Python正则表达式从入门到精通,看这篇就够了!
Python正则表达式从入门到精通教程

正则表达式是一种强大的文本处理工具,它使用一种特定的模式来描述在搜索文本时要匹配的一个或多个字符串。正则表达式能够用于字符串匹配、查找、替换等操作,是编程和自然语言处理领域中不可或缺的技能。本文,我将带领大家从基础开始,逐步深入,使用简洁易懂的语言全面解析正则表达式的核心概念、语法规则以及实际应用。

无论你是编程初学者,还是有一定经验的开发者,都能通过本文系统地掌握正则表达式,提升文本处理的能力。接下来就让我们一同踏上这段从入门到精通的学习之旅吧!
Regex正则表达式的基本功能
正则表达式(Regular Expression,常简写为regex 或 regexp)是一种用于描述字符串匹配模式的工具。其核心功能:给定一个规则(pattern),然后判断另一个字符串(目标文本)是否符合这个规则或者从目标文本中找出所有符合这个规则的部分。
1.正则提取
比如,下面有一段这样的个人描述中,我们想要从中提取出这个人物出生年月日,死亡年月日对应的具体数字:
'''李白(701年2月28日-762年12月)字太白,号青莲居士,
出生于蜀郡绵州昌隆县(今四川省绵阳市江油市青莲镇),一说山东人,一说出生于西域碎叶,祖籍陇西成纪(今甘肃省秦安县)。唐朝伟大的浪漫主义诗人,凉武昭王李暠九世孙。
'''
那么,学过正则表达式或看完这篇文章的你一定会写出这样一段代码来满足上述需求:
text='''
李白(701年2月28日-762年12月)字太白,号青莲居士,
出生于蜀郡绵州昌隆县(今四川省绵阳市江油市青莲镇),一说山东人,一说出生于西域碎叶
祖籍陇西成纪(今甘肃省秦安县)。唐朝伟大的浪漫主义诗人,凉武昭王李暠九世孙。
'''
import re
search_result=re.search(r'(\d+年)(\d+月)(\d+日?)?[—\-至](\d+年)(\d+月)(\d+日?)?',text)
for group in search_result.groups():
print(group)2.模式匹配
现在,你需要开发一个网页,这个网页在用户注册时需要填写手机号发送验证码,但是需要保证用户的输入是合法手机号,那么学过正则表达式或看完这篇文章的你一定会写出这样一段代码来满足上述需求:
#re.match与re.fullmatch
'''
re.match(r'abc')等价于re.match(r'^abc')
re.fullmatch(r'abc')等价于re.match(r'abc$')
当我们指定一个pattern并调用match时,它会隐式地帮我们加一个^(起始符)
当我们指定一个pattern并调用fullmatch时,它会隐式地帮我们在pattern中加入一对^&起始结束符
'''
#匹配输入是否是电话号:match
import re
match_pattern=re.compile(r'1[3-9]\d{9}')
phone_num_input='1314521659a'
if not phone_num_input.isdigit():
raise ValueError(f'手机号懂不懂?纯数字诶!')
if not match_pattern.fullmatch(phone_num_input):
raise ValueError(f'{phone_num_input}无效的手机号!')
else:
print('验证通过,是手机号,可以发送验证码!')3.规则替换
你是一个期刊官网web后端开发人员,用户要在你的期刊官网下载论文PDF,下载后的PDF名称是论文标题,但是论文标题中难免会包含本地操作系统路径所不支持的字符,比如在windows系统上新建的文件不能包含:*_ | <>类似字符,否则文件无效,下载的文件也破损无效,你需要做的是尽可能将这些字符全部替换为合法字符,比如空格或-破折号。
那么学过正则表达式或看完这篇文章的你一定会写出这样一段代码来满足上述需求:
#文件名中非法字符替换
import re
illegal_chars=r'[-/*::_""<>|]'
filename='''Principal_component analysis for *three-dimensional: structured illumination microscopy-(PCA-3DSIM)'''
filename,sub_num=re.subn(illegal_chars,' ',filename)
print(filename,sub_num)4.规则切分
你是一个古诗词爱好者,你手上的古诗词文本中有着类似的注释:
'''
《将进酒》君不见黄河之水天上来#注释:开篇气势磅礴
奔流到海不复回#注释:比喻时光流逝
君不见高堂明镜悲白发#注释:人生易老
朝如青丝暮成雪#注释:时光飞逝
人生得意须尽欢#注释:及时行乐
莫使金樽空对月#注释:不要辜负美景
'''
你想要得到每一句去掉注释后的古诗,那么学过正则表达式或看完这篇文章的你一定会写出这样一段代码来满足上述需求:
import re
text = '''
《将进酒》君不见黄河之水天上来#注释:开篇气势磅礴
奔流到海不复回#注释:比喻时光流逝
君不见高堂明镜悲白发#注释:人生易老
朝如青丝暮成雪#注释:时光飞逝
人生得意须尽欢#注释:及时行乐
莫使金樽空对月#注释:不要辜负美景
'''
result=re.split(r'#注释:[^\n]*\n?|\n+', text, flags=re.MULTILINE)
cleaned_result=[line for line in result if line.strip()!='']
print(cleaned_result)类似的场景还有很多,这里就不一 一列举了,上述四个场景基本上已经涵盖了正则表达式所有的应用范围。
那么接下来,就让我们在知识的海洋里遨游,从0到1的来学会正则表达式这一强大的字符匹配工具吧!

Python re模块使用教程
目前,几乎所有的编程语言都支持正则表达式这一字符匹配工具,但是每种编程语言下这一工具的使用方法还大不相同,本文我们以Python为主,来给大家讲解一下Python中正则表达式的具体使用教程。
首先,我们来运行一下下边这行代码看看re这个module内所有内容:
#python re 模块内置所有方法
import re
print(re.__all__)不出意外的话,应该都是这个结果:
['match', 'fullmatch', 'search', 'sub', 'subn', 'split', 'findall', 'finditer', 'compile', 'purge', 'template', 'escape', 'error', 'Pattern', 'Match', 'A', 'I', 'L', 'M', 'S', 'X', 'U', 'ASCII', 'IGNORECASE', 'LOCALE', 'MULTILINE', 'DOTALL', 'VERBOSE', 'UNICODE', 'NOFLAG', 'RegexFlag']
如果出意外的话,检查一下你的python版本吧,是不是还在用3.6以下的老古董🤨?
意外可能会出在缺少Pattern,Match,A,I,L,M,S,X,U这几个字符,不过,没关系,问题不大,这对本文的教程没有任何影响,本文还请大家放心食用😋
re的不同使用姿势
我们在使用Python的re模块进行正则匹配等任务时有主要有两种使用方法:
直接调用re内的一些方法:
这一方法符合大多数python练习生的库函数使用习惯:
即:
import xxx as xx
xx.yyy
当然,python正则表达式库的名称re已经够短小精悍了,没有必要再as一个别名
当我们以这种方式调用库函数时,所有这些库函数的首个位置参数都是pattern
比如:
import re
re.search(pattern=r' ',string=' ',flags=' ')
import re
string='姓名:李刚,出生年月:1989-05-01,手机号:18888888888'
name=re.search(pattern=r'(?<=姓名:)\w+',string=string)
phone_num=re.search(pattern=r'1[3-9]\d{9}',string=string)
birthday=re.search(pattern=r'\d{4}[-/_]?\d{1,2}[-/_]?\d{1,2}',string=string)
print(name)
print(phone_num)
print(birthday)预编译:😜
即先指定一个pattern并使用re.compile编译后赋值给一个对象
然后使用这个对象进行search,match等一系列操作,此时这些方法
的第一个位置参数是string待匹配字符串,不再是pattern。
这种使用方式就是我们耳熟能详地,面向对象的形式调用:a=xxx(class),a.method...
比如:
import re
pattern=re.compilie(r'')
pattern.search(string='',flags='')
import re
string='姓名:李刚,出生年月:1989-05-01,手机号:18888888888'
name_pattern=re.compile(r'(?<=姓名:)\w+')#正向后行断言,(?<=姓名:)\w+匹配 姓名:xxx(字母数字下划线) 这一字符串但不包含姓名:
birthday_pattern=re.compile(r'\d{2,4}[-/_]?\d{1,2}[-/_]?\d{1,2}')
phone_num_pattern=re.compile(r'1[3-9]\d{9}')
print(name_pattern.search(string))
print(phone_num_pattern.search(string))
print(birthday_pattern.search(string))返回值说明
无论是使用预编译或直接调用,re内绝大部分函数其返回值都是
(Match[str]|None),即Match对象或None。

Match对象的一般格式为:
<re.Match object; span=(xx, xx), match='匹配结果'>
- 其中match=''为查找结果,获取匹配结果通过索引[0]来获取
- 通过.span()方法可以获取span(元祖),其给出了匹配结果的首个字符与最后一个字符的起始与结束位置
- 通过.start()方法可以获取span中的起始位置,即span元祖的第一个值(int类型)
- 通过.end()方法可以获取span中的结束位置,即span元祖的第二个值(int类型)
- 通过.endpos属性可以获取span中的结束位置,即span元祖的第二个值(int类型)
也就是:
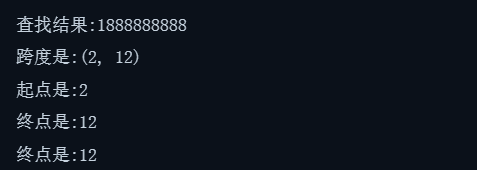
import re
text='''李刚1888888888'''
search_result=re.search(r'\d+',text)
if search_result:
print(f'查找结果:{search_result[0]}')
print(f'跨度是:{search_result.span()}')
print(f'起点是:{search_result.start()}')
print(f'终点是:{search_result.end()}')
print(f'字符串终点是:{search_result.endpos}')
else:
print('未查找到任何数字!')运行结果:
分组返回值
分组是正则表达式语法中一个绝秒的设计,使用分组可以对匹配到的内容进行引用并进一步提取详细信息。特别是在提取日期,URL,IP地址,邮箱等关键信息时,使用分组的形式可以让我们分别输出匹配结果中的每一部分。比如匹配日期时,分别输出年,月,日,时,分,秒等信息,匹配URL时分别输出域名与查询参数等...
分组这一语法的一般形式是使用圆括号将某些部分包含[断言除外],此时每个圆括号内的部分便是一个分组。当然,整个匹配结果本身也属于一个分组。
pattern=r'(\d{4})[-/_\s]*?(\d{1,2})[-/_\s]*?(\d{1,2})
#三个圆括号分别对年月日进行分组
例如:
#返回值之分组获取group
r'''
当我们的pattern中使用了小括号将某些部分包含时[断言除外],每个小括号内的部分便是一个分组
这里以匹配出生年月日这个pattern为例:
'(\d{4})[-/_\s]*?(\d{1,2})[-/_\s]*?(\d{1,2})'共计三个括号,且每个括号内不包含断言
#因此最后的分组总数便是1+3=4,
分组的总数等于()个数+1,这是因为第一个分组内容肯定是完整的匹配结果,要想单独获取每个分组,索引需要从1开始
当然,只要匹配结果存在,那么直接通过索引[0]和.group(0)获取到的完整匹配结果是一致的
也就是说即使你没有在pattern中显示地使用分组,仍然会至少分一个组出来,这个组便是你的完整匹配结果
特别地,如果需要获取不包含完整匹配结果的分组内容,可以通过groups方法来实现
'''
import re
string='姓名:李刚,出生年月:1989/05-01,手机号:18888888888'
#出生年月日之间的连接符可能的情况:
#- _ / 空格或空白,所以每个数字间使用[-/_\s]表示可能的字符集,同时这些符号可能出现也可能不出现
#所以匹配次数为*:0次或多次
birthday=re.search(pattern=r'(\d{4})[-/_\s]*?(\d{1,2})[-/_\s]*?(\d{1,2})',string=string)
print(f'完整出生日期:{birthday[0]}')
print(f'完整出生日期:{birthday.group(0)}')
print(f'出生年份:{birthday.group(1)}')
print(f'出生月份:{birthday.group(2)}')
print(f'出生日:{birthday.group(3)}')
print(f'所有不包括完整匹配结果的分组:{birthday.groups()}')正则匹配出生年月日
当我们通过group+索引的方式来获取分组内容时,要注意分组总数等于()个数+1,因为第一个分组内容是完整的匹配结果,后边才是每个分组的结果,若想要单独获取每个分组,索引需要从1开始。
当我们通过groups方法来获取分组内容时,分组总数等于()个数,因为该方法返回的列表中不包含完整匹配结果,若想要单独获取每个分组,索引需要从0开始。
运行结果:

当然还有一些特殊方法,比如findall,finditer,sub,subn,split,他们的返回值,在我们稍后详细讲解每一个方法时会提到。
内部函数详解
所谓,工欲善其事,必先利其器,在这里我们主要来了解一下Python re模块的内置方法与函数,并熟悉它们的使用方法。

re.match与re.fullmatch
| 参数 | 类型 | 说明 |
|---|---|---|
| pattern | str | 正则表达式的具体内容 |
| string | str | 待匹配字符串 |
| flags | int | 一些用来增强匹配效果的附加功能修饰符 |
顾名思义,re.match与re.fullmatch主要用来按照指定的pattern进行模式匹配,此时我们主要关心这个结果是否匹配即函数的返回值存在与否而不是内容本身,正如文章开篇所给出的例子:
需要保证用户的输入是合法手机号,那我们就可以使用re.match或re.fullmatch来实现这一功能,当然首先要保证输入是数字,这里使用Python字符串内置方法isdigit实现,具体代码如下:
#re.match与re.fullmatch
'''
re.match(r'abc')等价于re.match(r'^abc')
re.fullmatch(r'abc')等价于re.match(r'abc$')
当我们指定一个pattern并调用match时,它会隐式地帮我们加一个^(起始符)
当我们指定一个pattern并调用fullmatch时,它会隐式地帮我们在pattern中加入一对^&起始结束符
'''
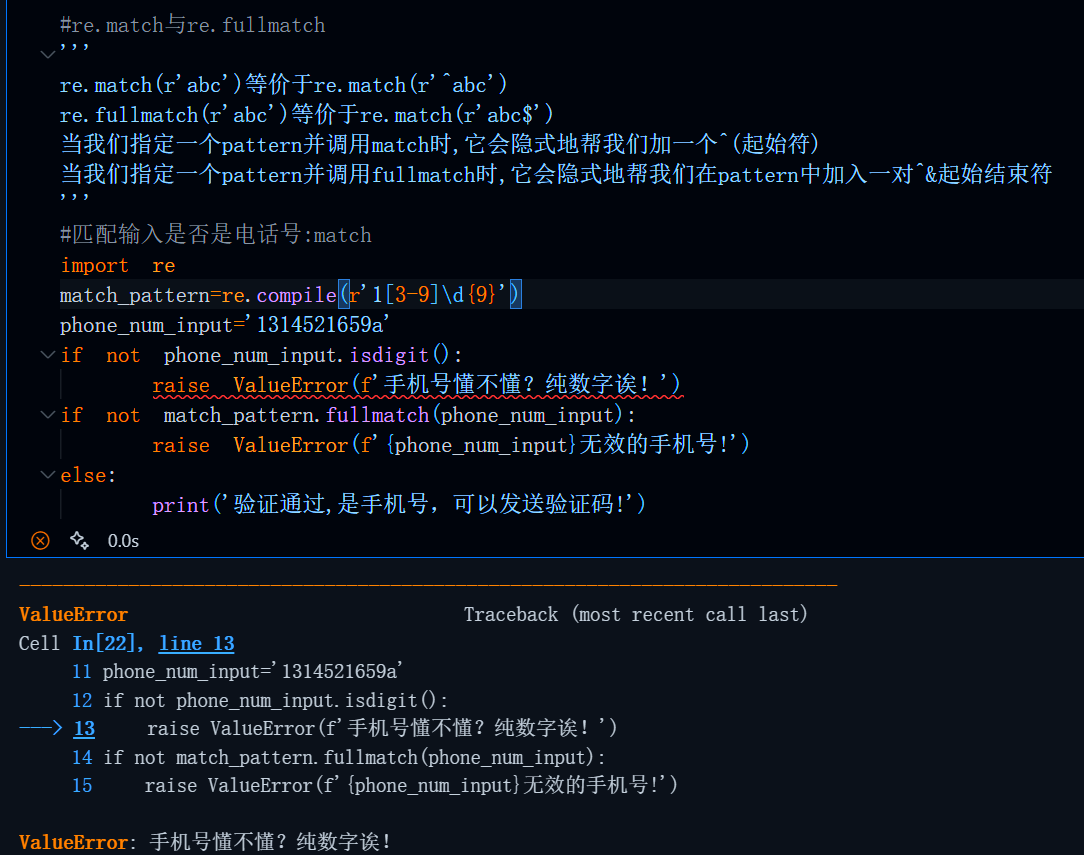
#匹配输入是否是电话号:match
import re
match_pattern=re.compile(r'1[3-9]\d{9}')
phone_num_input='1314521659a'
if not phone_num_input.isdigit():
raise ValueError(f'手机号懂不懂?纯数字诶!')
if not match_pattern.fullmatch(phone_num_input):
raise ValueError(f'{phone_num_input}无效的手机号!')
else:
print('验证通过,是手机号,可以发送验证码!')运行结果:
这里需要说明的是:
当我们指定一个pattern并调用re.match时,它会隐式地帮我们在pattern中加一个^(起始符),也就是
re.match(r'abc')等价于re.match(r'^abc')
那么,当我们使用match时它会从字符串的开头去匹配pattern,如果字符串在开头就没有与pattern相对应的格式的话,那么返回结果就是None
当我们指定一个pattern并调用re.fullmatch时,它会隐式地帮我们在pattern中加入一对^&(起始结束符),也就是
re.fullmatch(r'abc')等价于re.fullmatch(r'^abc$')
那么,当我们使用re.fullmatch时他会按照pattern去完整地匹配这个字符串,如果这个字符串整体的格式与pattern不一致的话,那么返回结果就是None。
二者的区别其实就在于是否有&,一对^&限定了pattern必须作用于完整的字符串(从头到尾),而只有^的话,只需要在字符串开头的地方有与pattern相对应的格式即可。总之,这两个函数最长用到的常见便是模版匹配,如果你在开发中遇到了类似需求,不妨尝试一下re.match与re.fullmatch函数,可能会比你使用if for循环遍历来匹配方便地多。
返回值
re.match与re.fullmatch的返回值与我们前边返回值说明中谈到的内容一致,这里不再赘述。
re.search
| 参数 | 类型 | 说明 |
|---|---|---|
| pattern | str | 正则表达式的具体内容 |
| string | str | 待匹配字符串 |
| flags | int | 一些用来增强匹配效果的附加功能修饰符 |
re.search可能是我们在使用re这个工具过程中使用频率最高的方法与函数,它的主要功能,顾名思义就是按照指定的pattern去字符串中查找满足条件的内容。
示例代码:
#re.search:查找匹配对象(只返回所有可能结果的第一个)
'''
re.search方法参数:
pattern:正则表达式
string:待匹配字符串
flags:修饰符,可以改变匹配的范围
re.search方法返回对象:
匹配成功时:返回re.Match对象,其包含了匹配的完整信息
形如:<re.Match object; span=(xx, xx), match='查找结果'>
其中match=''为查找结果,需要获取匹配结果需要使用[0]来获取
通过.span()方法可以获取span(元祖),其给出了匹配结果的首个字符与最后一个字符的起始与结束位置
通过.start()方法可以获取span中的起始位置,即span元祖的第一个值(int类型)
通过.end()方法可以获取span中的结束位置,即span元祖的第二个值(int类型)
通过.endpos属性可以获取整个字符串的结尾的索引
通过索引[0]来获取
匹配失败时:直接返回None
'''
import re
string='姓名:欧阳修,姓名:王安石,出生年月:1989/05-01,手机号:18888888888'
#正向后瞻搜索姓名
search_result=re.search(r'(?<=姓名:)\w{2,4}',string)
if search_result:
print(f'查找结果:{search_result[0]}')
print(f'跨度是:{search_result.span()}')
print(f'起点是:{search_result.start()}')
print(f'终点是:{search_result.end()}')
print(f'字符串终点是:{search_result.endpos}')
else:
print('未查找到名字!')
运行结果:
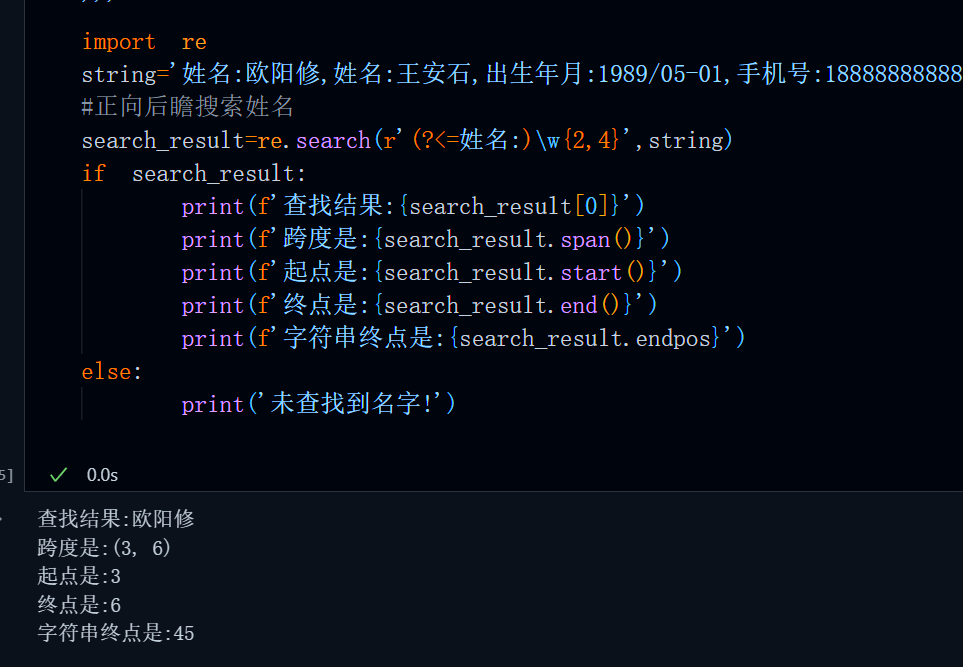
需要注意的是,当字符串中有多个满足条件的子串时,re.search只能匹配并返回第一个结果,并不能查找到所有满足条件的可能。比如,这里,符合条件的结果显然还包括王安石,但是他却只会返回第一个符合pattern格式的字符串也就是欧阳修。
返回值
re.search的返回值与我们前边返回值说明中谈到的内容一致,这里不再赘述。
re.findall
| 参数 | 类型 | 说明 |
|---|---|---|
| pattern | str | 正则表达式的具体内容 |
| string | str | 待匹配字符串 |
| flags | int | 一些用来增强匹配效果的附加功能修饰符 |
re.findall弥补了re.search无法查找所有满足条件的子串的这一遗憾,他的作用就是查找字符串中所有满足pattern的子串,并以列表的形式返回。
这里我们以web爬虫过程中最常见的一个情形为例:查找html中所有的direct链接
示例代码:
#re.findall
'''
re.findall方法参数:
pattern:正则表达式
string:待匹配字符串
flags:修饰符,可以改变匹配的范围
re.findall方法返回对象:
匹配成功时:返回[str],其包含了所有满足匹配条件的结果
匹配失败时:直接返回空列表[]
'''
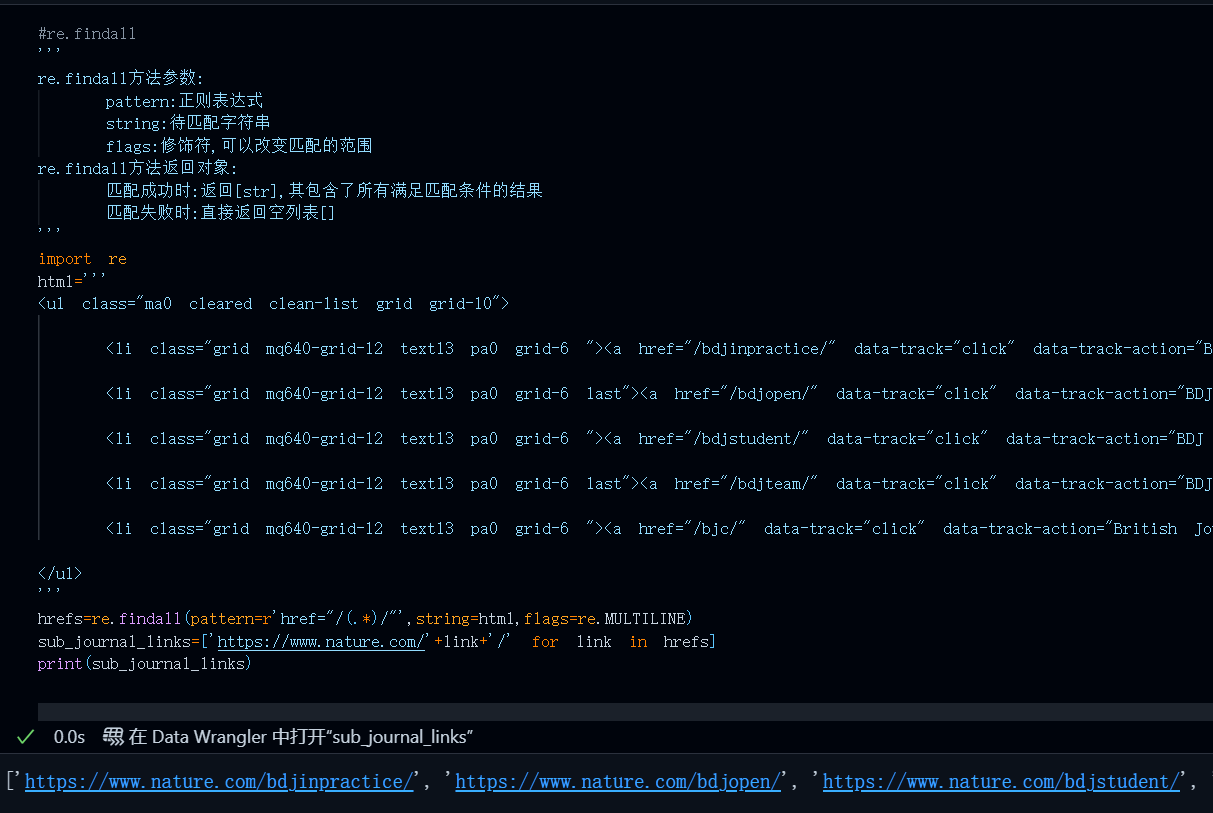
import re
html='''
<ul class="ma0 cleared clean-list grid grid-10">
<li class="grid mq640-grid-12 text13 pa0 grid-6 "><a href="/bdjinpractice/" data-track="click" data-track-action="BDJ In Practice" data-track-label="link" class="block pt10 pb10 equalize-line-height">BDJ In Practice</a></li>
<li class="grid mq640-grid-12 text13 pa0 grid-6 last"><a href="/bdjopen/" data-track="click" data-track-action="BDJ Open" data-track-label="link" class="block pt10 pb10 equalize-line-height">BDJ Open</a></li>
<li class="grid mq640-grid-12 text13 pa0 grid-6 "><a href="/bdjstudent/" data-track="click" data-track-action="BDJ Student" data-track-label="link" class="block pt10 pb10 equalize-line-height">BDJ Student</a></li>
<li class="grid mq640-grid-12 text13 pa0 grid-6 last"><a href="/bdjteam/" data-track="click" data-track-action="BDJ Team" data-track-label="link" class="block pt10 pb10 equalize-line-height">BDJ Team</a></li>
<li class="grid mq640-grid-12 text13 pa0 grid-6 "><a href="/bjc/" data-track="click" data-track-action="British Journal of Cancer" data-track-label="link" class="block pt10 pb10 equalize-line-height">British Journal of Cancer</a></li>
</ul>
'''
hrefs=re.findall(pattern=r'href="/(.*)/"',string=html)
sub_journal_links=['https://www.nature.com/'+link+'/' for link in hrefs]
print(sub_journal_links)
运行结果:
返回值说明:
re.findall函数的返回值是list[str],没有匹配到元素时返回[]空列表,如果匹配到元素的话,那么返回的便是所有符合pattern的子串构成的列表,同样的pattern(获取href属性的值中带/的内容),字符串为同一个html文本,如果使用re.search函数那么它只会返回第一个匹配到的内容,也就是
"/bdjinpractice/",无法获取所有的href值,
综上,在web爬虫任务中,re.findall是使用频率最高的一个函数,他可以用来提取网页中所有符合特定模式的子串,如所有的链接地址、所有的图片,文件,定向URL等。
re.sub与re.subn
| 参数 | 类型 | 说明 |
|---|---|---|
| pattern | str | 正则表达式的具体内容 |
| repl | str | 替换内容 |
| string | str | 待替换的原始字符串 |
| count | int | 替换数量,若传入了不为零的数则会按照匹配到的先后顺序替换count个字符 |
| flags | int | 一些用来增强匹配效果的附加功能修饰符 |
re.sub与re.subn用来正则替换字符串中指定pattern的内容,具体使用场景可以参考文章开篇所谈到的文件名非法字符替换。这二者区别不大,唯一的区别在于其返回值上。
示例代码:
#re.sub与re.subn
'''
re.sub与re.subn方法参数:
pattern:正则表达式
repl:匹配到的字符待替换对象
count:替换个数,默认为零,此时会把所有匹配到的字符全部替换
如果传入了不为零的数则会按照匹配到的先后顺序替换count个字符
flags:修饰符,可以改变匹配的范围
re.sub返回值:
str,被替换的字符串
re.subn返回值:
(str,int),替换后的字符串与替换数量
'''
#re.sub与re.subn唯一区别在于返回值上,其余参数和收用方法一致
import re
illegal_chars=r'[-/*::_""<>|]'
filename='''Principal_component analysis for *three-dimensional: structured illumination microscopy-(PCA-3DSIM)'''
filename,sub_num=re.subn(illegal_chars,' ',filename)
print(filename,sub_num)运行效果:

原字符串中共计有六个非法字符,全部被替换为" "空格
返回值说明:
对于re.sub来说其返回值类型为str,即替换后的字符串,特别地,如果在原始字符串中使用pattern没有匹配到任何内容,那么将不做任何替换其返回的str还是原始字符串。
对于re.subn来说其返回值在替换后的字符串基础上多了一个int类型的替换数量,二者结合起来便得到了re.subn函数的返回值类型tuple[str,int]
re.split
re.split函数用来正则分割字符串,具体使用场景可以参考文章开篇所谈到的规则切分。
| 参数 | 类型 | 说明 |
| pattern | str | 正则表达式 |
| string | str | 待切分字符串 |
| maxsplit | int | 最大切分数量,默认为零,此时会按照匹配到的字符全部切分,如果传入了不为零的数则会按照匹配结果先后顺序分割maxsplit次 |
| flags | int | 一些用来增强匹配效果的附加功能修饰符 |
示例代码:
#re.split
'''
re.split方法参数:
pattern:正则表达式
string:待匹配字符串
maxsplit:最大分割数量,默认为零,此时会按照匹配到的字符全部
如果传入了不为零的数则会按照匹配结果先后顺序分割maxsplit次
flags:修饰符,可以改变匹配的范围
re.split方法返回对象:
匹配成功时:[str],包含了所有满足匹配条件的分割结果
匹配失败时:[原字符串]
'''
import re
text = '''
《将进酒》君不见黄河之水天上来#注释:开篇气势磅礴
奔流到海不复回#注释:比喻时光流逝
君不见高堂明镜悲白发#注释:人生易老
朝如青丝暮成雪#注释:时光飞逝
人生得意须尽欢#注释:及时行乐
莫使金樽空对月#注释:不要辜负美景
'''
result=re.split(r'#注释:[^\n]*\n?|\n+', text, flags=re.MULTILINE)
cleaned_result=[line for line in result if line.strip()!='']
print(cleaned_result)运行结果:
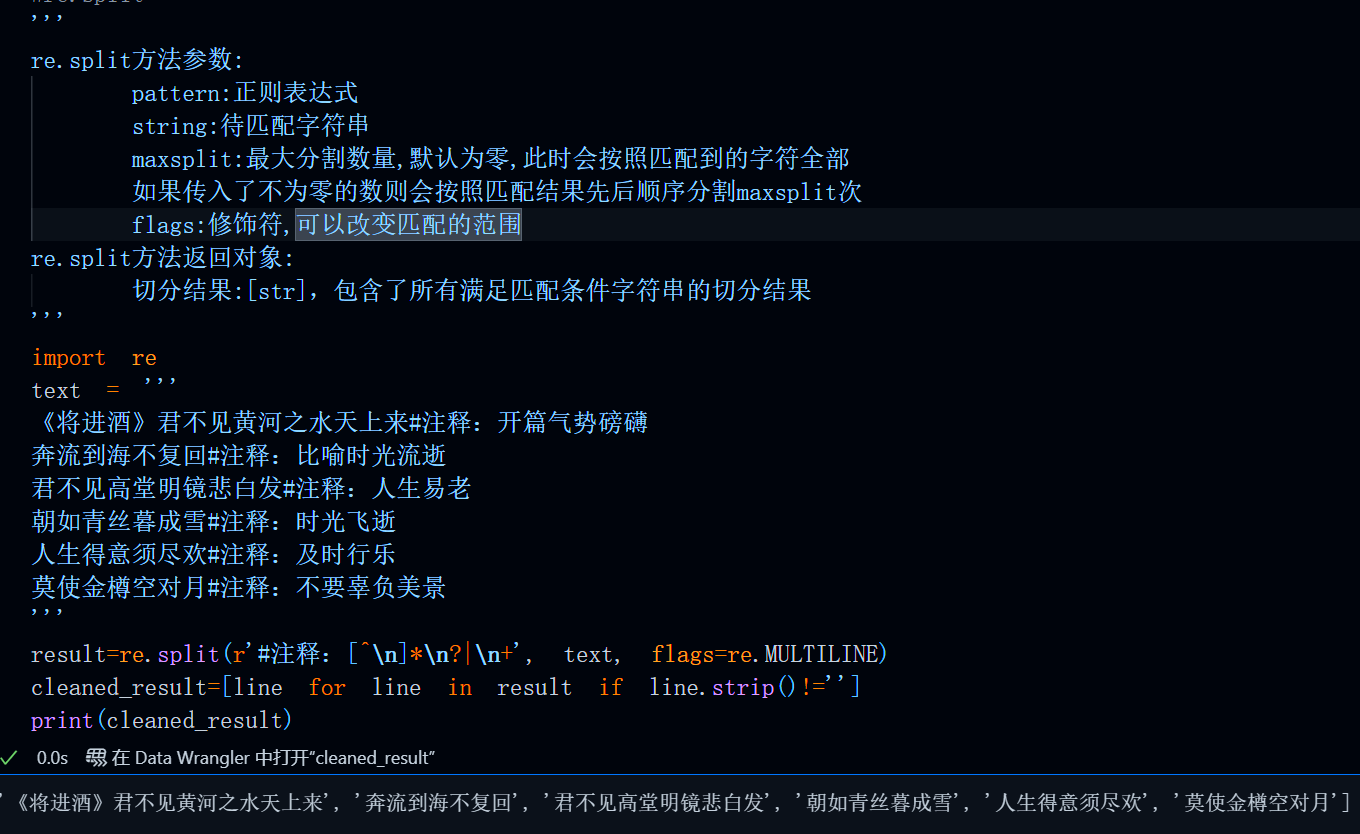
返回值说明:
对于re.split函数来说,其返回值为list[str]类型的列表,特别地,如果在原始字符串中使用pattern没有匹配到任何内容,那么将会以字符为单位进行分割。这与python字符串内置的切分方法split一致,但是re.split相较于split可以按照指定的规则进行切分,而split方法却只能按照给定的字符进行切割。
re.finditer
re.finditer与re.findall函数无论是在入参还是在用法上,二者都一模一样,唯一的区别在与re.finditer返回的内容时一个iterator,而re.findall函数返回的是一个list[str]。
| 参数 | 类型 | 说明 |
|---|---|---|
| pattern | str | 正则表达式的具体内容 |
| string | str | 待匹配字符串 |
| flags | int | 一些用来增强匹配效果的附加功能修饰符 |
示例代码:
#re.finditer
'''
re.finditer与re.findall与使用方法一致,二者唯一区别在于返回结果
re.finditer方法参数:
pattern:正则表达式
string:待匹配字符串
flags:修饰符,可以改变匹配的范围
re.finditer方法返回对象:
匹配成功时:返回一个iterator
匹配失败时:空的iterator
'''
import re
string='李白13288888888,欧阳修15519191919,王安石16666666666'
matches=re.finditer(pattern=r'1[3-9]\d{9}',string=string)
if matches:
for match in matches:
print(f'电话号:{match[0]}')运行结果:
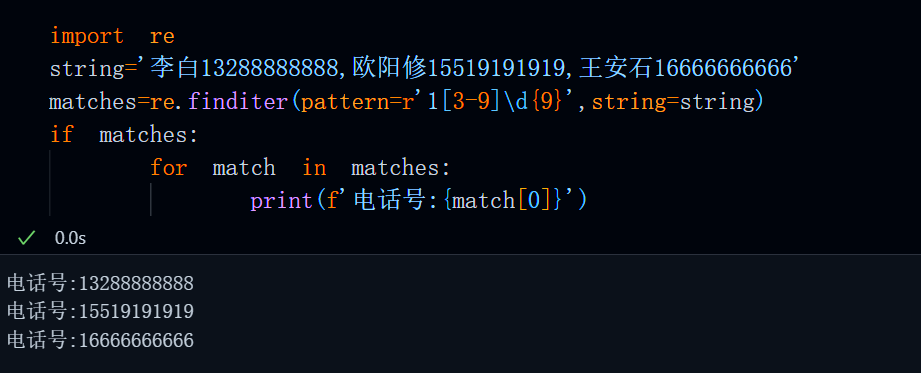
返回值说明:
re.finditer函数返回的内容是一个iterator,所谓的iterator就是指一个类似list或set(当然形式上不会体现)iterable对象,只能通过for循环,无法通过索引来获取其内部内容的数据结构。
通常在一些高性能场景下,我们会考虑使用re.finditer而不是re.findall,因为itertor相比于列表更加节省内存。
re.escape
re.escape不是一个用来查找匹配的函数,而是一个用于转义预定义字符的方法,比如:我们要匹配c++这个单词,但由于+为预定义字符表示匹配一次或多次,如果不对其使用\转义(所有的预定义字符都通过\来转义)+这一预定义字符的话(即c\+\+),那么c++表示匹配字母c一次或多次。
但是如果一个需要在pattern中保留的单词中有多个预定义字符的话,这样手动写很麻烦
re.escape可以自动帮我们将这个词内部包含的所有预定义字符自动转义。
示例代码:
#re.escape
r'''
re.escape不是一个用来查找匹配的方法,而是一个用于转义特殊字符的方法
比如:我们要匹配c++,由于+为预定义字符表示匹配一次或多次
如果不对其使用\转义的话(即c\+\+),c++表示匹配字母c次或多次
但是如果一个需要在pattern中保留的单词中有多个预定义字符的话这样手动写很麻烦
re.escape可以自动帮我们将所有可能的预定义字符转义
'''
import re
text='I love c++,python,java,javascript'
no_escape_pattern=r'c++'#+为预定义字符表示匹配一次或多次,不对+转义的话,c++表示匹配字母c次或多次
escape_pattern=re.escape(r'c++')#+等价于c\+\+
print(re.search(no_escape_pattern,text)[0])
print(re.search(escape_pattern,text)[0])运行结果:
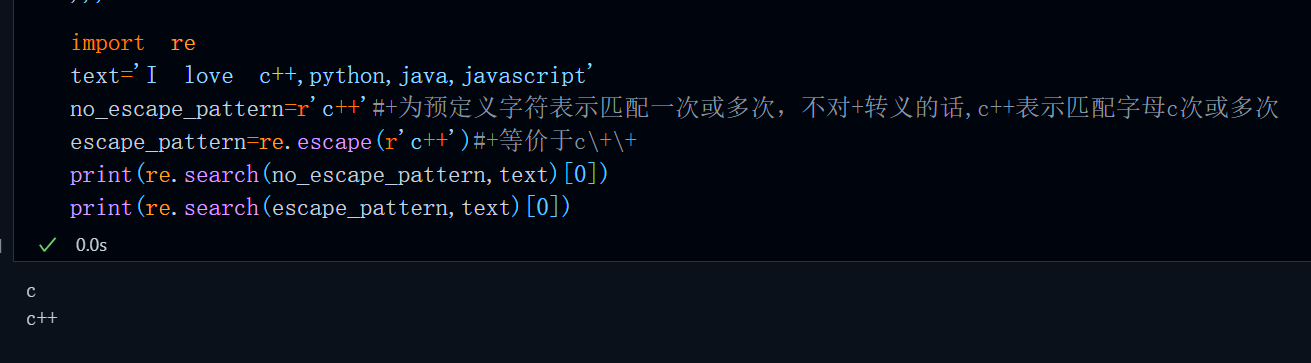
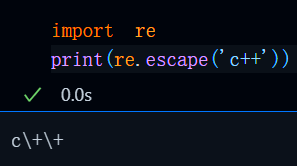
返回值说明:
该函数的返回值为字符串自动转义后的字符,比如re.escape('c++'),那么其返回值便是c\+\+
re.purge
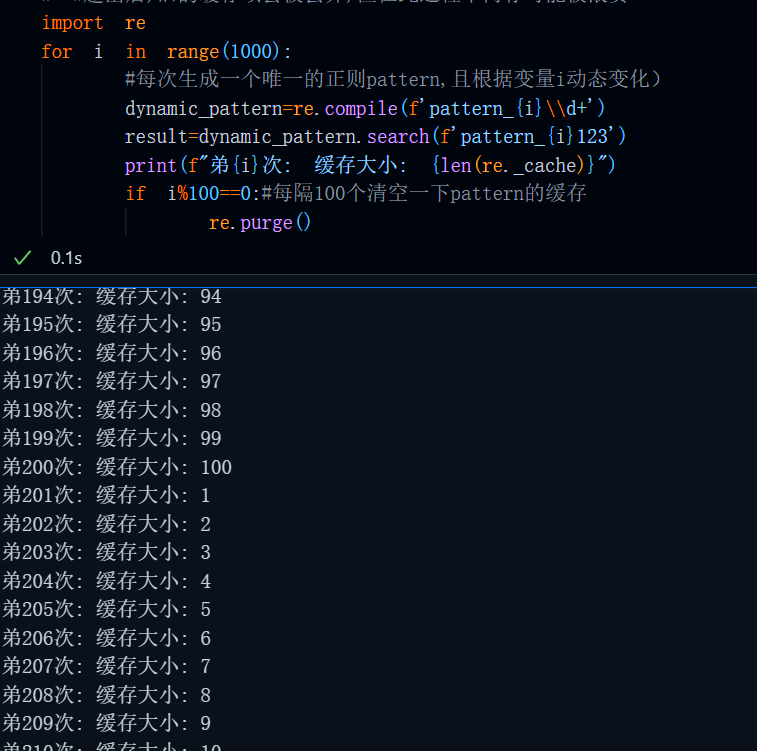
在一般的生产环境中我们还用不到re.purge,这个函数用来清空已编译的正则表达式对象re.Pattern,以避免重复编译相同的正则模式,释放内存。这种情况主要出现在:
import re
for i in range(1000):
#每次生成一个唯一的正则pattern,且根据变量i动态变化)
dynamic_pattern=re.compile(f'pattern_{i}\\d+')
result=dynamic_pattern.search(f'pattern_{i}123')
print(f"弟{i}次: 缓存大小: {len(re._cache)}")
#缓存会持续增长,直到达到_MAXCACHE(默认512,单位:个)
#超出后,旧的缓存项会被丢弃,但在此过程中内存可能被浪费动态生成大量pattern的情形下,特别地,我们还可以使用re._cache来统计pattern的缓存个数,其上限为re._MAXCACHE=512,单位为个。
那么到这儿,可能会有小伙伴问,那我的pattern超过512该怎么办?是不是会无法匹配,只能每次使用第512个旧pattern?
这样的担心是多余的,因为python的regex对此使用的方法是LRU(Latest Recent Used)
当编译第513个不同的正则表达式时,最久未使用的那个会被自动移除,最近使用的正则表达式会保留在缓存中,这样可以保证即使pattern的缓存数量超过512且每次使用的pattern不同仍然可以完整匹配,不会出现指向错误的情况,但是,这样比较浪费内存(可能只有几kb不到),因此 当我们动态生成时,还是尽可能的使用一下re.purge(),偶尔清空一下,不要一直堆积到512。
import re
for i in range(1000):
#每次生成一个唯一的正则pattern,且根据变量i动态变化)
dynamic_pattern=re.compile(f'pattern_{i}\\d+')
result=dynamic_pattern.search(f'pattern_{i}123')
print(f"弟{i}次: 缓存大小: {len(re._cache)}")
if i%100==0:#每隔100个清空一下pattern的缓存
re.purge()运行结果:
Flags作用
re模块内部的flags常量主要用于修改正则表达式的匹配行为可以在某些方面增强匹配范围。re模块内部所有类的具体使用情况如下表所示:
| 参数名称 (常量) | 类型 | 说明 |
|---|---|---|
**re.IGNORECASE(re.I**) |
标志常量 | 忽略大小写。使匹配对大小写不敏感。例如,[A-Z] 也会匹配小写字母。 |
**re.MULTILINE(re.M**) |
标志常量 | 多行模式。改变 ^ 和 $ 的行为。默认情况下,^ 和 $ 只匹配字符串的开始和结尾。启用后,^ 匹配每一行的开头(字符串开头和换行符之后),$ 匹配每一行的结尾(字符串结尾和换行符之前)。 |
**re.DOTALL(re.S**) |
标志常量 | 点(.)匹配所有字符。默认情况下,点 (.) 匹配除换行符 (\n) 之外的任何字符。启用此标志后,点 (.) 将匹配包括换行符在内的任何字符。 |
**re.ASCII(re.A**) |
标志常量 | ASCII 字符集。使 \w, \W, \b, \B, \d, \D, \s, \S 这些转义序列只匹配 ASCII 字符,而不是完整的 Unicode 数据库。这是 Python 3.6 及以后版本的默认行为,除非使用 re.UNICODE 标志。 |
**re.UNICODE(re.U**) |
标志常量 | Unicode 字符集(Python 3 已弃用)。在 Python 3 中,字符串默认是 Unicode,因此此标志是冗余的且没有效果。仅为向后兼容而保留。 |
**re.VERBOSE(re.X**) |
标志常量 | 详细模式。此标志允许你编写格式更清晰、可读性更高的正则表达式。它会忽略模式中的空白(除非在字符类中或使用反斜杠转义)并允许添加注释。非常适合编写复杂的正则表达式。 |
**re.LOCALE(re.L**) |
标志常量 | 区域设置模式。使 \w, \W, \b, \B 的匹配依赖于当前的区域设置(locale)。不推荐使用,因为该机制非常不可靠,且仅适用于 8 位字节模式。在 Python 3 中,re.ASCII 是更好的选择。 |
**re.DEBUG** |
标志常量 | 显示调试信息。在编译正则表达式时,将调试信息打印到标准输出。用于开发和理解复杂正则表达式的工作原理。 |
**re.NOFLAG** |
标志常量 | 无标志。表示不应用任何标志。用于明确表示不使用任何修饰符,使代码意图更清晰。 |
注意:上述所有的flag可以多个同时使用,此时需要使用'|'或'+'相连接,比如:
import re
re.search(pattern=r'^\d+&#使用re.verbose加注释',string='',flags=re.MULTILINE|re.VERBOSE)内部类详解
除了上述函数外,re模块内部还有四个类,分别是:
re.Match,re.Pattern,re.FlagTypes,re.error
这里以re.Match类为例,我们来看一下其内部的具体调用过程:

re.Match类初始化

re.search函数
可以发现,他们都来自于_compiler类下的compile方法(函数),只不过re.search函数传入了pattern与flags,而re.Match的pattern为'’,flags为0,这意味着它无法参与任何匹配过程,再加之初始化时使用了type()函数,我们不难猜出,这个re,Match主要用于类型说明,不参与任何实际应用,更直白一些,re.Match,re.Pattern,re.RegexFlag这三个类除了用来写TyptHint没有什么卵用。
比如:
我们在某些情况下可能需要自定义一个函数,其中的某些参数与re内部函数的参数一致,比如
pattern,flag,那么我们便可以按照这样的形式来写TypeHint
#re.Pattern,re.Match,re.RegexFlag
'''
re.Pattern,re.Match还有re.RegexFlag都是python regex内部的类
日常使用中除了用来写TypeHint没有什么卵用
'''
import re
def re_func(string:str,pattern:re.Pattern,flag:re.RegexFlag)->re.Match:
return re.search(pattern,string,flag)
效果:

re.error异常处理
re.error是这四个类中比较特殊的类,这个类主要用来异常处理正则匹配过程中可能产生的错误,当需要try except或继承自定义错误时试用。
但是,日常使用中谁会对正则表达式进行异常捕获?这种情况基本不可能出现,唯一可能的情况就是,你开发了一个函数,这个函数的某个参数是支持用户自定义的pattern,你在函数内部对这个pattern使用re.compile进行预编译然后执行查找匹配等任务,但是有些zz用户输入非法pattern,这个时候为了'委婉'地提醒他们,需要进行异常处理或者继承该error自定义error等
比如:
import re
def re_func(string:str,pattern:re.Pattern):
try:
pattern=re.compile(pattern)
return pattern.search(string)
except re.error as e:
print(f'{e},连个正则表达式的Pattern都写不明白?孩子你回家吧')
re_func('李白15265464897',r'(?)')运行效果:

总结

到这儿,Python正则表达式模块re内部的所有函数,类,常量,以及它们的使用方法已经讲解完毕,现在,你应该已经掌握了这个module的具体使用方法,正在摩拳擦掌,跃跃欲试,准备成为正则大佬了😎,可惜目前你只学会了刀枪棍棒,真正的精髓在于这些刀枪棍棒中的pattern,也就是正则表达式的语法。
接下来,我将详细讲解正则表达式的各种语法规则,带你深入探索正则表达式的奥秘。从最简单的字符匹配,到复杂的分组、捕获、断言等高级用法,每一个细节都不会放过。通过丰富的实例和详细的解析,让你真正掌握正则表达式的精髓,从而在处理文本数据时游刃有余,成为真正的正则大佬!
正则表达式语法
正则表达式最早出现于50年代,由数学家斯蒂芬·克莱恩和数学家肯·汤普森共同研究并发明。它是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。后来经过一些程序员的不断发展和完善,正则表达式逐渐成为了一种功能强大的文本处理工具。
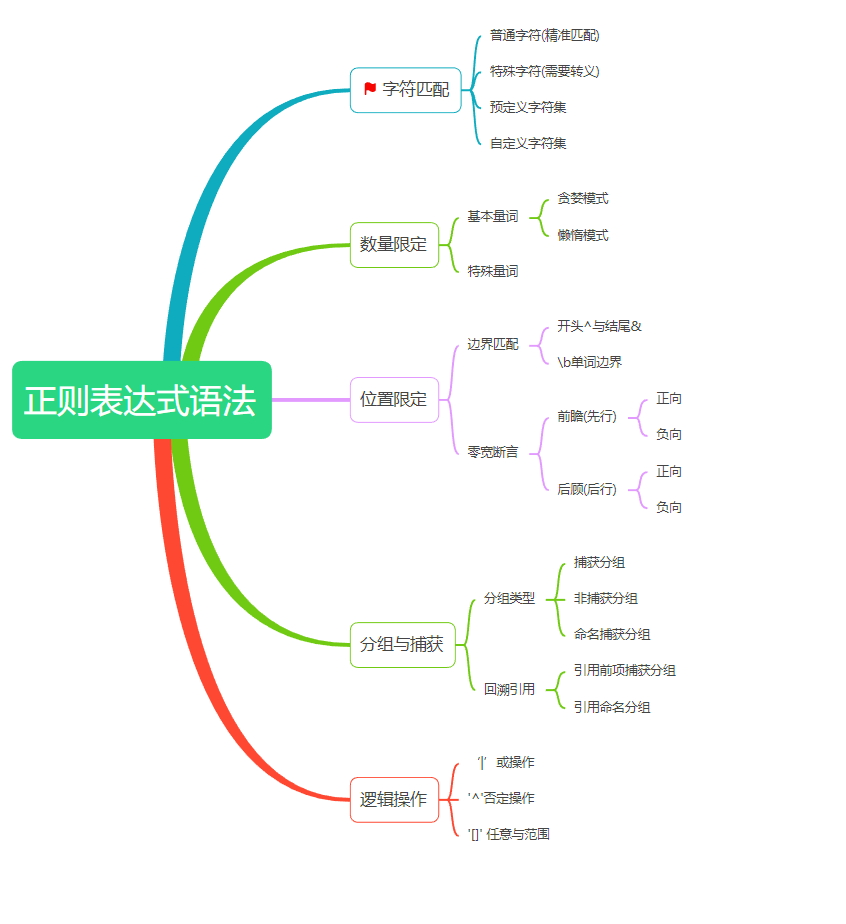
正则表达式的语法,这里我把它分为5个部分:字符匹配,数量限定,位置限定,分组与捕获
以及逻辑操作。当然,如果我这里的分类方法与你的不同,那么一切依你为准。
如何写出流利的正则Pattern?
先从大处着眼,把握文本的整体模式和规律。再逐步细化,关注细节特征,比如字符类型、出现次数,位置关系等,然后把这些特征使用正则规则替换。
看到这儿,那么部分杠精可能会说这听上去像是句废话,这点道理谁不知道啊?好好好,道理谁都懂,接下来我们来实践,例子才是最好的学习方法,实践出真知。
字符匹配
字符匹配是正则表达式的核心功能也是语法基础,这里我把他分为普通字符,预定义字符集,自定义字符集还有特殊字符。
精准匹配
当我们的pattern为一个自定义即不包含任何“量词”,“交替符”等正则规则的普通字符时,此时正则方法执行的是精准匹配,这种匹配模式常用于关键字统计,比如,我们需要统计一个pdf中关键字的出现次数,那么便可以通过这种方法来实现。
代码:
#精准匹配,关键词查询
import fitz
import re
total_num=0
pdf_path=r"E:\Desktop\测试专用\Broadband photon-counting dual-comb spectroscopy with attowatt sensitivity over turbulent optical paths.pdf"
keyword=str(input(f'请输入关键字:'))
with fitz.open(pdf_path) as pdf:
for page in range(pdf.page_count):
#为了保证这个单词是完整单词,使用\b来限定,不然这个单词可能是其他单词中的一部分
#不属于完整单词,同时还要考虑大小写
num=len(re.findall(rf'\b{keyword}\b',pdf[page].get_text(),re.IGNORECASE))
total_num+=num
print(f'第{page+1}页{keyword}数量',num)
print(f'关键字{keyword}总数:{total_num}')运行结果:
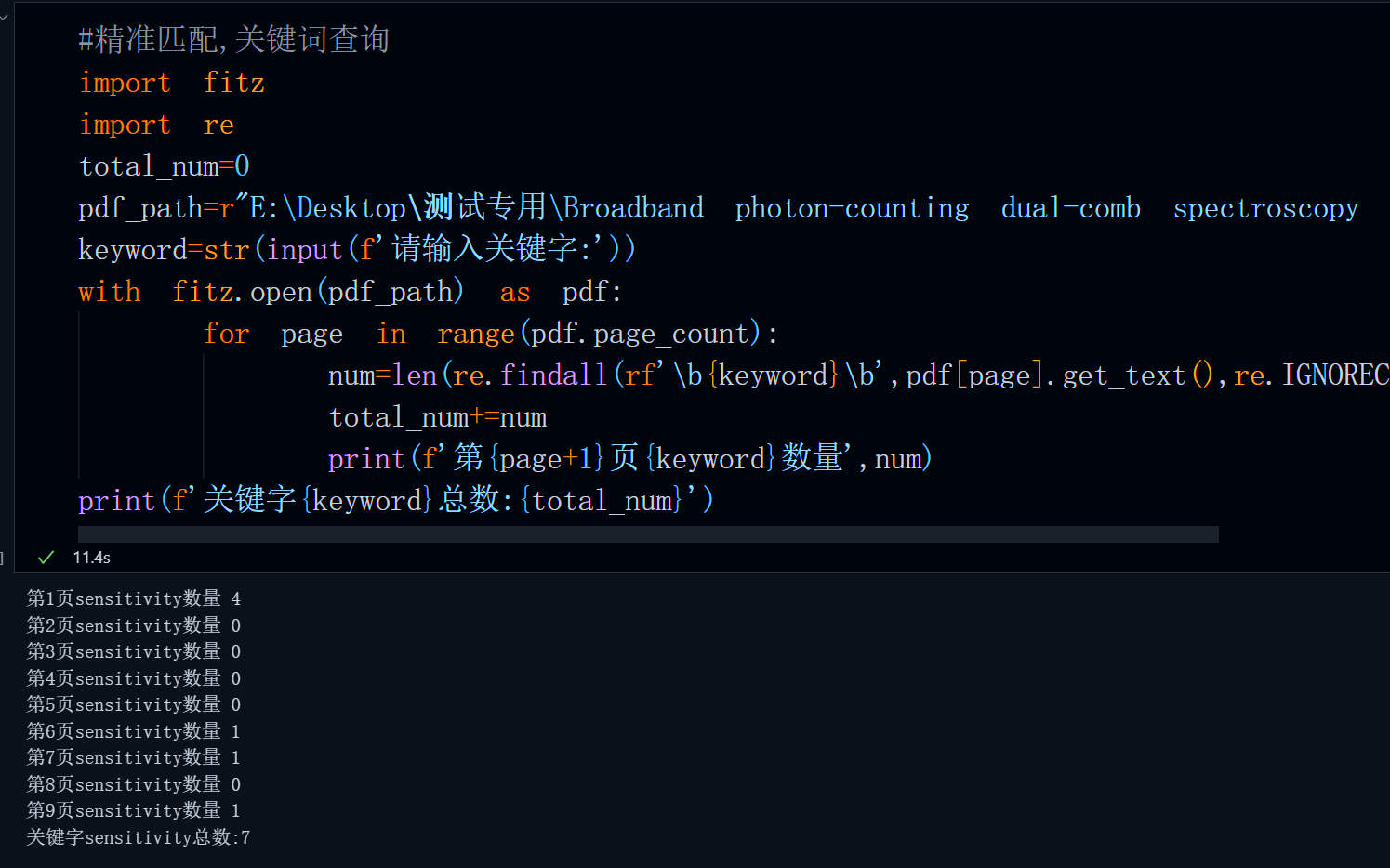
需要注意,为了保证我们的单词是完整出现而不是较长单词中的一部分比如mathematics中的math,我们需要在单词首位加一个\b用来避免这种情况,同时考虑到大小写的影响,flags还应该设置为re.IGNOGRCASE。
字符转义问题
\在Python中具有转义功能,\t表示制表符(一个tab的空格),\n表示换行, \\'表示单个\,所以当我们的字符常量中共包含'\'时,需要再字符串前加一个r或R(raw-string)来避免SyntaxWarning。
正因为\有着特殊含义,特别是在文件路径中,如果不加以r修饰,那么你字符中的\n可能被识别为换行,\t被识别为制表符。

同样,为了保留\在正则表达式中的特殊含义,我们需要在pattern这个字符串前加一个r,特别地,如果想要匹配\这个字符,那么需要使用'\\'来转义'\'。当然,如果你的待匹配对象是一个变量且不确定是否存在需要转义的字符,那么建议你使用re.escape函数来进行上述操作,具体使用方法前文已讲,这里不在赘述。
预定义字符集(元字符)
预定义字符集是正则表达式中的一类特殊符号,用于匹配某一类字符。主要包括:
- `.` - 匹配除换行符外的任意单个字符
- `\d` - 匹配任意数字,等价于`[0-9]`
- `\D` - 匹配任意非数字字符,等价于`[^0-9]`
- `\w` - 匹配字母、数字、下划线,等价于'[a-zA-Z0-9_ ]'
- `\W` - 匹配非单词字符,等价于'[^a-zA-Z0-9_ ]'
- `\s` - 匹配任意空白字符
- `\S` - 匹配任意非空白字符
- `\n` - 匹配换行符
- `\t` - 匹配制表符
`\v` - 匹配垂直制表符
`\f` - 匹配换页符
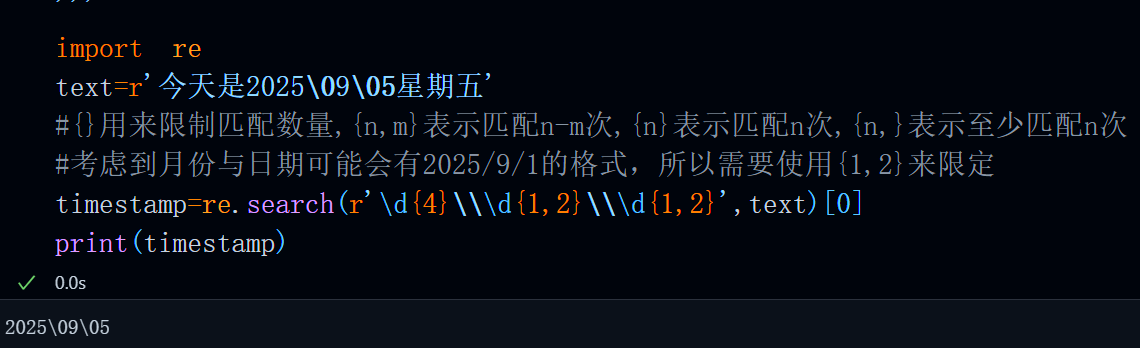
比如。我们需要匹配YYYY\MM\DD这样的时间戳,由于YYYY,MM,DD都是数字,所以可以使用\d来匹配对应的年月日数字,中间使用\\(转义\)来连接它们,也就是:
代码:
#预定义字符集匹配
r'''
预定义字符匹配是指我们使用regex预先定义好的一些表达来匹配字符,使用时要注意转义问题
要避免SyntaxWarning,在pattern前加一个r,匹配\的时候要使用\\来转义表示\
比如:
- `.` - 匹配除换行符外的任意单个字符
- `\d` - 匹配任意数字,等价于`[0-9]`
- `\D` - 匹配任意非数字字符,\d取反,等价于`[^0-9]`
- `\w` - 匹配字母、数字、下划线,等价与`[a-zA-Z0-9_]`
- `\W` - 匹配非单词字符,\w取反,等价与`[^a-zA-Z0-9_]`
- `\s` - 匹配任意空白字符(空白字符包括\t(水平制表符),\r(回车符),\n(换行符),\v(垂直制表符),\f(换页符))
- `\S` - 匹配任意非空白字符,\s取反
- `\t` - 匹配制表符
- `\f` - 匹配换页符
- `\n` - 匹配换行符
- `\v` - 匹配垂直制表符
'''
import re
text=r'今天是2025\09\05星期五'
#{}用来限制匹配数量,{n,m}表示匹配n-m次,{n}表示匹配n次,{n,}表示至少匹配n次
#考虑到月份与日期可能会有2025/9/1的格式,所以需要使用{1,2}来限定
timestamp=re.search(r'\d{4}\\\d{1,2}\\\d{1,2}',text)[0]
print(timestamp)运行结果:
自定义字符集[]
- `[abc]` - 匹配a、b或c中的任意一个字符
- `[^abc]` - 匹配不在a、b、c中的任意字符
- `[0-9]`-匹配0-9之间的任意数字
- `[a-z]` - 匹配从a到z的任意小写字母
- `[A-Z]`-匹配从A到Z的任意大写字母
- `[a-zA-Z]`-匹配从A到Z的任意大小写字母
- `[a-zA-Z0-9]·-匹配任意字母加数字组合
- `[0-9A-F]`-匹配十六进制数字
在匹配一些特殊字符时,我们经常需要用到一些不属于预定义字符集的字符,那么这时我们可以使用[]来自定义一个字符集。需要注意的是[]内部的元素默认为至少匹配一次,如果需要匹配多次需要使用量词来限定。
这里我们以匹配邮箱为例,按照邮箱的通用国际标准(RFC 5322)规则邮箱的一般构成为:
本地部分@域名(xxx.com,xxx.net,xxx.io,xxx.cn)(例如:username@example.com)
那么根据我们前边谈到的写出正则Pattern的通用方法,我们不难得到一个这样的pattern结构:
pattern=r'[]+@[]+\.[]+'
这里+表示每个部分匹配1次或多次,第一个[]用来定义邮箱号的字符构成,@后边的内容为域名,其中域名还可以进一步分为服务商与顶级域名,@后边的第一个[]用来定义服务商的字符构成,最后一个[]是顶级域名的字符集。
邮箱号的规则较为复杂,不过一般而言其主要是字母加数字构成,因此我们可以先在第一个[]填入:
[a-zA-Z0-9],然后便是可能存在的特殊符号,比如?!_*#等,这里为了考虑的全面一些,我们直接把它们全部放进去,也就是:
[0-9a-zA-Z.!#$%&’*+/=?^_`{|}~-]
接着便是域名了,服务商的名称的话基本就是纯数字+字母组合,当然也有一些服务商名称包含
. , _ , -这样的连字符,这些服务商基本都是一些使用Gmail或Outlook的公司自定义的域名。为了考虑周到一些,我们这部分也把它们加进去,那么第二个[]内容就是:
[a-zA-Z0-9._-]
最后一部分顶级域名比较固定,就这四个xxx.com,xxx.net,xxx.io,xxx.cn,那么直接:
[a-zA-Z0-9]
最终,结合上述思路,不难得到一个完整的邮箱正则匹配代码:
#自定义字符集匹配之邮箱匹配
'''
自定义字符集就是使用[]将我们所有需要匹配的字符包含在内,正则引擎默认的匹配行为是至少
'''
text='姓名:学制浅,电话号:13888888888,邮箱:0281??3*4.@sues.cn'
import re
email_pattern =r'[0-9a-zA-Z.!#$%&’*+/=?^_`{|}~-]+@[a-zA-Z0-9._-]+\.[a-zA-Z0-9]+'
print(f'邮箱:',re.search(email_pattern,text)[0])运行结果:
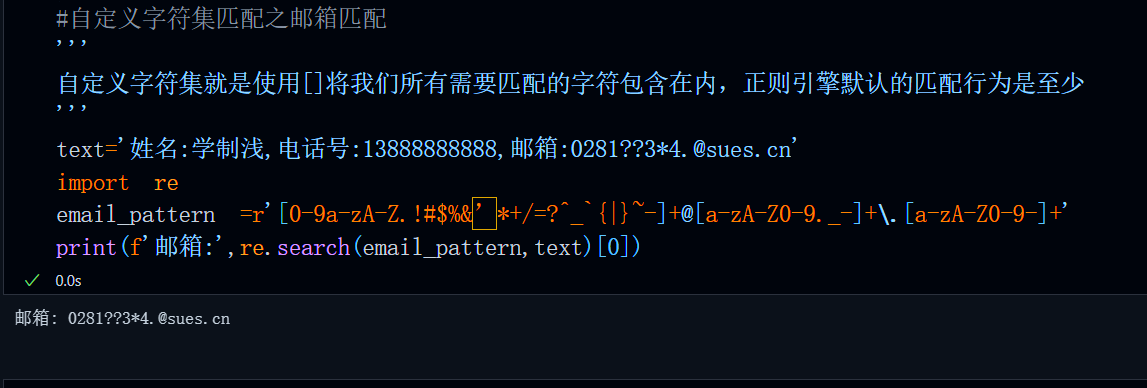
效果还可以,这个正则Pattern基本上可以应对99%的邮箱匹配,根据前边谈到的分组输出,我们还可以在@字符前后分别使用()包裹,这样可以分别输出邮箱账号与域名。也就是:
pattern =r'([0-9a-zA-Z.!#$%&’*+/=?^_`{|}~-]+)@([a-zA-Z0-9._-]+\.[a-zA-Z0-9-]+)'
此时,输出效果为:
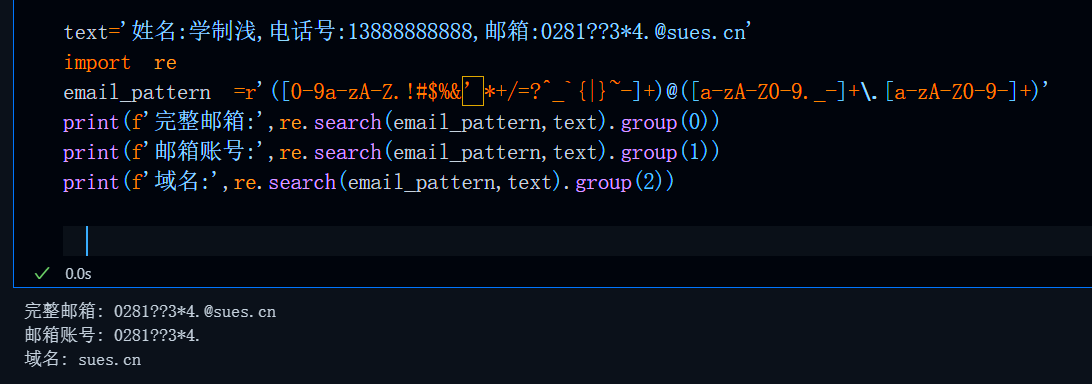
自定义字符集注意事项
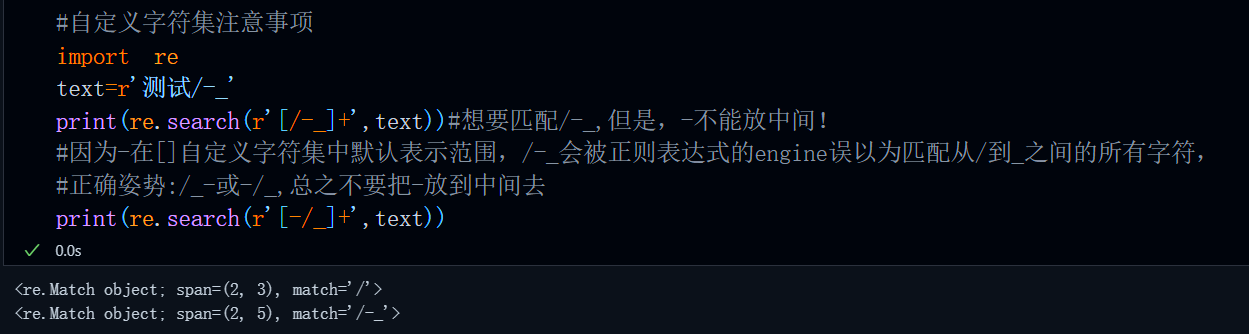
1.需要匹配-这个字符本身的时候不要把-放到一堆字符中间去!如果把-放到字符中间它表示的含义是范围!比如:
2.自定义字符集内匹配[ ]时不要忘记使用\转义!(也就是\[\])
3.自定义字符集与预定义字符集大部分情况下可以转换,如果为了更加直观和高效建议使用预定义字符集实现!比如:
- `\d` - 匹配任意数字,等价于`[0-9]`
- `\D` - 匹配任意非数字字符,\d取反,等价于`[^0-9]`
- `\w` - 匹配字母、数字、下划线,等价与`[a-zA-Z0-9_]`
- `\W` - 匹配非单词字符,\w取反,等价与`[^a-zA-Z0-9_]`
特殊字符
在正则表达式中,有两个特殊符号,分别是‘.‘’与^,'.'用来匹配除换行符以外的任何字符,
而^有两种用法,一种表示否定,另一种表示边界限定,这里我们只讲否定这一用法,后者在边界限定中继续讲解。
'.'的基本用法:
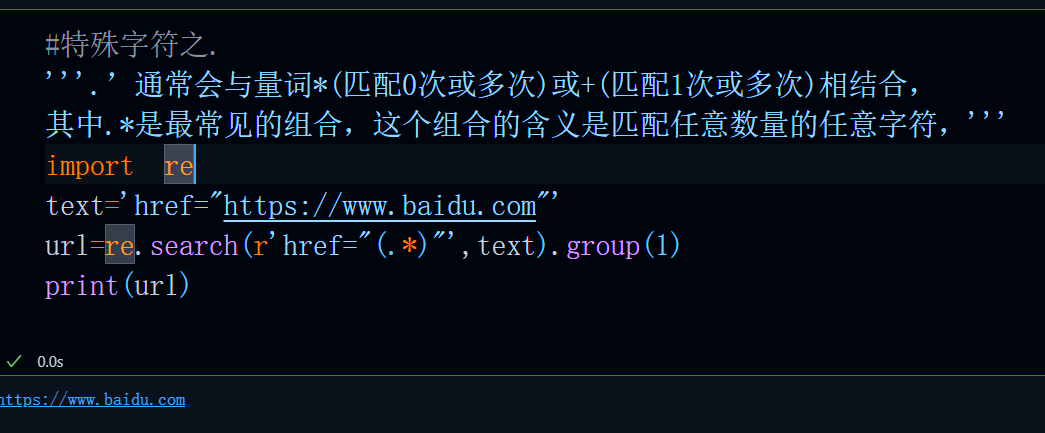
‘.’通常会与量词*(匹配0次或多次)或+(匹配1次或多次)相结合,其中.*是最常见的组合,这个组合的含义是匹配任意数量的任意字符,你可以在很多支持正则查找的工具中看到这个标志,比如:
vscode内的正则查找
TexStudio内的正则查找符号
这个组合主要用在匹配a与b之间的所有内容中
'^'否定:
当我们需要实现否定的功能,也就是不匹配某些内容时,那么这个时候可以使用[^]的形式来实现,比如,我们想要匹配一段话中不包含某个元素的内容:、
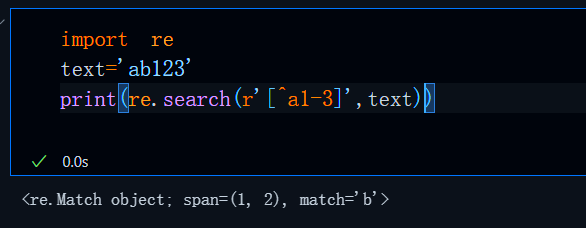
这里的pattern是指不匹配a和1-3之间的任何数字,那么匹配结果显然只有b
需要注意的是,在[]内^的作用域是其后边的所有字符,如果我们把^放到字母a后边,那么此时:
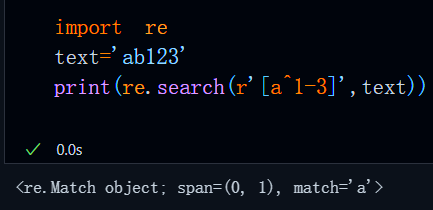
pattern的含义发生了变化,此时pattern的含义是匹配字母a,不匹配1-3之间的任何数字,那么结果自然是a
到这儿,字符匹配的是所有内容便讲解完了,接下来便是量词了,所谓凡事有度,字符匹配也是要有数量限定的,正则虽好,不可贪杯哦。
数量限定
当我们在匹配字符时,往往会遇到需要精确控制匹配次数的情况,这时数量限定就派上了用场。它允许我们指定某个字符或字符组在匹配过程中出现的具体次数或者次数范围,从而让匹配更加精准和灵活。
正则表达式中的量词根据匹配模式可以分为2类:贪婪模式,懒惰模式。
基本量词
`*` 匹配0次或多次
`+` 匹配1次或多次
`?` 匹配0次或1次 #最为特殊,可以转贪婪为懒惰
`{n}` 匹配恰好n次
`{n,}` 匹配至少n次
·{n,m}` 匹配n到m次
它们的作用域为该修饰符前边的1个字符,当然也可以是多个字符,若是多个字符需要使用()或[]包裹,也就是说:
ab*表示匹配字符a其中b匹配0次或多次
[ab]*表示匹配字符ab整体0次或多次
(ab)*表示匹配字符ab整体0次或多次并分组
(?:ab)*表示匹配字符ab整体0次或多次不分组
基本量词中*与+是两个抽象量词,他们分别表示匹配0次或多次,匹配1次或多次,主要用在匹配不确定数量的内容上,不过,可能有人会感到疑惑什么叫匹配0次?这里我们以一个简单的例子来说明:
代码:
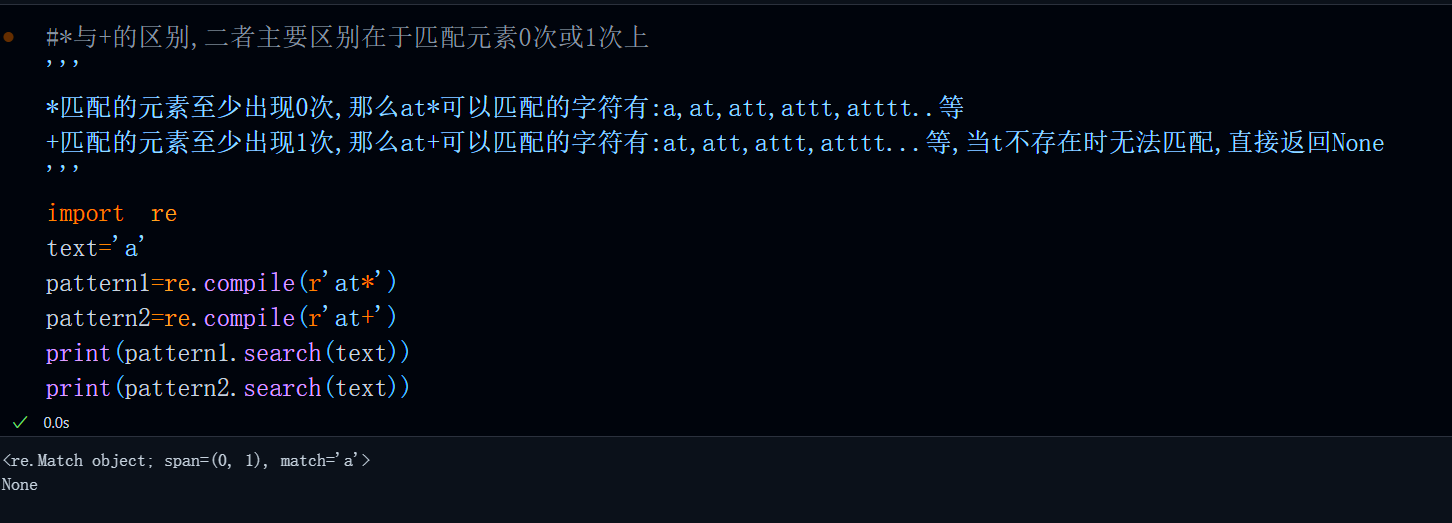
#基本量词之*与+的区别,二者主要区别在于匹配元素0次或1次上
'''
*匹配的元素至少出现0次,那么at*可以匹配的字符有:a,at,att,attt,atttt..等
+匹配的元素至少出现1次,那么at+可以匹配的字符有:at,att,attt,atttt...等,当t不存在时无法匹配,直接返回None
'''
import re
text='a'
pattern1=re.compile(r'at*')
pattern2=re.compile(r'at+')
print(pattern1.search(text))
print(pattern2.search(text))运行结果:
除此之外,如果我们想通过范围来限定匹配元素的数量,那么便可以使用{},其具体用法为:
- `{n}` 匹配恰好n次
- `{n,}` 匹配至少n次
- ·{n,m}` 匹配n到m次
这里我们以匹配电话号和日期为例,我们都知道,大陆手机号以1开头,第二位数字3-9,剩下的9为数字任意组合(使用\d{9}或[0-9]{9}),那么便可以这样来匹配:
import re
phone_num='13945678910'
if not phone_num.isdigit():
raise ValueError(f'电话号是纯数字!')
if not re.fullmatch(r'1[3-9]\d{9}',phone_num):#大陆手机号13x-19x
raise ValueError(f'号段不对!')
else:
print('正常的手机号')常见的日期格式为:YYYY-MM-DD,当然也不排除YY/MM/DD这样的短日期格式,那么我们的pattern便可以设计为:
pattern=r'\d{2,4}[-/年]\d{1,2}[-/月]\d{1,2}[日]'
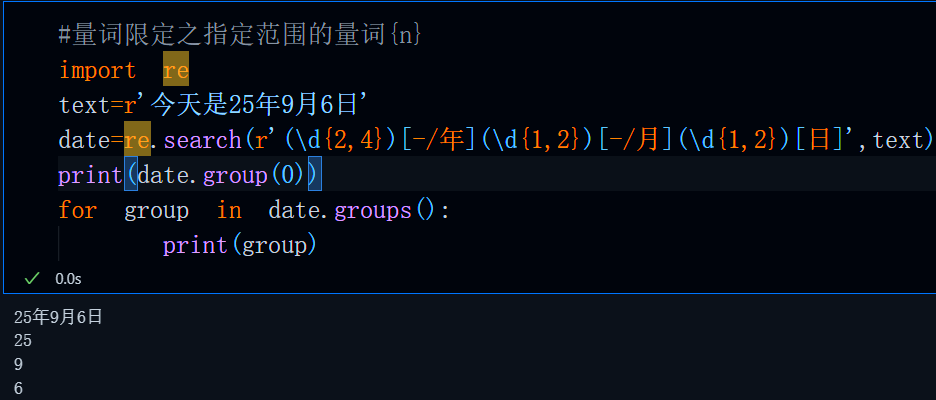
#量词限定之指定范围的量词{n}
import re
text=r'今天是25年9月6日'
date=re.search(r'(\d{2,4})[-/年](\d{1,2})[-/月](\d{1,2})[日]',text)
print(date.group(0))
for group in date.groups():
print(group)运行结果:
贪婪模式
所谓贪婪模式,就是指正则引擎按照pattern匹配时会尽可能的去匹配最长子串(默认行为),而在基本量词中除了{n}(匹配恰好n次)与{n,m}(匹配n到m此)外其他量词都属于贪婪模式,也就是:
`*` 匹配0次或多次
`+` 匹配1次或多次
`{n,}` 匹配至少n次
比如,在text中,我们想要使用.*来匹配a与d之间的所有内容,那么所有可能的匹配结果有:
abcd#最短
abcd123d
abcd123defd#最长
#基本量词之贪婪模式
import re
'''
.用来匹配除换行符外任意字符(除非使用re.DOTALL)
*用来表示修饰内容(前一个内容)匹配0次或多次
a.*d表示匹配a到d之间任意字符0次或多次这属于贪婪模式,
正则表达式会尽可能多和长的去查找以a开头以d结尾的字符串子串
'''
text='abcd123defd456'
greedy=re.search(r'a.*d',text)[0]
print(greedy)不出意外,最终的匹配结果是这三个中最长的那一个,这便是贪婪模式
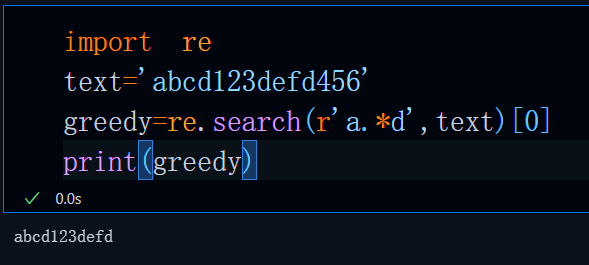
正则引擎按照pattern匹配字符串时会尽可能的去匹配又长又多的结果(这是默认行为)
懒惰模式
懒惰模式与贪婪模式恰好相反,正则引擎按照pattern匹配字符串时会尽可能的去匹配又短又少的结果。
我们只需要在所有的量词后加一个?便可以自动将贪婪模式转为懒惰模式,比如说,(a.*?d)转变为懒惰模式,那么其表示匹配a到d之间任意数量的任意字符串,但是要求axxxd这个子串最短:
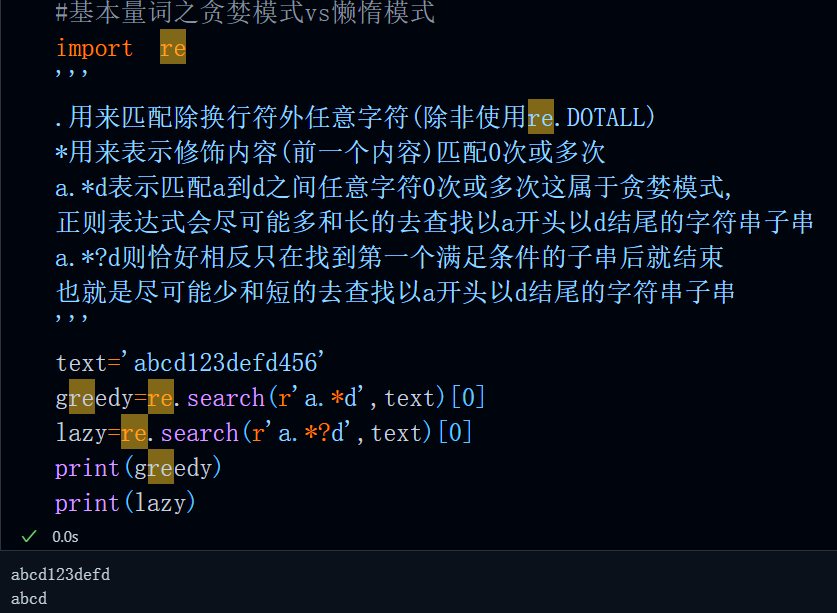
#基本量词之贪婪模式vs懒惰模式
import re
'''
.用来匹配除换行符外任意字符(除非使用re.DOTALL)
*用来表示修饰内容(前一个内容)匹配0次或多次
a.*d表示匹配a到d之间任意字符0次或多次这属于贪婪模式,
正则表达式会尽可能多和长的去查找以a开头以d结尾的字符串子串
a.*?d则恰好相反只在找到第一个满足条件的子串后就结束
也就是尽可能少和短的去查找以a开头以d结尾的字符串子串
'''
text='abcd123defd456'
greedy=re.search(r'a.*d',text)[0]
lazy=re.search(r'a.*?d',text)[0]
print(greedy)
print(lazy)运行结果:
位置限定
当我们在匹配字符时,有时需要进行位置限定,位置限定可以分为边界匹配与前瞻后顾(零宽断言)两个部分。
边界匹配^$
边界匹配是指匹配字符串的开始、结束或者单词的边界等特定位置。可以分为两类:
- 从xxx开始,以xxx结束(^,$)
- 完整的单词边界(匹配完整math而不是mathematics中的math)
^与$经常成对出现,当我们将要匹配的内容使用^&包裹时,此时待匹配的字符必须处于整个字符开头的位置(^限定开始,$限定结束),否则无结果。
^的作用域为其自身之后的所有字符,&的作用域为其自身之前的所有字符。
二者相结合,优势互补,正好可以实现匹配以xxx开始yyy结束的一段字符。
^的使用场景之一:校验用户名(数字字母开头):
#位置限定之^与&
import re
user_name='''Hello,Mr Crab'''
#检测用户名是否以数字或字母开头
if re.search(r'^[a-zA-Z0-9]',user_name):
print(f'合法用户名')
else:
print(f'非法用户名')运行结果:
$的使用场景之一:获取文件后缀名(尾部.之后的所有非.内容):
#位置限定之$获取文件类型
import re
#匹配文件名尾部$,并且.之后不包含.的内容
filename=r'test.txt'
filetype=re.search(r'\.[^.]+$',filename)
print(filetype.group(0))^$使用场景之一:密码强度检测(检测密码的构成)
#位置限定^$之密码强度检测
import re
password='1234'
is_strong=True
week_reason=None
checks={
"必须包含至少一个大写字母": r'^(?=.*[A-Z]).+$',
"必须包含至少一个小写字母": r'^(?=.*[a-z]).+$',
"必须包含至少一个数字": r'^(?=.*\d).+$',
"必须包含至少一个特殊字符": r'^(?=.*[!@#$%^&*()_+=-]).+$'
}
for key,pattern in checks.items():
if not re.fullmatch(pattern,password):
week_reason=key
is_strong=False
if not is_strong:
print(f'密码强度过弱:{week_reason}')
else:
print(f'密码强度足够!')运行结果:
单词边界\b
\b主要用于匹配完整单词(可以避免包含问题),比如我们需要统计这段话中math的数量:
'''Math is the abbreviation of mathematics.
Nowadays,collage math courses mainly include Linear Algebra,Advanced Mathematics,Probilities and Statistics'''
代码:
#单词边界 \b用来匹配完整单词(不包括包含在其他单词中的)
import re
text='''Math is the abbreviation of mathematics.
Nowadays,collage math courses mainly include Linear Algebra,Advanced Mathematics,Probilities and Statistics'''
result1=re.findall(r'math',text,re.IGNORECASE)
result2=re.findall(r'\bmath\b',text,re.IGNORECASE)
print(rf'无\b结果{result1}')
print(rf'有\b结果{result2}')运行结果:
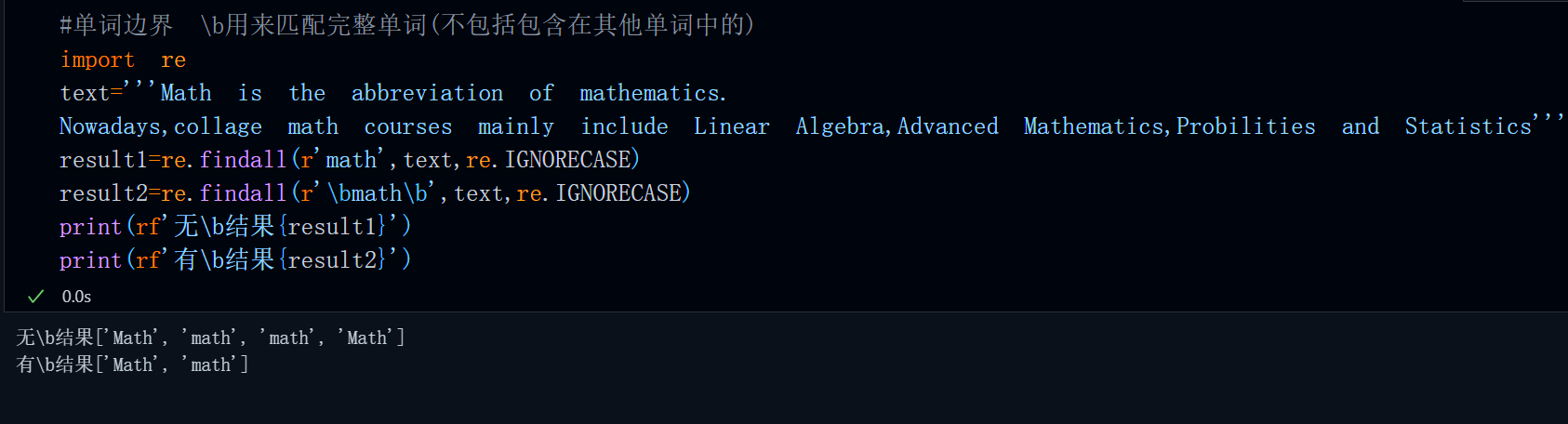
可以看到,如果不加\b单词边界限制,那么findall函数统计的math还来自于Mathematics中的math,此时匹配的并不是完整的math单词。使用\bmath\b后匹配的便是完整的math单词。
零宽断言(前瞻后顾)
零宽断言是正则表达式中一个较为复杂的概念,这里我给大家详细解释一下这个名称的由来以及使用方法。
这里的断言在逻辑上有些类似Python中的断言,只占用一行,后边紧跟着条件,条件后是不满足条件时执行的具体操作(输出报错message),当然还会引发AssertionError(正则表达式中不会)
根据判断内容的正确与否,我们可以将其分为正向与负向,根据其判断的内容所处位置我们还可以将其分为前瞻(look ahead)与后顾(look behind)。因此零宽断言共计有四种,分别是:正向前瞻,负向前瞻,正向后顾,负向后顾。他们的具体表达形式如下:
`(?=...)` 正向前瞻断言
`(?!...)` 负向前瞻断言
`(?<=...)` 正向后顾断言
`(?<!...)` 负向后顾断言
人们常说一个人做事要瞻前顾后,这里的前瞻后顾与该成语中的瞻前和后顾有着相似的逻辑内涵,前瞻指的是在某个位置之前进行匹配判断,就像在前进道路上提前观察前方是否符合预期条件;后顾是指在某个位置之后进行匹配判断,如同回头查看已经走过的路是否满足特定要求。
注意:这里的前后分别指的是x字符串的右侧与左侧,因为正则引擎匹配内容时的顺序为从左到右!
正向前瞻(?=)
含义:yy前面(右侧)的内容是xxx的时候匹配yy,也就是匹配yy前面(右侧)是xxx的yy
表达式: yy(?=xxx)xxx
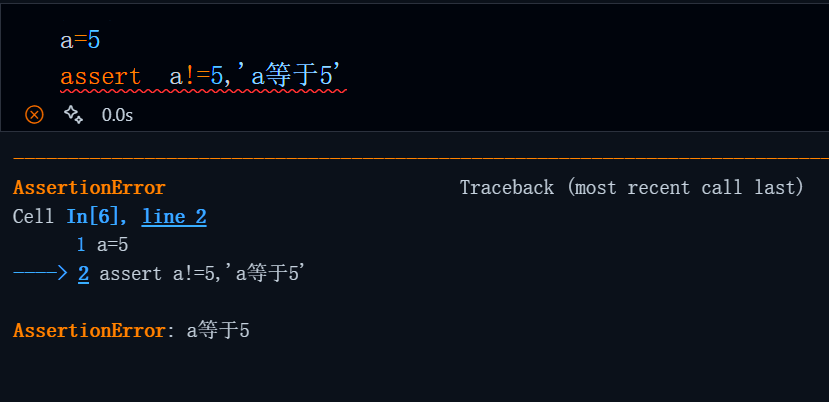
正向是指表达式判断的内容为等于或者是,前瞻指的是在某个位置之前进行匹配判断(前指右侧),在使用时前瞻时,表达式要置于待匹配内容的前方(右侧)。比如,要根据邮箱来获取qq号,那么便可以使用正向前瞻来实现。
匹配逻辑很简单,就是匹配一串数字(\d+),但我们要确保这个数字的右侧(前方)是@qq.com,由于判断条件为是属于正向,并且待判断内容位于待匹配内容前方,所以我们使用正向前瞻。
代码:
#位置限定零宽断言之正向前瞻
'''正向前瞻:yy(?=xxx)xxx
当待匹配内容前方(右侧)存在xxx的时候匹配该内容,即匹配前面(右侧)是xxx的yy
(?=)类似于if条件相等语句判断
可用于检查待匹配内容前方是否存在xxx'''
import re
info=r'''88888888@qq.com'''
qq_num=re.search(r'\d+(?=@qq.com)',info)#如果是qq邮箱(以qq.com结尾)输出qq号
if qq_num:
print(f'QQ号为:{qq_num.group(0)}')
else:
print(f'非QQ邮箱无法匹配!')
运行结果:
负向前瞻(?!)
含义:yy前面(右侧)的内容不是xxx的时候匹配yy,也就是匹配yy前面(右侧)不是xxx的yy
表达式: yy(?=xxx)xxx
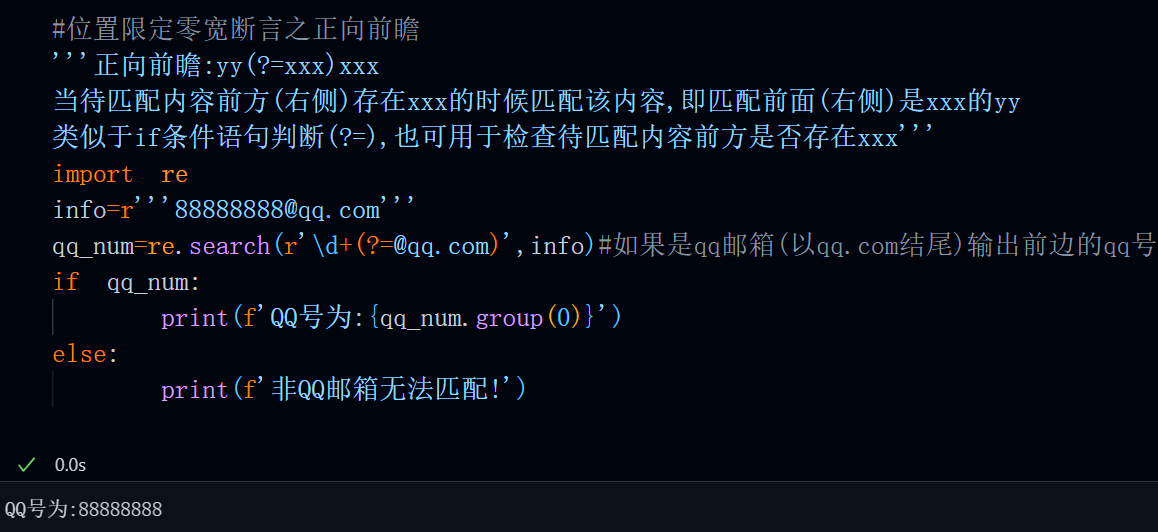
负向是指表达式判断的内容为不等于或者不是,前瞻指的是在某个位置之前进行匹配判断(前指右侧),在使用时前瞻时,表达式要置于待匹配内容的前方(右侧)。比如,要判断用户名(user123@admin)中是否包含admin来筛选非管理员用户。
匹配逻辑很简单,就是匹配后缀不以admin结尾的一串数字或字母,但我们要确保这个数字的由于判断条件为不是属于负向,并且待判断内容位于待匹配内容前方,所以我们使用负向前瞻。
代码:
#位置限定零宽断言之负向前瞻
'''负向前瞻:yy(?!xxx)xxx
当待匹配内容前方(右侧)不存在xxx的时候匹配该内容,即匹配前面(右侧)不是xxx的yy
类似于if条件语句判断!=,也可用于检查待匹配内容前方是否存在xxx;'''
import re
#检查username中不包含"admin"
usernames=['user123@normal','user456@normal','user789@admin']
for username in usernames:
if re.match(r'\w+\d+@(?!admin)',username):
print("不包含admin.不是管理员!")
else:
print("包含admin,是管理员!")运行结果:
正向后顾(?<=)
含义:yy后面(左侧)的内容是xxx的时候匹配yy,也就是匹配yy后面(左侧)是xxx的yy
表达式: xxx(?<=xxx)yy
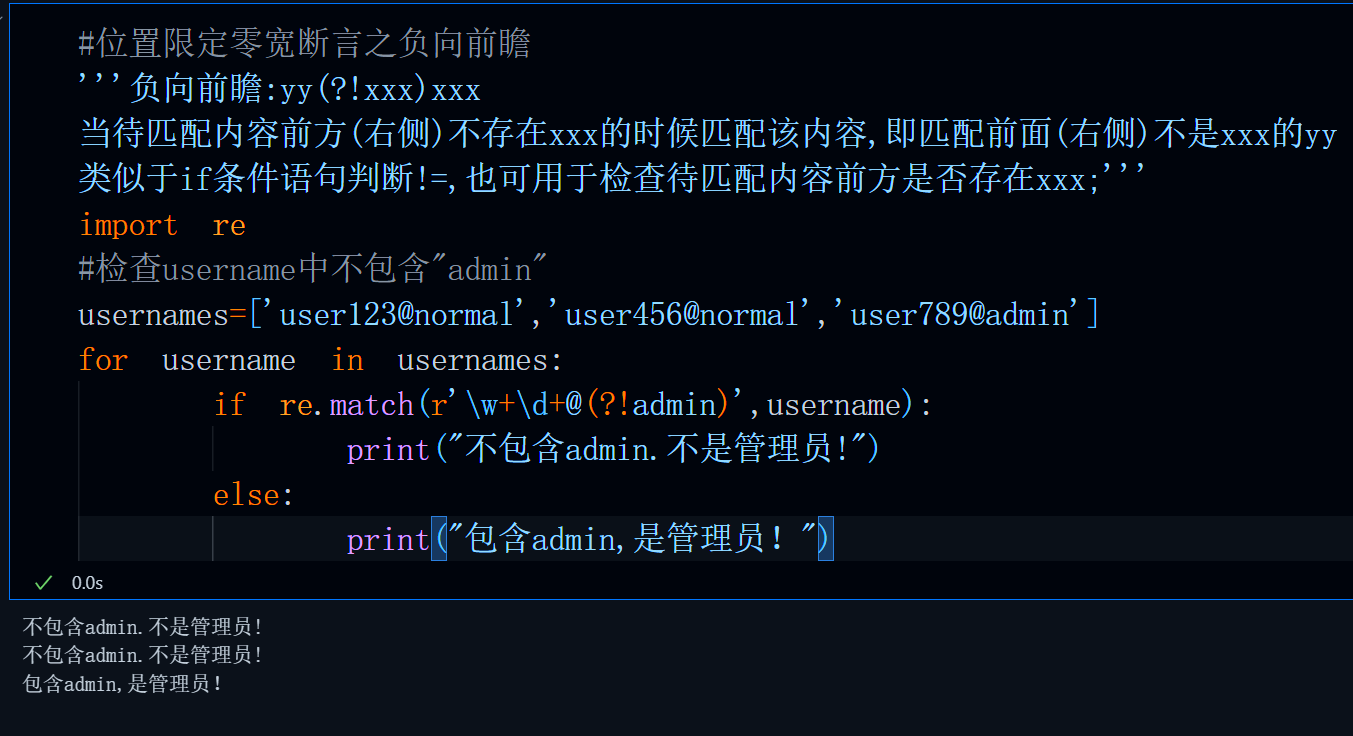
正向是指表达式判断的内容为等于或者是,后顾指的是在某个位置之后进行匹配判断(后指左侧),在使用后顾时,表达式要置于待匹配内容的后方(左侧)。比如,要获取姓名:学智枪这段话中的人物姓名,那么便可以使用正向后顾来实现。
匹配逻辑很简单,就是匹配一段字符(\w+),但我们要确保这个字符的后方(左侧)是姓名:,由于判断条件为是属于正向,并且待判断内容位于待匹配内容后方,所以我们使用正向后顾。
代码:
#位置限定零宽断言正向后顾
'''正向后顾:xxx(?<=xxx)yy
当待匹配内容后方(左侧)存在xxx的时候匹配该内容,即匹配后面(左侧)是xxx的yy
类似于if条件语句判断==,也可用于检查待匹配内容后方(左侧)是否存在xxx(前缀)'''
import re
info=r'''姓名:学智抢'''
name=re.search(r'(?<=姓名:)\w+',info).group(0)
print(name)运行结果:
负向后顾(?<!)
含义:yy后面(左侧)的内容不是xxx的时候匹配yy,也就是匹配yy后面(右侧)不是xxx的yy
表达式: xxx(?<=xxx)yy
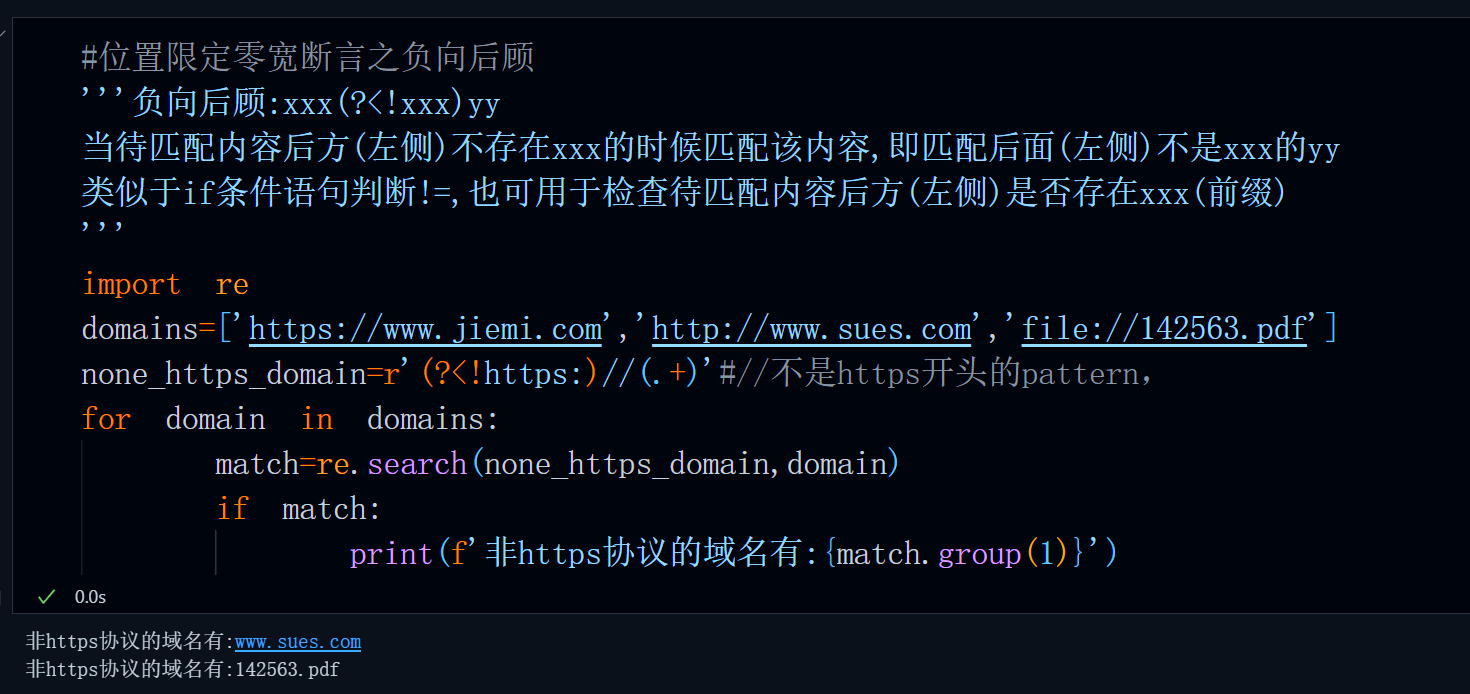
负向是指表达式判断的内容为不等于或者不是,后顾指的是在某个位置之后进行匹配判断(后指左侧),在使用时后顾时,表达式要置于待匹配内容的后方(左侧)。比如,要获取非https协议的域名,便可以使用负向后顾。
匹配逻辑很简单,就是匹配前缀不以https:开头的//后的所有内容,由于判断条件为不是属于负向,并且待判断内容位于待匹配内容后方(左侧),所以我们使用负向后顾。
代码:
#位置限定零宽断言之负向后顾
'''负向后顾:xxx(?<!xxx)yy
当待匹配内容后方(左侧)不存在xxx的时候匹配该内容,即匹配后面(左侧)不是xxx的yy
类似于if条件语句判断!=,也可用于检查待匹配内容后方(左侧)是否存在xxx(前缀)
'''
import re
domains=['https://www.jiemi.com','http://www.sues.com','file://142563.pdf']
none_https_domain=r'(?<!https:)//(.+)'#//不是https开头的pattern,
for domain in domains:
match=re.search(none_https_domain,domain)
if match:
print(f'非https协议的域名有:{match.group(1)}')运行结果:
前瞻后顾总结
到这儿,可能大家看的还是有些迷糊,那么我这里按照这样的类比方式,你一定可以醍醐灌顶
| 断言类型 | 正则表达式示例 | 类比 | 更精确的描述 |
|---|---|---|---|
| 正向前瞻 | yy(?=xxx)xxx |
**类似于 endswith** |
匹配 **yy,但要求 yy 的后面必须紧跟着** xxx |
| 负向前瞻 | yy(?!xxx)xxx |
**类似于 not endswith** |
匹配 **yy,但要求 yy 的后面必须不能是** xxx |
| 正向后顾 | xxx(?<=xxx)yy |
**类似于 startswith** |
匹配 **yy,但要求 yy 的前面必须紧跟着** xxx |
| 负向后顾 | xxx(?<!xxx)yy |
**类似于 not startswith** |
匹配 **yy,但要求 yy 的前面必须不能是** xxx |
总而言之,前瞻用于匹配或校验后缀,后顾用于匹配或校验前缀。所谓前瞻就是向前(右)看,后顾就是回头向后(左)看。它们类似与python字符串内置方法中的endswith和startswith但是这两个方法只能校验和匹配固定内容,无法实现正则校验!
分组与捕获
分组这一概念,在文章开篇出关于re内一些函数的返回值一处就已说明过了,这里我们再来重温一下,并补充一下捕获的概念。
分组是正则表达式语法中一个绝秒的设计,使用分组可以对匹配到的内容进行引用并进一步提取详细信息。特别是在提取日期,URL,IP地址,邮箱等关键信息时,使用分组的形式可以让我们分别输出匹配结果中的每一部分。比如匹配日期时,分别输出年,月,日,时,分,秒等信息,匹配URL时分别输出域名与查询参数等...
分组这一语法的一般形式是使用圆括号将某些部分包含[断言除外],此时每个圆括号内的部分便是一个分组。当然,整个匹配结果本身也属于一个分组。
pattern=r'(\d{4})[-/_\s]*?(\d{1,2})[-/_\s]*?(\d{1,2})
#三个圆括号分别对年月日进行分组
例如:
#返回值之分组获取group
r'''
当我们的pattern中使用了小括号将某些部分包含时[断言除外],每个小括号内的部分便是一个分组
这里以匹配出生年月日这个pattern为例:
'(\d{4})[-/_\s]*?(\d{1,2})[-/_\s]*?(\d{1,2})'共计三个括号,且每个括号内不包含断言
#因此最后的分组总数便是1+3=4,
分组的总数等于()个数+1,这是因为第一个分组内容肯定是完整的匹配结果,要想单独获取每个分组,索引需要从1开始
当然,只要匹配结果存在,那么直接通过索引[0]和.group(0)获取到的完整匹配结果是一致的
也就是说即使你没有在pattern中显示地使用分组,仍然会至少分一个组出来,这个组便是你的完整匹配结果
特别地,如果需要获取不包含完整匹配结果的分组内容,可以通过groups方法来实现
'''
import re
string='姓名:李刚,出生年月:1989/05-01,手机号:18888888888'
#出生年月日之间的连接符可能的情况:
#- _ / 空格或空白,所以每个数字间使用[-/_\s]表示可能的字符集,同时这些符号可能出现也可能不出现
#所以匹配次数为*:0次或多次
birthday=re.search(pattern=r'(\d{4})[-/_\s]*?(\d{1,2})[-/_\s]*?(\d{1,2})',string=string)
print(f'完整出生日期:{birthday[0]}')
print(f'完整出生日期:{birthday.group(0)}')
print(f'出生年份:{birthday.group(1)}')
print(f'出生月份:{birthday.group(2)}')
print(f'出生日:{birthday.group(3)}')
print(f'所有不包括完整匹配结果的分组:{birthday.groups()}')正则匹配出生年月日
当我们通过group+索引的方式来获取分组内容时,要注意分组总数等于()个数+1,因为第一个分组内容是完整的匹配结果,后边才是每个分组的结果,若想要单独获取每个分组,索引需要从1开始。
当我们通过groups方法来获取分组内容时,分组总数等于()个数,因为该方法返回的列表中不包含完整匹配结果,若想要单独获取每个分组,索引需要从0开始。
运行结果:
非捕获与命名捕获
只要使用()将字符包括,那么正则引擎便会将()内的内容作为一个分组,而捕获与非捕获是指,我们使用()分组后,在最终的匹配结果中是否可以通过group(index)的形式获取到这个()内的具体内容,比如说:
代码:
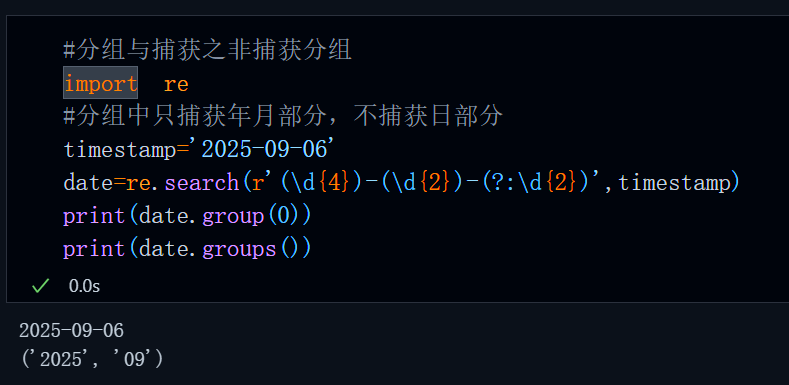
#分组与捕获之非捕获分组
import re
#分组中只捕获年月部分,不捕获日部分
timestamp='2025-09-06'
date=re.search(r'(\d{4})-(\d{2})-(?:\d{2})',timestamp)
print(date.group(0))
print(date.groups())运行结果:
显然,不难发现控制分组是否捕获的关键字是?:
(?:xxx)#分组但是不捕获
当我们在()内添加?:时,便可以使得这个()内的元素被分组,但是不捕获,也就是使用group(index)无法获取,这样可以节省内存
有些时候我们可能还需要对这个分组进行命名,方便后续操作(引用),这个时候我们需要按照这样的格式来命名:
(?P<name>xxx)#注意字母P必须为大写,xxx为具体匹配规则,name为该分组名
也就是在分组括号最前端使用?P<>来对该分组命名,命名后,我们可以使用group('name')来分别获取每一个分组内容(group(0)依然是完整匹配结果),此时称这些分组为捕获组,可以使用groupdict()方法来获取具体的分组情况:
代码:
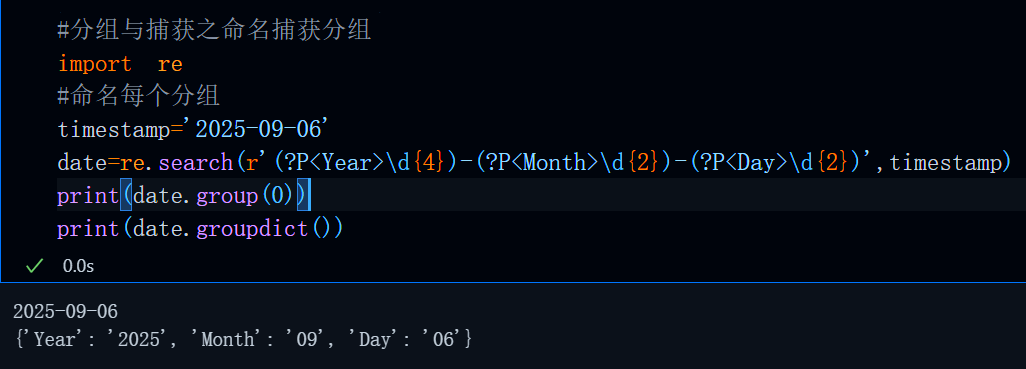
#分组与捕获之命名捕获分组
import re
#命名每个分组
timestamp='2025-09-06'
date=re.search(r'(?P<Year>\d{4})-(?P<Month>\d{2})-(?P<Day>\d{2})',timestamp)
print(date.group(0))
print(date.groupdict())运行结果:
捕获组引用
前边我们说到,捕获后的分组可以对匹配到的内容进行引用并进一步提取详细信息,这里我们来看一下捕获组引用这一具体操作。
捕获组引用是指,在正则表达式中引用前边捕获分组内容,具体使用场景有:
| 场景 | 分组类型 | 示例 |
|---|---|---|
| 字符串替换 | \1 或 \g<name> |
re.sub(r'(\d+)', r'\1', text) |
| 检测重复内容 | 反向引用 \1 |
r'(\w+)\s+\1' |
在引用时,我们还可以根据是否对捕获组组命名将其分为命名引用和不命名引用
不命名引用捕获组
不命名引用的具体引用方式为 \index,其中index为该分组在所有分组中的序数,比如:
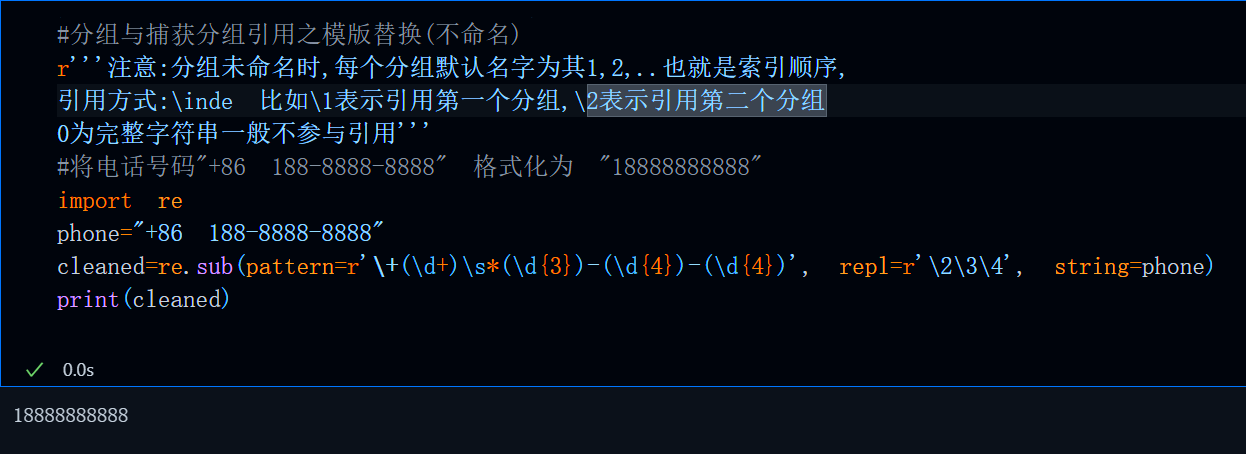
#分组与捕获分组引用之模版替换(不命名)
r'''注意:分组未命名时,每个分组默认名字为其1,2,..也就是索引顺序,
引用方式:\inde 比如\1表示引用第一个分组,\2表示引用第二个分组
0为完整字符串一般不参与引用'''
#将电话号码"+86 188-8888-8888" 格式化为 "18888888888"
import re
phone="+86 188-8888-8888"
cleaned=re.sub(pattern=r'\+(\d+)\s*(\d{3})-(\d{4})-(\d{4})', repl=r'\2\3\4', string=phone)
print(cleaned)
运行结果:
命名引用捕获组
命名引用与不命名引用有所区别, 当我们引用一个命名过的分组时,需要通过:
\g<name>,name为分组名
这里以重新组合时间戳为例:
#分组与捕获分组引用之模版替换(命名引用)
import re
timestamp='2025-09-07'
timestamp=re.sub(pattern=r'(?P<Year>\d{4})-(?P<Month>\d{2})-(?P<Day>\d{2})',repl=r'\g<Day>-\g<Month>-\g<Year>',string=timestamp)
print(timestamp)运行结果:

重复单词检测
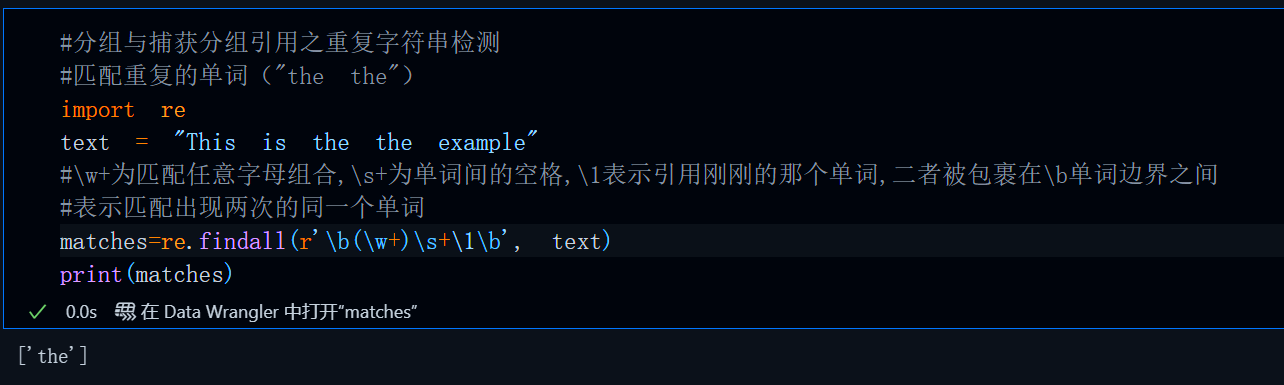
重复单词检测的原理其实很简单,就是匹配单词后通过引用的形式再匹配这个单词一遍,如果匹配成功,说明有单词重复,具体代码如下:
#分组与捕获分组引用之重复字符串检测
#匹配重复的单词("the the")
import re
text = "This is the the example"
#\w+为匹配任意字母组合,\s+为单词间的空格,\1表示引用刚刚的那个单词,二者被包裹在\b单词边界之间
#表示匹配出现两次的同一个单词
matches = re.findall(r'\b(\w+)\s+\1\b', text)
print(matches) # ['the']运行结果:
逻辑操作之"|"
正则表达式支持“或”这一逻辑操作,'|'可以连接多个pattern,实现任意一个存在则匹配的效果,当然也可以用来同时匹配多个Pattern对应的字符(需要使用findall,search只返回首个找到的)
比如,同时匹配不同类型的时间戳:
#逻辑操作之或"|"
'''可以连接多个pattern,实现任意一个存在则匹配任一个的效果
#也可以用来同时匹配多个Pattern对应的字符(需要使用findall,search只返回首个找到的)
实际上就是或这一逻辑操作'''
import re
text="15/09/2023 2023-09-15"
matches=re.findall(r'\d{4}-\d{2}-\d{2}|\d{2}/\d{2}/\d{4}', text)
print(matches)运行结果:

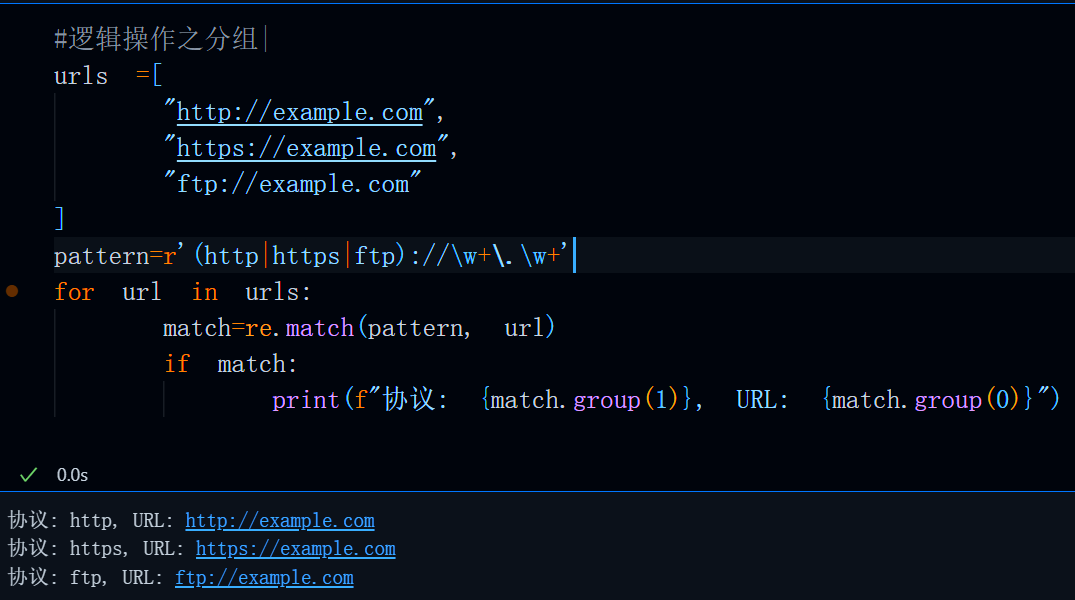
当然,“|”这一运算也支持分组,比如说,
#逻辑操作之分组|
urls =[
"http://example.com",
"https://example.com",
"ftp://example.com"
]
pattern=r'(http|https|ftp)://\w+\.\w+'
for url in urls:
match=re.match(pattern, url)
if match:
print(f"协议: {match.group(1)}, URL: {match.group(0)}")
运行结果:
实战案例
讲了这么多,我们来实战一下,这里我給大家准备了两个个案例来实战一下,分别是web爬虫,自动获取微信wxid。
web爬虫之正则匹配url
这里我们以爬取nature journal index内的所有子刊链接为例:
Nature siteindex子刊链接汇总界面
·首先通过抓包分析,将网页内容保存到本地txt内,具体爬取过程可以参考这篇文章:
https://blog.csdn.net/weixin_73953650/article/details/150933136?spm=1001.2014.3001.5501
这里我们直接使用保存到本地的txt,分析网页结构不难发现,所有蓝色字体的href属性的值便是跳转链接,我们只需要获取到所有href值然后手动拼接即可
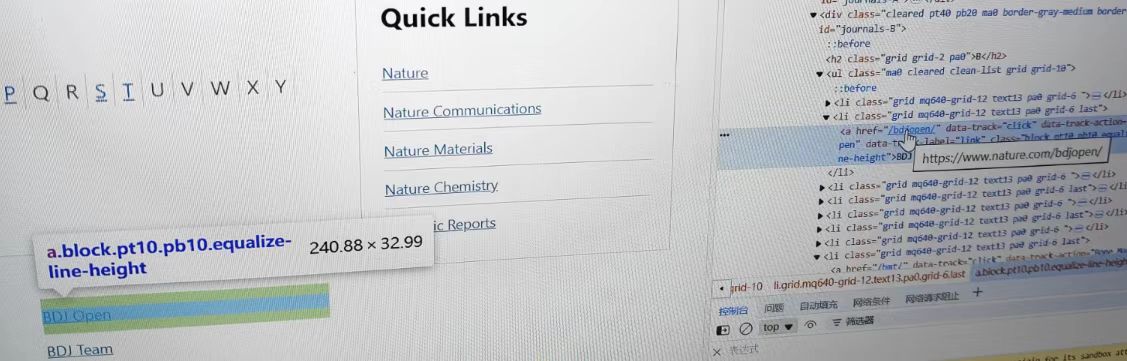
由于是要获取href后的值,那么pattern自然可以写成:
pattern=r'href="/(.*)/"'
#实战案例一:爬虫链接提取(正则表达式实现)
import re
with open('test.txt','r') as f:
hrefs=re.findall(pattern=r'href="/(.*)/"',string=f.read(),flags=re.MULTILINE)
sub_journal_links=['https://www.nature.com/'+link+'/' for link in hrefs]
print(sub_journal_links)运行效果:
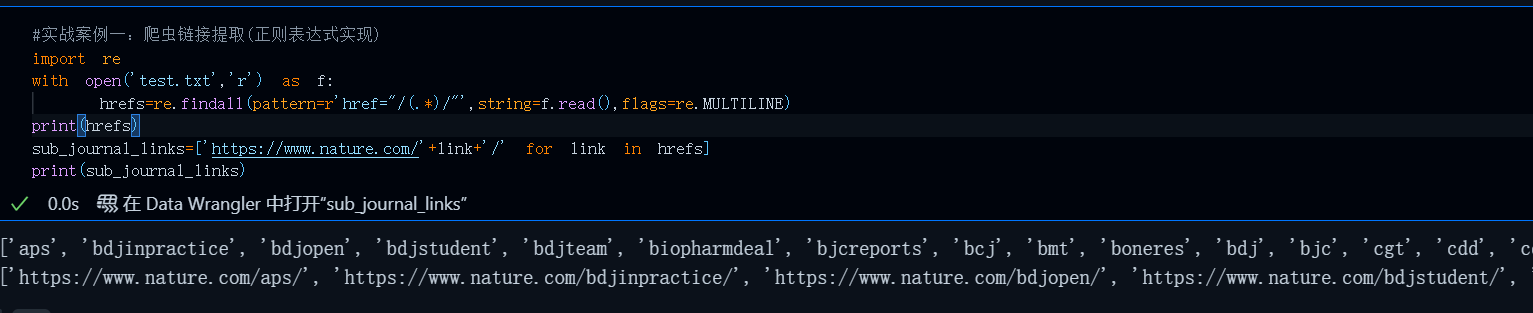
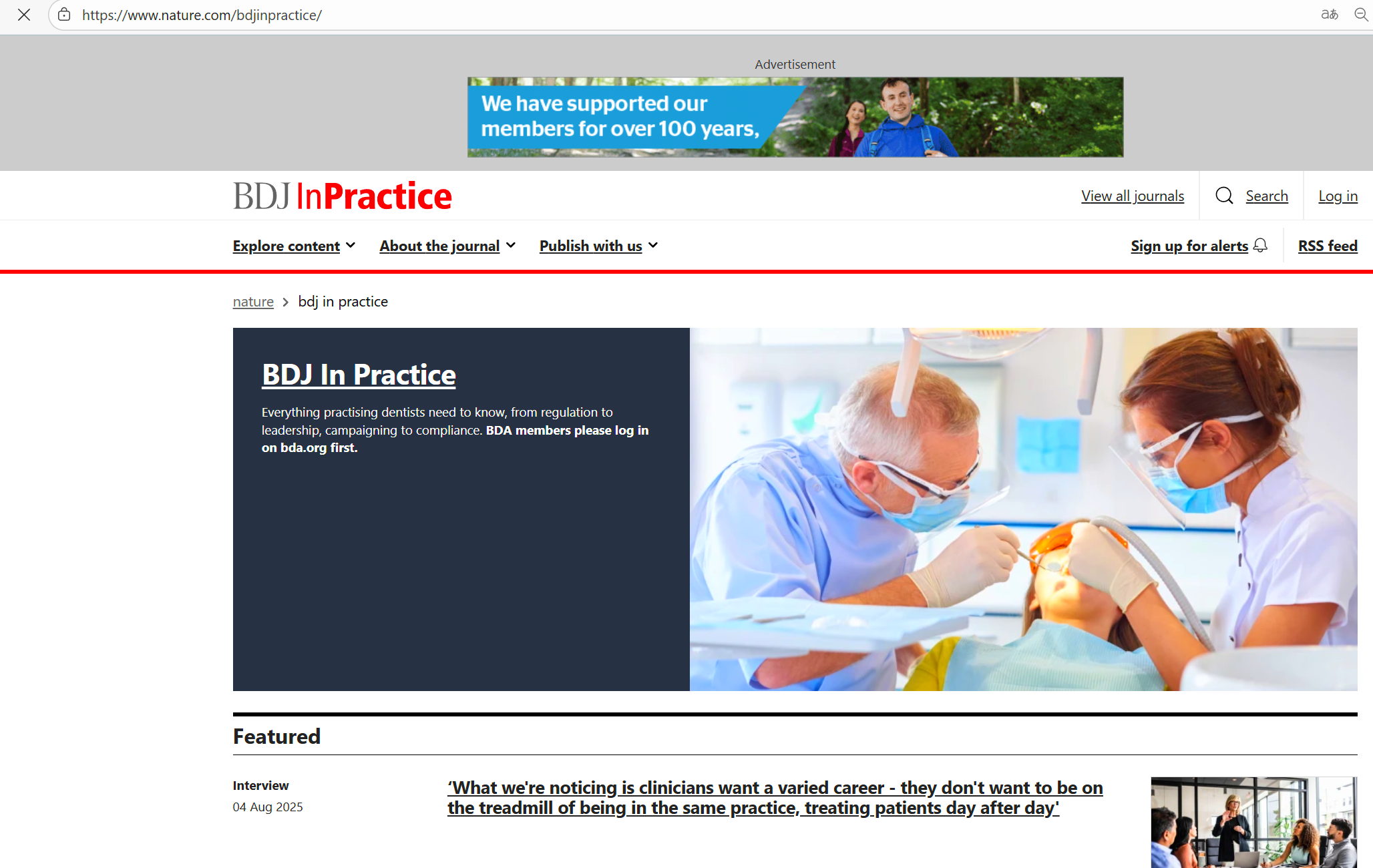
在浏览器中随便打开一个url测试一下:
总结

但筑模式,前程自明
.掠万物如风,*吞星月似海,+贪婪是本性,?懒惰亦从容。捕获是尘缘,分组即因果,
()圈一方天地,\1唤旧日重逢,数据如潮退,匹配似月明
(?=)前瞻如鹰望,(?<=)后顾似舟痕。
|分岔择一道,[...]方寸藏玄机。莫惧回溯深如渊,但信模式定乾坤

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 36
36 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)