DeepSeek-R1复现方案梳理
在 100 步时,解方程的成功率约为 25%,并且模型开始用文字进行 “推理”;近日,来自UC伯克利的研究团队基于Deepseek-R1-Distilled-Qwen-1.5B,通过简单的强化学习(RL)微调,得到了全新的DeepScaleR-1.5B-Preview。由huggingface组建,目前刚上线2周,发布了最新进展open-r1/update-1,在MATH-500任务上接近deep
中科院计算所网数实验室DeepResearch团队,指导老师郭嘉丰
DeepResearch-R1
- 公开推理数据集收集
- DeepSeek-R1复现方案梳理
面向DeepResearch的强化学习训练方案
DeepRetrieval
论文题目:DeepRetrieval: Hacking Real Search Engines and Retrievers with Large Language Models via Reinforcement Learning
论文链接:https://arxiv.org/abs/2503.00223
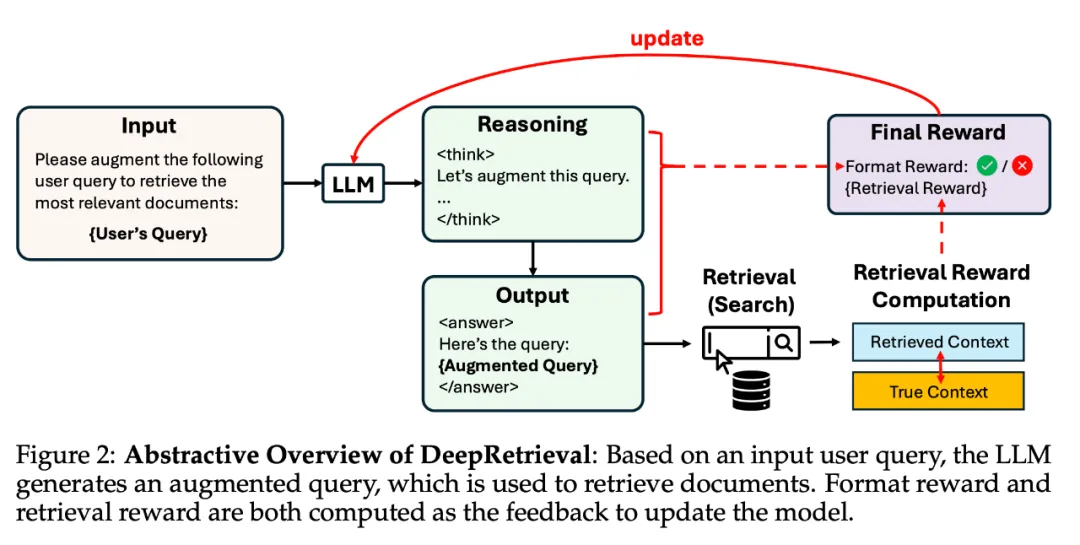
强化学习在多种检索任务中的通用有效性展示
论文中值得称赞的是,在五种不同的检索任务中展示了强化学习方法在查询改写中的有效性。这些任务分别涉及不同的查询格式和奖励结构,具体如下:
1. Literature Searching(文献检索)
- 定义:给定一个查询,从搜索引擎中检索相关文档。
- 评估指标:Recall@K(在前K个结果中检索到的目标文档的百分比)
- Query形态:采用医学专用的PICO检索语法
- 示例:
"((达姆明) AND (围手术期 OR 血液转输 OR 去氨加压素 OR 抗凝剂)) AND (随机对照试验)" - 特点:包含布尔运算符和专业术语,结构严谨。
- 示例:
2. Evidence-Seeking Retrieval(证据寻找检索)
- 定义:给定一个问题,检索包含匹配答案候选项的文档。
- 评估指标:H@N(第一个出现答案的文档排名是否在前N位)
- Query形态:类似自然语言
- 示例:
"What is another term for the pivot mounting?"
- 示例:
3. Classic Sparse Document Retrieval(经典稀疏文档检索)
- 定义:使用关键词匹配和布尔操作进行文档检索(如BM25算法)。
- 评估指标:NDCG(归一化折扣累积增益,衡量排序质量)
- Query形态:关键词与布尔表达式的组合
- 示例:
"(李明 IS-A 人物 AND 李明 IS-A 在职) OR (李明 IS-A 人物 AND 李明 IS-A 失业)"
- 示例:
4. Classic Dense Document Retrieval(经典密集文档检索)
- 定义:使用查询和文档的语义向量表示进行检索。
- 评估指标:NDCG
- Query形态:自然语言表述
- 示例:
"量子计算的基本原理是什么?" - 系统会将查询转换为语义向量,通过语义相似度检索相关文档。
- 示例:
5. SQL Database Search(SQL数据库检索)
- 定义:根据自然语言查询生成SQL语句来检索数据库中的信息。
- 评估指标:执行准确率(检索结果与目标答案的匹配程度)
- Query形态:SQL语句
- 示例:
"SELECT 书名 FROM 图书表 WHERE 类型 != '诗歌'"
- 示例:
方法要点
方法要点
输入:原始查询 q
输出:改写后的查询 q′(自然语言、布尔表达式或 SQL)
环境反馈:使用 q′ 去检索系统中查询 → 返回结果 → 与 groundtruth 对比,计算 reward,reward 为 task-specific 检索表现(如 Recall@K、NDCG@K、SQL accuracy)
使用 PPO 进行训练,并加入格式奖励(format correctness)与 KL-regularization 保证训练稳定,优化目标如下:
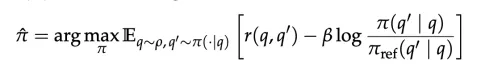
其中,π_ref 是参考策略(reference policy),通常指的是在强化学习开始之前的初始模型。β 是一个合适的 KL 惩罚系数,用于控制正则化的强度。KL 散度项的作用是惩罚当前策略与参考策略之间的过大偏离,从而在强化学习训练过程中保证策略更新的稳定性。
DeepResearcher
论文题目:DeepResearcher: Scaling Deep Research via Reinforcement Learning in Real-world Environments
论文地址:https://github.com/GAIR-NLP/DeepResearcher/blob/main/resources/DeepResearcher.pdf
发布日期:2025年4月4日
研究动机
随着大型语言模型(LLMs)推理能力的飞速发展,OpenAI、Google 和 XAI 等科技巨头纷纷推出了备受欢迎的 Deep Research 产品。这些工具能帮助用户整合海量网络信息,解决复杂问题,大大提升研究效率。
但现有系统存在两大痛点:一方面,商业产品如 OpenAI 的 Deep Research 完全是 “黑盒”,其技术细节不对外公开;另一方面,开源项目往往依赖人工设计的工作流程,导致行为僵化、泛化能力差,在复杂研究场景中表现脆弱。
DeepResearcher简介
DeepResearcher 通过强化学习扩展(RL scaling)在真实网络环境中训练,自发形成了令人惊叹的研究能力。以图中所示的例子为证:在回答问题时,DeepResearcher 不只是简单搜索信息,而是展现出人类才有的复杂行为模式 —— 自主规划研究步骤、动态调整搜索策略、交叉验证不同来源的信息。
特别值得注意的是,当面对 “谁是电影先驱” 这类开放性问题时,DeepResearcher 不会盲目接受首次搜索结果,而是主动开展第二轮更精确的搜索以验证信息准确性,确保最终答案的可靠性。这种自发形成的交叉验证行为,是 AI 真正理解 “研究” 本质的体现!

DeepResearcher 训练架构
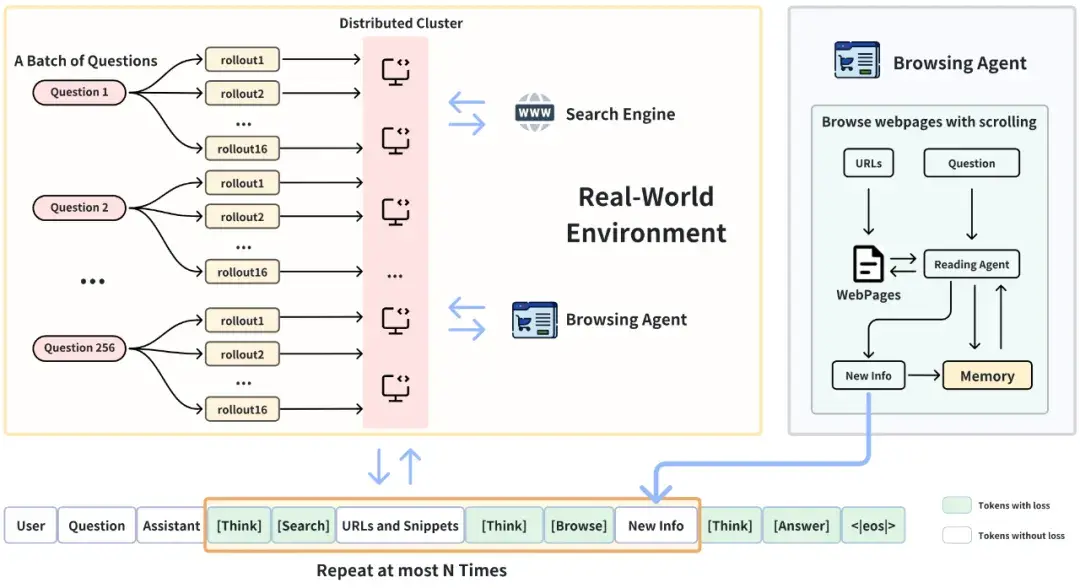
DeepResearcher 的深度研究轨迹
在 DeepResearcher 的推理轨迹中,智能体会根据用户问题和观测结果进行迭代推理与工具选择,在动态的真实世界环境中通过网页搜索解决问题。
-
推理(Reasoning)
DeepResearcher 在执行具体动作之前必须先进行推理。每次推理过程都被封装在<think>标签内,遵循 DeepSeek-R1 的设定。 -
网页搜索工具(Web Search Tool)
DeepResearcher 通过生成 JSON 格式的请求来调用网页搜索工具。搜索结果以结构化格式返回,每条结果包含标题(title)、URL 和摘要(snippet)。当前实现使用固定的 top-k(如 10)作为搜索结果的检索参数。未来工作可以探索基于 LLM 的动态参数优化以提升搜索效率。 -
网页浏览智能体(Web Browsing Agent)
网页浏览智能体为 DeepResearcher 系统提供可靠、与问题相关、且可增量更新的信息。具体操作流程如下:- 对每个查询维护一个短期记忆库;
- 收到网页浏览请求后,首先处理 URL 的第一页内容;
- 基于查询、历史记忆和新获取的网页内容,执行以下判断:
- 是否继续读取下一个 URL / 页面片段;
- 是否停止浏览;
- 将相关信息追加到短期记忆库;
- 当智能体决定停止浏览时,整理短期记忆库中的新增信息并返回给 DeepResearcher 系统。
-
回答生成(Answering)
当模型判断已获取足够信息后,它会生成最终答案,并将其封装在<answer></answer>标签内返回给用户。
训练方法
该项目采用强化学习(Reinforcement Learning, RL)训练智能体。本节概述了具体如何利用 RL 框架进行训练,以及在其中使用的具体算法和工具。
GRPO 算法
研究团队采用群体相对策略优化(Group Relative Policy Optimization, GRPO)算法。GRPO 通过参考策略与当前策略生成的一组 rollout 来优化当前策略。具体流程如下:
- 给定 G 个 rollout,其中每个输入 x 服从经验分布 D(即 x∼D);
- GRPO 使用这些轨迹来估计基准(baseline),无需单独训练评论模型(critic);
- 通过最大化以下目标函数来优化当前策略(公式略)。
观察掩码(Masking Observations)
工具的输出是一个观察结果,而不是期望模型产生的输出。因此,训练过程中采用掩码方法,防止工具输出参与训练,仅允许模型的响应影响训练。
奖励函数
使用 F1 分数作为主要奖励函数,并对格式错误的回复进行惩罚。
- 格式惩罚(Format Penalty):若答案格式不正确(如缺少标签或结构错误),智能体将受到 -1 的惩罚。
- F1 奖励(F1 Reward):若答案格式正确,奖励将基于词级别 F1 分数进行评估,该指标衡量生成答案与参考答案的准确性。F1 分数越高,奖励越高。

R1-Searcher
论文标题:R1-Searcher: Incentivizing the Search Capability in LLMsvia Reinforcement Learning
代码开源: https://github.com/SsmallSong/R1-Searcher
把模型思考+RAG通过强化学习结合到一起,让答案更准确。基础模型使用的qwen & llama。

简单来说就是,希望模型输出这样的格式,通过输出特殊token,触发搜索,然后再把检索到的内容拼接进去,继续生成。当然这个过程可以进行多次。
<think>
xxx
xxx
<begin_of_query>检索查询关键词<end_of_query>
<begin_of_documents>检索到的文档内容<end_of_documents>
xxxx
</think>
<answer>最终答案</answer>
2阶段训练,第一阶段主要是奖励格式,相对而言,这个格式改动比较大,所以单独设计了一个阶段来训练?让模型快速学会怎么使用检索模块。
第一阶段用到了一些中等难度的数据(低于20次推理的数据),不奖励答案正确性,只看格式奖励和召回标记触发次数来奖励,如下图,2个奖励求和。

第二阶段用格式奖励+正确答案是否正确的奖励,如下图,2个奖励求和。

评估预测answer和正确answer是否匹配,2个测录,一个是规则判断是否包含,一个是用大模型判断。

Search-R1
论文题目:Search-R1: Training LLMs to Reason and Leverage Search
Engines with Reinforcement Learning
项目地址:https://github.com/PeterGriffinJin/Search-R1
背景和动机
-
发表时间:2025 年 3 月(arxiv 预印版)
-
研究问题:如何使 LLM 更有效地利用外部知识进行复杂推理和问答。
-
背景:
- 现有 LLM 在需要外部知识的多轮复杂推理任务中存在两个关键缺陷:
传统 RAG 方法难以进行动态的多轮检索(如回答 " 特斯拉上海工厂年产量 " 需要先检索工厂地址,再查当地政策); - 基于提示的工具调用方法依赖预训练知识,无法学习最优搜索策略
- 现有 LLM 在需要外部知识的多轮复杂推理任务中存在两个关键缺陷:
-
研究契机:2025 年 DeepSeek-R1 证明纯强化学习可以培养 LLM 的自我验证能力,但未结合外部检索。本文提出将强化学习框架扩展到检索增强场景。
核心思路
核心思想: 将搜索引擎建模为强化学习环境的一部分,使 LLM 能通过试错自主学习:
- 搜索即环境交互:将搜索 API 调用转化为马尔可夫决策过程的状态转移
- 结构化文本生成:通过特殊标记实现程序化控制
- 轻量化奖励设计:仅用最终答案正确性作为奖励信号,避免复杂过程监督
灵感来源:
- DeepSeek-R1 通过强化学习提升 LLM 的推理能力,但未涉及搜索引擎的集成。
- 现有的 RAG 和工具使用方法在灵活性和可扩展性方面存在局限性。
SEARCH-R1 框架说明
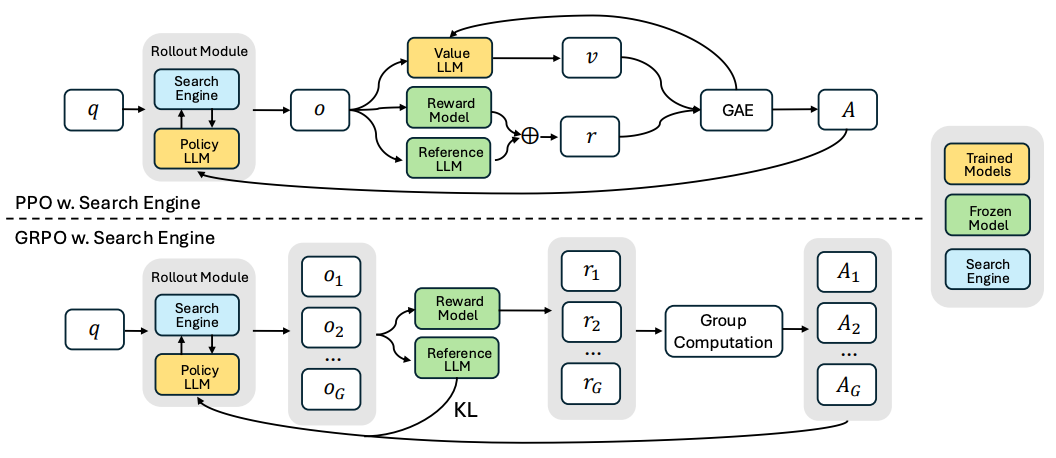
框架简介
SEARCH-R1 是一种将搜索引擎整合为语言模型环境组成部分的强化学习训练框架。其核心理念是允许语言模型(LLM)在生成 token 的同时主动进行信息检索,以提升模型在多轮推理任务中的表现。
核心机制
- 搜索与推理结合:通过特殊标记符引导模型的行为:
<search>与</search>:触发并标识检索动作。<information>与</information>:包含检索到的内容。<think>与</think>:包含模型的推理步骤。<answer>与</answer>:包含模型的最终回答。
- 多轮交互能力:模型可多次进行检索和推理,逐步构建答案。
- 奖励函数设计:采用基于结果的奖励函数,避免繁琐的中间过程标注,使强化学习更高效。
强化学习算法支持
- 算法兼容性强:
- 支持多种主流强化学习算法,如 PPO(Proximal Policy Optimization)和 GRPO(Generalized Reward Policy Optimization)。
- 稳定性增强机制:
- 引入retrieved token masking(检索 token 掩码):仅对语言模型生成的 token 计算训练损失,排除由搜索返回的文本,从而提升训练稳定性和效果。
训练模板
- 模板设计简洁清晰:
- 明确结构包含三部分:推理、搜索、答案,便于模型理解任务结构。
- 避免内容偏见:
- 模板设计不引入具体内容偏好,确保模型在强化学习过程中能自主学习策略和知识获取方法。
ReSearch
论文地址:https://arxiv.org/abs/2503.19470
项目地址:https://github.com/Agent-RL/ReSearch
ReSearch框架:通过强化学习推理搜索的LLM框架
研究动机
近年来,LLM在各种任务中表现得越来越出色,比如回答问题、生成文本等。然而,当问题变得复杂,需要多步推理和外部信息检索时,传统的LLM就显得有些力不从心了。例如,回答“谁是花旗银行成立那年的美国总统?”这样的问题,模型需要先找到花旗银行的成立年份,再查找那年的美国总统。这种多步推理和检索的需求,正是ReSearch试图解决的难题。
现有的方法大多是基于手动设计的提示词(prompt)或启发式规则,但这些方法不仅费时费力,还难以扩展到更复杂的问题。而ReSearch通过强化学习,直接让模型在没有监督数据的情况下学会如何结合搜索进行推理,这无疑是一个非常有前景的方向
ReSearch核心思想:结合推理与搜索
ReSearch 框架的核心在于将搜索操作视为推理链(Chain-of-Thought)的一部分。模型在推理过程中生成包含“思考过程”和“搜索查询”的文本链,搜索结果作为反馈,进一步影响后续的推理。
🌐 1. 思考与搜索的交互过程
模型在推理时会交替进行思考、发起搜索,并根据搜索结果继续推理。格式上采用特定标签标注不同环节。
<think>我需要先找到花旗银行的成立年份。</think>
<search>花旗银行成立年份</search>
<result>花旗银行成立于1812年。</result>
<think>现在我需要查找1812年的美国总统。</think>
<search>1812年美国总统</search>
<result>1812年的美国总统是詹姆斯·麦迪逊。</result>
<answer>答案是\boxed{James Madison}。</answer>
这种方式体现了模型与外部搜索引擎的迭代交互:
<think>标签用于记录模型当前的思考。<search>标签发起搜索查询。<result>标签反馈搜索结果。<answer>标签最终给出答案。
🧠 2. 强化学习训练机制
ReSearch 框架使用强化学习方式训练模型,使其在推理过程中学会:
- 何时搜索:判断是否有必要发起搜索。
- 如何搜索:生成高效且相关的搜索查询。
- 如何使用搜索结果:将检索信息整合入推理链中。
训练过程中,模型通过尝试多种推理路径,并根据最终答案的正确性奖励信号进行优化,逐步找到最优策略。
ReSearch 的训练方法概述
ReSearch 的训练基于一种名为 Group Relative Policy Optimization (GRPO) 的强化学习算法。该方法通过采样多个推理链(rollouts),优化模型生成更高奖励的推理链,从而提高推理能力和检索整合能力。
搜索操作的集成
ReSearch 模型能够在推理过程中主动调用搜索工具,其机制如下:
- 搜索操作由特殊标签控制,例如:
<search>表示发起搜索查询;<result>表示插入检索结果;</search>触发系统执行搜索并插入结果。
示例:
<think>推理内容1</think>
<search>搜索查询内容</search>
<result>搜索结果内容</result>
<think>推理内容2</think>
<answer>最终答案是 \boxed{结果}</answer>
奖励建模
ReSearch 的奖励函数由 答案奖励(Answer Reward) 和 格式奖励(Format Reward) 两部分组成。公式如下:
r =
{
f1(apred, agt), if f1 score > 0
0.1, if f1 score == 0 and format is correct
0, if f1 score == 0 and format is incorrect
}
说明:
f1(apred, agt):预测答案与参考答案的 F1 分数;- 若 F1 分数为 0:
- 若格式正确(如用
\boxed{}包裹),则奖励为 0.1; - 若格式错误,则无奖励。
- 若格式正确(如用
GRPO 训练流程图示
(请参考图示部分:包括 (a) GRPO 训练流程 和 (b) 推理链生成过程)
该流程使模型逐步学会如何有效地嵌入并利用搜索操作进行复杂推理。
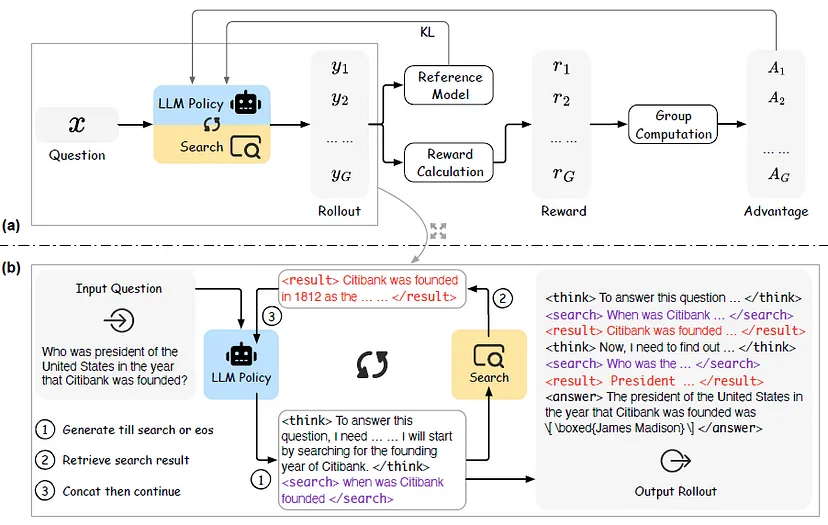
检索结果屏蔽机制
为防止模型对搜索结果产生过度依赖,训练阶段会 屏蔽搜索结果的内容,只优化模型的思考路径和查询构造能力。
提示词模板设计
ReSearch 采用两类提示词模板以适配不同类型的模型:
- 基础模型的提示词模板
A conversation between User and Assistant. The user asks a question, and the assistant solves
it. The assistant first thinks about the reasoning process in the mind and then provides the
user with the answer. During thinking, the assistant can invoke the wikipedia search tool
to search for fact information about specific topics if needed. The reasoning process and
answer are enclosed within <think></think> and <answer></answer> tags respectively,
and the search query and result are enclosed within <search></search> and <result>
</result> tags respectively. For example, <think> This is the reasoning process. </think>
<search> search query here </search><result> search result here </result><think>
This is the reasoning process. </think><answer> The final answer is \boxed{answer here}
</answer>. In the last part of the answer, the final exact answer is enclosed within \boxed{}
with latex format. User: prompt. Assistant:
指令微调模型的系统提示词模板
You are a helpful assistant that can solve the given question step by step with the help of the
wikipedia search tool. Given a question, you need to first think about the reasoning process in
the mind and then provide the answer. During thinking, you can invoke the wikipedia search
tool to search for fact information about specific topics if needed. The reasoning process and
answer are enclosed within <think></think> and <answer></answer> tags respectively,
and the search query and result are enclosed within <search></search> and <result>
</result> tags respectively. For example, <think> This is the reasoning process. </think>
<search> search query here </search><result> search result here </result><think>
This is the reasoning process. </think><answer> The final answer is \boxed{answer here}
</answer>. In the last part of the answer, the final exact answer is enclosed within \boxed{}
with latex format.
Agent-R1
项目地址:https://github.com/0russwest0/Agent-R1
Agent-R1是由中科大认知智能全国重点实验室开发的智能体强化学习训练框架,致力于推进强化学习与智能体技术的融合发展。框架采用端到端强化学习方法,突破了依赖人工设计工作流的传统智能体开发瓶颈,让AI直接从与环境的交互中学习最优策略,实现自主决策与行动。开发者只需定义特定领域的工具和奖励函数,即可将Agent-R1扩展到各种应用场景,无需编写复杂的工作流程。
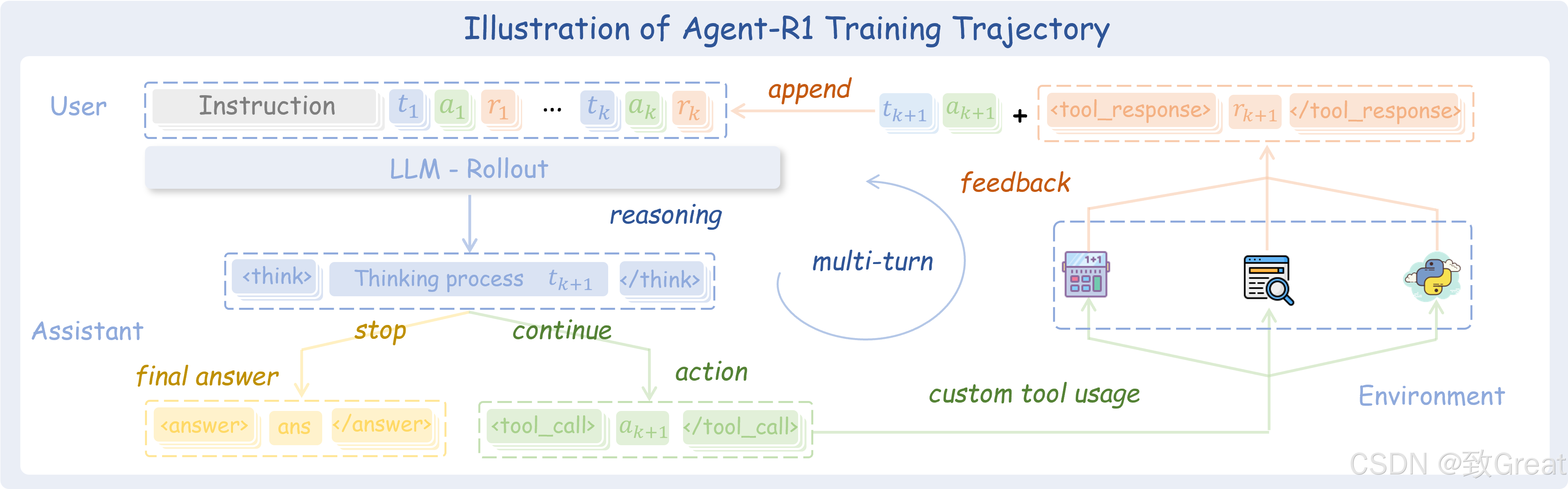
多轮工具调用能力
Agent-R1采用端到端强化学习方法,训练智能体从完整交互轨迹中学习。这使模型能够进行连续多轮工具调用,理解长期因果关系,将当前行动与未来结果关联起来,形成真正的规划和迭代能力。
多工具协调机制
框架支持智能体学习如何协调使用多种工具共同解决复杂任务。智能体能够灵活选择最适合当前情境的工具组合,形成有效的工具组合策略,而非被限制在单一工具的使用模式中。
过程奖励系统
创新的过程奖励机制允许对每个工具调用的有效性进行单独评估,而非仅关注最终结果。通过受PRIME启发的奖励归一化技术,我们平衡了过程奖励与结果奖励,确保智能体在追求最终目标的同时也注重解决问题的过程质量。
自定义工具和环境
框架与主流LLM工具调用格式完全兼容,开发者可以轻松扩展自己的工具和应用场景。只需定义特定领域的工具和奖励函数,即可将Agent-R1应用到任何专业领域,无需复杂的工作流设计。
多种强化学习算法
Agent-R1 支持多种先进的强化学习算法,包括PPO、GRPO和REINFORCE++,为不同需求和场景提供灵活选择。开发者可以根据具体应用选择最适合的算法,优化智能体的学习效果。
多模态支持
最新版本实现了全面的多模态支持,无缝集成视觉-语言模型(VLMs),使智能体能够处理和推理文本与视觉输入的组合。这一功能极大扩展了智能体的应用场景,能够在丰富的多模态环境中进行有效交互。
RAGEN
RAGEN 引入了强化学习框架来训练可以在交互式随机环境中运行的具有推理能力的 LLM 代理。
RAGEN leverages reinforcement learning to train LLM reasoning agents in interactive, stochastic environments.
项目链接:https://github.com/RAGEN-AI/RAGEN
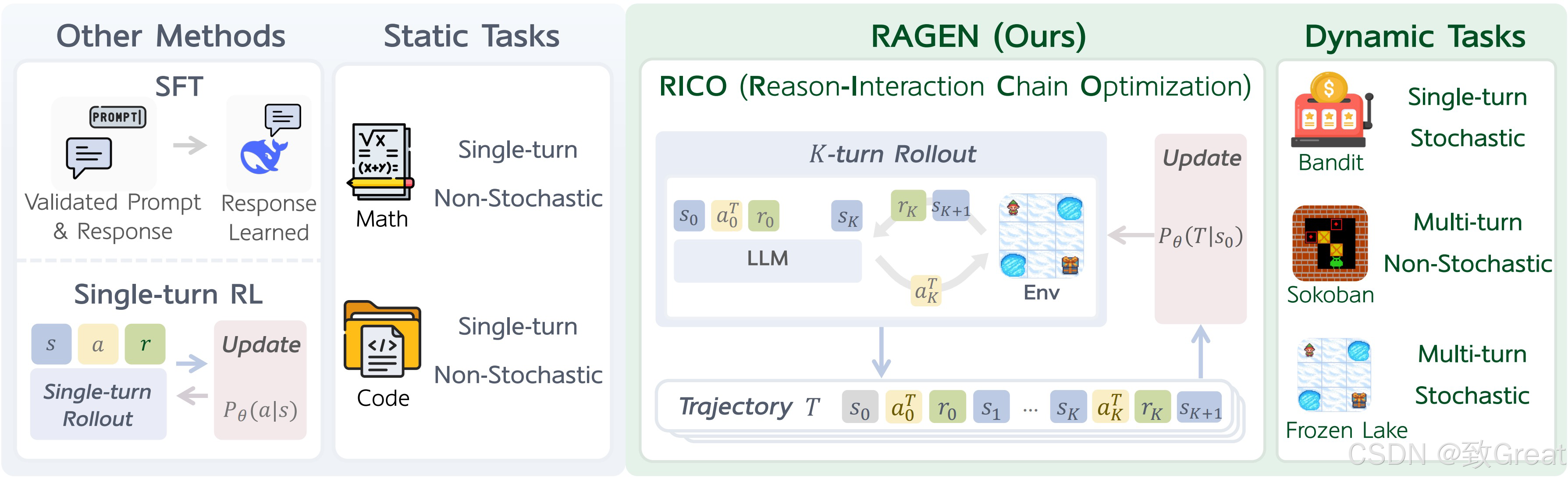
推理交互链优化 (RICO) 框架具有两个交错阶段:推出阶段和更新阶段。LLM 迭代生成推理引导的动作以与环境交互以获得轨迹级奖励,并针对 LLM 更新进行规范化,以共同优化推理和行动策略。
具有基于规则的奖励的强化学习 (RL) 已显示出增强大型语言模型 (LLM) 推理能力的潜力。然而,现有方法主要侧重于数学推理和编码等静态、单轮任务。将这些方法扩展到代理场景会带来两个基本挑战:
- 多轮交互:代理必须执行顺序决策并对环境反馈做出反应
- 随机环境:不确定性,相同的行为可能导致不同的结果
RAGEN 通过以下方式应对这些挑战:
- 代理任务的马尔可夫决策过程 (MDP) 公式
- 优化整个轨迹分布的推理交互链优化 (RICO) 算法
- 渐进式奖励规范化策略可处理多样化、复杂的环境
RAGEN 引入了强化学习框架来训练具有推理能力的 LLM 代理,这些代理可以在交互式随机环境中运行。该框架由两个关键组件组成:
> MDP 配方
我们将代理与环境的交互表述为马尔可夫决策过程 (MDP),其中状态和动作是标记序列,从而允许 LLM 推理环境动态。在时间 t,状态s_{t}
通过动作a_{t}过渡到下一个状态,同时遵循转换函数。该策略根据轨迹历史生成动作。目标是最大化多个交互回合中的预期累积奖励。
> 推理-交互链优化
RICO 使 LLM 能够在整个轨迹上联合优化推理和行动策略。该算法在两个阶段之间交替进行:
推出阶段:推理-交互链生成
给定初始状态,LLM 会生成多条轨迹。在每一步中,模型都会接收轨迹历史并生成推理引导的动作:… action 。环境接收动作并返回反馈(奖励和下一个状态)。
更新阶段:多转弯轨迹优化
生成轨迹后,我们训练 LLM 来优化预期奖励。RICO 不是采用逐步优化,而是使用重要性抽样来优化整个轨迹。这种方法可以实现长远推理,同时保持计算效率。
> 奖励规范化策略
我们实施了三种渐进式规范化策略来稳定训练:
- ARPO : 直接保留原始奖励
- BRPO:使用批次统计数据对每个训练批次的奖励进行标准化
- GRPO:在提示组内进行规范化,以平衡不同任务难度的学习
DeepSeek-R1复现方案梳理
open-r1
由huggingface组建,目前刚上线2周,发布了最新进展open-r1/update-1,在MATH-500任务上接近deepseek的指标,可以在open-r1/open-r1-eval-leaderboard查看指标的排行榜。
mini-deepseek-r1
用 GRPO 和倒计时游戏复制出一个简单版本的 R1。
在大约 50 步时,模型学会了正确的格式,即…\n…;在 100 步时,解方程的成功率约为 25%,并且模型开始用文字进行 “推理”;在 200 步时,收敛变慢,成功率约为 40%。模型开始学习一种新的“格式”,它通过尝试不同的组合并检查结果来解方程,这种方式类似于编程解决问题的方式;在 450 步时,解方程的成功率为 50%,性能仍然在缓慢提升,并且模型保持了从 200 步开始的新格式。
open-thoughts
该项目目标是策划一个推理数据集来训练最先进的小型推理模型,该模型在数学和代码推理基准上超越DeepSeek-R1-Distill-Qwen-32B和DeepSeek-R1-Distill-Qwen-7B 。

TinyZero
干净、简约、易于访问的 DeepSeek R1-Zero 复制品
TinyZero 是DeepSeek R1 Zero在倒计时和乘法任务中的复刻版。我们以veRL为基础进行构建。通过强化学习,3B 基础 LM 可以自行开发自我验证和搜索能力只需不到 30 美元,就可以亲身体验 Ahah 时刻。
simpleRL-reason
项目地址:https://github.com/hkust-nlp/simpleRL-reason
这是 DeepSeek-R1-Zero 和 DeepSeek-R1 在数据有限的小模型上进行训练的复制品
这个 repo 包含一个简单的强化学习方法,用于提高模型的推理能力。它很简单,因为只使用了基于规则的奖励,该方法与DeepSeek-R1中使用的方法几乎相同,只是代码当前使用的是 PPO 而不是 GRPO。我们已经使用此代码在有限的数据(8K 示例)上训练小型模型(7B),取得了令人惊讶的强劲结果 - 例如,从 Qwen2.5-Math-7B(基础模型)开始,我们直接在其上执行 RL。没有 SFT,没有奖励模型,只有 8K MATH 示例用于验证,结果模型在 AIME 上实现 (pass@1) 33.3%、在 AMC 上实现 62.5%、在 MATH 上实现 77.2%,优于 Qwen2.5-math-7B-instruct,并且可与使用 >50 倍更多数据和更复杂组件的以前基线相媲美。

RAGEN
RAGEN 是 DeepSeek-R1 在 AGENT 训练上的第一个开源复现版。

RAGEN 是用于训练智能体模型的 DeepSeek-R1 (-Zero) 方法的首次复现,主要在gym-sokoban(传统的推箱子游戏)任务上进行训练。
unsloth-Reasoning - GRPO
项目地址:https://docs.unsloth.ai/basics/reasoning-grpo
使用 GRPO(强化学习微调的一部分)通过 Unsloth 训练自己的 DeepSeek-R1 推理模型。

DeepSeek 的 GRPO(组相对策略优化)是一种无需价值函数模型的强化学习技术,能够高效优化响应并降低内存和计算成本。借助 Unsloth,仅需 7GB VRAM 即可在本地训练高达 15B 参数的推理模型(如 Llama 3.1、Phi-4、Mistral 或 Qwen2.5),而此前类似任务需要 2xA100 GPU(160GB VRAM)。GRPO 现已支持 QLoRA 和 LoRA,可将标准模型转化为成熟的推理模型。测试显示,仅训练 Phi-4 100 步,GRPO 模型已能生成思考 token 并给出正确答案,显著优于未使用 GRPO 的模型。
oat-zero
项目地址:https://github.com/sail-sg/oat-zero
DeepSeek-R1-Zero 的轻量级复制品,对自我反思行为进行了深入分析。
DeepSeek-R1-Zero 最鼓舞人心的结果之一是通过纯强化学习 (RL) 实现**“顿悟时刻”**。在顿悟时刻,模型会学习自我反思等新兴技能,这有助于它进行情境搜索来解决复杂的推理问题。
在 R1-Zero 发布后的短短几天内,多个项目在较小规模(例如 1B 到 7B)上独立“复现”了类似 R1-Zero 的训练,并且都观察到了 Aha 时刻,这通常通过模型响应长度的突然增加来衡量。按照他们的设置仔细检查了类似 R1-Zero 的训练过程,并分享了以下发现:
- 在类似 R1-Zero 的训练中,可能不存在顿悟时刻。相反,发现顿悟时刻(例如自我反思模式)出现在第 0 个时期,即基础模型中。
- 从基础模型的反应中发现了肤浅的自我反思(SSR),在这种情况下自我反思并不一定会导致正确的最终答案。
- 通过 RL 仔细研究了类似 R1-Zero 的训练,发现响应长度增加的现象不是由于自我反思的出现,而是 RL 优化精心设计的基于规则的奖励函数的结果。

deepscaler
只用4500美元成本,就能成功复现DeepSeek?就在刚刚,UC伯克利团队只用简单的RL微调,就训出了DeepScaleR-1.5B-Preview,15亿参数模型直接吊打o1-preview,震撼业内。
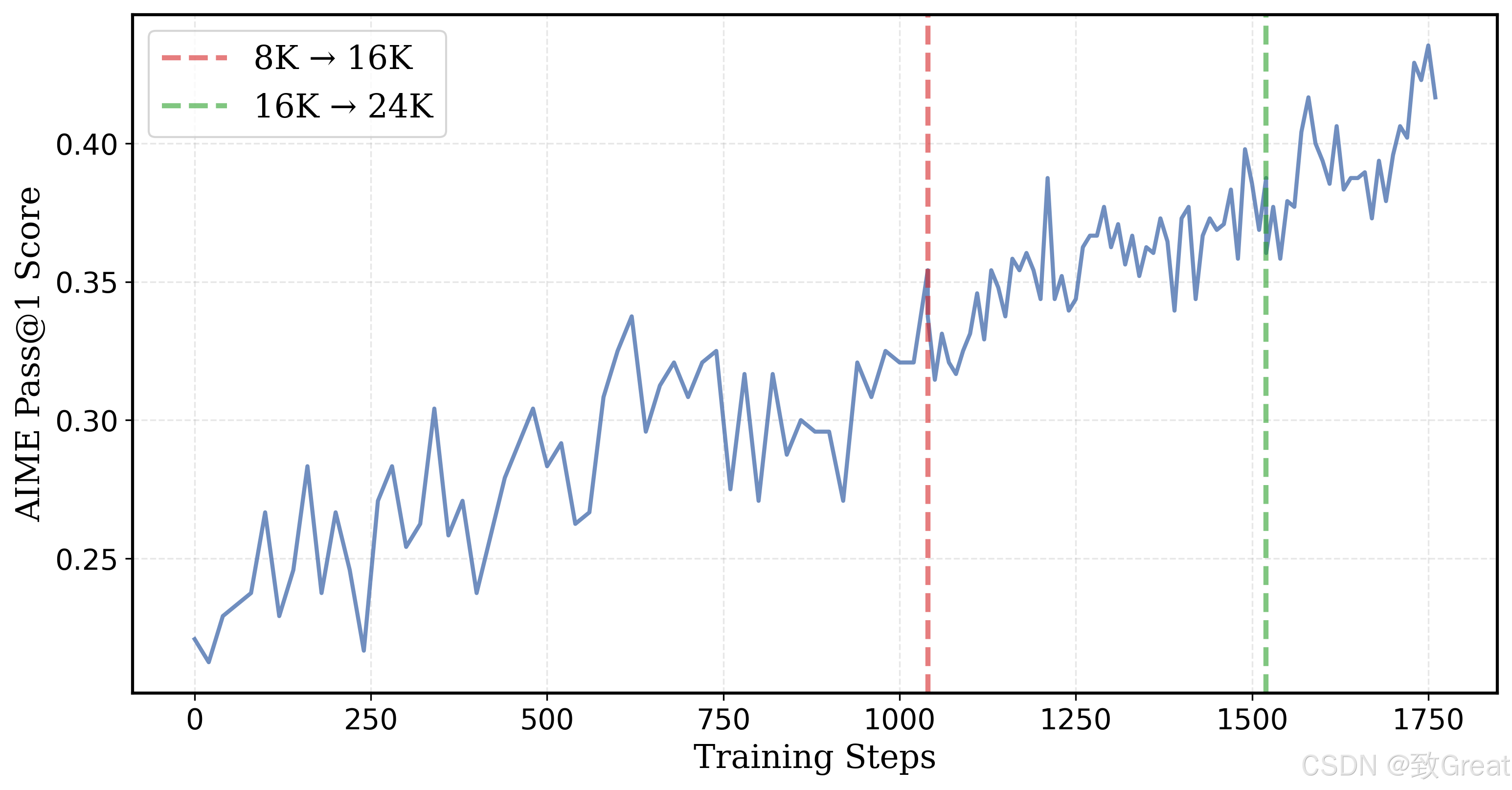
第一步,研究人员会训练模来型进行短思考。他们使用DeepSeek的GRPO方法,设定了8k的上下文长度来训练模型,以鼓励高效思考。
经过1000步训练后,模型的token使用量减少了3倍,并比基础模型提升了5%。接下来,模型被训练进行长思考。强化学习训练扩展到16K和24K token,以解决更具挑战性、以前未解决的问题。随着响应长度增加,平均奖励也随之提高,24K的魔力,就让模型最终超越了o1-preview!

近日,来自UC伯克利的研究团队基于Deepseek-R1-Distilled-Qwen-1.5B,通过简单的强化学习(RL)微调,得到了全新的DeepScaleR-1.5B-Preview。在AIME2024基准中,模型的Pass@1准确率达高达43.1% ——不仅比基础模型提高了14.3%,而且在只有1.5B参数的情况下超越了OpenAI o1-preview!

grpo_demo
项目地址:https://gist.github.com/willccbb/4676755236bb08cab5f4e54a0475d6fb
原始的 grpo_demo.py 帖子
下面直接奉上源码:
# train_grpo.py
import re
import torch
from datasets import load_dataset, Dataset
from transformers import AutoTokenizer, AutoModelForCausalLM
from peft import LoraConfig
from trl import GRPOConfig, GRPOTrainer
# Load and prep dataset
SYSTEM_PROMPT = """
Respond in the following format:
<reasoning>
...
</reasoning>
<answer>
...
</answer>
"""
XML_COT_FORMAT = """\
<reasoning>
{reasoning}
</reasoning>
<answer>
{answer}
</answer>
"""
def extract_xml_answer(text: str) -> str:
answer = text.split("<answer>")[-1]
answer = answer.split("</answer>")[0]
return answer.strip()
def extract_hash_answer(text: str) -> str | None:
if "####" not in text:
return None
return text.split("####")[1].strip().replace(",", "").replace("$", "")
# uncomment middle messages for 1-shot prompting
def get_gsm8k_questions(split = "train") -> Dataset:
data = load_dataset('openai/gsm8k', 'main')[split] # type: ignore
data = data.map(lambda x: { # type: ignore
'prompt': [
{'role': 'system', 'content': SYSTEM_PROMPT},
#{'role': 'user', 'content': 'What is the largest single-digit prime number?'},
#{'role': 'assistant', 'content': XML_COT_FORMAT.format(
# reasoning="9 is divisble by 3 and 8 is divisible by 2, but 7 is prime.",
# answer="7"
#)},
{'role': 'user', 'content': x['question']}
],
'answer': extract_hash_answer(x['answer'])
}) # type: ignore
return data # type: ignore
dataset = get_gsm8k_questions()
# Reward functions
def correctness_reward_func(prompts, completions, answer, **kwargs) -> list[float]:
responses = [completion[0]['content'] for completion in completions]
q = prompts[0][-1]['content']
extracted_responses = [extract_xml_answer(r) for r in responses]
print('-'*20, f"Question:\n{q}", f"\nAnswer:\n{answer[0]}", f"\nResponse:\n{responses[0]}", f"\nExtracted:\n{extracted_responses[0]}")
return [2.0 if r == a else 0.0 for r, a in zip(extracted_responses, answer)]
def int_reward_func(completions, **kwargs) -> list[float]:
responses = [completion[0]['content'] for completion in completions]
extracted_responses = [extract_xml_answer(r) for r in responses]
return [0.5 if r.isdigit() else 0.0 for r in extracted_responses]
def strict_format_reward_func(completions, **kwargs) -> list[float]:
"""Reward function that checks if the completion has a specific format."""
pattern = r"^<reasoning>\n.*?\n</reasoning>\n<answer>\n.*?\n</answer>\n$"
responses = [completion[0]["content"] for completion in completions]
matches = [re.match(pattern, r) for r in responses]
return [0.5 if match else 0.0 for match in matches]
def soft_format_reward_func(completions, **kwargs) -> list[float]:
"""Reward function that checks if the completion has a specific format."""
pattern = r"<reasoning>.*?</reasoning>\s*<answer>.*?</answer>"
responses = [completion[0]["content"] for completion in completions]
matches = [re.match(pattern, r) for r in responses]
return [0.5 if match else 0.0 for match in matches]
def count_xml(text) -> float:
count = 0.0
if text.count("<reasoning>\n") == 1:
count += 0.125
if text.count("\n</reasoning>\n") == 1:
count += 0.125
if text.count("\n<answer>\n") == 1:
count += 0.125
count -= len(text.split("\n</answer>\n")[-1])*0.001
if text.count("\n</answer>") == 1:
count += 0.125
count -= (len(text.split("\n</answer>")[-1]) - 1)*0.001
return count
def xmlcount_reward_func(completions, **kwargs) -> list[float]:
contents = [completion[0]["content"] for completion in completions]
return [count_xml(c) for c in contents]
#model_name = "meta-llama/Llama-3.2-1B-Instruct"
model_name = "Qwen/Qwen2.5-1.5B-Instruct"
if "Llama" in model_name:
output_dir = "outputs/Llama-1B-GRPO"
run_name = "Llama-1B-GRPO-gsm8k"
else:
output_dir="outputs/Qwen-1.5B-GRPO"
run_name="Qwen-1.5B-GRPO-gsm8k"
training_args = GRPOConfig(
output_dir=output_dir,
run_name=run_name,
learning_rate=5e-6,
adam_beta1 = 0.9,
adam_beta2 = 0.99,
weight_decay = 0.1,
warmup_ratio = 0.1,
lr_scheduler_type='cosine',
logging_steps=1,
bf16=True,
per_device_train_batch_size=1,
gradient_accumulation_steps=4,
num_generations=16,
max_prompt_length=256,
max_completion_length=786,
num_train_epochs=1,
save_steps=100,
max_grad_norm=0.1,
report_to="wandb",
log_on_each_node=False,
)
peft_config = LoraConfig(
r=16,
lora_alpha=64,
target_modules=["q_proj", "k_proj", "v_proj", "o_proj", "up_proj", "down_proj", "gate_proj"],
task_type="CAUSAL_LM",
lora_dropout=0.05,
)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.bfloat16,
attn_implementation="flash_attention_2",
device_map=None
).to("cuda")
tokenizer = AutoTokenizer.from_pretrained(model_name)
tokenizer.pad_token = tokenizer.eos_token
# use peft at your own risk; not working for me with multi-GPU training
trainer = GRPOTrainer(
model=model,
processing_class=tokenizer,
reward_funcs=[
xmlcount_reward_func,
soft_format_reward_func,
strict_format_reward_func,
int_reward_func,
correctness_reward_func],
args=training_args,
train_dataset=dataset,
#peft_config=peft_config
)
trainer.train()
DeepScaleR
项目链接:https://github.com/agentica-project/deepscaler
DeepScaleR 是一个开源项目,旨在使 LLM 的强化学习 (RL) 完全普及,并在实际任务中大规模重现 DeepSeek R1 和 OpenAI O1/O3。对于所有版本,我们在此开源所有努力,包括训练脚本(包括超参数)、模型、数据集和日志。
近期,UC 伯克利团队宣布,他们仅以4500美元的成本,通过简单的强化学习(RL),就成功复现并训练出了 DeepScaleR-1.5B-Preview 模型,直接超越了 o1-preview。
UC伯克利的研究团队以 Deepseek-R1-Distilled-Qwen-1.5B 为基础,通过强化学习(RL),在 40,000 个高质量数学问题上进行训练,使用了 3800 A100 小时(4500美元),训练出了 DeepScaleR-1.5B-Preview 模型。在多个竞赛级数学基准测试中优于 OpenAI 的 o1-preview。
RL 扩展最大的挑战之一是高昂的计算成本。如果要直接复制 DeepSeek-R1 的实验(32K输出,8000 steps),至少需要 70,000 A100 GPU 小时——即使是 1.5B 的小模型。为了解决这个问题,团队采用了线短后长的训练策略。先在 8K 上训练,然后再逐渐扩展到 16K 和 32K。最总将训练成本降低到了 3800 A100 小时(4500美元)。
正如 Deepseek-R1 所倡导的,团队采用结果奖励模型(ORM),而非过程奖励模型(PRM)。奖励函数返回值如下:
- 返回 1:如果 LLM 的答案,既能通过 LaTeX 语法检查,又能通过 Sympy 数学验证,就给它奖励。
- 返回 0:要是 LLM 的答案是错的,或者格式不对,比如少了 和 标记,那就不给奖励。
LIMO
项目链接:https://github.com/GAIR-NLP/LIMO
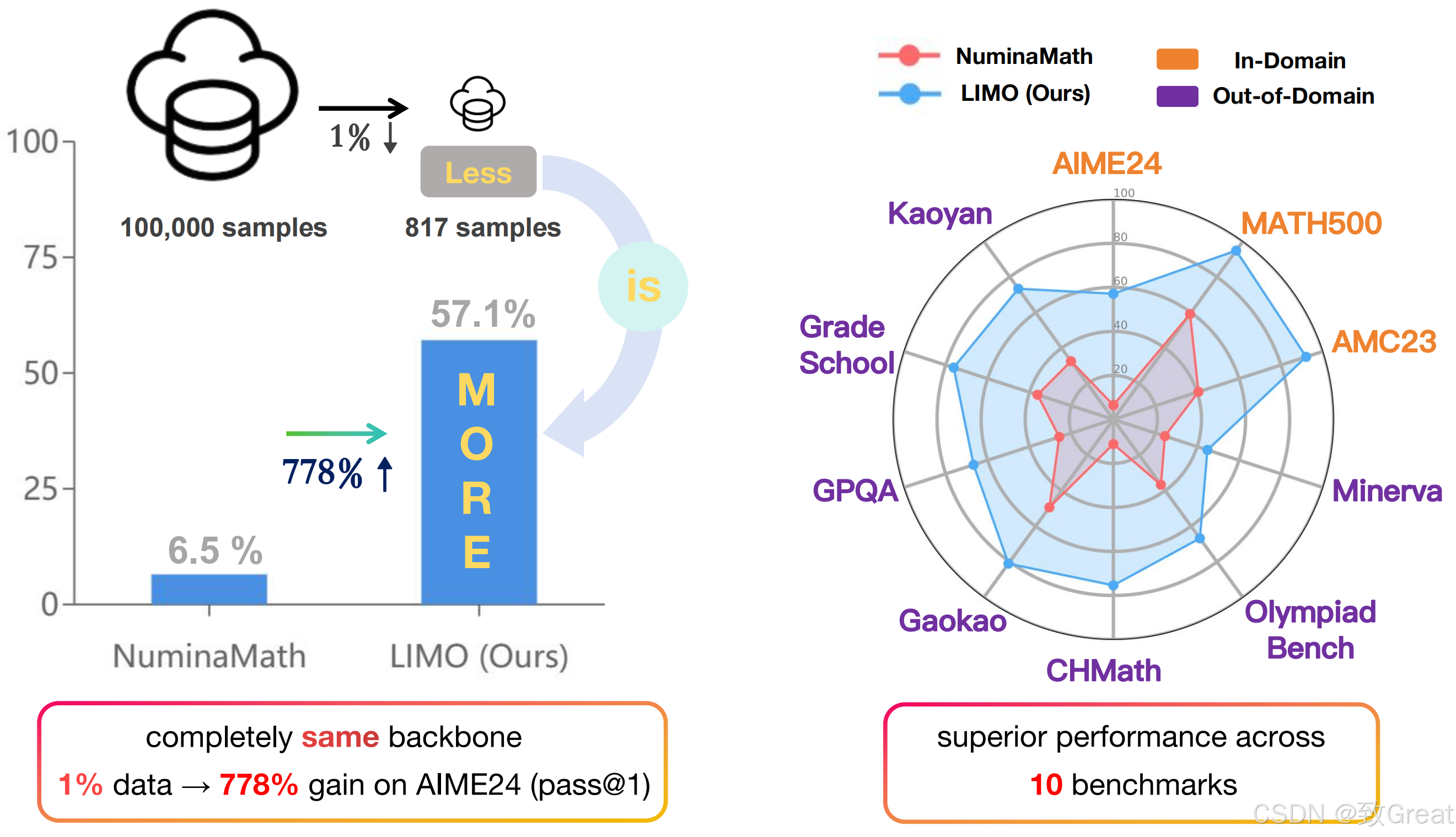
在之前很长的时间里,大家的共识是“海量数据”才能训练出强大的模型。尤其在数学领域,业界普遍坚信,唯有依托海量数据与复杂的强化学习,才能取得突破性进展。
然而,上交大的最新研究成果却给出了一个另外答案:仅需 817 条精心策划的样本,便能让模型在数学竞赛级别的难题上超越众多现有的顶尖模型。这一发现不仅颠覆了传统认知,更揭示了一个我们可能一直忽视的事实:大模型的数学潜能或许始终存在,关键在于如何有效激发它。
“少即是多”(LIMO)假设形式化表述为:在预训练基座模型中,通过最小却精确协调的认知过程展示,可以激发出复杂的推理能力。这一假设建立在两个基本前提之上:
- (I)模型参数空间中蕴含着潜在的先决知识;
- (II)将复杂问题精确拆解为详尽、逻辑清晰的推理链,能够使认知过程变得明确且可追溯。
为了验证这一假设,LIMO 提出了一种系统化的方法来构建高质量、最小化的数据集,以有效唤醒模型的内在推理潜能。
问题选择 :高质量的问题应该能自然地引发扩展的推理过程。选择标准包括以下几点:
-
难度等级 : 优先考虑具有复杂推理链、多样化的思维过程和知识整合的问题,这些问题能够使大语言模型有效利用预训练知识进行高质量的推理。
-
泛化性 : 那些偏离模型训练分布的问题可以更好地挑战其固定的思维模式,鼓励探索新的推理方法,从而扩展其推断搜索空间。
-
知识多样性 :选择的问题应涵盖各种数学领域和概念,要求模型在解决问题时整合和连接遥远的知识。
推理能力数据集
- open-r1/OpenR1-Math-220k:OpenR1-Math-220k 是一个大规模数学推理数据集,包含 220k 道数学题,每道题都有DeepSeek R1针对 NuminaMath 1.5 中的问题生成的 2 到 4 条推理痕迹。
- OpenThoughts-114k:拥有 114,000 个高质量示例,涵盖数学、科学、代码和谜题等。
- bespokelabs/Bespoke-Stratos-17k:对伯克利 Sky-T1 数据的复制,使用 DeepSeek-R1 创建了一个包含问题、推理过程和答案的数据集。
- R1-Distill-SFT:目前有 17000 个样本,目的是创建数据以支持 Open-R1 项目。
- cognitivecomputations/dolphin-r1:包含 80 万个样本的数据集,其中的数据来自 DeepSeek-R1 和 Gemini flash 的生成结果,同时还有来自 Dolphin chat 的 20 万个样本。
- GSM8K:GSM8K(小学数学 8K)是一个包含 8.5K 道高质量、语言多样化的小学数学应用题的数据集。该数据集的创建是为了支持需要多步推理的基本数学问题的问答任务。
- LIMO:LIMO(Less Is More for Reasoning)仅用 817 条精心设计的训练样本,通过简单的 SFT,就全面超越了那些使用几十万数据训练的主流模型,如 o1-preview 和 QwQ。
- agentica-org/DeepScaleR-Preview-Dataset:在训练数据集方面,研究人员精心收集了 1984 至 2023 年的美国国际数学邀请赛(AIME)题目、2023年之前的美国数学竞赛(AMC)题目,以及来自 Omni-MATH 和 Still 数据集的各国及国际数学竞赛题目。约4万个问题-答案对,作为训练数据集。
参考资料
GRPO训练
训练记录
-
Qwen2.5-14B-Instruct
set -x export HYDRA_FULL_ERROR=1 export VLLM_ATTENTION_BACKEND=XFORMERS python3 -m verl.trainer.main_ppo \ algorithm.adv_estimator=grpo \ data.train_files=$HOME/data/gsm8k/train.parquet \ data.val_files=$HOME/data/gsm8k/test.parquet \ data.train_batch_size=1024 \ data.max_prompt_length=512 \ data.max_response_length=1024 \ data.filter_overlong_prompts=True \ data.truncation='error' \ actor_rollout_ref.model.path=/home/jovyan/codes/llms/Qwen2.5-14B-Instruct \ actor_rollout_ref.actor.optim.lr=1e-6 \ actor_rollout_ref.model.use_remove_padding=True \ actor_rollout_ref.actor.ppo_mini_batch_size=256 \ actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu=80 \ actor_rollout_ref.actor.use_kl_loss=True \ actor_rollout_ref.actor.kl_loss_coef=0.001 \ actor_rollout_ref.actor.kl_loss_type=low_var_kl \ actor_rollout_ref.model.enable_gradient_checkpointing=True \ actor_rollout_ref.actor.fsdp_config.param_offload=False \ actor_rollout_ref.actor.fsdp_config.optimizer_offload=False \ actor_rollout_ref.rollout.log_prob_micro_batch_size_per_gpu=160 \ actor_rollout_ref.rollout.tensor_model_parallel_size=2 \ actor_rollout_ref.rollout.name=vllm \ actor_rollout_ref.rollout.gpu_memory_utilization=0.6 \ actor_rollout_ref.rollout.n=5 \ actor_rollout_ref.ref.log_prob_micro_batch_size_per_gpu=160 \ actor_rollout_ref.ref.fsdp_config.param_offload=True \ algorithm.kl_ctrl.kl_coef=0.001 \ trainer.critic_warmup=0 \ trainer.logger=['console','wandb'] \ trainer.project_name='verl_grpo_example_gsm8k' \ trainer.experiment_name='qwen2_7b_function_rm' \ trainer.n_gpus_per_node=8 \ trainer.nnodes=1 \ trainer.save_freq=-1 \ trainer.test_freq=5 \ trainer.total_epochs=15 $@显存分布:
+---------------------------------------------------------------------------------------+ | NVIDIA-SMI 535.129.03 Driver Version: 535.129.03 CUDA Version: 12.2 | |-----------------------------------------+----------------------+----------------------+ | GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |=========================================+======================+======================| | 0 NVIDIA A100-SXM4-80GB On | 00000000:3D:00.0 Off | 0 | | N/A 54C P0 295W / 400W | 60293MiB / 81920MiB | 80% Default | | | | Disabled | +-----------------------------------------+----------------------+----------------------+ | 1 NVIDIA A100-SXM4-80GB On | 00000000:42:00.0 Off | 0 | | N/A 49C P0 270W / 400W | 60537MiB / 81920MiB | 80% Default | | | | Disabled | +-----------------------------------------+----------------------+----------------------+ | 2 NVIDIA A100-SXM4-80GB On | 00000000:61:00.0 Off | 0 | | N/A 47C P0 345W / 400W | 60521MiB / 81920MiB | 80% Default | | | | Disabled | +-----------------------------------------+----------------------+----------------------+ | 3 NVIDIA A100-SXM4-80GB On | 00000000:67:00.0 Off | 0 | | N/A 54C P0 361W / 400W | 60521MiB / 81920MiB | 80% Default | | | | Disabled | +-----------------------------------------+----------------------+----------------------+ | 4 NVIDIA A100-SXM4-80GB On | 00000000:AD:00.0 Off | 0 | | N/A 54C P0 347W / 400W | 60537MiB / 81920MiB | 39% Default | | | | Disabled | +-----------------------------------------+----------------------+----------------------+ | 5 NVIDIA A100-SXM4-80GB On | 00000000:B1:00.0 Off | 0 | | N/A 47C P0 336W / 400W | 60537MiB / 81920MiB | 1% Default | | | | Disabled | +-----------------------------------------+----------------------+----------------------+ | 6 NVIDIA A100-SXM4-80GB On | 00000000:D0:00.0 Off | 0 | | N/A 49C P0 364W / 400W | 60393MiB / 81920MiB | 74% Default | | | | Disabled | +-----------------------------------------+----------------------+----------------------+ | 7 NVIDIA A100-SXM4-80GB On | 00000000:D3:00.0 Off | 0 | | N/A 55C P0 358W / 400W | 60249MiB / 81920MiB | 76% Default | | | | Disabled | +-----------------------------------------+----------------------+----------------------+ +---------------------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=======================================================================================| +---------------------------------------------------------------------------------------+
FAQ
-
问题1:
RuntimeError: CUDA error: an illegal memory access was encountered CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect. For debugging consider passing CUDA_LAUNCH_BLOCKING=1 Compile with TORCH_USE_CUDA_DSA to enable device-side assertions.https://github.com/volcengine/verl/issues/421
可以尝试在运行脚本开中增加 export VLLM_ATTENTION_BACKEND=XFORMERS
-
问题2
Set the environment variable HYDRA_FULL_ERROR=1 for a complete stack trace.添加环境变量
export HYDRA_FULL_ERROR=1 -
问题3:
hydra.errors.ConfigCompositionException: Could not append to config. An item is already at 'actor_rollout_ref.actor.fsdp_config.param_offload'. Either remove + prefix: 'actor_rollout_ref.actor.fsdp_config.param_offload=False' Or add a second + to add or override 'actor_rollout_ref.actor.fsdp_config.param_offload': '++actor_rollout_ref.actor.fsdp_config.param_offload=False'添加运行环境变量:
set -x export HYDRA_FULL_ERROR=1 export VLLM_ATTENTION_BACKEND=XFORMERS -
问题4:Qwen2.5-32B-Instruct 8卡 A100 80GB OOM
CUDA out of memory. Tried to allocate 270.00 MiB. GPU 0 has a total capacity of 79.33 GiB of which 19.81 MiB is free. Process 2395281 has 79.29 GiB memory in use. Of the allocated memory 76.06 GiB is allocated by PyTorch, and 166.25 MiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True to avoid fragmentation. See documentation for Memory Management (https://pytorch.org/docs/stable/notes/cuda.html#environment-variables) -
问题5:flash-attn安装
**flash_attn-2.7.4.post1+cu12torch2.4cxx11abiTRUE-cp310-cp310-linux_x86_64.whl** **flash_attn-2.7.4.post1+cu12torch2.4cxx11abiFALSE-cp310-cp310-linux_x86_64.whl**通过下面命令判断选择安装的版本:
import torch print(torch._C._GLIBCXX_USE_CXX11_ABI) -
问题5: resource temporarily unavailable
[2025-03-13 22:58:03,152 E 2249743 2250179] logging.cc:120: Stack trace: /home/jovyan/codes/envs/verl/lib/python3.10/site-packages/ray/_raylet.so(+0x13aa76a) [0x7fc0f6abe76a] ray::operator<<() /home/jovyan/codes/envs/verl/lib/python3.10/site-packages/ray/_raylet.so(+0x13adea2) [0x7fc0f6ac1ea2] ray::TerminateHandler() /lib/x86_64-linux-gnu/libstdc++.so.6(+0xae20c) [0x7fc1c17a920c] /lib/x86_64-linux-gnu/libstdc++.so.6(+0xae277) [0x7fc1c17a9277] /lib/x86_64-linux-gnu/libstdc++.so.6(+0xae4d8) [0x7fc1c17a94d8] /home/jovyan/codes/envs/verl/lib/python3.10/site-packages/ray/_raylet.so(+0x6eb3f4) [0x7fc0f5dff3f4] boost::throw_exception<>() /home/jovyan/codes/envs/verl/lib/python3.10/site-packages/ray/_raylet.so(+0x13ba24b) [0x7fc0f6ace24b] boost::asio::detail::do_throw_error() /home/jovyan/codes/envs/verl/lib/python3.10/site-packages/ray/_raylet.so(+0x13bac6b) [0x7fc0f6acec6b] boost::asio::detail::posix_thread::start_thread() /home/jovyan/codes/envs/verl/lib/python3.10/site-packages/ray/_raylet.so(+0x13bb0cc) [0x7fc0f6acf0cc] boost::asio::thread_pool::thread_pool() /home/jovyan/codes/envs/verl/lib/python3.10/site-packages/ray/_raylet.so(+0xccd6f4) [0x7fc0f63e16f4] ray::rpc::(anonymous namespace)::_GetServerCallExecutor() /home/jovyan/codes/envs/verl/lib/python3.10/site-packages/ray/_raylet.so(_ZN3ray3rpc21GetServerCallExecutorEv+0x9) [0x7fc0f63e1789] ray::rpc::GetServerCallExecutor() /home/jovyan/codes/envs/verl/lib/python3.10/site-packages/ray/_raylet.so(_ZNSt17_Function_handlerIFvN3ray6StatusESt8functionIFvvEES4_EZNS0_3rpc14ServerCallImplINS6_24CoreWorkerServiceHandlerENS6_14LocalGCRequestENS6_12LocalGCReplyELNS6_8AuthTypeE0EE17HandleRequestImplEbEUlS1_S4_S4_E0_E9_M_invokeERKSt9_Any_dataOS1_OS4_SJ_+0x12b) [0x7fc0f606937b] std::_Function_handler<>::_M_invoke() /home/jovyan/codes/envs/verl/lib/python3.10/site-packages/ray/_raylet.so(_ZN3ray4core10CoreWorker13HandleLocalGCENS_3rpc14LocalGCRequestEPNS2_12LocalGCReplyESt8functionIFvNS_6StatusES6_IFvvEES9_EE+0x89) [0x7fc0f5ffd129] ray::core::CoreWorker::HandleLocalGC() /home/jovyan/codes/envs/verl/lib/python3.10/site-packages/ray/_raylet.so(_ZN3ray3rpc14ServerCallImplINS0_24CoreWorkerServiceHandlerENS0_14LocalGCRequestENS0_12LocalGCReplyELNS0_8AuthTypeE0EE17HandleRequestImplEb+0xfe) [0x7fc0f608f3ae] ray::rpc::ServerCallImpl<>::HandleRequestImpl() /home/jovyan/codes/envs/verl/lib/python3.10/site-packages/ray/_raylet.so(+0xd0cbc8) [0x7fc0f6420bc8] EventTracker::RecordExecution() /home/jovyan/codes/envs/verl/lib/python3.10/site-packages/ray/_raylet.so(+0xcf0ffe) [0x7fc0f6404ffe] std::_Function_handler<>::_M_invoke() /home/jovyan/codes/envs/verl/lib/python3.10/site-packages/ray/_raylet.so(+0xcf1476) [0x7fc0f6405476] boost::asio::detail::completion_handler<>::do_complete() /home/jovyan/codes/envs/verl/lib/python3.10/site-packages/ray/_raylet.so(+0x13b78db) [0x7fc0f6acb8db] boost::asio::detail::scheduler::do_run_one() /home/jovyan/codes/envs/verl/lib/python3.10/site-packages/ray/_raylet.so(+0x13b9259) [0x7fc0f6acd259] boost::asio::detail::scheduler::run() /home/jovyan/codes/envs/verl/lib/python3.10/site-packages/ray/_raylet.so(+0x13b9962) [0x7fc0f6acd962] boost::asio::io_context::run() /home/jovyan/codes/envs/verl/lib/python3.10/site-packages/ray/_raylet.so(_ZN3ray4core10CoreWorker12RunIOServiceEv+0x91) [0x7fc0f5ff40b1] ray::core::CoreWorker::RunIOService() /home/jovyan/codes/envs/verl/lib/python3.10/site-packages/ray/_raylet.so(+0xdfe4e0) [0x7fc0f65124e0] thread_proxy /lib/x86_64-linux-gnu/libc.so.6(+0x94ac3) [0x7fc267d97ac3] /lib/x86_64-linux-gnu/libc.so.6(+0x126850) [0x7fc267e29850] *** SIGABRT received at time=1741906683 on cpu 123 *** PC: @ 0x7fc267d999fc (unknown) pthread_kill @ 0x7fc267d45520 (unknown) (unknown) [2025-03-13 22:58:03,152 E 2249743 2250179] logging.cc:484: *** SIGABRT received at time=1741906683 on cpu 123 *** [2025-03-13 22:58:03,152 E 2249743 2250179] logging.cc:484: PC: @ 0x7fc267d999fc (unknown) pthread_kill [2025-03-13 22:58:03,152 E 2249743 2250179] logging.cc:484: @ 0x7fc267d45520 (unknown) (unknown) Fatal Python error: Aborted Extension modules: numpy.core._multiarray_umath, numpy.core._multiarray_tests, numpy.linalg._umath_linalg, numpy.fft._pocketfft_internal, numpy.random._common, numpy.random.bit_generator, numpy.random._bounded_integers, numpy.random._mt19937, numpy.random.mtrand, numpy.random._philox, numpy.random._pcg64, numpy.random._sfc64, numpy.random._generator, pyarrow.lib, pandas._libs.tslibs.ccalendar, pandas._libs.tslibs.np_datetime, pandas._libs.tslibs.dtypes, pandas._libs.tslibs.base, pandas._libs.tslibs.nattype, pandas._libs.tslibs.timezones, pandas._libs.tslibs.fields, pandas._libs.tslibs.timedeltas, pandas._libs.tslibs.tzconversion, pandas._libs.tslibs.timestamps, pandas._libs.properties, pandas._libs.tslibs.offsets, pandas._libs.tslibs.strptime, pandas._libs.tslibs.parsing, pandas._libs.tslibs.conversion, pandas._libs.tslibs.period, pandas._libs.tslibs.vectorized, pandas._libs.ops_dispatch, pandas._libs.missing, pandas._libs.hashtable, pandas._libs.algos, pandas._libs.interval, pandas._libs.lib, pyarrow._compute, pandas._libs.ops, pandas._libs.hashing, pandas._libs.arrays, pandas._libs.tslib, pandas._libs.sparse, pandas._libs.internals, pandas._libs.indexing, pandas._libs.index, pandas._libs.writers, pandas._libs.join, pandas._libs.window.aggregations, pandas._libs.window.indexers, pandas._libs.reshape, pandas._libs.groupby, pandas._libs.json, pandas._libs.parsers, pandas._libs.testing, torch._C, torch._C._fft, torch._C._linalg, torch._C._nested, torch._C._nn, torch._C._sparse, torch._C._special, msgpack._cmsgpack, google._upb._message, psutil._psutil_linux, psutil._psutil_posix, setproctitle, yaml._yaml, charset_normalizer.md, requests.packages.charset_normalizer.md, requests.packages.chardet.md, uvloop.loop, ray._raylet, markupsafe._speedups, PIL._imaging, frozenlist._frozenlist, PIL._imagingft, multidict._multidict, yarl._quoting_c, propcache._helpers_c, aiohttp._http_writer, aiohttp._http_parser, aiohttp._websocket.mask, aiohttp._websocket.reader_c, pyarrow._json (total: 85) Aborted

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 22
22 0
0- 0



 已为社区贡献36条内容
已为社区贡献36条内容

所有评论(0)