及命名规则

NVIDIA各类显卡功能说明

NVIDIA各类显卡功能说明





NVIDIA各类显卡功能总结
三、⽬前主流GPU⼤模型推理与训练性能⽐较
主流GPU性能对⽐
说明:
-
不区分数据中⼼显卡和消费级显卡;
-
不区分原版显卡与中国特供版显卡;
-
统计信息截⽌到H100系列显卡;
-
显卡性能受架构、核⼼数、带宽等综合影响;
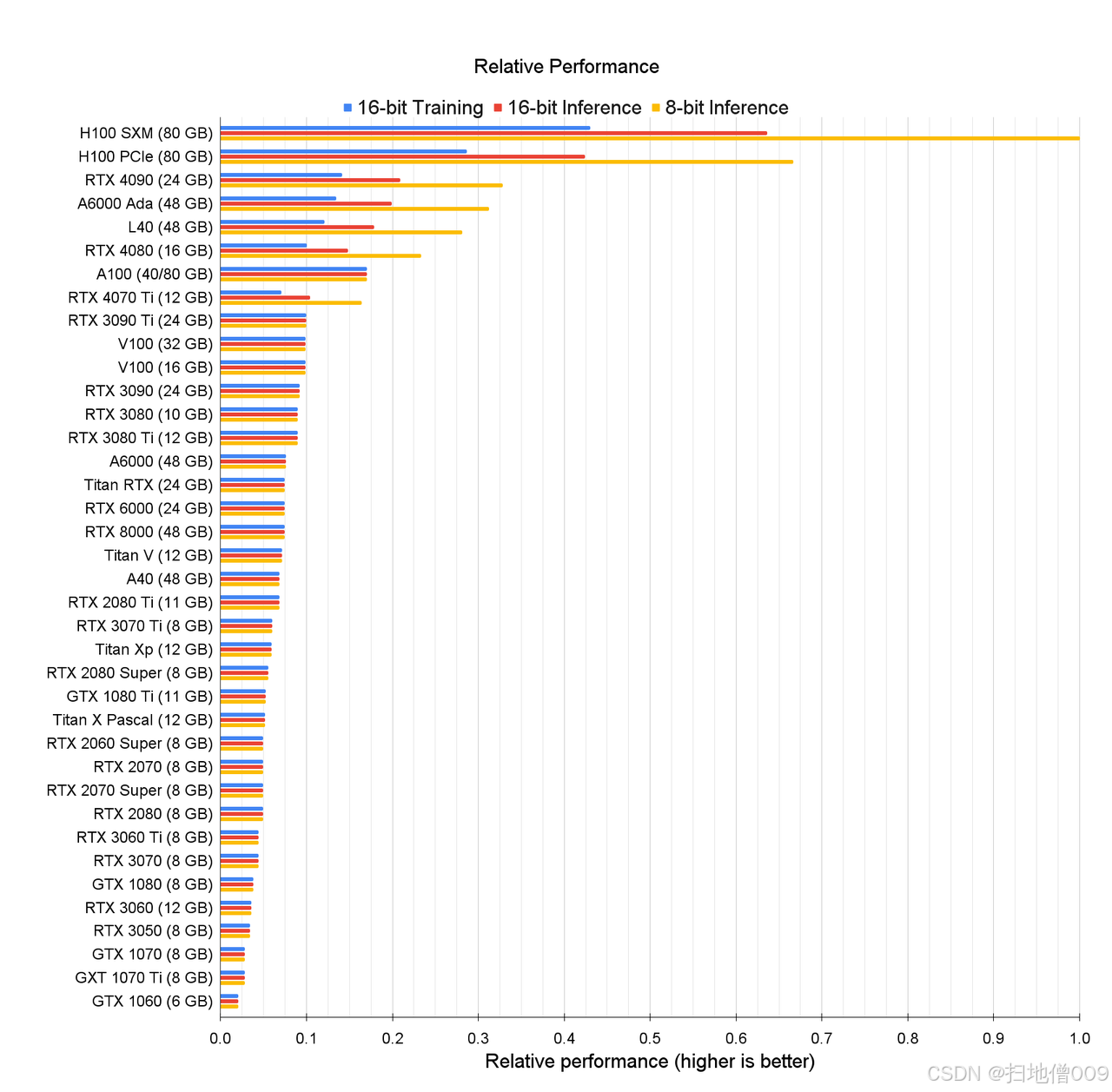
⬅️单卡推理&训练性能
与
每1块钱能买到的最⼤算⼒➡️
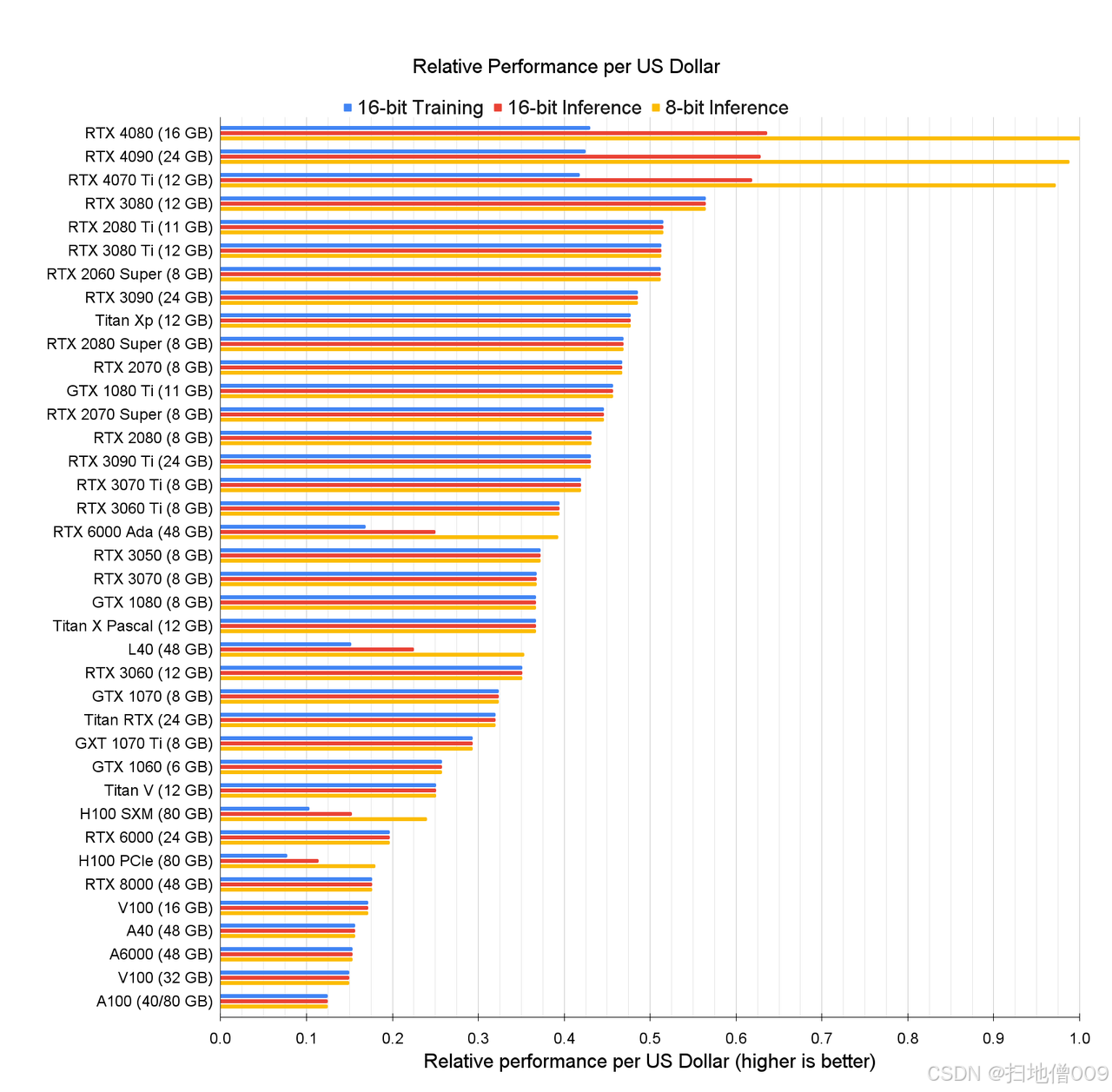
不同显卡性能对⽐-重要结论
-
H系列显卡性能在训练以及各精度训练⽅⾯⼤幅领先;
-
4090推理性能很强(强于A100),但训练能⼒不如A100,且受限于显存
⼤⼩和显存带宽,整体训练能⼒较弱;
-
3090的推理和训练的理论性能越是A100的60%,但同样受限于显存⼤⼩
和显存带宽,实际性能和A100差距较⼤,但仍不失为低成本模型训练;
-
A10、T4等显卡在深度学习推理与训练⽅⾯表现较差;
显卡性价⽐对⽐-重要结论
-
上述对⽐未考虑显卡本身运⾏稳定性与多卡集群带来的性能损耗,只⽤于在绝对环境下单卡性能对⽐;
-
单卡环境下,4080(16G)是性价⽐之王。但在集群环境下,考虑到数据传输损
耗和集群运⾏稳定性,A100/H100仍是⾸选;
-
2080ti 22G魔改版(约2400元)性价⽐超越4080,但使⽤有⼀定⻛险;
-
除了考虑集群架构外,还需要综合考虑旧版GPU在软件上的⼀些不适配问题。综合来看,从性价⽐⻆度考虑,推荐2080ti 22G>4080>3090>4090>2080 11G。
四、不同参数量的⼤模型,训练、微调、推理分别需要多⼤显存
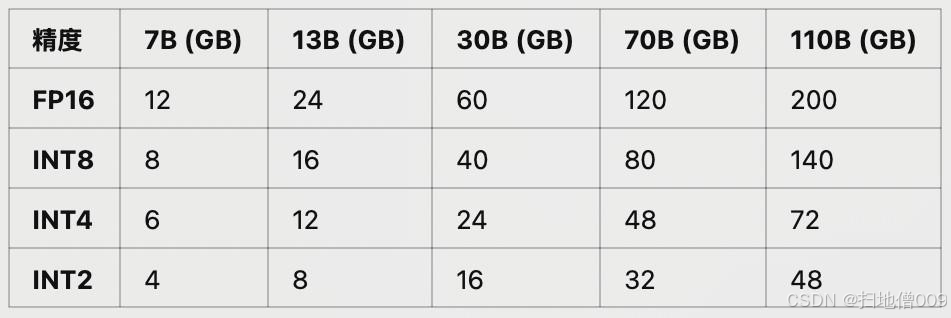
不同尺⼨、不同精度⼤模型推理所需显存占⽤
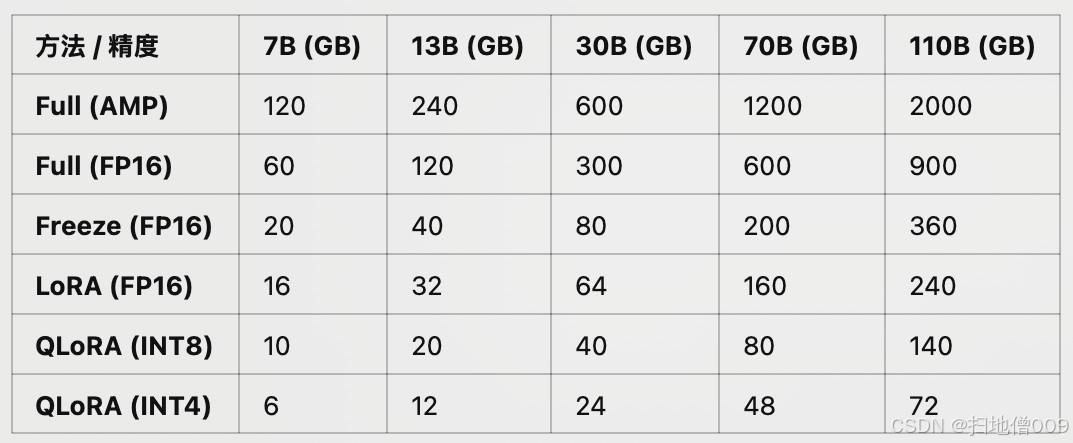
不同尺⼨、不同精度⼤模型训练与微调所需显存占⽤
不同尺⼨、不同精度⼤模型推理推荐GPU
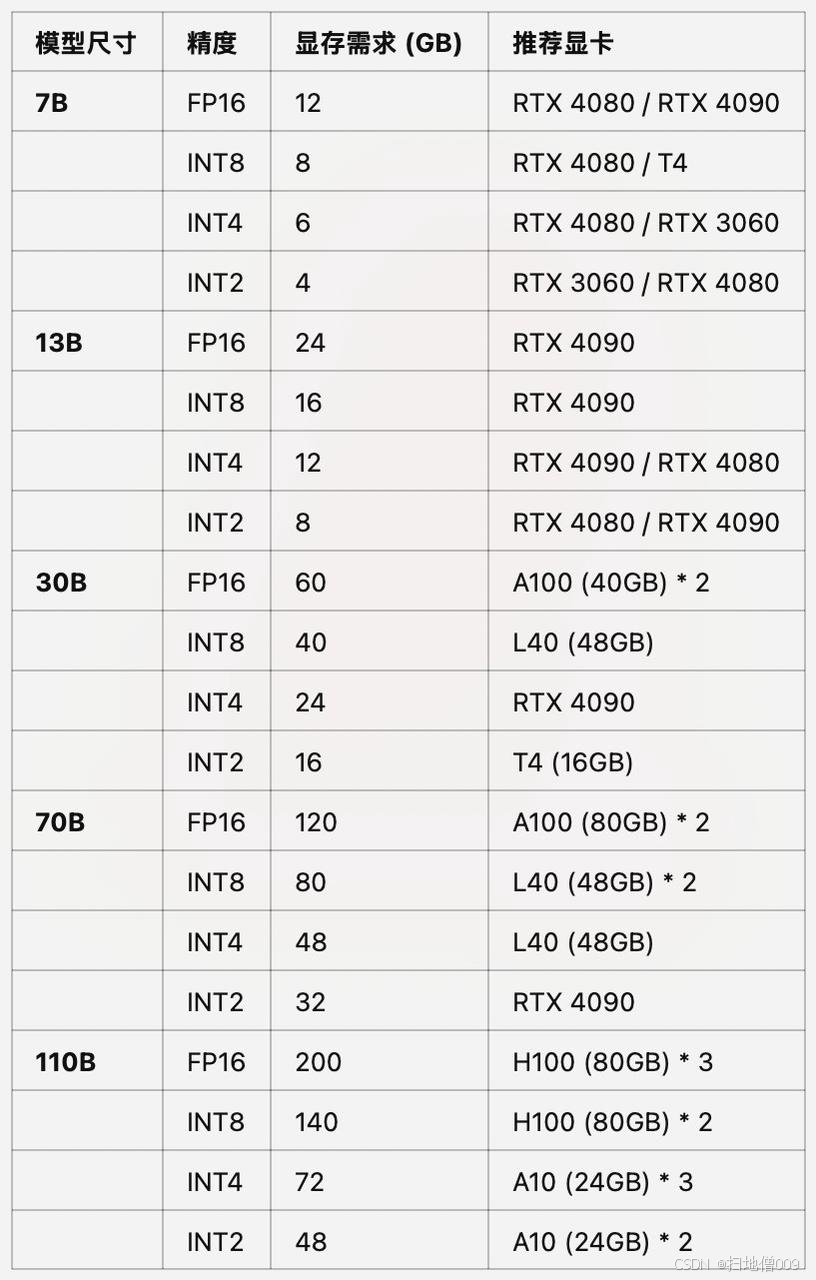
-
其中RTX 4090可等价替换为RTX 3090;
-
其中A100可替换为A800(国内特供);
-
其中L40可替换为L20(国内特供);
不同尺⼨、不同精度⼤模型预训练推荐GPU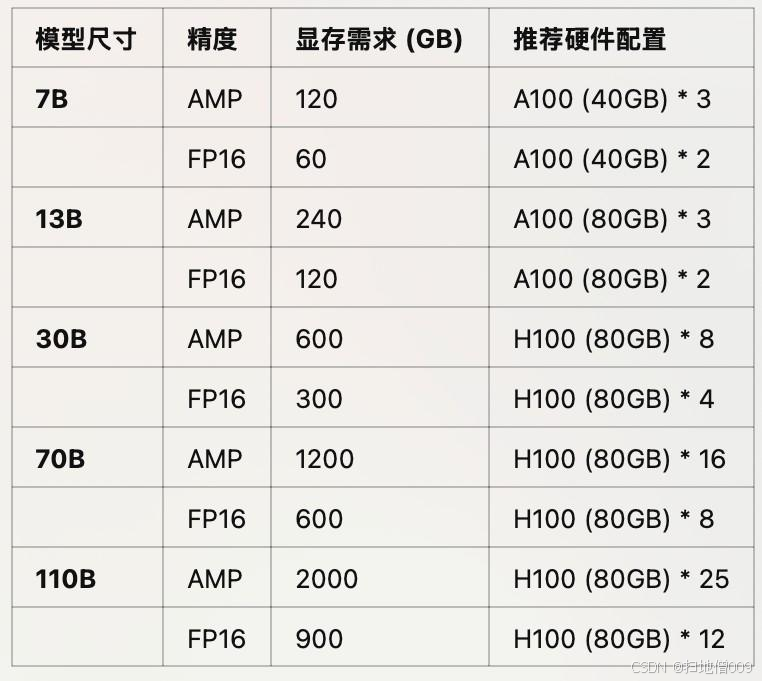
-
其中RTX 4090可等价替换为RTX 3090;
-
其中A100可替换为A800(国内特供);
-
其中L40可替换为L20(国内特供);
不同尺⼨、不同精度⼤模型⾼效微调推荐GPU
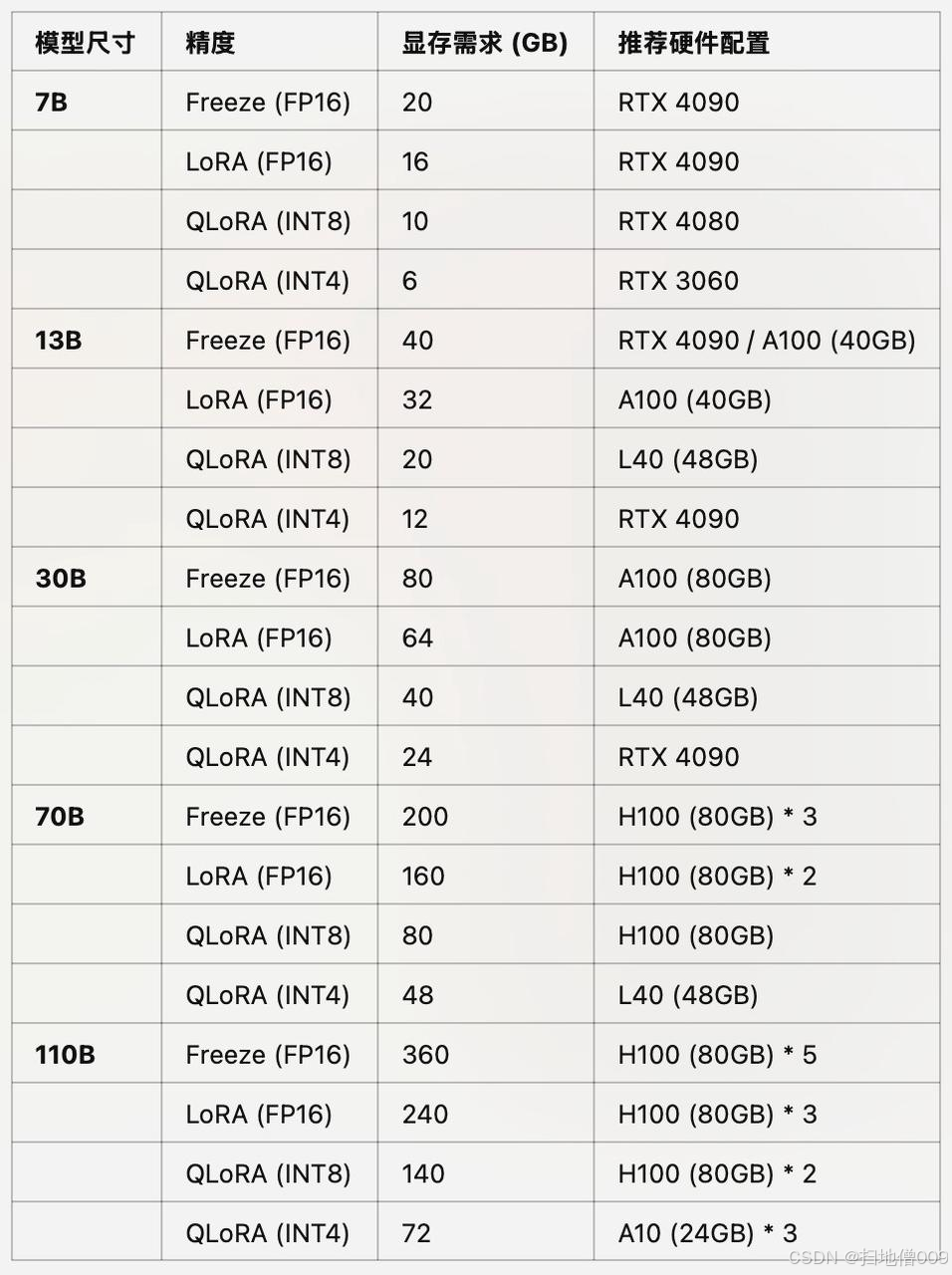
-
其中RTX 4090可等价替换为RTX 3090;
-
其中A100可替换为A800(国内特供);
-
其中L40可替换为L20(国内特供);
五、不同使⽤场景下 推荐GPU配置⽅案
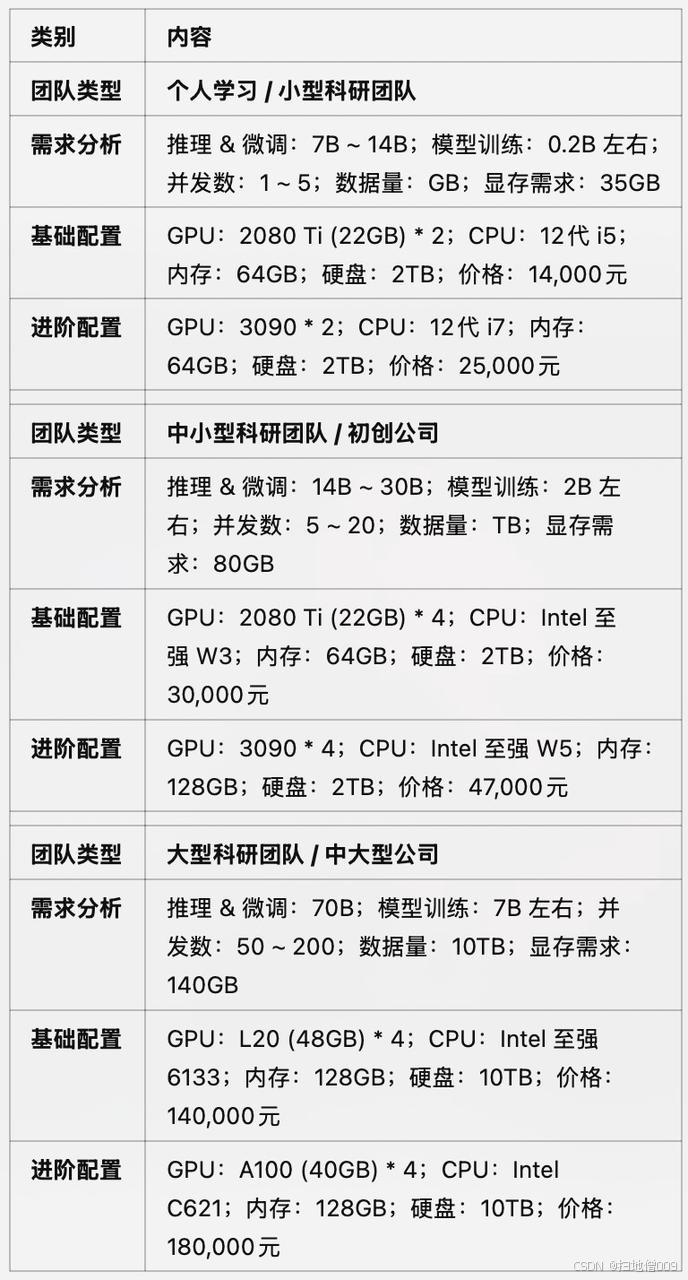
个⼈学习、⼩型科研团队
单台服务器参考配置
需求分析:
-
推理&微调:7B-14B
-
模型训练:0.2B左右
-
并发个数:1-5
-
数据量规模:GB
-
显存需求预估:35G
基础配置:
-
GPU:2080ti 22G * 2
-
CPU:12代i5
-
内存:64G
-
硬盘:2T
-
价格预估:14000
进阶配置:
-
GPU:3090 * 2
-
CPU:12代i7
-
内存:64G
-
硬盘:2T
-
价格预估:14000
中⼩型科研团队、初创公司
单台服务器参考配置
需求分析:
-
推理&微调:14B-30B
-
模型训练:2B左右
-
并发个数:5-20
-
数据量规模:TB
-
显存需求预估:80G
基础配置:
-
GPU:2080ti 22G * 4
-
CPU:Intel ⾄强W3
-
内存:64G
-
硬盘:2T
-
价格预估:30000
进阶配置:
-
GPU:3090 * 4
-
CPU:Intel ⾄强W5
-
内存:128G
-
硬盘:2T
-
价格预估:47000
⼤型科研团队、中⼤型公司
单台服务器参考配置
需求分析:
-
推理&微调:70B
-
模型训练:7B左右
-
并发个数:5-200
-
数据量规模:10TB
-
显存需求预估:140G
基础配置:
-
GPU:L20 * 4
-
CPU:Intel ⾄强6133
-
内存:128G
-
硬盘:10T
-
价格预估:140000
进阶配置:
-
GPU:A100 40G * 4
-
CPU:Intel C621
-
内存:128G
-
硬盘:10T
-
价格预估:180000
不同使⽤场景下推荐GPU配置⽅案汇总

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 16
16 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)