开源RAG引擎RAGFlow
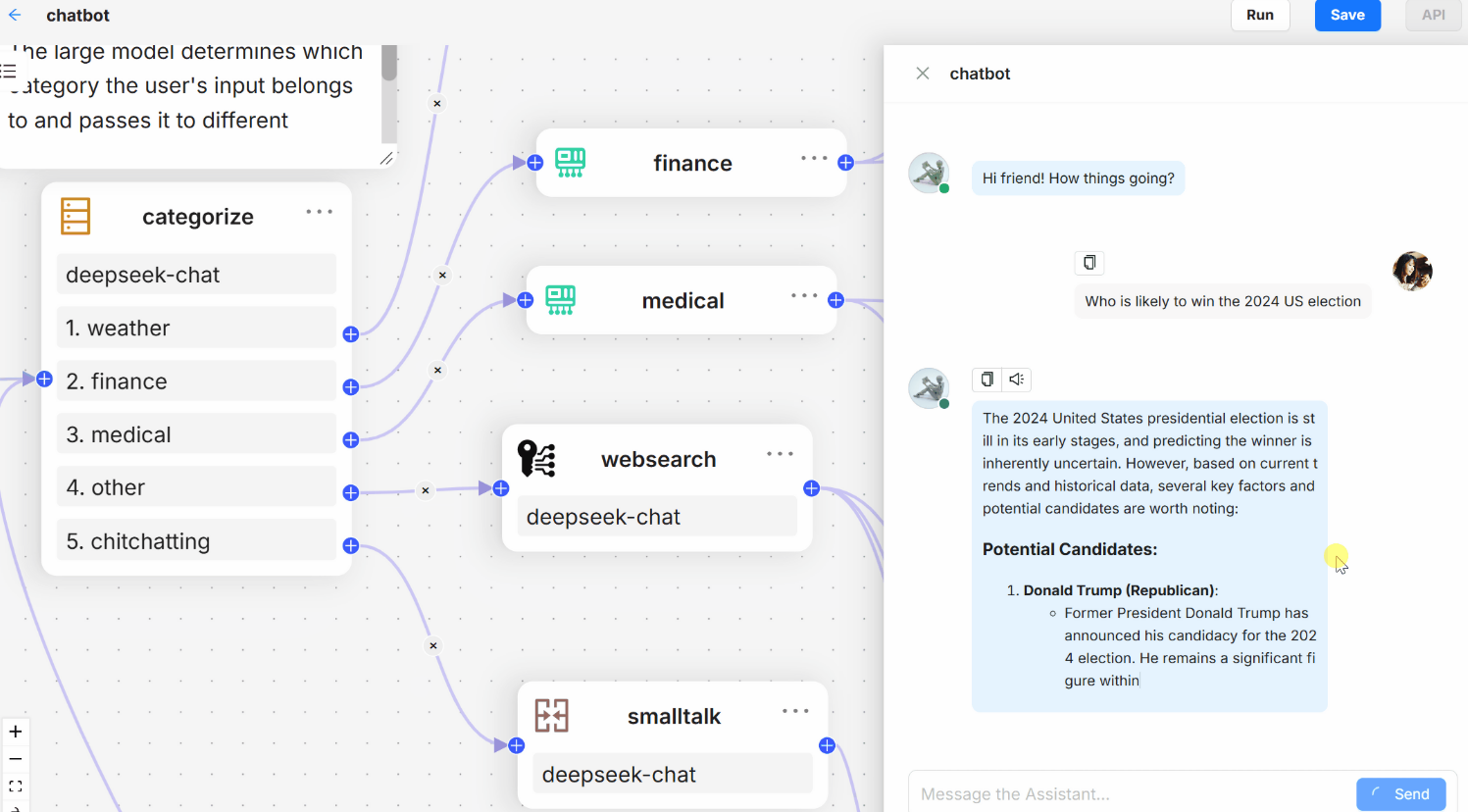
数据预处理层:负责文档解析、分块和向量化,包含格式识别、OCR、表格重建等专用模块。检索增强层:实现混合检索策略,协调向量数据库、全文搜索引擎和知识图谱的查询与结果融合。生成与交互层:集成LLM生成能力,提供API和Web界面,处理用户查询并返回带引用的答案。RAGFlow作为新一代开源RAG引擎,通过深度文档理解和模块化设计,显著降低了构建知识密集型AI应用的门槛。开箱即用的体验:从文档上传到智
RAGFlow是一款基于检索增强生成(Retrieval-Augmented Generation,RAG)技术的开源框架,专注于通过深度文档理解技术处理复杂格式的非结构化数据,为企业及开发者提供高效、准确的文本处理和问答功能。作为端到端的RAG解决方案,RAGFlow显著简化了知识密集型AI应用的开发流程,将智能检索与文本生成无缝结合,同时确保结果的可追溯性和可解释性。以下将从核心特性、技术架构、部署使用、应用场景等多个维度全面介绍这一创新工具。
一、RAGFlow的核心特性与技术创新
RAGFlow区别于传统RAG方案的核心价值在于其深度文档理解能力和高度自动化的工作流,解决了传统方案中数据处理粗糙、检索效率低下、生成结果不可控等痛点问题。
1. 深度文档理解与多格式兼容
RAGFlow支持解析包括PDF、Word、Excel、PPT、图片、扫描件、网页等在内的多种复杂格式非结构化数据,并能精准提取文本、表格、图片等元素,保留文档原始结构信息(如标题、段落、换行符等)。其创新之处在于:
-
智能表格处理:不仅能识别文档中的表格存在,还会分析表格布局,处理多行文字合并等复杂情况,确保表格数据以合理形式存储和检索。例如,会计凭证中的跨行数字能够被正确识别和关联。
-
OCR集成:通过结合光学字符识别技术,RAGFlow可以处理扫描件和影印文档,极大扩展了数据源的适用范围,使得纸质文档数字化后也能纳入知识体系。
-
多模态支持:除了纯文本,系统还能处理图文混合内容,识别图片中的文字和图表信息,为真正的多模态问答奠定基础。
2. 智能化分块与混合检索策略
传统RAG系统常因简单粗暴的文本分块导致语义割裂,而RAGFlow通过以下创新解决了这一问题:
-
模板化分块处理:提供多种分块策略(如按段落、语义单元、表格优先等),用户可根据文档类型选择最合适的分块方式。例如,法律文书适合按条款分块,学术论文则适合按章节分块。
-
可视化调整界面:分块结果可通过可视化界面人工校验和调整,提升透明度和可控性,避免AI处理导致的语义偏差。
-
混合检索增强:融合向量搜索、全文检索及知识图谱(GraphRAG)技术,显著提高召回率和精确度。知识图谱通过实体关系聚合信息,特别适合解决复杂多跳推理问题。
3. 减少幻觉与可信引用机制
针对LLM"幻觉"问题,RAGFlow实施多重保障:
-
源头追溯:每个生成答案都自动标注引用来源,支持点击查看原始文档片段,如同学术论文的参考文献。
-
Self-RAG技术:模型在生成过程中会自我评估检索结果的合理性,动态调整生成策略,进一步减少无依据的"编造"。
-
答案验证:关键数据回答时可自动对比多个来源片段,标记可能存在矛盾的信息,提醒用户注意核实。
4. 动态工作流与模块化设计
RAGFlow的架构设计充分考虑了灵活性和扩展性:
-
插件化组件:允许用户替换向量数据库(Chroma/FAISS/Weaviate)、生成模型(Llama/GPT等)和Embedding模型(如bge-m3),无需修改核心代码。
-
动态决策:系统会根据查询复杂度自动调整检索策略(如分层检索、信息补充),无需人工预设规则。简单问题可能仅需向量检索,而复杂问题会触发多路召回和重排序。
-
多模型支持:可同时配置多个LLM(如GPT-4用于创意生成、Claude用于逻辑推理),根据问题类型智能路由。
表:RAGFlow与传统RAG方案的对比
| 特性 | RAGFlow | 传统RAG方案 |
|---|---|---|
| 开发效率 | 配置文件驱动,1小时完成部署 | 需编码集成多个组件,耗时1天以上 |
| 文档支持 | 自动解析20+种格式,保留结构信息 | 需自行预处理,易丢失表格等复杂结构 |
| 检索能力 | 混合检索(向量+全文+图谱),多路召回 | 通常仅向量检索,召回率有限 |
| 可控性 | 可视化分块调整,人工干预接口 | 黑箱操作,调整需重新训练 |
| 学习曲线 | 低代码,业务人员可上手 | 需技术背景,学习成本高 |
二、技术架构与系统设计
RAGFlow的整体架构遵循模块化设计原则,通过容器化技术实现快速部署,其技术栈和系统组成体现了现代AI系统的典型特征。
1. 分层架构概述
系统采用典型的三层架构设计:
-
数据预处理层:负责文档解析、分块和向量化,包含格式识别、OCR、表格重建等专用模块。
-
检索增强层:实现混合检索策略,协调向量数据库、全文搜索引擎和知识图谱的查询与结果融合。
-
生成与交互层:集成LLM生成能力,提供API和Web界面,处理用户查询并返回带引用的答案。
2. 核心组件详解
-
智能文档处理引擎:基于AI模型识别文档布局和结构,特别是对复杂PDF的处理能力远超常规工具。例如,能识别财务报表中的跨页表格并正确关联数据。
-
多路召回系统:并行执行多种检索方式,包括:
- 密集检索:基于最新Embedding模型(如bge-m3)
- 稀疏检索:BM25等传统算法
- 知识图谱查询:处理实体关系类问题
-
融合排序模块:采用学习排序(LTR)技术,综合考虑语义相关性、来源权威性和时效性等因素。
-
可插拔模型池:预集成主流LLM(GPT、Gemini、智谱AI等)和Embedding模型,支持热切换而无须重启服务。
3. 关键技术亮点
-
RAPTOR技术:实现文本的层次化摘要,构建树状结构索引,显著优化长文档多步推理场景的检索效率。
-
流式处理:支持大规模文档的增量索引,避免全量重建的资源消耗。
-
微服务架构:各组件通过gRPC通信,可独立扩展。例如,检索服务可横向扩展应对高并发。
三、部署与使用指南
RAGFlow通过Docker容器提供开箱即用的体验,极大降低了部署门槛,使企业能够快速构建基于私有知识的智能问答系统。
1. 硬件与软件要求
最低配置:
- CPU:4核(建议8核以上)
- 内存:16GB(建议32GB以上)
- 磁盘:50GB可用空间(建议SSD)
- Docker 24.0.0+ & Docker Compose v2.26.1+
关键系统配置:
# 调整内核参数
sudo sysctl -w vm.max_map_count=262144
echo "vm.max_map_count=262144" >> /etc/sysctl.conf # 永久生效
2. 快速部署步骤
-
获取代码:
git clone https://github.com/infiniflow/ragflow.git cd ragflow/docker -
启动服务(国内用户可使用阿里云镜像加速):
sed -i 's/infiniflow\/ragflow/registry.cn-hangzhou.aliyuncs.com\/infiniflow\/ragflow/g' .env docker compose -f docker-compose-CN.yml up -d -
验证部署:
docker logs -f ragflow-server # 看到Web服务端口提示即成功 -
访问系统:
- 浏览器打开
http://服务器IP:80 - 首次使用需在Web界面配置LLM和Embedding模型的API密钥
- 浏览器打开
3. 核心配置详解
系统通过三个主要文件管理配置:
-
.env:定义基础环境变量,如服务端口、数据库密码等
SVR_HTTP_PORT=80 MYSQL_PASSWORD=your_strong_password MINIO_PASSWORD=your_strong_password -
service_conf.yaml:配置后端服务参数,关键项包括:
user_default_llm: "OpenAI" # 或"ZhipuAI"、"Ollama"等 API_KEY: "sk-xxx" # 对应模型的API密钥 embedding_model: "bge-m3" # Embedding模型选择 -
docker-compose-CN.yml:定义服务依赖和资源限制,可调整CPU/内存分配
4. 典型使用流程
-
创建知识库:
- 上传文档(支持批量拖拽)
- 选择分块模板(如"通用"、“表格优先”)
- 设置块大小(默认128 tokens)和重叠区域
-
检索测试:
- 使用"Retrieval Testing"功能验证分块效果
- 根据结果调整分块策略或尝试不同Embedding模型
-
构建问答助手:
- 关联知识库和生成模型
- 配置生成参数(温度值、最大生成长度等)
- 设置引用显示方式(内联标注或底部列表)
-
API集成:
from ragflow import Pipeline pipeline = Pipeline( documents=["manual.pdf"], vector_db="chroma", model="gpt-4" ) answer = pipeline.query("如何申请休假?") print(answer.text, answer.sources) # 答案及来源企业系统可通过RESTful API与之集成
四、应用场景与典型案例
RAGFlow的深度文档理解能力和灵活架构,使其在多个专业领域展现出独特价值,以下为典型应用场景及实施效果。
1. 企业知识管理与智能客服
- 场景特点:企业通常有大量规章制度、产品手册等内部文档,传统搜索工具难以满足自然语言查询需求。
- RAGFlow方案:
- 一键上传HR手册、产品规格书等各类文档
- 员工通过自然语言提问,如"年假如何计算?"
- 系统返回基于具体条款的精准答案,并标注出处
- 实施效果:
- 某广电企业将专业问题解答准确率从70%提升至95%以上
- 员工培训成本降低40%,客服响应速度提升3倍
2. 法律与医疗专业咨询
- 场景特点:对答案准确性要求极高,必须能够追溯法律条文或临床指南原文。
- RAGFlow方案:
- 加载法律法规数据库或医疗指南
- 启用"Law"专用处理模板,保留条款编号等关键元数据
- 生成答案时强制附带原文引用
- 典型案例:
- 法律事务所用于快速查询相似判例,回答时自动标注"依据XX法第X条"
- 医院临床支持系统引用最新治疗指南回答药物相互作用查询
3. 学术研究与文献分析
- 场景特点:需要从海量论文中提取关键发现,理解复杂学术概念。
- RAGFlow方案:
- 使用"Paper"模板处理学术PDF,识别摘要、方法、结论等章节
- 构建领域知识图谱,连接相关概念
- 支持"比较A和B方法在C指标上的差异"等复杂查询
- 用户价值:
- 研究人员文献调研时间缩短60%
- 自动生成带引用的文献综述初稿
4. 技术文档智能助手
- 场景特点:开发文档更新频繁,API参考查询需求量大。
- RAGFlow方案:
- 同步GitHub文档仓库,自动增量更新索引
- 开发者提问"如何使用XX接口实现YY功能?"
- 返回最新版本文档片段及代码示例
- 实施案例:
- 某开源项目将文档查询解决率从45%提升至82%
- 结合代码检索,可直接定位相关函数实现
表:RAGFlow行业应用效果对比
| 行业 | 典型问题类型 | 准确率提升 | 响应时间 |
|---|---|---|---|
| 金融 | 合规条款查询、财报分析 | 70% → 92% | <2秒 |
| 医疗 | 药物相互作用、诊疗指南 | 65% → 89% | <3秒 |
| 制造业 | 设备故障处理、操作规程 | 60% → 85% | <1.5秒 |
| 教育 | 教材内容问答、题目解析 | 75% → 90% | <1秒 |
五、社区生态与发展路线
作为开源项目,RAGFlow拥有活跃的开发者社区和清晰的演进路线,持续吸收行业需求推动技术迭代。
1. 社区支持与贡献
-
协作平台:
- GitHub:主仓库接收功能需求和Bug报告
- Discord:实时技术交流社区
- Twitter:发布最新动态
-
贡献方式:
- 文档翻译:完善多语言使用指南
- 适配器开发:新增对更多LLM或数据库的支持
- 行业模板:贡献特定领域(如财务、法律)的文档处理模板
2. 版本演进与路线图
根据官方披露,RAGFlow的未来发展聚焦于:
-
2024 Q3:
- 增强多模态能力(图片、图表深度理解)
- 优化分布式索引性能,支持十亿级文档
-
2024 Q4:
- 内置Agent框架,支持多步骤工具调用
- 增强SQL生成能力,实现自然语言到数据库查询
-
2025规划:
- 实时流数据处理支持
- 个性化检索(基于用户历史行为优化结果)
3. 相关开源项目
RAGFlow与同团队其他项目形成完整生态:
- Infinity:AI原生数据库,提供高性能向量检索和结构化数据联合查询
- DeepDoc:深度文档理解库,支持复杂格式解析
- Xinference:本地化大模型部署框架,可与RAGFlow集成
六、总结与选型建议
RAGFlow作为新一代开源RAG引擎,通过深度文档理解和模块化设计,显著降低了构建知识密集型AI应用的门槛。其核心优势体现在:
-
开箱即用的体验:从文档上传到智能问答,全流程自动化,业务人员无需编码即可构建知识系统。
-
企业级可靠性:支持复杂格式处理、答案溯源和混合检索,满足专业场景的严苛要求。
-
灵活的扩展性:可替换各环节组件,适应不同技术栈和业务需求。
对于企业用户,建议从具体业务场景(如客服、培训)入手,利用现有文档快速验证价值;对于开发者,可基于API深度定制,将其作为AI能力中间件集成到现有系统。随着长上下文LLM的普及,RAGFlow的独特价值将更多体现在处理超大规模、多模态专业知识的场景中,成为组织知识管理的核心基础设施。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 12
12 0
0- 0



 已为社区贡献35条内容
已为社区贡献35条内容

所有评论(0)