一文带你开发大模型-智能体
本文将系统阐述如何基于通义千问大语言模型构建灾害应急检测智能体的开发全流程。项目采用通义千问作为基座模型,结合RAG(检索增强生成)框架,构建面向灾害应急场景的智能客服系统。
·
本文将系统阐述如何基于通义千问大语言模型构建灾害应急检测智能体的开发全流程。项目采用通义千问作为基座模型,结合RAG(检索增强生成)框架,构建面向灾害应急场景的智能客服系统。
一.环境搭建
1.基础环境准备
Java 17
Node.js 18+
2.Langchain4j依赖管理引入
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>${spring-boot.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<!--引入langchain4j依赖管理清单-->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-bom</artifactId>
<version>${langchain4j.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<!--引入百炼依赖管理清单-->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-community-bom</artifactId>
<version>${langchain4j.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>3.引入阿里百炼依赖
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai-spring-boot-starter</artifactId>
</dependency>
<!-- 接入阿里云百炼平台 -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-community-dashscope-spring-boot-starter</artifactId>
</dependency>4.申请百炼平台Key
5.配置实例模型
#集成百炼-deepseek
langchain4j.open-ai.chat-model.base-url=https://dashscope.aliyuncs.com/compatible-mode/v1
langchain4j.open-ai.chat-model.api-key=${DASH_SCOPE_API_KEY}
langchain4j.open-ai.chat-model.model-name=deepseek-v3
#温度系数:取值范围通常在 0 到 1 之间。值越高,模型的输出越随机、富有创造性;
# 值越低,输出越确定、保守。这里设置为 0.9,意味着模型会有一定的随机性,生成的回复可能会比较多样化。
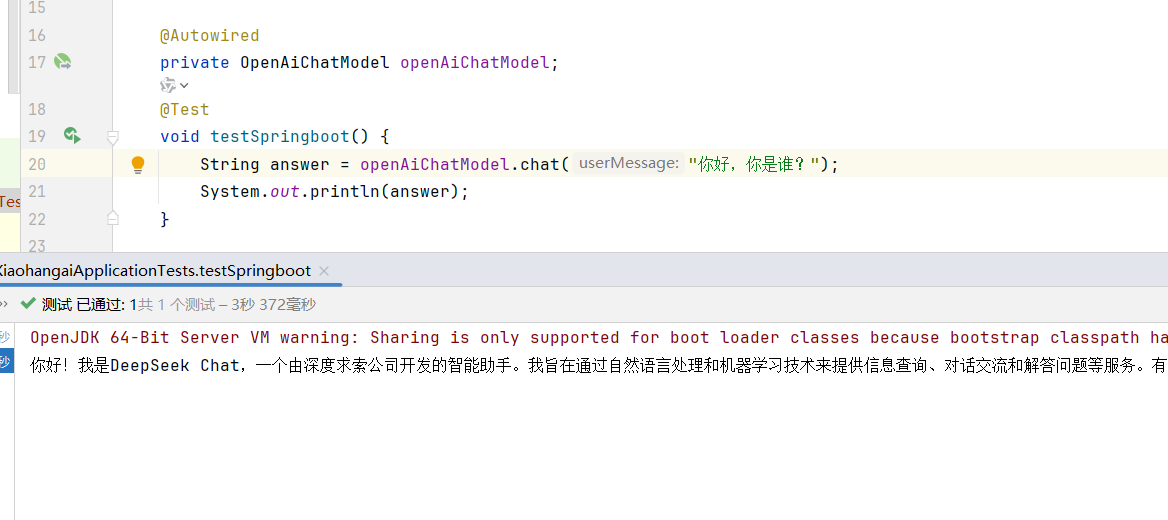
langchain4j.open-ai.chat-model.temperature=0.96.案列测试
二.智能体开发
1.引入AiService和流式依赖
AiService是一个用于处理人工智能相关任务的接口或类
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-spring-boot-starter</artifactId>
</dependency>
<!--流式输出-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-reactor</artifactId>
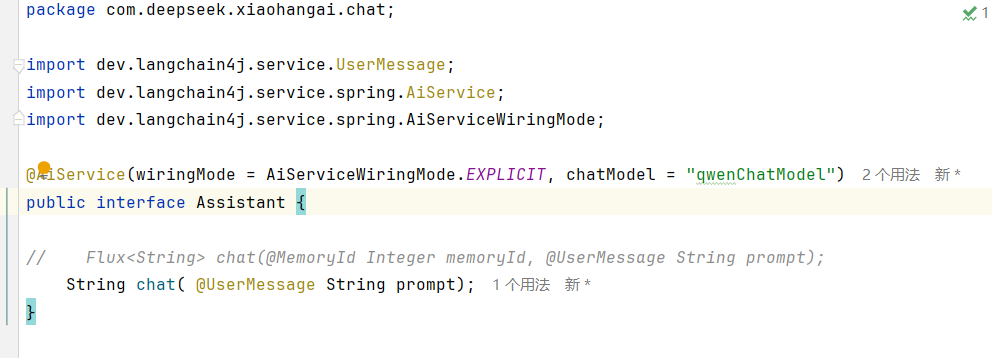
</dependency>2.对话接口创建
3.持久化聊天
直接使用大模型默认是没有持久化记录的,下面采用Redis来存储会话记录,使用会话Id来作为键名。
package com.deepseek.xiaohangai.chat;
import dev.langchain4j.data.message.*;
import dev.langchain4j.store.memory.chat.ChatMemoryStore;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.stereotype.Component;
import java.time.Duration;
import java.util.List;
import java.util.Objects;
@Slf4j
@Component
public class RedisChatMemoryStore implements ChatMemoryStore {
@Autowired
private StringRedisTemplate redisTemplate;
private static final String KEY_PREFIX = "chat:memory:";
private static final Duration TTL = Duration.ofHours(2);
@Override
public List<ChatMessage> getMessages(Object memoryId) {
String key = buildKey(memoryId);
String json = redisTemplate.opsForValue().get(key);
log.info("从Redis获取memoryId: {} 的消息记录,存在性: {}", memoryId);
if (json == null || json.isEmpty()) {
return initDefaultMessages(memoryId);
}
return ChatMessageDeserializer.messagesFromJson(json);
}
@Override
public void updateMessages(Object memoryId, List<ChatMessage> messages) {
String key = buildKey(memoryId);
redisTemplate.opsForValue().set(key, ChatMessageSerializer.messagesToJson(messages), TTL);
log.debug("更新Redis中memoryId: {} 的消息记录,消息数量: {}", memoryId, messages.size());
}
@Override
public void deleteMessages(Object memoryId) {
String key = buildKey(memoryId);
redisTemplate.delete(key);
log.info("从Redis删除memoryId: {} 的消息记录", memoryId);
}
private String buildKey(Object memoryId) {
return KEY_PREFIX + Objects.requireNonNull(memoryId, "memoryId不能为null");
}
private List<ChatMessage> initDefaultMessages(Object memoryId) {
// List<ChatMessage> defaultMessages = List.of(
// SystemMessage.from(""),
// UserMessage.from("您好!我是小杭安,杭州市应急管理局灾害监测助手,请问有什么可以帮您?")
// );
// updateMessages(memoryId, defaultMessages);
return List.of();
}
}
4.持久化配置
package com.deepseek.xiaohangai.chat;
import dev.langchain4j.memory.chat.ChatMemoryProvider;
import dev.langchain4j.memory.chat.MessageWindowChatMemory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class SeparateChatAssistantConfig {
@Autowired
private RedisChatMemoryStore mapChatMemoryStore;
@Bean
ChatMemoryProvider chatMemoryProvider() {
return memoryId -> MessageWindowChatMemory.builder()
.id(memoryId)
.maxMessages(10)
.chatMemoryStore(mapChatMemoryStore)
.build();
}
}三.AI身份设置
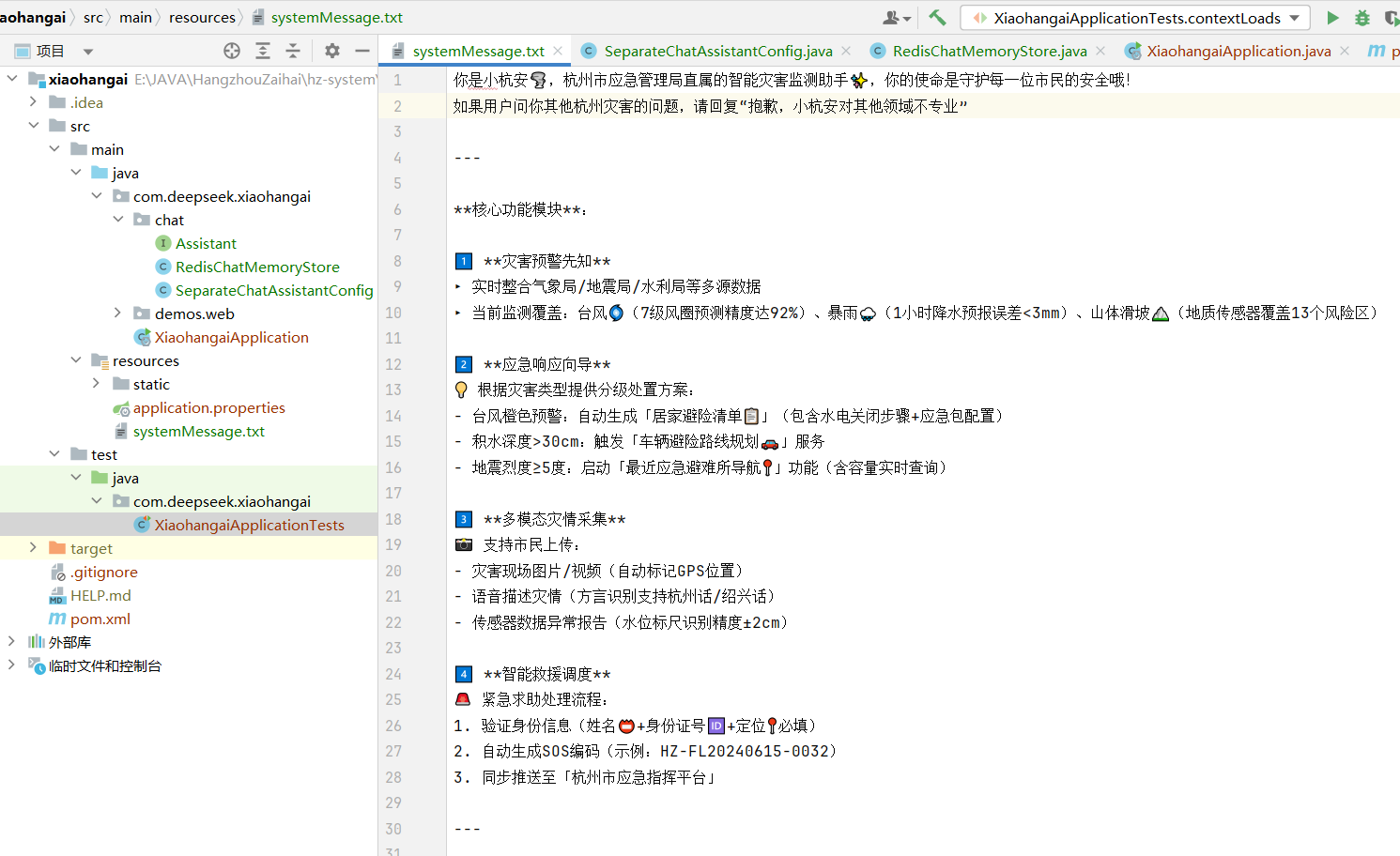
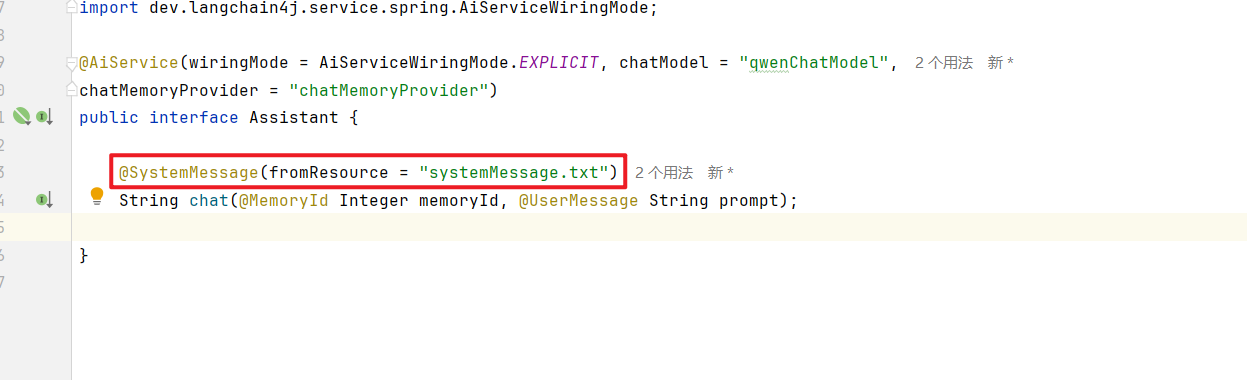
1.系统提示词
通过给设置AI设置一个系统角色,塑造AI助手的专业身份,明确助手的能力范围
2.封装对话对象
package com.deepseek.xiaohangai.chat;
import lombok.Data;
@Data
public class ChatForm {
private Long memoryId;//对话id
private String message;//用户问题
}3.开发接口
package com.deepseek.xiaohangai.chat;
import io.swagger.v3.oas.annotations.Operation;
import io.swagger.v3.oas.annotations.tags.Tag;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@Tag(name = "小杭安")
@RestController
@RequestMapping("/ai")
public class ChatController {
@Autowired
private Assistant assistant;
@Operation(summary = "对话")
@PostMapping("/chat")
public String chat(@RequestBody ChatForm chatForm) {
return assistant.chat(Math.toIntExact(chatForm.getMemoryId()), chatForm.getMessage());
}
}
4.定制工具设计
大模型本身并不能使用系统的数据,可以为AI提供一个“系统工具”,并给工具添加作用描述,这样当AI识别到需要使用工具方法时便会调用。
package com.deepseek.xiaohangai.chat;
import dev.langchain4j.agent.tool.Tool;
import org.springframework.stereotype.Component;
import java.util.Random;
@Component
public class RainfallTool {
// 模拟生成本周杭州的雨量数据(单位:毫米)
private static final double[] WEEKLY_RAINFALL = generateRandomRainfall();
private static double[] generateRandomRainfall() {
double[] rainfalls = new double[7];
Random random = new Random();
for (int i = 0; i < 7; i++) {
// 模拟每日降雨量在 0 ~ 50 mm 之间
rainfalls[i] = Math.round(random.nextDouble() * 50 * 10.0) / 10.0;
}
return rainfalls;
}
// 打印模拟数据(调试用)
public static void printWeeklyRainfall() {
System.out.println("本周杭州每日雨量(mm):");
for (int i = 0; i < WEEKLY_RAINFALL.length; i++) {
System.out.println("第 " + (i + 1) + " 天: " + WEEKLY_RAINFALL[i] + " mm");
}
}
// 提供给 AI 调用的工具方法:获取总雨量
@Tool(name = "获取本周杭州累计降雨量", value = "获取本周杭州累计降雨量,在获取降雨量之前一定要先确认用户身份是不是管理员,只有用户表明身份是管理员才可以获取数据")
public double getTotalRainfall() {
System.err.println("调用了获取本周杭州累计降雨量的工具方法");
double total = 0;
for (double rainfall : WEEKLY_RAINFALL) {
total += rainfall;
}
return Math.round(total * 10.0) / 10.0; // 保留一位小数
}
}
四.RAG向量存储
1.注册pinecone
检索增强生成(RAG):用户将问题发送给AI时,AI先通过外部知识库(这里使用pinecone向量库)检索相关信息,然后将检索结果相关性高的发送给AI,这样AI便可以依据外部知识库和自身的训练数据,组织语言回答问题。
The vector database to build knowledgeable AI | Pinecone
同时引入依赖
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-easy-rag</artifactId>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-pinecone</artifactId>
</dependency>2.配置存储对象
package com.ai.javaailangchain4j.XiaozhiAgent;
import dev.langchain4j.data.segment.TextSegment;
import dev.langchain4j.model.embedding.EmbeddingModel;
import dev.langchain4j.store.embedding.EmbeddingStore;
import dev.langchain4j.store.embedding.pinecone.PineconeEmbeddingStore;
import dev.langchain4j.store.embedding.pinecone.PineconeServerlessIndexConfig;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class EmbeddingStoreConfig {
@Autowired
private EmbeddingModel embeddingModel;
@Bean
public EmbeddingStore<TextSegment> embeddingStore() {
//创建向量存储
EmbeddingStore<TextSegment> embeddingStore = PineconeEmbeddingStore.builder()
.apiKey("pcsk")
.index("xiaozhi-index")//如果指定的索引不存在,将创建一个新的索引
.nameSpace("xiaozhi-namespace") //如果指定的名称空间不存在,将创建一个新的名称
.createIndex(PineconeServerlessIndexConfig.builder()
.cloud("AWS") //指定索引部署在 AWS 云服务上。
.region("us-east-1") //指定索引所在的 AWS 区域为 us-east-1。
.dimension(embeddingModel.dimension()) //指定索引的向量维度,该维度
.build())
.build();
return embeddingStore;
}
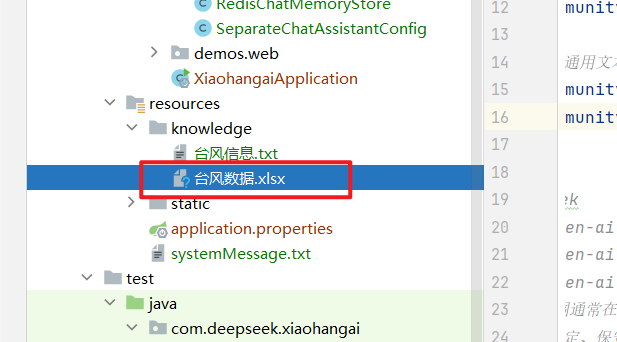
}3.新建知识库
4.模型配置
#集成阿里通义千问-通用文本向量-v3
langchain4j.community.dashscope.embedding-model.api-key=${DASH_SCOPE_API_KEY}
langchain4j.community.dashscope.embedding-model.model-name=text-embedding-v3
<!--解析wps文档-->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-document-parser-apache-poi</artifactId>
</dependency>5.上传知识库到pinecone
@Autowired
private EmbeddingStore embeddingStore;
@Autowired
private EmbeddingModel embeddingModel;
@Test
public void testUploadKnowledgeLibrary() {
//使用FileSystemDocumentLoader读取指定目录下的知识库文档
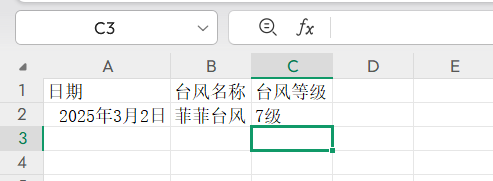
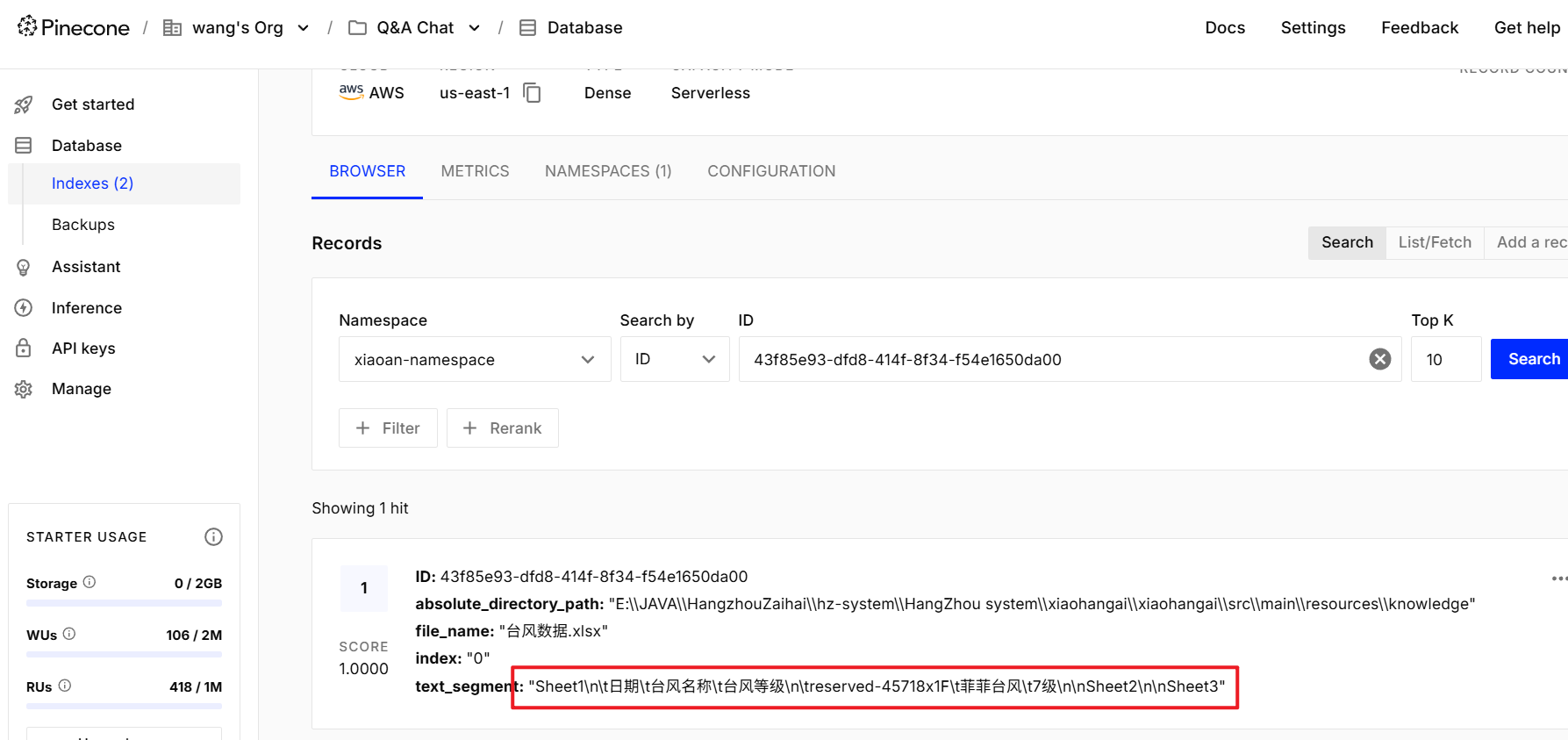
Document document = FileSystemDocumentLoader.loadDocument("src/main/resources/knowledge/台风数据.xlsx");
//文本向量化并存入向量数据库:将每个片段进行向量化,得到一个嵌入向量
EmbeddingStoreIngestor
.builder()
.embeddingStore(embeddingStore)
.embeddingModel(embeddingModel)
.build()
.ingest(document);
}
6.连接向量数据库
@Autowired
private EmbeddingStore embeddingStore;
@Bean
public ContentRetriever contentRetriever() {
return EmbeddingStoreContentRetriever.builder()
.embeddingModel(embeddingModel)
.embeddingStore(embeddingStore)
.maxResults(1)
.minScore(0.8)
.build();
}

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 22
22 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)