NeurIPS Spotlight 论文解读 | ARM: Adaptive Reasoning Model
GRPO的奖励仅基于预测结果与真实标签的匹配度(0或1),而Ada-GRPO在此基础上,增加了“探索奖励权重”——对于在训练集中出现概率较低的推理格式(如Short CoT仅占2条,而Long CoT占6条),通过“组大小÷该格式样本数”的方式提升其奖励权重(如Short CoT的奖励为8÷2=4,Long CoT的奖励为8÷6≈1.3),鼓励模型探索高效但使用较少的推理格式。引入余弦衰减的α系数
点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
作者简介
谢健,俄亥俄州立大学博士生
内容简介
尽管大型推理模型在复杂任务上表现出强劲性能,但它们缺乏根据任务难度调整推理token使用量的能力。这往往会导致“过度思考”问题——即进行过多不必要的推理。尽管通过人工干预控制token预算可能在一定程度上缓解该问题,但这与实现完全自主人工智能的目标存在根本性矛盾。
在本研究中,我们提出了自适应推理模型(Adaptive Reasoning Model, ARM),该模型能够根据具体任务自适应选择合适的推理格式。这些格式包括三种高效推理格式——直接回答(Direct Answer)、短思维链(Short CoT)和代码式推理(Code),以及一种更详尽的推理格式——长思维链(Long CoT)。为训练ARM,我们引入了Ada-GRPO算法,该算法是分组相对策略优化(Group Relative Policy Optimization, GRPO)的改进版本,旨在解决传统GRPO中存在的格式坍缩问题。Ada-GRPO使ARM具备了极高的token使用效率,在保持与纯依赖长思维链(Long CoT)的模型相当性能的前提下,平均减少约30%的token使用量,最高可减少约70%。此外,该算法不仅通过减少token生成提升了推理效率,还使训练速度提升了约2倍。
除默认的自适应模式(Adaptive Mode)外,ARM还支持另外两种推理模式:1)指令引导模式(Instruction-Guided Mode),允许用户通过特殊token明确指定推理格式,适用于已知一批任务对应最优推理格式的场景;2)共识引导模式(Consensus-Guided Mode),该模式先聚合三种高效推理格式的输出结果,若结果存在分歧则启用长思维链(Long CoT)推理,以更高的token开销优先保障推理性能。
论文地址:https://arxiv.org/pdf/2505.20258
代码链接:https://team-arm.github.io/arm
论文解读
本项研究旨在解决大型语言模型(LRMs)中存在的“过度思考”(Over-thinking)问题。“过度思考”现象首次被提出并引发广泛关注,源于腾讯2024年的一项研究。该研究通过一个简单的示例——“2加3的结果是多少”,直观展现了这一问题:对于人类而言,“2加3等于5”是近乎常识性的知识,传统通用模型仅需几个或十几个token即可得出答案;但o1-preview、o1-mini、DeepSeek-R1、QWQ32等类o1模型,却需要消耗数百甚至近千个token才能完成这一简单计算。

这种现象并非我们期望的理想状态。一个高效的模型应具备“因材施教”的推理能力:面对简单问题时,采用简洁的思维方式快速求解;处理复杂问题时,再投入更多token进行深度推理。
目前,学界已关注到“过度思考”问题并提出了相关解决方案,其中最具代表性的是“长度惩罚”(Length Penalty)方案,典型工作包括L1和ThinkPrune等。
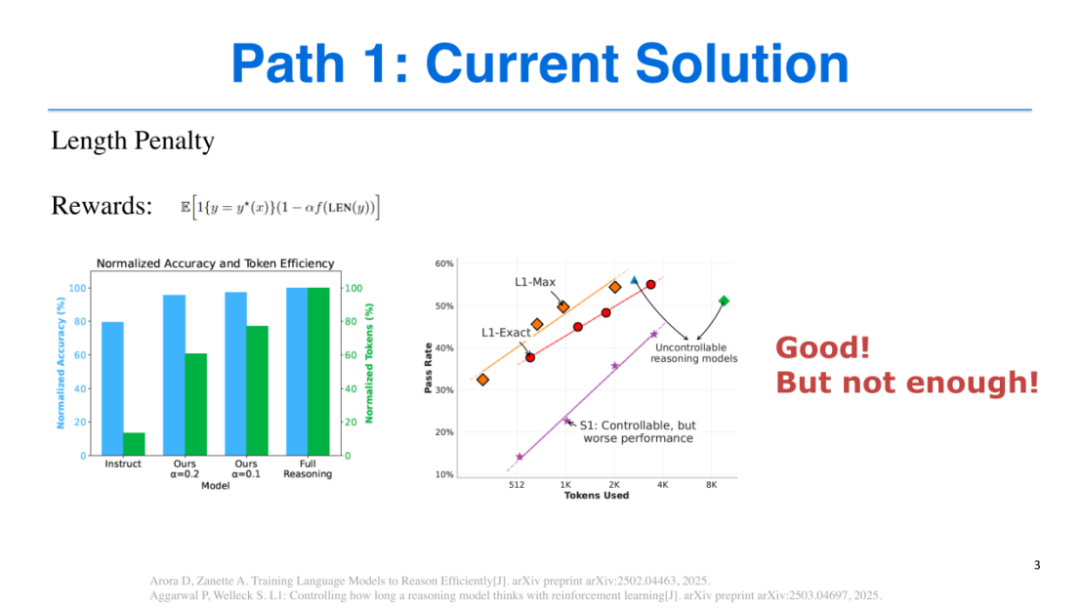
L1的核心思路是在提示词(prompt)中明确指定模型的token使用上限,例如限制模型在4096个token内完成任务,一旦超出上限便会受到惩罚,以此约束模型的推理过程。但该方案存在明显缺陷:它要求使用者对任务难度有清晰认知和先验知识,才能合理设定token阈值。若对任务难度判断失误——如为复杂任务分配过少的token(如512个),则会导致模型性能显著下降。
ThinkPrune则采用另一种思路:为不同的token预算训练专属模型,例如分别训练适配4096个token和2048个token的模型,使用者需根据任务所需的token范围调用对应模型。但无论是L1还是ThinkPrune,都需要人工介入,依赖使用者的经验判断任务特性,未能满足对“统一模型”的需求——即一个模型能够自主适配不同难度任务的推理需求。
研究思路:借鉴人类双系统思维模式
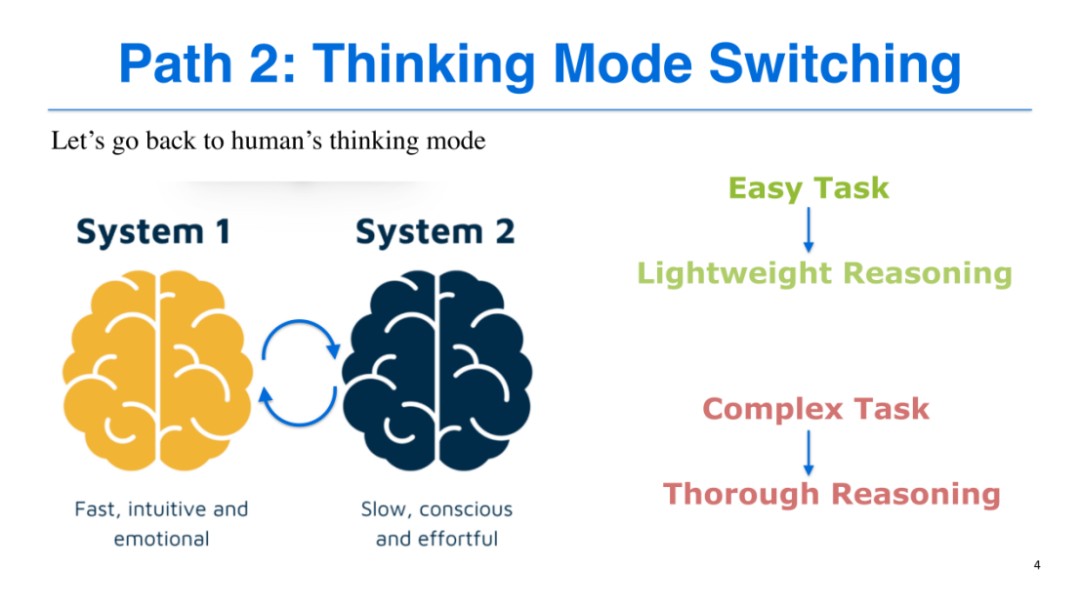
为实现这一目标,我们借鉴了人类的双系统思维模式(System 1 & System 2):
-
System 1(快思考):适用于简单任务,具有快速、直观、情绪化的特点,无需复杂推理即可得出答案;
-
System 2(慢思考):适用于复杂任务,需要有意识地投入精力,通过逐步演算、排除错误、反复验证等过程求解,例如解决复杂数学题或奥赛题。
我们的核心构想是:将这两种思维模式整合到同一个模型中,让模型能够根据任务难度自主选择合适的推理方式。人类已总结出多种可明确归类的推理格式,我们将其划分为“轻量化推理”和“深度推理”两大类,分别对应System 1和System 2:
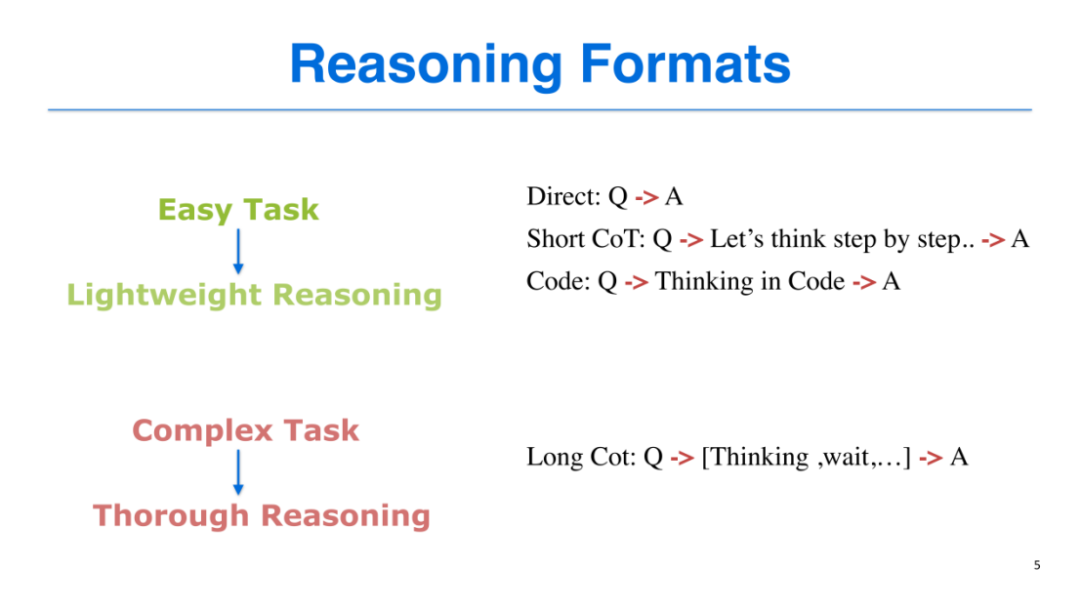
1. 轻量化推理(适用于简单任务,token开销通常不超过300个):
-
直接推理(Direct):输入问题(Q)后,模型直接输出答案(A),例如“2加3”直接返回“5”;
-
短链思维链推理(Short CoT):输入问题后,模型通过“逐步思考”(Let's think step by step)的方式呈现推理过程,最终输出答案;
-
代码式推理(Code):借鉴DeepSeek 2025年初的研究成果,模型以代码逻辑进行推理(如“A=2,B=3,Answer = A + B”),在符号计算任务中表现更优。

2. 深度推理(适用于复杂任务,token开销可达数千甚至上万个):
-
长链思维链推理(Long CoT):输入问题后,模型通过长时间思考、反复推敲、自我纠错(如“思考、停顿、排除错误”等过程),最终输出答案,是目前复杂推理任务中常用的方式。
模型训练与优化:Ada-GRPO算法
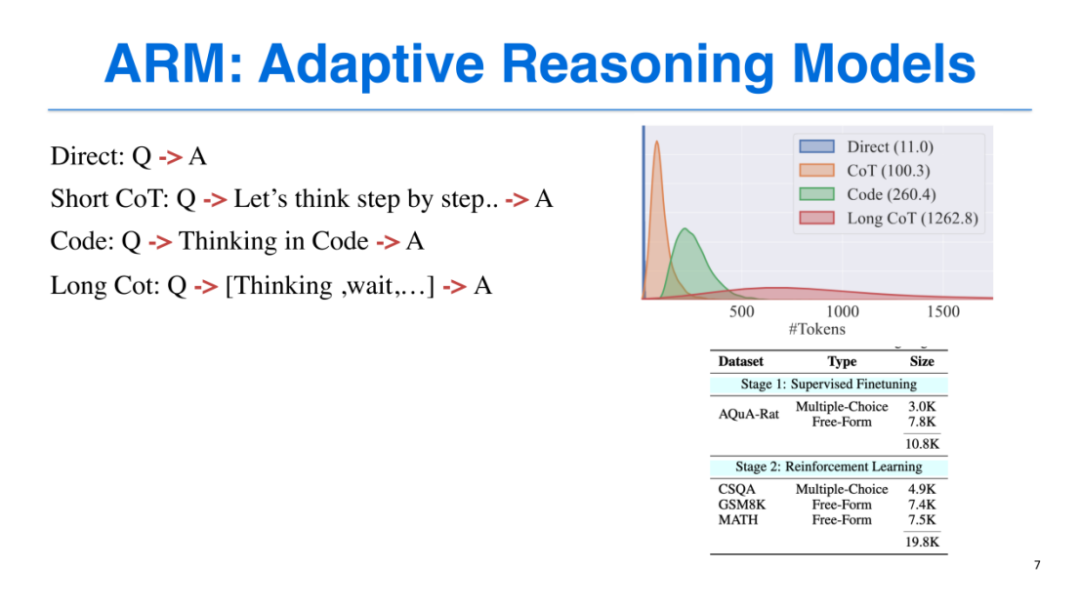
我们的训练基于AQuA-Rat数据集,涵盖3000条选择题和7800条自由问答形式题目,为每个任务配备4种推理格式;强化学习阶段则采用CSQA、GSM8K、MATH等数据集,总规模达19.8K。
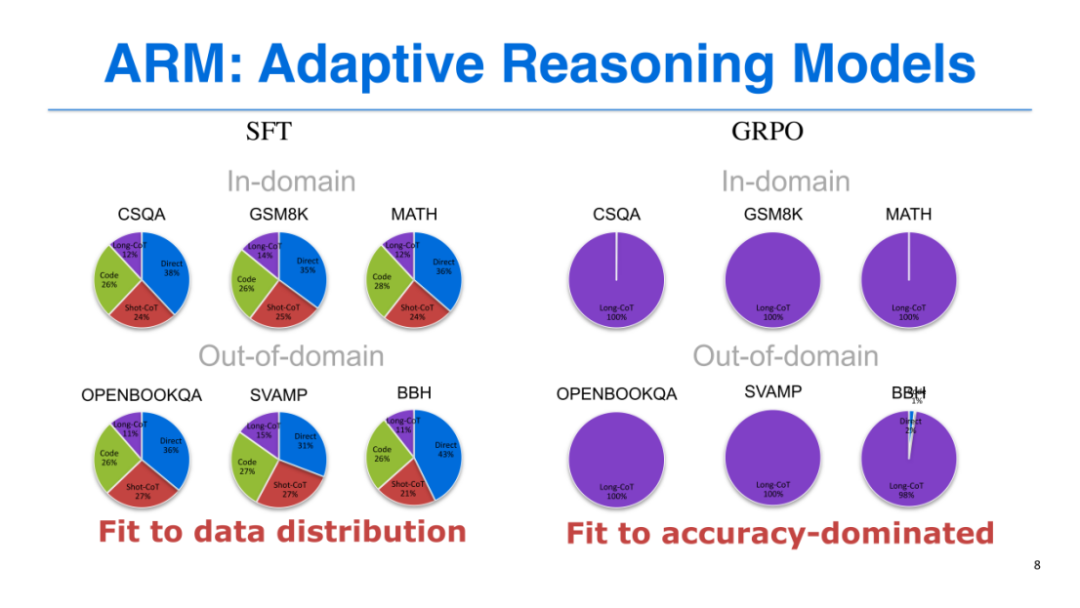
我们首先验证了监督微调(SFT)和GRPO(一种强化学习算法)能否实现“自适应推理”目标,结果并不理想:
-
SFT的问题:SFT需将4种推理格式全部喂给模型训练,导致模型倾向于平均分配推理格式的使用概率,无法根据任务难度自主选择。例如,对于简单的常识问答(Common QA),模型未能更多采用高效的直接推理;对于复杂的数学任务,也未优先使用长链思维链推理,最终导致性能损失。
-
GRPO的问题:GRPO以SFT模型为初始化,初期能均衡输出不同推理格式,但由于长链思维链推理(Long CoT)的性能更优,获得的奖励更多,随着训练推进,模型会逐渐偏向于使用Long CoT,最终所有任务都采用该推理格式,再次陷入“过度思考”的困境。
为解决上述问题,我们提出了Ada-GRPO(Adaptive GRPO)算法,核心优化在于奖励分配机制:
-
基础奖励与探索奖励结合:GRPO的奖励仅基于预测结果与真实标签的匹配度(0或1),而Ada-GRPO在此基础上,增加了“探索奖励权重”——对于在训练集中出现概率较低的推理格式(如Short CoT仅占2条,而Long CoT占6条),通过“组大小÷该格式样本数”的方式提升其奖励权重(如Short CoT的奖励为8÷2=4,Long CoT的奖励为8÷6≈1.3),鼓励模型探索高效但使用较少的推理格式。
-
奖励权重衰减机制:引入余弦衰减的α系数,随着训练步数增加,探索奖励权重逐渐降低,最终回归到基于性能的0-1奖励分布,保证模型在后期专注于性能优化。(余弦衰减机制一定程度上提升了训练稳定性,具体细节可参考论文原文)

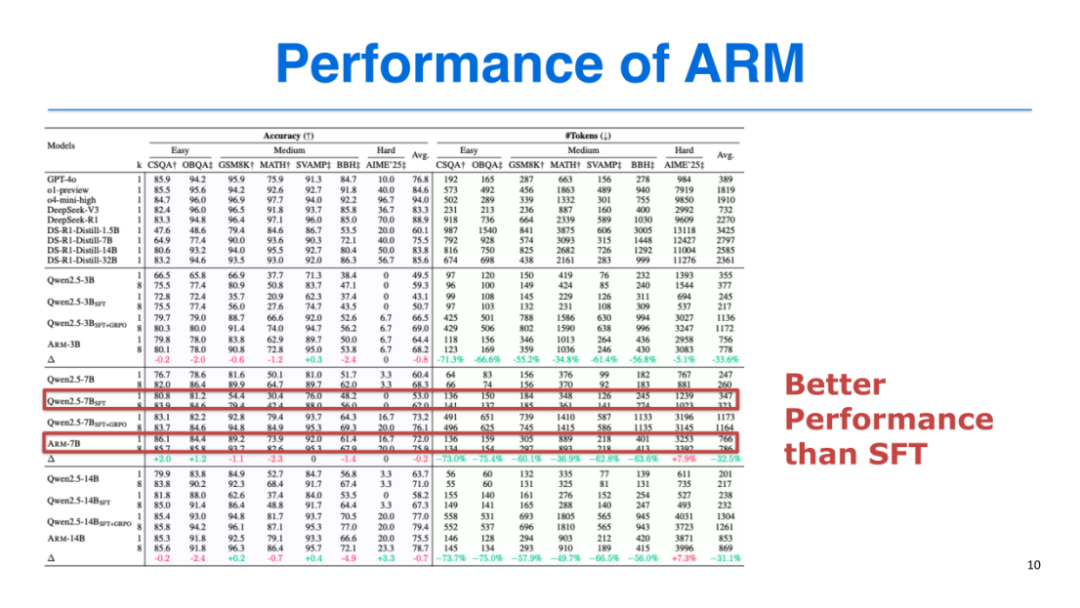
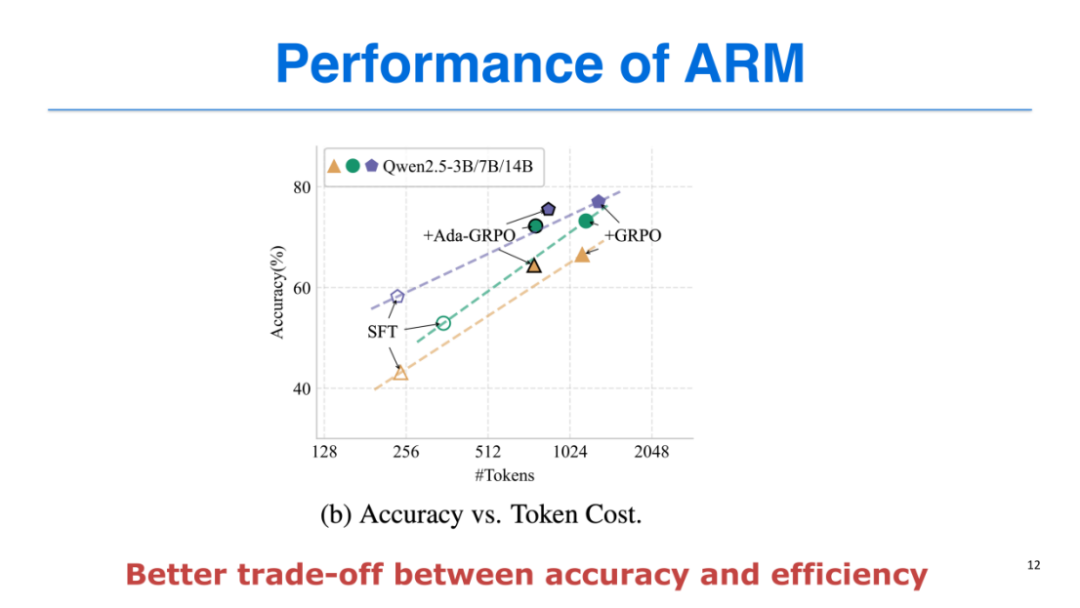
我们在7个数据集上对ARM进行测试,结果显示:
-
与SFT相比:ARM在所有模型规模(3B、7B、14B)上均实现性能提升,同时显著优化了token使用效率;
-
与GRPO相比:ARM的性能与GRPO基本持平(性能损失仅0.2%),但token开销节省30%-70%,证明了方法的泛化性和鲁棒性;
-
性能-效率平衡:SFT和GRPO的性能- token开销曲线呈线性关系,而ARM始终位于该曲线的左上方,实现了更高的准确率与更优的token效率的平衡。
ARM支持三种推理模式,适配不同使用场景:
-
自适应模式(Adaptive Mode,默认):模型自主判断任务难度并选择推理格式,在高准确率和高效token使用之间达到最佳平衡。例如,在简单任务(如CSQA+)上,准确率达86.1%,仅使用136个token;在复杂任务(如AIME'25)上,准确率16.7%,使用3253个token。
-
指令引导模式(Instruction Guide Mode):使用者可通过提示词指定推理格式(如“Direct”“Short CoT”),适用于使用者对任务难度有明确认知的场景。例如,已知AIME'25是高难度任务,可指定使用Long CoT推理,提升性能。
-
共识模式(Consensus Mode):模型先通过三种轻量化推理格式(Direct、Short CoT、Code)推理,若结果一致则输出答案;若不一致则切换到Long CoT,性能最优但token开销最大(约为自适应模式的2-2.5倍)。
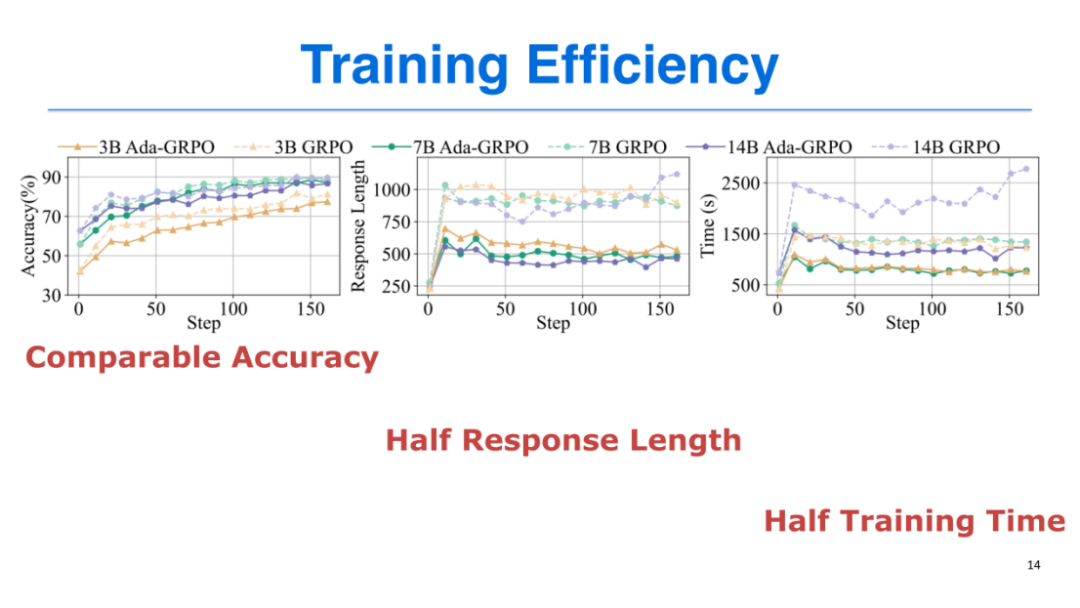
训练效率:与GRPO相比,ARM的响应长度缩短一半,训练时间节省近50%,因为训练时间主要受响应长度(token开销)影响;
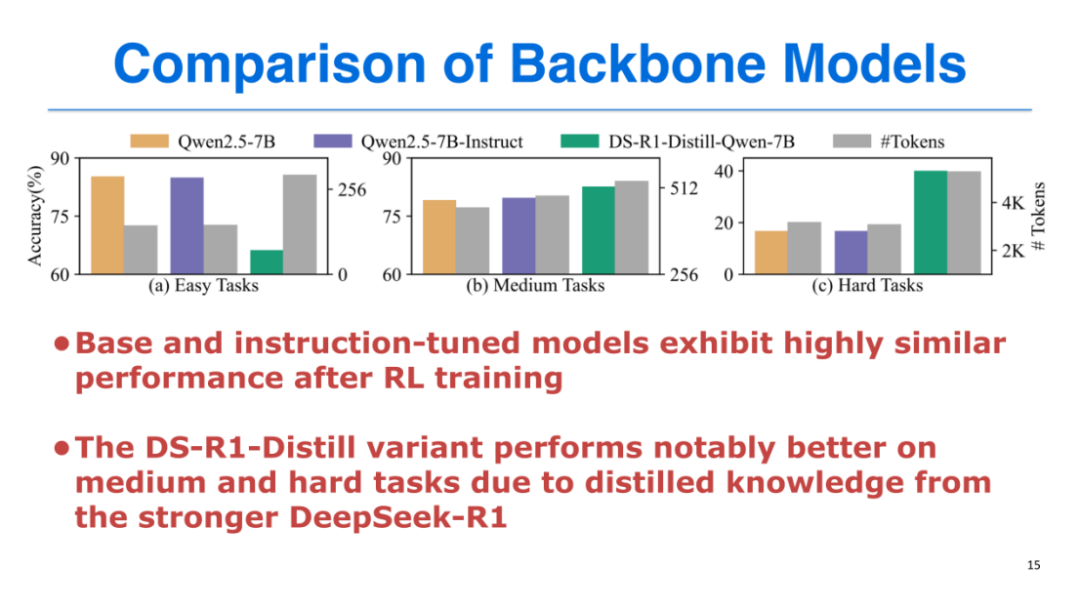
backbone 对比:我们测试了Qwen2.5-7B(Base)、Qwen2.5-7B-Instruct、DS-R1-Distill-Qwen-7B三种骨干模型,发现:
-
Base和Instruct模型经过强化学习后性能差异不大;
-
DS-R1-Distill模型在中高难度任务上性能更优,但在简单任务上“过度思考”问题更严重;
-
最终选择Qwen2.5-7B(Base)作为骨干模型,平衡了简单任务和复杂任务的表现。
本研究提出的ARM模型,通过借鉴人类双系统思维模式,整合轻量化推理与深度推理格式,并基于Ada-GRPO算法实现了“自适应推理”,有效解决了大型语言模型的“过度思考”问题,在准确率和token效率之间达到了更优平衡。
本期文章由支昕整理
往期精彩文章推荐

关于AI TIME
AI TIME源起于2019年,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法和场景应用的本质问题进行探索,加强思想碰撞,链接全球AI学者、行业专家和爱好者,希望以辩论的形式,探讨人工智能和人类未来之间的矛盾,探索人工智能领域的未来。
迄今为止,AI TIME已经邀请了2000多位海内外讲者,举办了逾800场活动,超1000万人次观看。

我知道你
在看
提出观点,表达想法,欢迎
留言

点击 阅读原文 查看作者直播回放!

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 0
0 0
0- 0



 已为社区贡献50条内容
已为社区贡献50条内容

所有评论(0)