二十张图带彻底弄懂RNN!
介绍了RNN(循环神经网络)的基础知识和应用场景。RNN作为NLP领域的重要模型,RNN通过循环连接的网络结构处理序列数据,解决了CNN难以处理变长序列的问题。文章详细解析了RNN的四种典型结构(1to1、NtoN、Nto1、1toN)及其工作原理,重点说明了隐状态h的信息传递机制。同时探讨了RNN在机器翻译、情感分析等任务中的应用,以及其存在的梯度爆炸和长距离依赖等缺陷。
0 前言
快速入门NLP,我们绕不开RNN,现有的ChatGPT、豆包以及Deepseek等大模型,如果要往前溯源的话,多少都能看到一些RNN的影子。
如果了解过(卷积神经网络,CNN)的小伙伴就会知道,CNN在图像上表现比较好,但是如果涉及到文本语音等序列信号,由于序列比较长,且长度不一,比较难直接的拆分成一个个独立的样本来通过CNN训练,此时RNN在这种任务上更具备优势了。
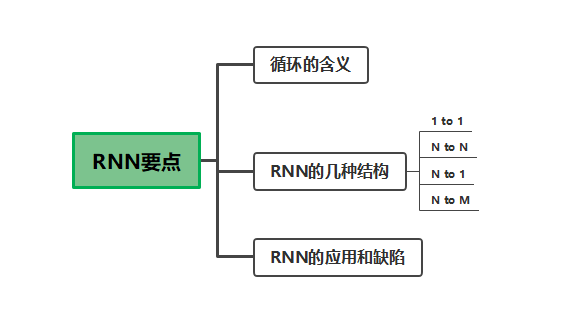
思维导图:把握以下RNN要掌握的要点,了解这些这些基础知识,加上代码实战理解,就足够了。
1 数据预处理
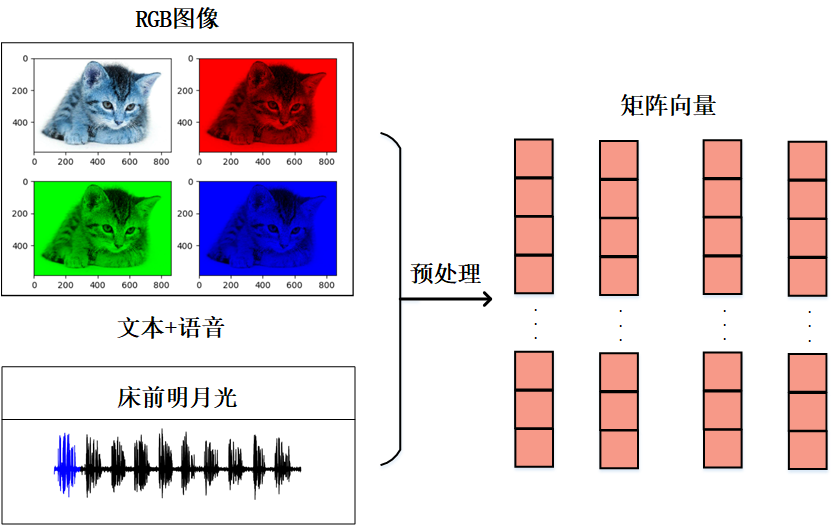
在计算机视觉中,图像我们主要分为RGB三个通道,转化为像素值去处理,在自然语言处理领域,我们更多的是面对文本、语音等序列信号。
同样都是要通过网络去训练,那么我们必然需要将信号转化为数据,这些数据在网络训练中,基本是向量或者矩阵,在这点上我认为NLP比CV入门要稍微要难一些,不过不要紧,我们学CV的时候也并不要求一定要把图像处理全部学完,NLP也是同理的。
目前NLP数据预处理的库已经非常成熟,作为初学者的我们先理解下概念,知道文本需要通过某种处理转化为数值向量,再通过网络训练就可以了,等到深入之后,我们可以再去了解什么是BOW、One-Hot以及词嵌入等概念,这次我们主要目的是学习清楚RNN的网络结构和原理,这是后续学习其他模型结构的基础。
2 RNN介绍
如果了解过CNN的小伙伴就会知道,CNN的输入大小和输出一直是一致的,比如输入的就这么多图片,输出就是预测的概率;但是RNN要解决的问题不一样,比如翻译问题,你不能确保输入的文字到底有多长,也不能确保输出的文字有多长。或者文本的情感分析,分析一段话是快乐的还是忧伤的,我们其实也没有办法去界定输入和输出的长度,此时RNN就应运而生了。
2.1 循环的含义
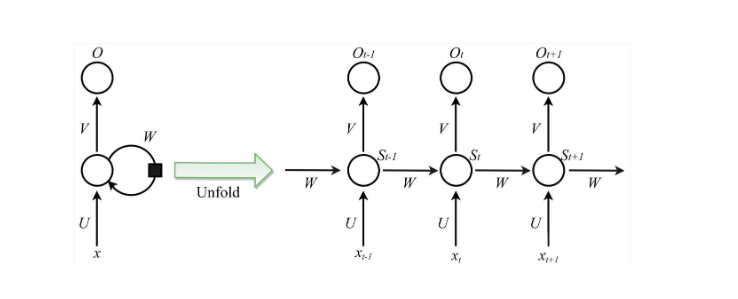
我们看下面市场上流通的RNN网络结构图,相信绝大部分人看到一开始看到RNN的网络结构图都会一脸懵逼,表示看不懂。这是啥?那个弯的箭头干啥用的?循环在哪儿?
可以看到中间有个Unfold,说明右边图是左边图的展开,右边图可以看到网络的结构都很类似,是一层又一层相同的网络结构不断重复循环连接,这里就是RNN的循环的含义所在。
2.2 RNN的几种结构
当然光看这个图,其实还是很难理解的,这里给小伙伴们说明一下它难在什么地方,主要就在于这个箭头是什么?箭头上的字母又是什么?
这种符号系统,让人看不懂RNN的网络结构图,不过没关系,我们换种视角看,从最简单的结构入手,由浅入深来了解它的结构。
2.2.1 RNN的 1 to 1
先来了解最简单的单层网络,看一下网络结构图,输入是x,输出是y,因此是1对1。
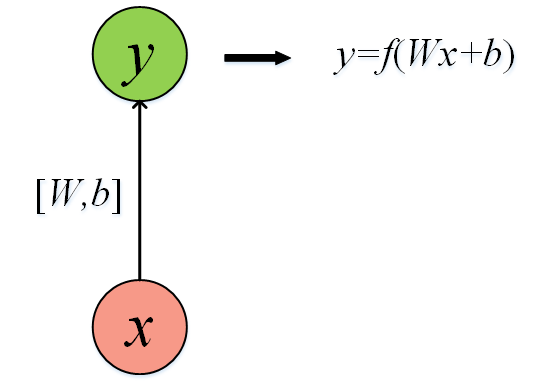
这里就要明白这个箭头的含义:每一次箭头都是在对输入x做一次线性变换(乘以矩阵W再加偏置b):也就是Wx+b,我们将结果再通过激活函数f映射。加深一下印象:碰到箭头就是做一次线性变换。
2.2.2 RNN的 N to N
刚才我们的输入是单个输出也是单个,现在我们的输入不止一个,比如翻译问题,我们有多个单词,I will go home,此时我们把I will go home转化为x1,x2,x3以及x4。那么I will go home翻译为中方是我要回家,自然就是N to N问题了。
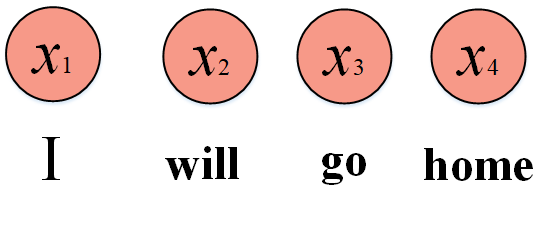
你很自然想到网络结构应该是这样的:输出和输出一一对应嘛,但是我们好像少考虑了些什么,正常来说,我们人类听到I will go几个单词后,极大概率猜测后面的单词是home,这是为什么呢?因为“回”往往是与“家”关联的,也就是说每个词与词之间包含着信息,然后我们下面的这种结构丢弃了这种关联性,网络很可能翻译成“我要回一”“我要回二”这种前前言不搭后语的句子。
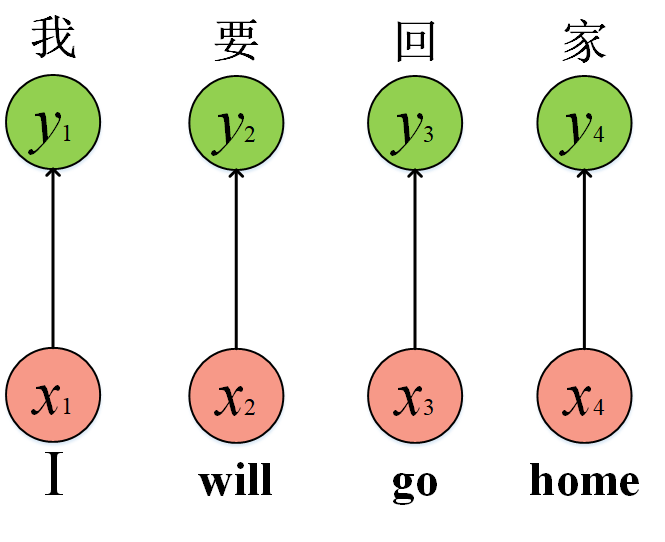
这也正是CNN的局限性,它无法很好的去解决这种序列前后信息的关联。RNN解决了这个问题,解决方法是加入“隐状态”h,说的通俗一点就是将前面单词的信息继续传递到后面的单词中,这就模拟了人类对文本处理的方式,理解上下文信息的关联性。
而目前我们画的图中信息与信息额关联依旧是孤立的,隐状态是如何将前面分词的信息传递到下一个分词呢,我们不可能直接加进去,这样信息量太大,我们人类理解一句话也不是要听清楚别人说的每一个字,此时转移矩阵就出现了,我们来看下面图就明白了。
还记得我说的吗,箭头表示什么?表示做一次线性变换。,h2由h1的变换以及x2的变换相加再加上偏置b而来,并且我们还要将结果通过激活函数映射,因此我们可以计算出:
h2=f(Ux2+Wh1+b);
而y2=f(Vh2+b);
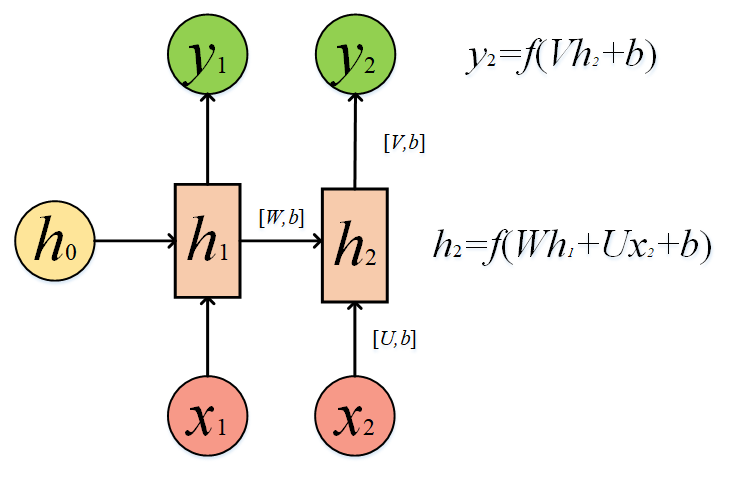
小伙伴们停下来多花几秒认真看下这个公式,是不是就理解了h2是怎么来的,y2是怎么来的。我们可以看出y2包含了h2的信息,而h2又是从h1计算来的,而h1又是从x1计算来的。这么一看,y2中就包含了x1的信息。
一环套一环,其实我们是可以写出y2关于x1的函数表达式的,但是函数嵌套太多,我们就不写出来了。总结成一句话就是,y2和x1发生了关联,有了信息流动的通道。可以从下图中箭头方向看出来。
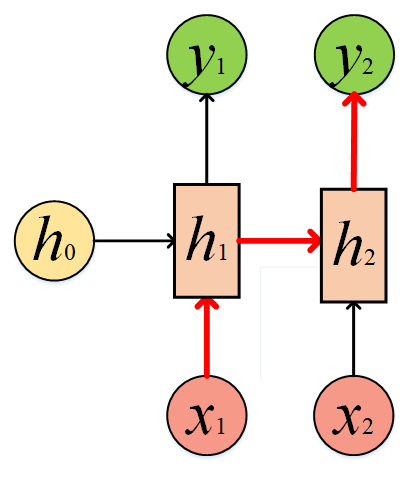
有了以上理解的基础,我们的输入不是N个吗,N个相同的结构进行叠加循环,我们就得到了RNN的经典网络结构。此时我们再回过头看开篇的那张图,此时的你应该也豁然开朗了,RNN的结构似乎也没那么难了。另外再说明一下,h0我们初始化为0。
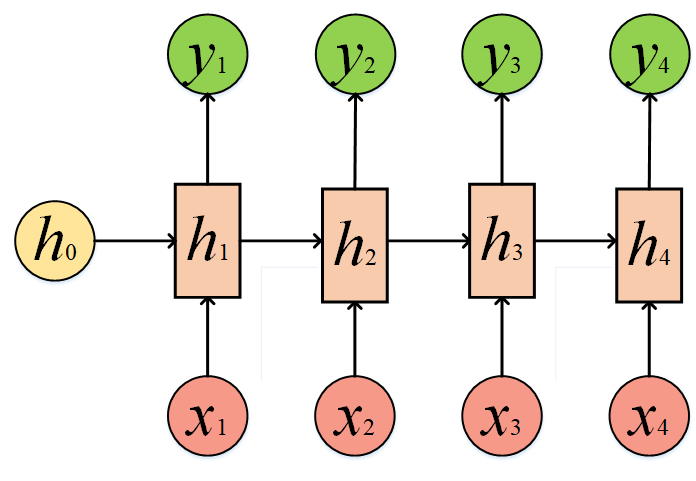
注意:
1、箭头就是在做线性变换;
2、箭头碰到一起就是相加;
3、相同的结构不断叠加:
在经过转移矩阵预测输出y1,y2,y3以及y4后,再与真实标签对比,得到损失函数,通过梯度下降和反向传播(可以参考我之前的文章,详细讲解了反向传播的原理),不断优化U、W以及偏置b等参数,最终就得到了一个可以工作的RNN了。它的输入长度是N,输出长度也是N。其实以上结构可以无限循环下去,只是没有画出来了。
2.2.3 RNN的 N to 1
再学习了N to N后,再学习其他结构那就简单多了,我们来看看N to 1的结构:
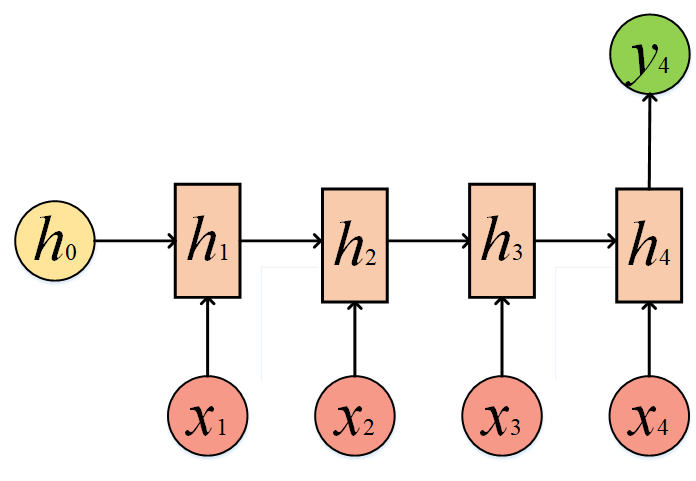
我们不去计算y1、y2和y3,只保留y4,这类问题通常为文本的情感分析,比如分析文本的情感是快乐还是伤感,本质上是一个分类问题,因此我们针对y4的结果其实是对h4进行一个softmax的输出:
y4 = softmax(vh4+b)
2.2.4 RNN的 1 to N
这种结构事实上就是把x2、x3以及x4全部置零了,这种1 to N可以被用来给一个词,让他来造句。
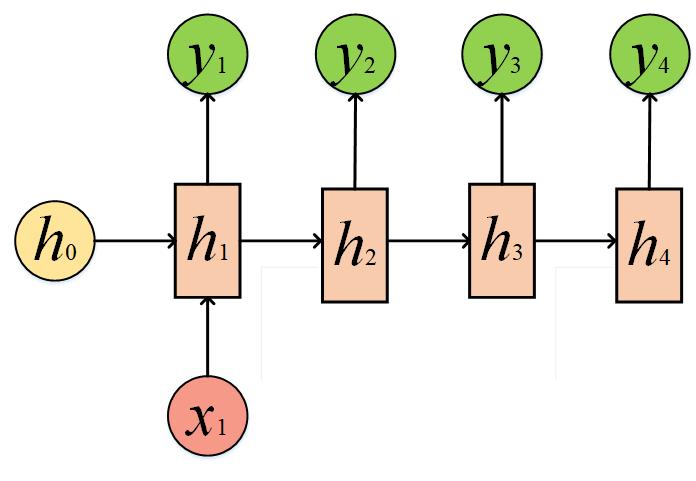
我们也可以给同一个x,某种程度上也是1 to N:
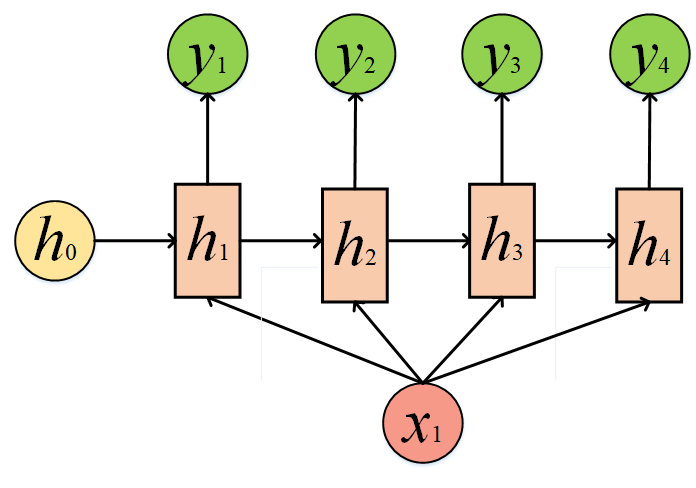
2.2.4 RNN的 N to M
N to M要复杂一些:这种结构也是Encoder-Decoder模型,也可以称之为Seq2Seq模型。在真实的环境中,我们处理的输入和输出的长度往往是不同的,比如翻译问题,源语言和目标语言的句子往往并没有相同的长度。所以,Encoder-Decoder结构先将输入数据编码成一个上下文向量c:
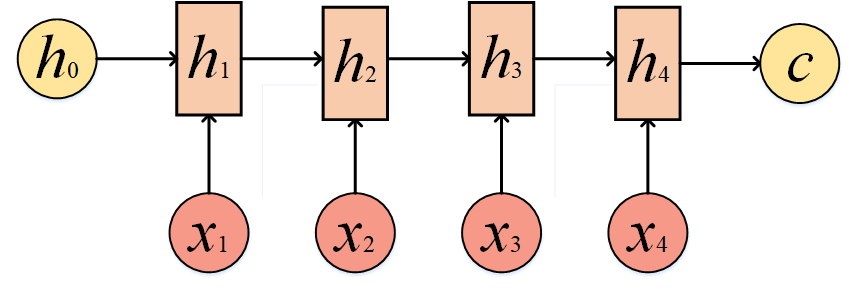
拿到c之后,就用另一个RNN网络对其进行解码,这部分RNN网络被称为Decoder。具体做法就是将c当做之前的初始状态h0输入到Decoder中:
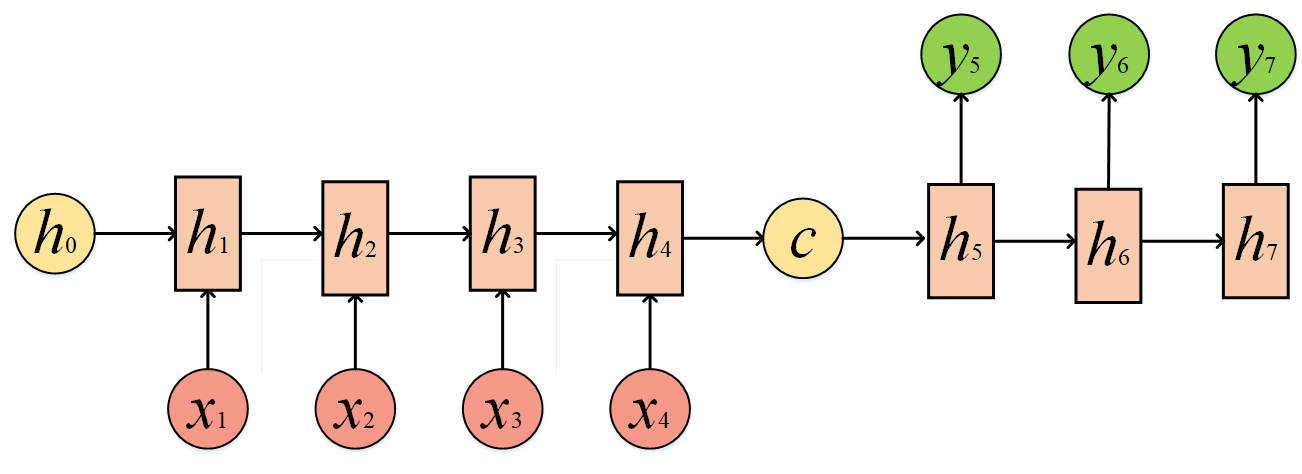
或者变个形,将c当做每一步的输入:
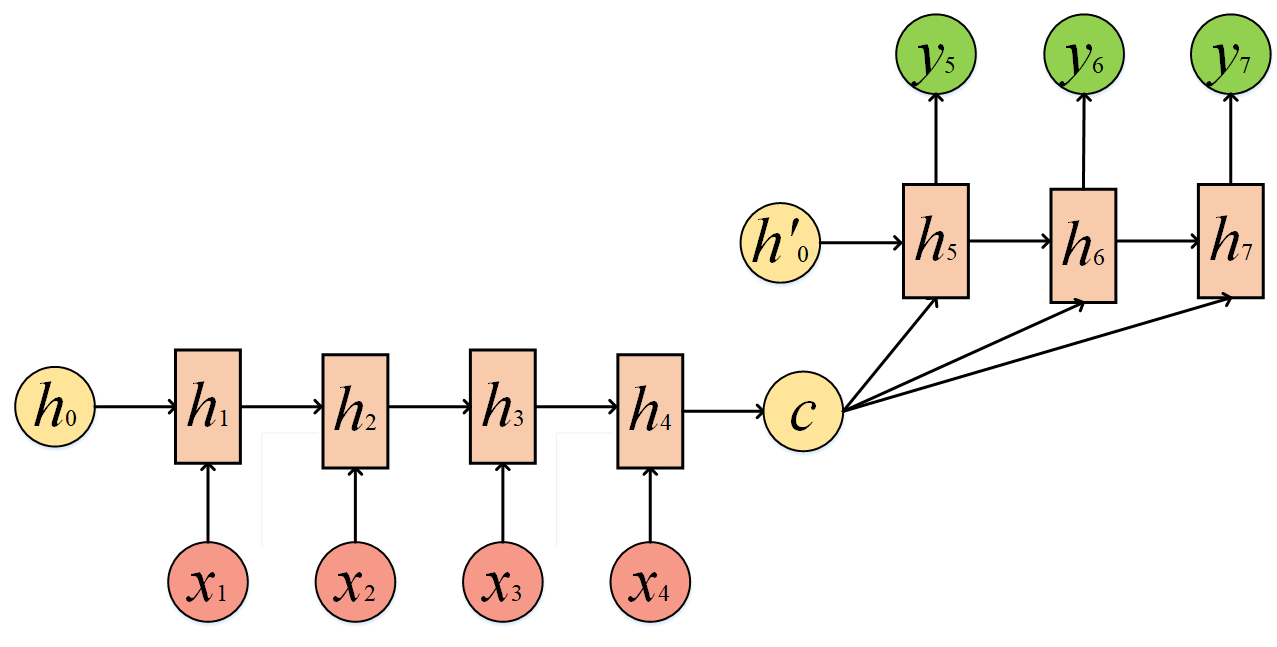
这种结构可以做的事情就多了,比如机器翻译、文本摘要、阅读理解、语音识别......
2.3 RNN的应用和缺陷
2.3.1 RNN的应用
RNN的架构非常灵活,可以配置成多种输入输出模式,以适应不同的任务: 一对一(One-to-One): 标准神经网络模式,如图像分类。实际上这不是典型的RNN应用。 一对多(One-to-Many): 单一输入,序列输出。
-
例如:图像字幕生成(输入一张图片,输出一句描述性文字)。 多对一(Many-to-One): 序列输入,单一输出。
-
例如:文本情感分析(输入一个句子,输出“正面”或“负面”情感);时间序列分类。 多对多(Many-to-Many):
- 同步多对多: 每个时间步都有输入和输出,且输入输出序列等长。
-
例如:视频帧级别的分类(给每一帧打标签)。 异步多对多(编码器-解码器): 输入序列和输出序列长度不同。
-
-
例如:机器翻译(将一句中文编码,然后解码成一句英文);语音识别。
2.3.2 RNN的缺陷
-
梯度爆炸:由于RNN链路比较长,因此网络非常容易出现梯度消失或者梯度爆炸。
-
长距离以依赖:当链路太长时,前面词的含义早已经模糊不清了,因此在长语句的任务上表现不好
解决这个缺陷,就是LSTM的任务了,我们下篇文章见。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 17
17 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)