IK分词器安装、配置、分词自定义,接上文ElasticSearch安装配置篇,为后续的ElasticSearch实际操作配置前提条件与基础
IK分词器是ElasticSearch(es)的一个最最最有名插件,能够把一段中文或者别的语句划分成一个个的关键字,进而在搜索的时候对数据库中或者索引库数据进一个匹配操作
IK分词器是ElasticSearch(es)的一个最最最有名插件,能够把一段中文或者别的语句划分成一个个的关键字,进而在搜索的时候对数据库中或者索引库数据进一个匹配操作
举个小例子,可以将计算机科学与技术学院更细致的拆分为计算机、计算 、算机 、科学、与、技术、学院 、技术学院等。
IK提供了两个分词算法:ik_smart和ik_max_word,其中ik_smart为最少切分,ik_max_word为最细粒度划分。
目录
一、安装ik分词器
1、添加至环境目录
在上一篇文章中我已经安装了ElasticSearch,并且我新建了环境目录
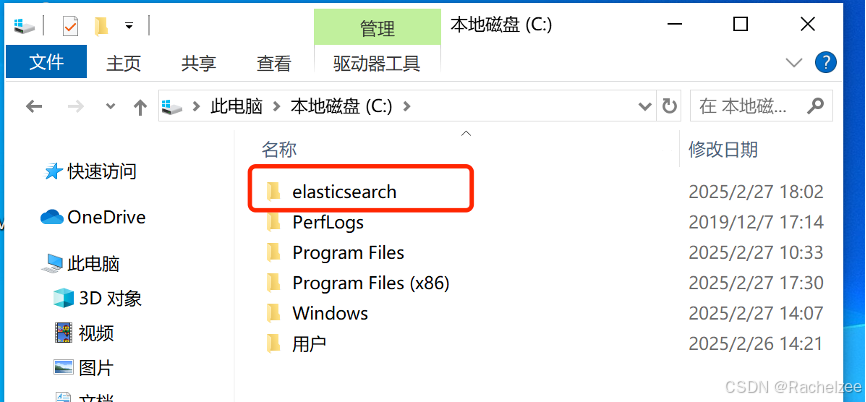
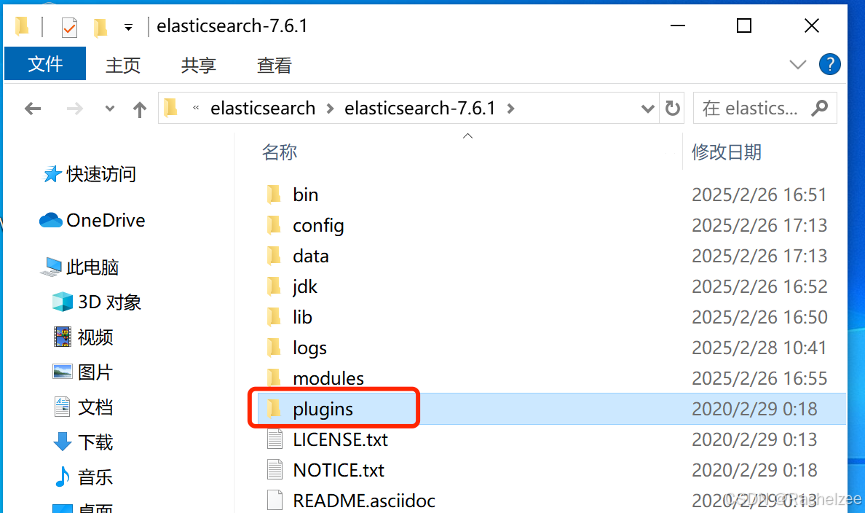
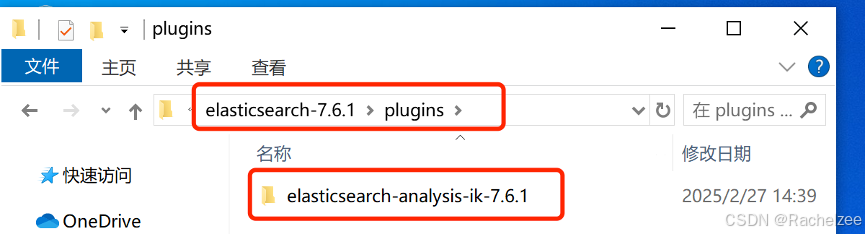
现在将ik分词器的文件夹解压到C:\elasticsearch\elasticsearch-7.6.1\plugins中。
2、重启es
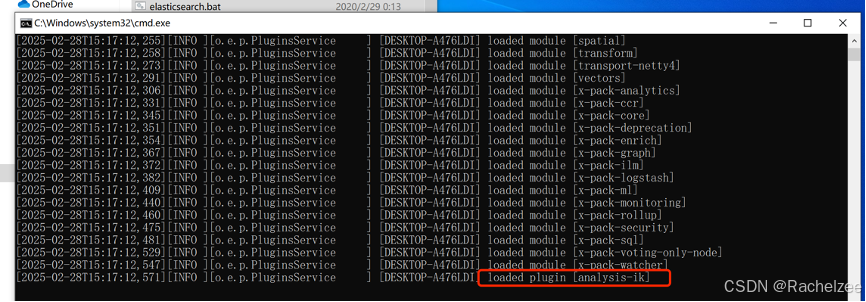
已成功安装ik分词器插件
这里我觉得每次点开都超级麻烦啊,我就直接把那三个常用的文件新建了快捷方式拖到桌面上了
每次按照从左到右的顺序重启即可
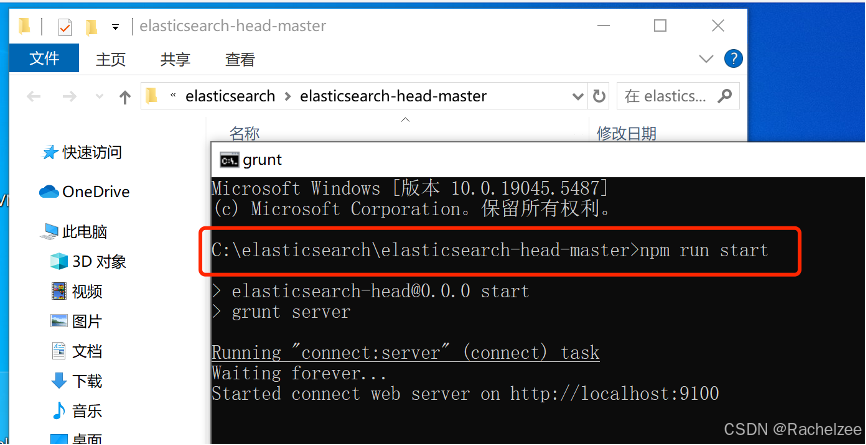
其中第二个文件应通过输入指令
启动指令
npm run start
更多详情可以看我的上一篇文章
也可以通过命令来查看加载进来的插件
elasticsearch-plugin list
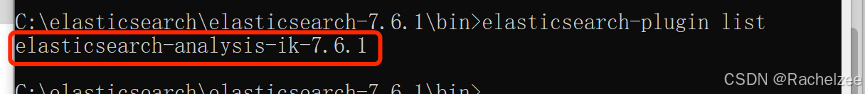
二、配置IK分词器
1、使用kibana测试
启动kibana:C:\elasticsearch\kibana-7.6.1-windows-x86_64\bin\kibana.bat
需要耐心等待,而且需要检查是否已经启动elasticsearch.bat、elasticsearch-head-master。kibana生成前端资源要一点时间,这时候nodejs监听已经运行但是资源页面资源还没准备好,之后会尝试连接elasticsearch如果连不上超时也起不来,所以等一会在看日志有没有error就好。
2、打开kibana进行测试
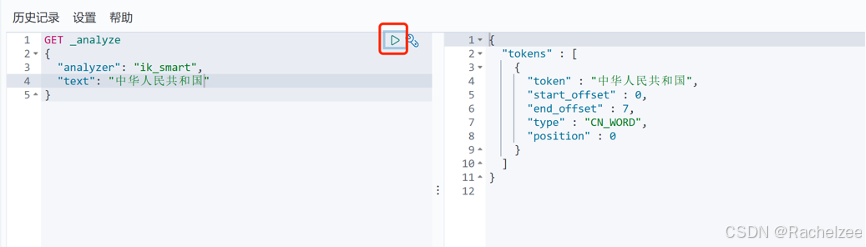
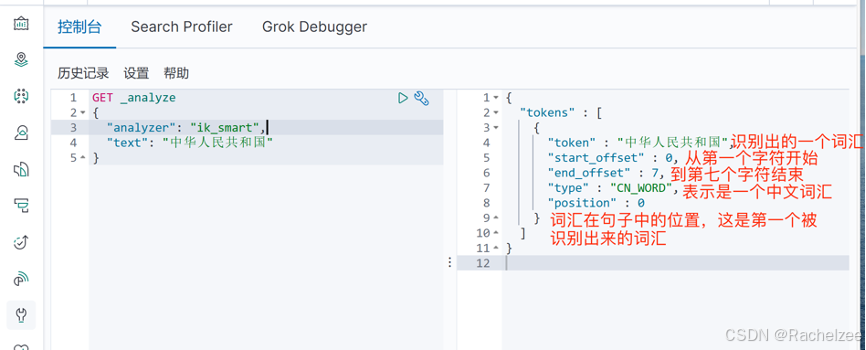
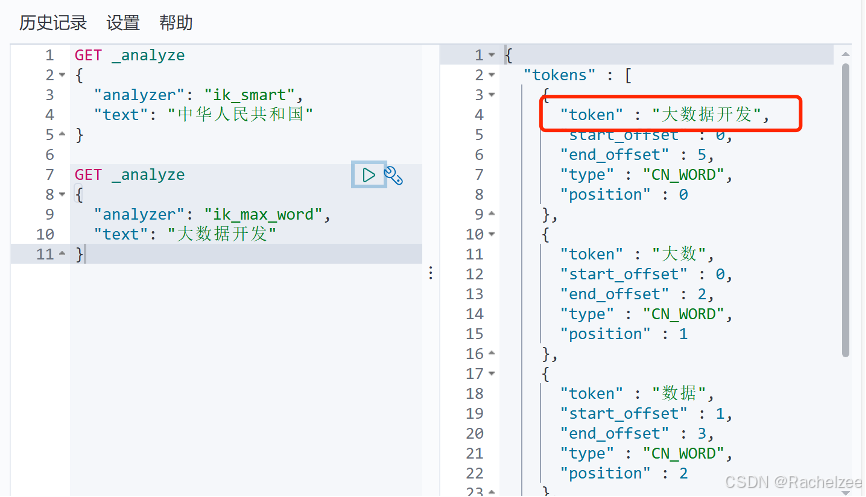
GET _analyze
{
"analyzer": "ik_smart",
"text": "中华人民共和国"
}
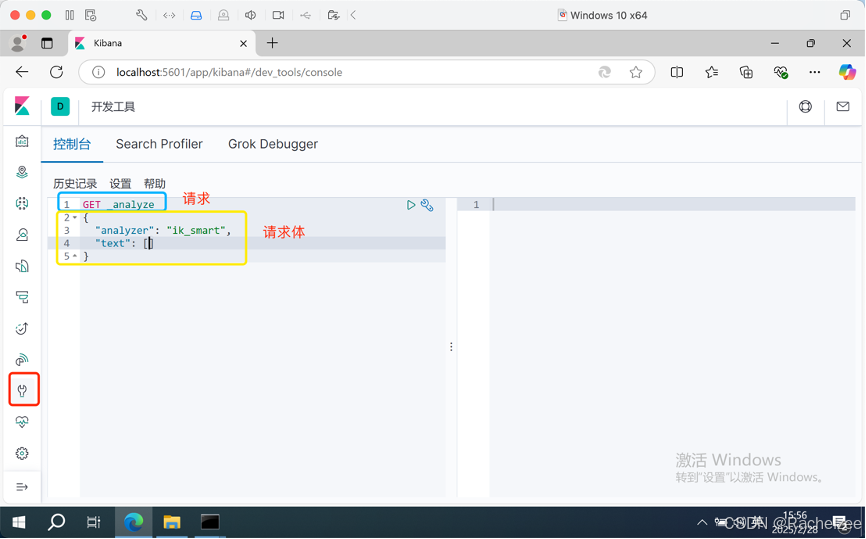
试运行一次下面的代码,分出了一个词
再看一个例子的话
GET _analyze
{
"analyzer": "ik_max_word",
"text": "大数据开发"
}
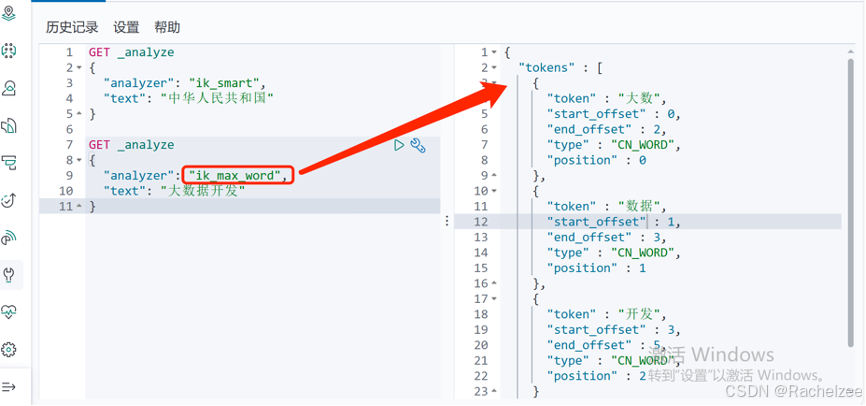
那么ik_smart与ik_max_word的对比如下表
|
ik_smart |
ik_max_word |
|
|
分词粒度 |
智能分词,最粗粒度划分 |
最细粒度划分 |
|
分词次数与字重复 |
每个字在句子中只会出现一次 |
允许句子中的字反复出现,只要在词库中出现过,就会被拆分出来 |
|
歧义识别 |
有歧义识别功能 |
没有歧义识别功能 |
ik_smart为最少切分
ik_max_word为最细粒度划分
三、分词自定义
1、新建字典
当字典中没有自己需要的词,需要自己添加词至分词器的字典中
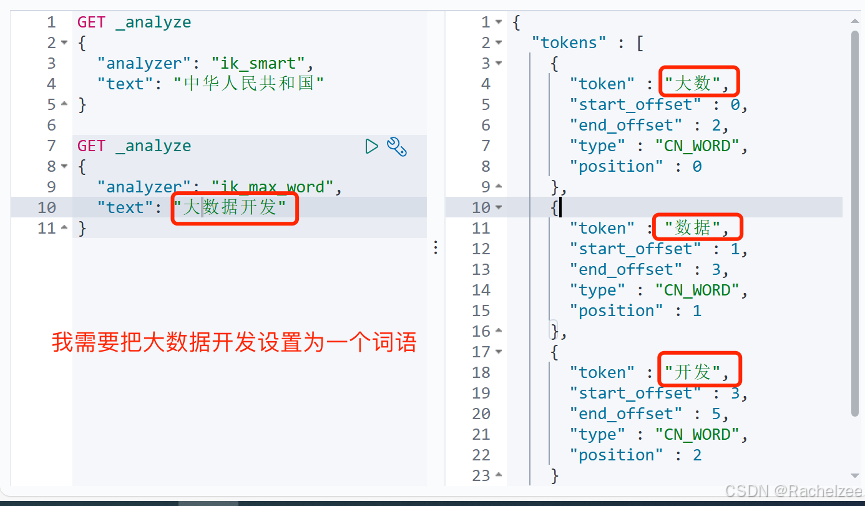
Ik分词器中增加自己的配置
文件路径:C:\elasticsearch\elasticsearch-7.6.1\plugins\elasticsearch-analysis-ik-7.6.1\config
新建一个自己的字典,文件后缀改为.dic
添加自己设定的词

保存并关闭此文件
再看ik分词器配置文件,打开

将自己新建的字典添加至配置文件中
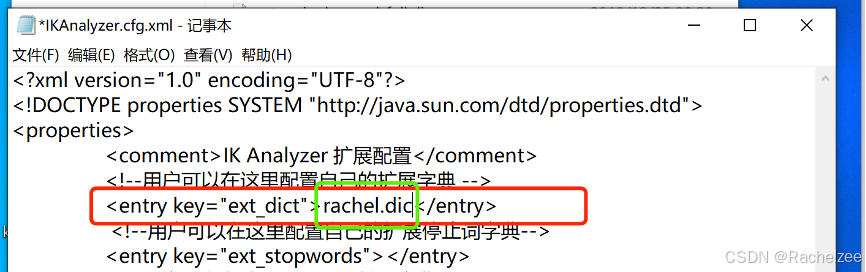
保存并关闭
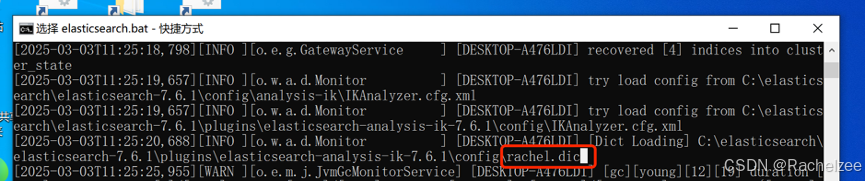
2、重启es
加载了rachel.dic
再次测试看效果
以后我们需要自己配置分词就在自己定义的dic文件中进行配置即可
至此IK分词器安装、配置、分词自定义完成
四、Rest操作-关于索引的基本操作
Rest是一种软件架构风格,而不是标准,只是提供了一组设计原则和约束条件。它主要用于客户端和服务器交互类的软件。基于这个风格设计的软件可以更简洁,更有层次,更易于实现缓存等机制。
|
method |
url地址 |
描述 |
|
PUT |
Localhost:9200/索引名称/类型名称/文档id |
创建文档(指定文档id) |
|
POST |
Localhost:9200/索引名称/类型名称 |
创建文档(随机文档id) |
|
POST |
Localhost:9200/索引名称/类型名称/文档id/_update |
修改文档 |
|
DELETE |
Localhost:9200/索引名称/类型名称/文档id |
删除文档 |
|
GET |
Localhost:9200/索引名称/类型名称/文档id |
通过文档id查询文档 |
|
POST |
Localhost:9200/索引名称/类型名称/_search |
查询所有数据 |
下面为基本操作
1、创建一个索引
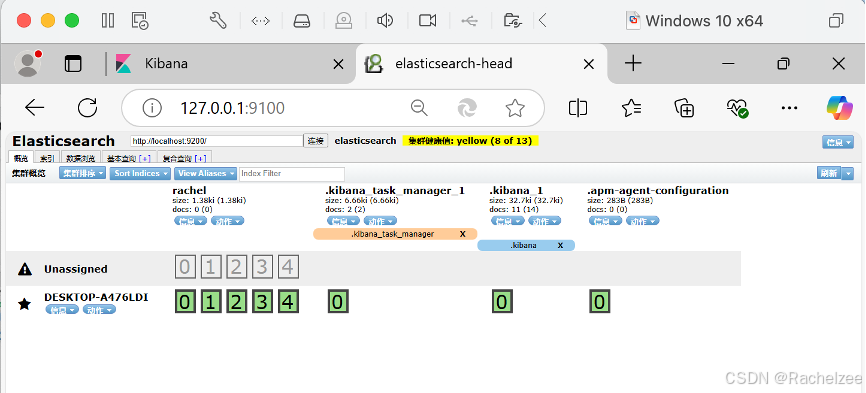
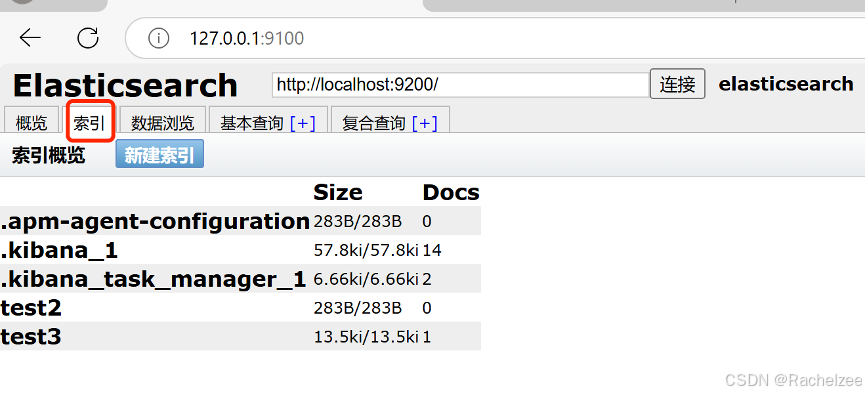
启动head,我已启动所以才有error
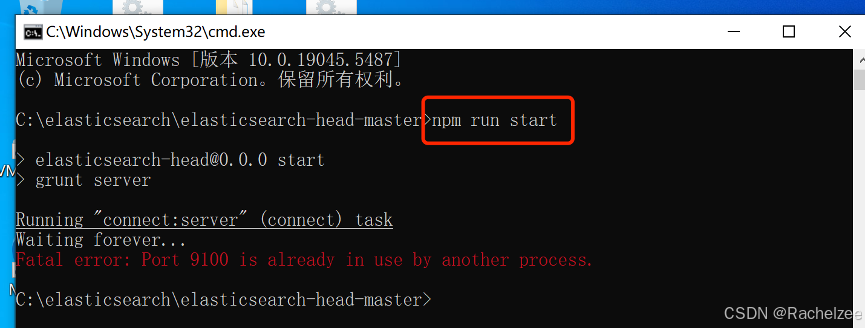
然后在浏览器中访问127.0.0.1:9100
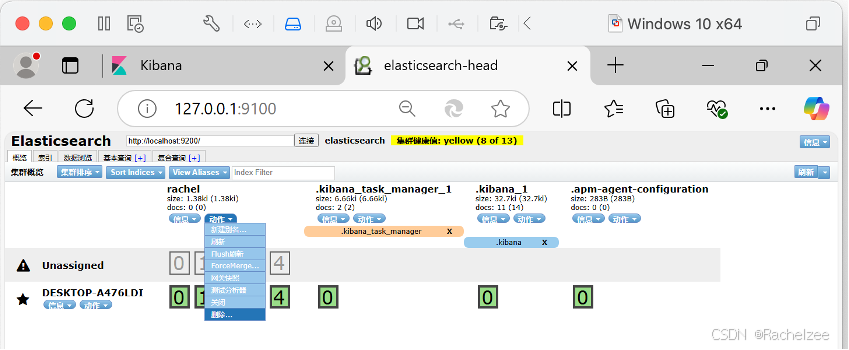
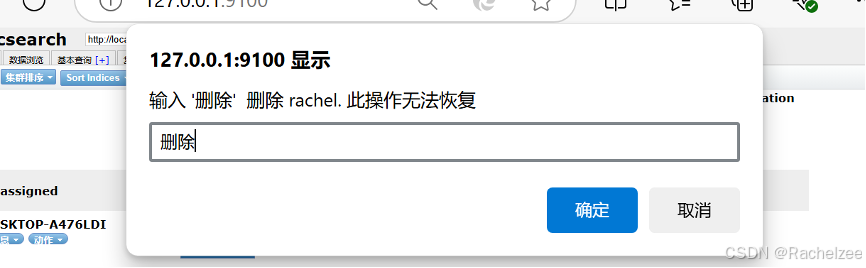
有没有用的库,可以直接删掉
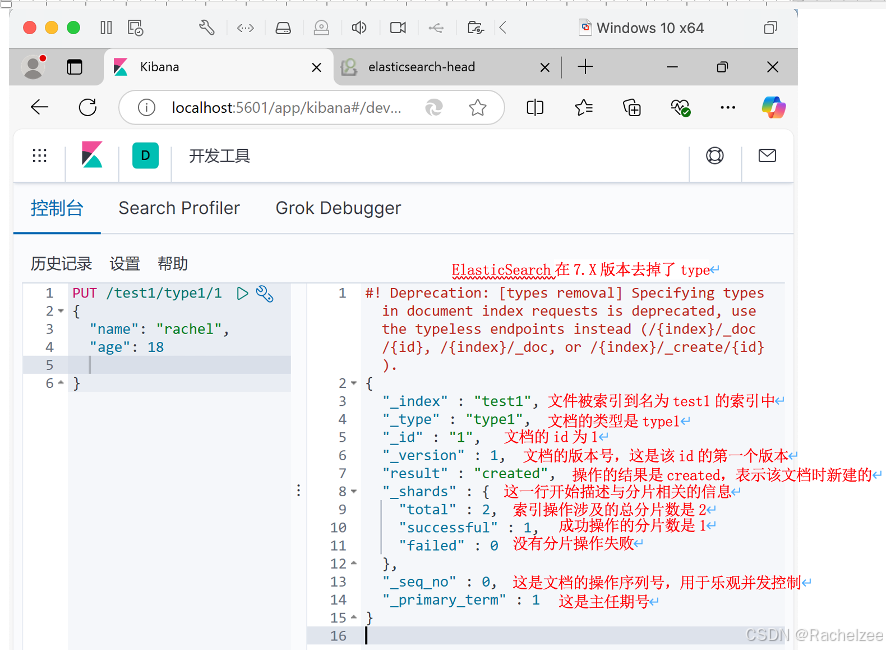
2、创建索引步骤:使用PUT命令
PUT /test1/type1/1
{
"name": "rachel",
"age": 18
}
其中解释:
|
响应体部分 |
解释 |
|
/test1/type1/1 |
请求的URL |
|
/test1 |
索引的名称 |
|
/type1 |
文档的类型 |
|
/1 |
文档的ID |
刷新页面,已成功创建test1库
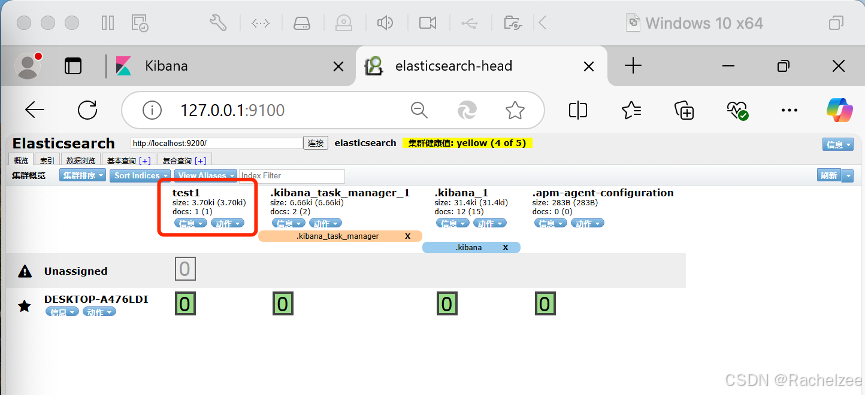
可以查看数据
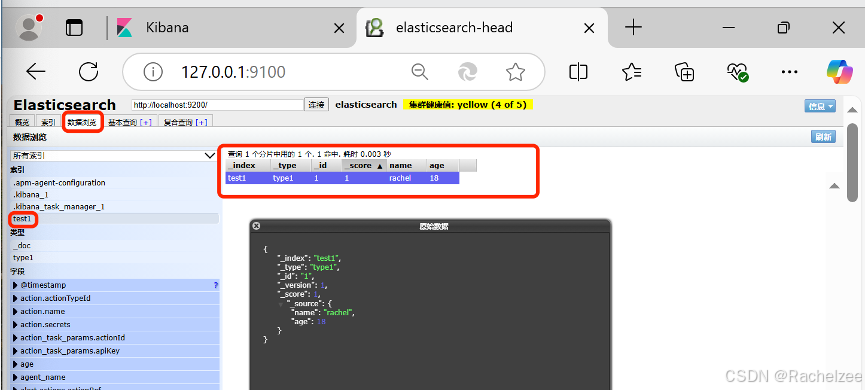
完成了自动增加索引,也成功添加了数据
3、指定字段类型
这里补充一些数据类型
字符串类型:test、keyword
数值类型:long、integer、short、byte、double、float、half float、scaled float
日期类型:date
布尔值类型:boolean
二进制类型:binary
PUT /test2
{
"mappings": {
"properties": {
"name":{
"type": "text"
},
"age":{
"type": "long"
},
"birthday":{
"type": "date"
}
}
}
}
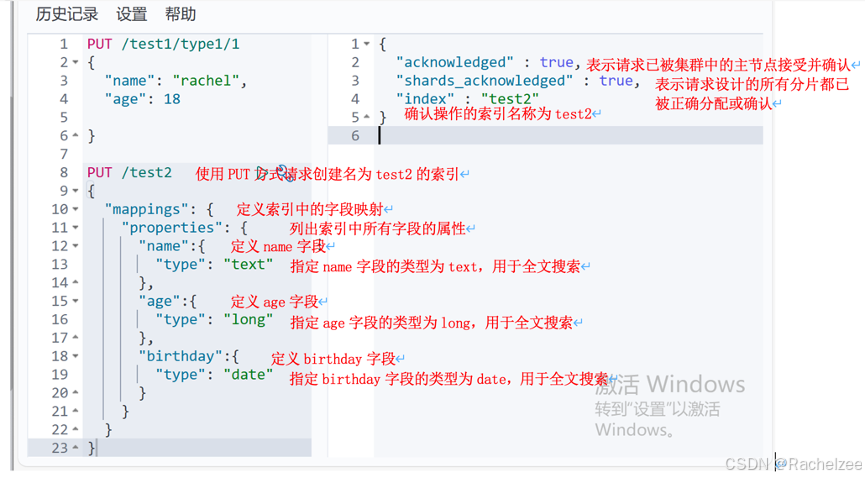
4、获得这个规则
通过GET请求获取具体的信息
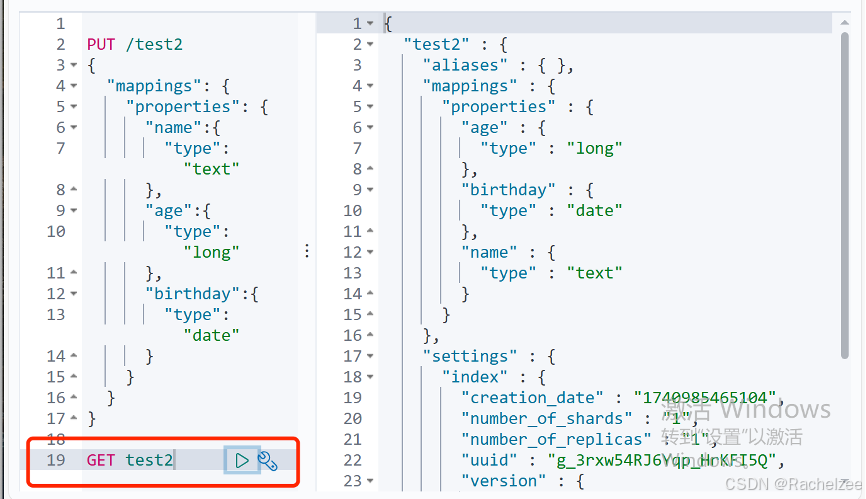
5、查看默认的信息
创建索引test3
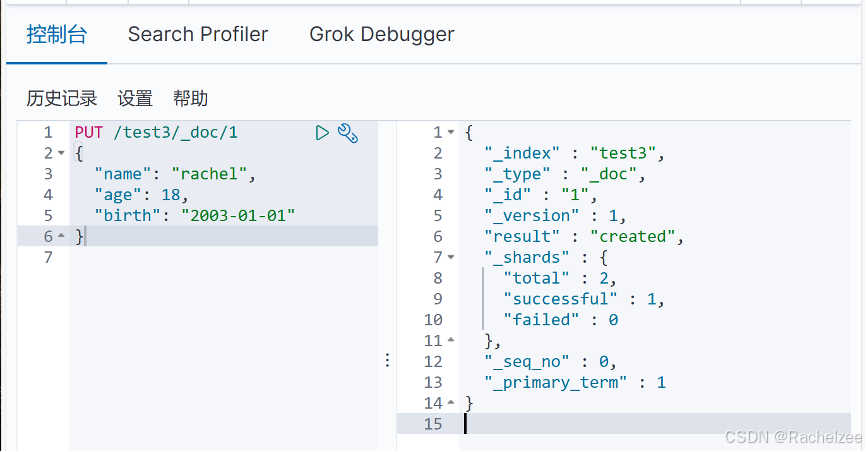
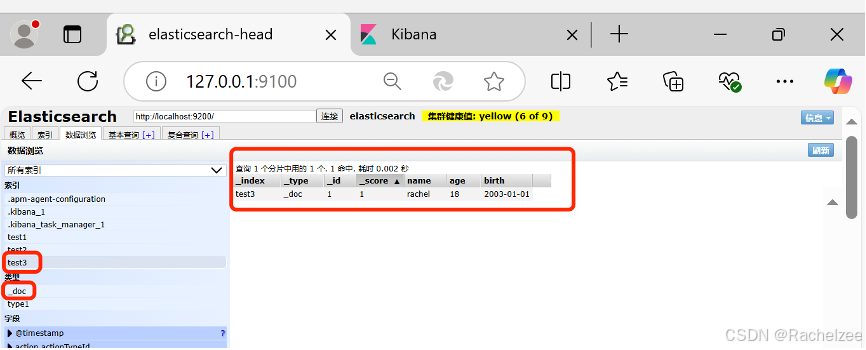
查看默认信息:GET
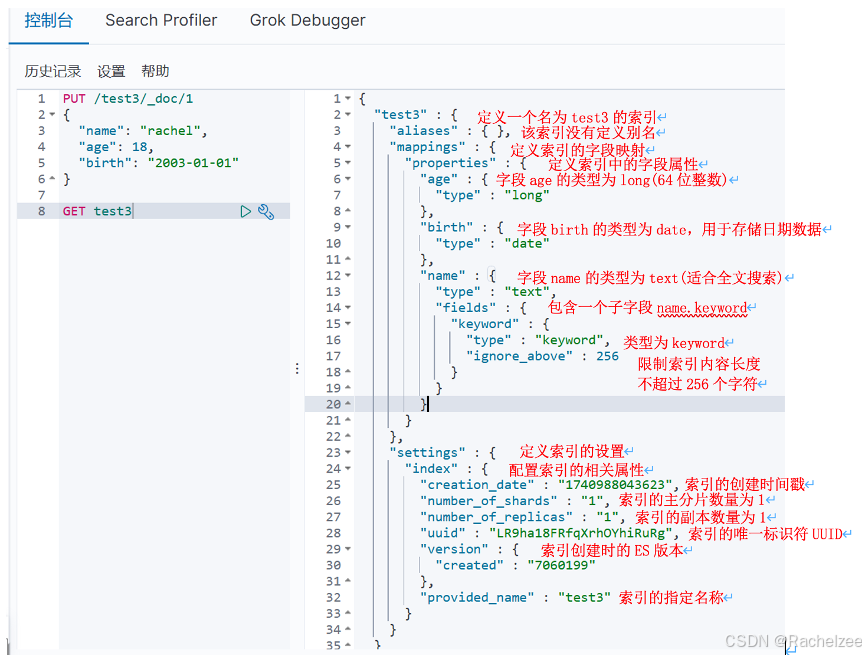
如果自己的文档字段没有制定,那么es会默认配置字段类型
6、修改索引
使用PUT提交然后覆盖,或者使用POST修改
方法一:先使用PUT覆盖
初始:
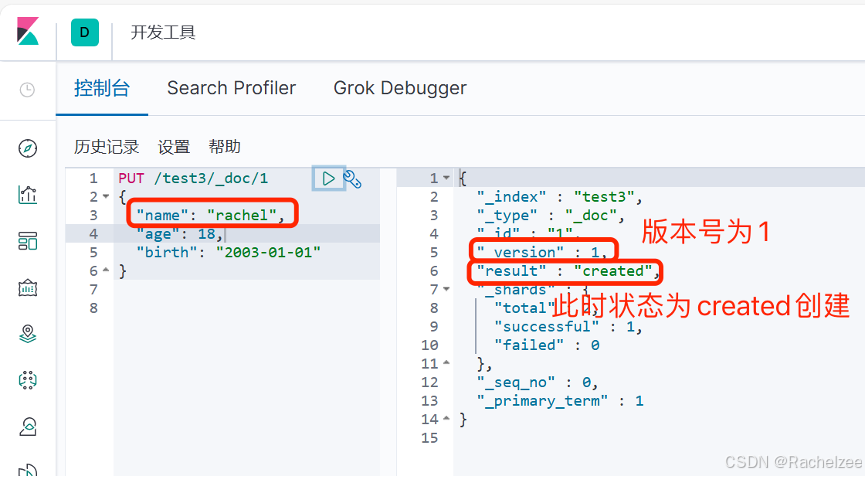
修改name字段后
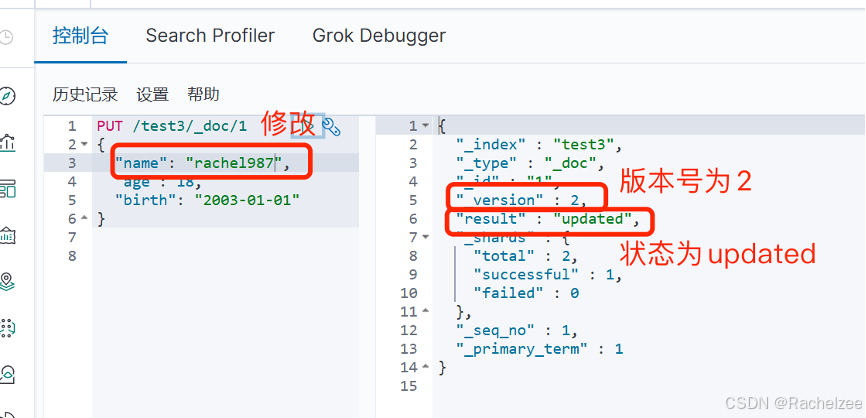
方法二:使用POST修改
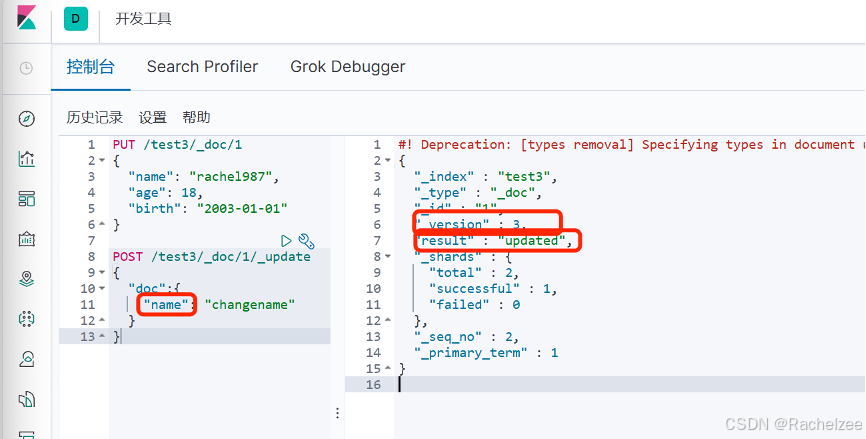
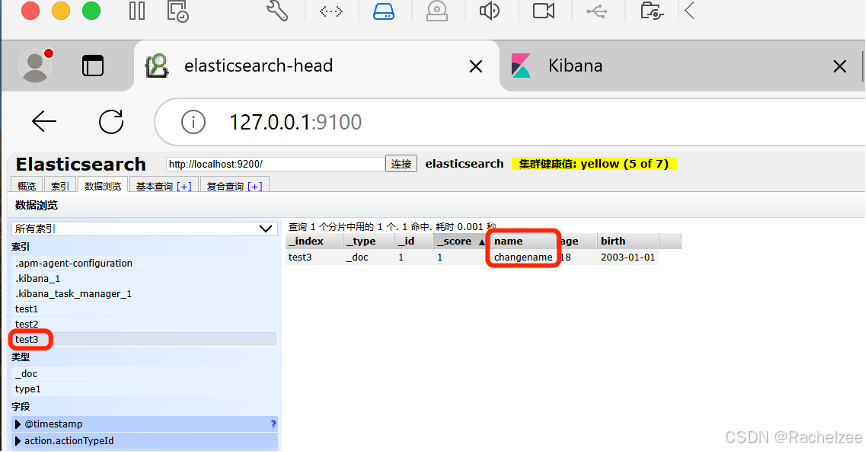
可以看到name字段已被更改
7、删除索引
删除索引使用DELETE
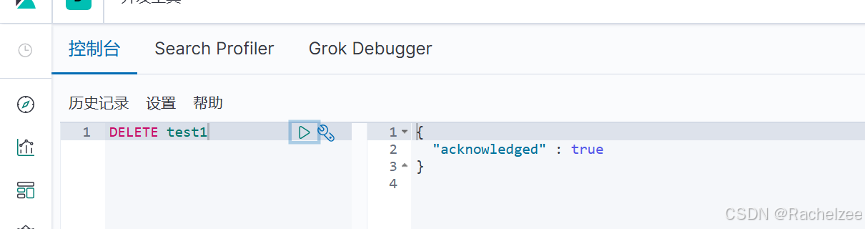
刷新索引,发现索引test1已被删除
ES中推荐大家使用RESTFUL风格

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 17
17 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)