突破分割边界!多模态大模型X-SAM:从 “分割万物” 到 “任意分割”,实现全场景图像分割统一
突破分割边界!多模态大模型X-SAM:从 “分割万物” 到 “任意分割”,实现全场景图像分割统一
《博主简介》
小伙伴们好,我是阿旭。
专注于计算机视觉领域,包括目标检测、图像分类、图像分割和目标跟踪等项目开发,提供模型对比实验、答疑辅导等。
《------往期经典推荐------》
二、机器学习实战专栏【链接】,已更新31期,欢迎关注,持续更新中~~
三、深度学习【Pytorch】专栏【链接】
四、【Stable Diffusion绘画系列】专栏【链接】
五、YOLOv8改进专栏【链接】,持续更新中~~
六、YOLO性能对比专栏【链接】,持续更新中~
《------正文------》

一、研究背景
- 现有模型局限
- 大语言模型(LLMs):具备强大的通用知识表征能力,但在像素级感知理解上存在固有缺陷,无法直接处理图像分割等需像素级分析的任务。
- 分割任意事物模型(SAM):虽在视觉提示驱动的图像分割领域有显著进展,但存在多掩码预测能力弱、类别特异性分割表现不足、无法整合所有分割任务于统一架构等问题。
- 现有多模态大语言模型(MLLMs):多局限于生成文本输出,难以应对图像分割这类需像素级理解的视觉任务,且多数相关研究仍局限于特定任务,缺乏通用性。
- 研究目标:构建一个统一的多模态大语言模型框架X-SAM,突破现有模型限制,将分割范式从“分割任意事物”拓展到“任意分割”,实现对多种图像分割任务的统一处理。
二、核心创新点

-
统一分割框架:提出首个能整合所有图像分割任务的多模态大语言模型架构,将通用分割、指代分割、开放词汇分割等多种任务转化为标准化分割格式,支持文本查询与视觉查询两种输入类型。
-
新分割任务:视觉接地(VGD)分割:通过交互式视觉提示(如点、涂鸦、框、掩码)分割图像中所有实例对象,为MLLMs引入视觉接地模态,增强其像素级可解释性,且支持单图像与跨图像场景。
-
多阶段统一训练策略:设计三阶段训练流程,解决多源数据训练适配问题,具体包括:
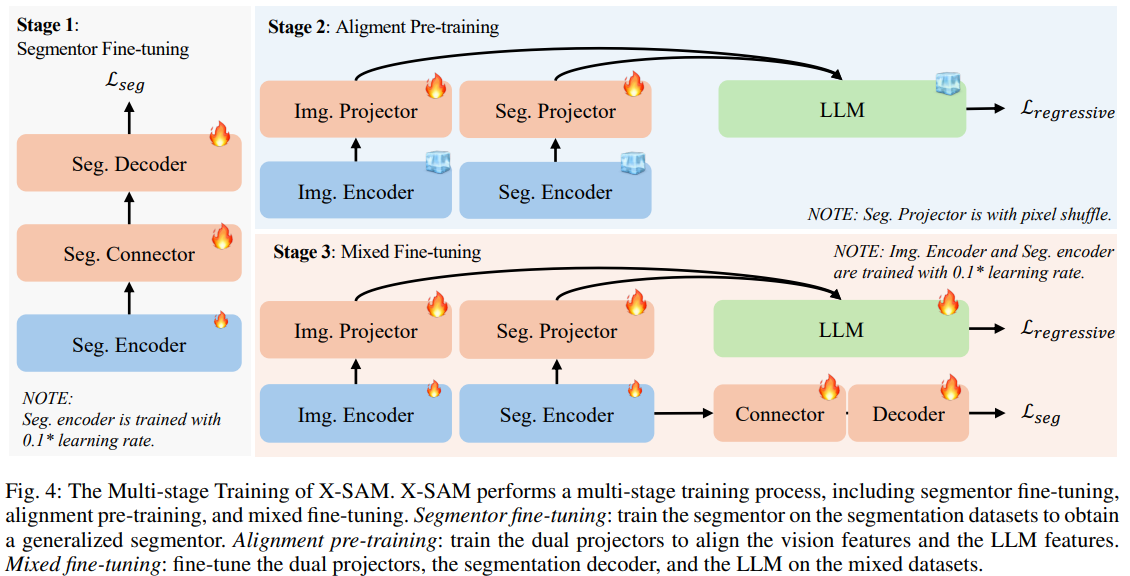
- 分割器微调阶段:在COCO-Panoptic数据集上训练分割器,优化分割解码器以实现单次前向传播分割所有对象,损失函数为分类损失、掩码损失与骰子损失之和。
- 对齐预训练阶段:在LLaVA-558K数据集上训练双投影器,使视觉特征与LLM的文本嵌入对齐,采用自回归损失函数。
- 混合微调阶段:在混合数据集(含图像对话与多种分割数据集)上进行端到端训练,对话任务用自回归损失,分割任务结合自回归损失与分割损失。
-
双编码器与双投影器设计
- 双编码器:图像编码器(采用SigLIP2-so400m)提取全局图像特征,助力图像理解;分割编码器(采用SAM-L)提取细粒度特征,支撑精准分割。
- 双投影器:通过MLP投影器将图像特征与处理后的分割特征(经像素洗牌操作降维)映射到语言嵌入空间,再与文本嵌入拼接输入LLM。
三、模型架构
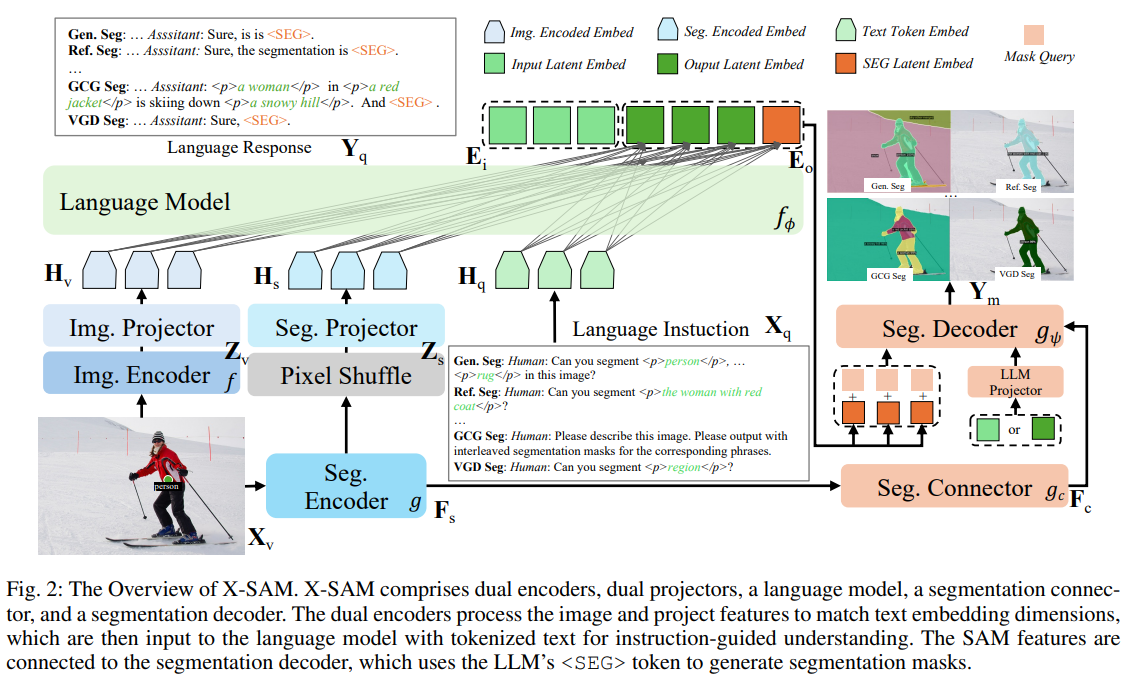
X-SAM整体架构包含五大核心模块,各模块协同实现多模态输入处理与统一分割输出,具体结构如下:
- 双编码器
- 图像编码器:采用SigLIP2-so400m,提取全局图像特征(Z_v),用于整体图像理解。
- 分割编码器:采用SAM-L,提取细粒度图像特征(Z_s),为精准分割提供细节支撑。
- 双投影器
- 对分割编码器输出的大尺寸特征,先通过像素洗牌操作降维,再经MLP投影器(w_s)映射到语言嵌入空间(H_s)。
- 图像编码器特征直接经MLP投影器(w_i)映射到语言嵌入空间(H_v),最终拼接(H_v)、(H_s)与文本嵌入输入LLM。
- 分割连接器:通过像素洗牌操作实现特征的尺度转换,将分割编码器的单尺度(1/16)特征转化为多尺度(1/8、1/16、1/32)特征,为分割解码器提供丰富的尺度信息。
- 分割解码器:替换SAM原解码器,借鉴Mask2Former设计,结合LLM输出的令牌嵌入、多尺度分割特征与掩码查询令牌,预测掩码及类别概率,同时引入潜在背景嵌入统一处理所有分割任务的“忽略”类别。
- 大语言模型(LLM):采用Phi-3-mini-4k-instruct,负责处理文本指令与视觉特征的融合理解,生成语言响应并输出令牌触发分割结果。
四、实验结果
- 实验设置
- 数据集:涵盖分割器微调(COCO-Panoptic)、对齐预训练(LLaVA-558K)、混合微调(LLaVA-1.5、COCO-Panoptic、COCO-VGD等)三大类,共涉及超20个分割数据集,其中COCO-VGD为新增VGD分割数据集。
- 评估指标:通用分割与开放词汇分割用PQ、mIoU、mAP;指代分割与推理分割用cIoU、gIoU;GCG分割用METEOR、CIDEr、AP50、mIoU;VGD分割用AP、AP50等。
- 实现细节:基于XTuner代码库,使用16张A100 GPU训练,三阶段训练的 batch size、学习率、训练轮次等参数分别优化(如分割器微调batch size=64,学习率1e-5~1e-4,共36轮)。
- 核心性能表现:X-SAM在7类分割任务中均实现当前最优(SOTA)性能,部分关键结果如下:
- 指代分割:在RefCOCO、RefCOCO+、RefCOCOg验证集上,分别比PSALM高1.5%、5.1%、10.0% cIoU;比Sa2VA-8B(更大模型)分别高3.5%、1.8%、5.1% cIoU。
- GCG分割:Val集上METEOR 15.4、CIDEr 46.3、AP50 33.2、mIoU 69.4,比GLaMM高0.2% METEOR、3.2% CIDEr,比OMG-LLaVA高3.3% AP、3.9% mIoU。
- VGD分割:在点、涂鸦、框、掩码四种视觉提示下,AP分别达47.9、48.7、49.5、49.7,远超PSALM(最高仅5.8 AP50)。
- 开放词汇分割:A150-OV数据集上PQ 20.9、AP 16.2、mIoU 28.8,优于ODISE(PQ 22.6但AP 14.4)与PSALM(PQ 13.7)。
- 消融实验验证
- 混合微调:使A150-OV的AP提升6.0%、Reason-Val的gIoU提升8.9%,证明其对跨任务泛化能力的增强作用。
- 双编码器:采用SAM分割编码器时,GCG-Val的mIoU提升4.6%、COCO-VGD的AP提升7.2%,优于Swin编码器。
- 多阶段训练:加入分割器微调(S1)使COCO-Pan的PQ提升9.3%,加入对齐预训练(S2)使对话任务准确率提升2.1%。
- 数据集平衡重采样:当超参数t=0.1时,推理分割gIoU从44.1%提升至56.6%,整体性能最优。
五、局限性与未来工作
- 局限性
- 分割数据集与对话数据集的联合训练会对部分分割任务(如COCO-Pan)性能产生轻微负面影响(PQ下降0.8%),需优化数据集混合策略。
- 模型在部分任务(如推理分割的cIoU)上未达绝对最优,统一模型的任务适配性仍需提升。
- 未来方向
- 整合SAM2模型,将X-SAM的应用场景从图像分割拓展到视频分割。
- 把VGD分割任务延伸至视频领域,引入视觉接地的时序信息,开发视频级视觉接地分割任务。
六、其他
- 代码开源:https://github.com/wanghao9610/X-SAM
- 论文地址:https://arxiv.org/abs/2508.04655
- 模型参数:总参数量约5B,兼顾性能与部署效率。
- 适用场景:涵盖通用分割、指代分割、推理分割、GCG分割、交互式分割、VGD分割等,可应用于图像编辑、视觉问答、场景理解等计算机视觉领域。
好了,这篇文章就介绍到这里,喜欢的小伙伴感谢给点个赞和关注,更多精彩内容持续更新~~
关于本篇文章大家有任何建议或意见,欢迎在评论区留言交流!

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 23
23 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)