2025年主流开源大模型的结构设计差异
2025 年的大模型们,本质依然是带各种结构增强模块的 Decoder-only Transformer。创新点主要集中在:注意力变体、MoE 设计、归一化策略、KV Cache 节省等。
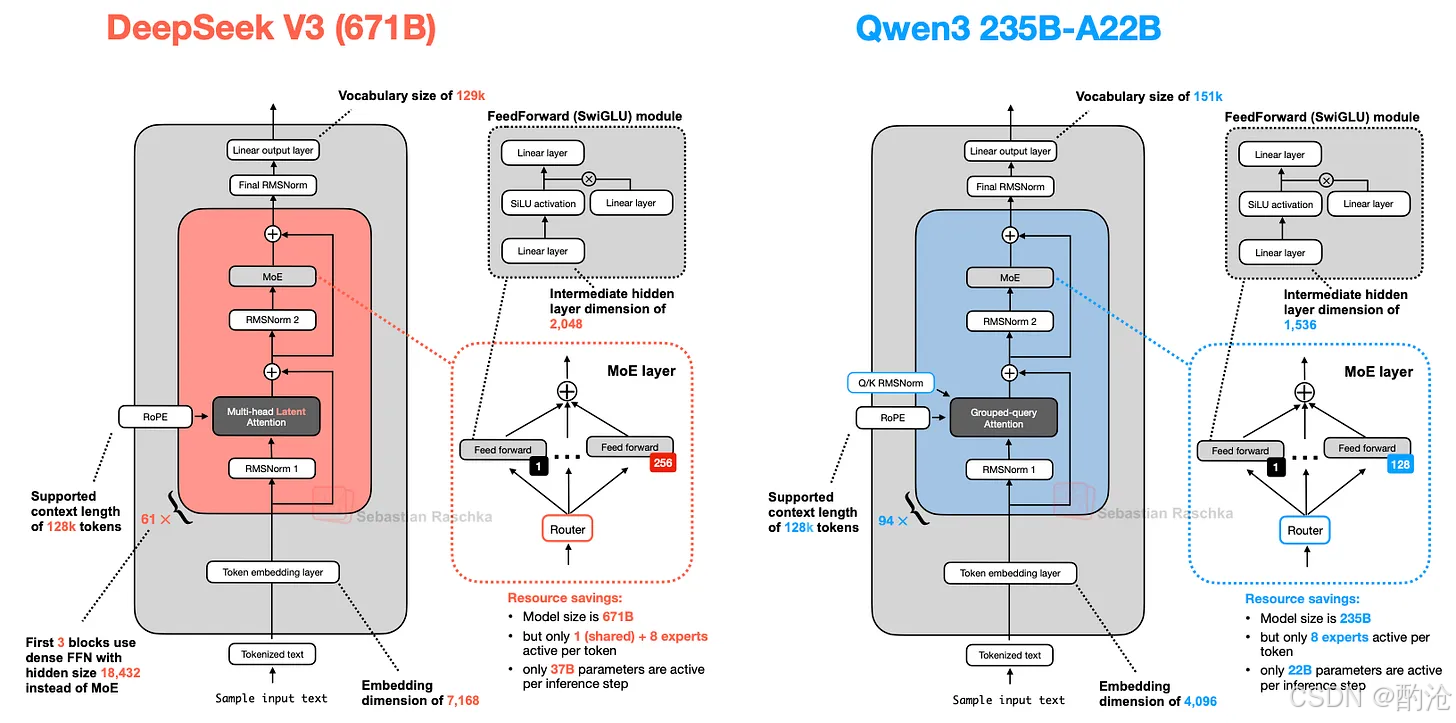
1 DeepSeek V3
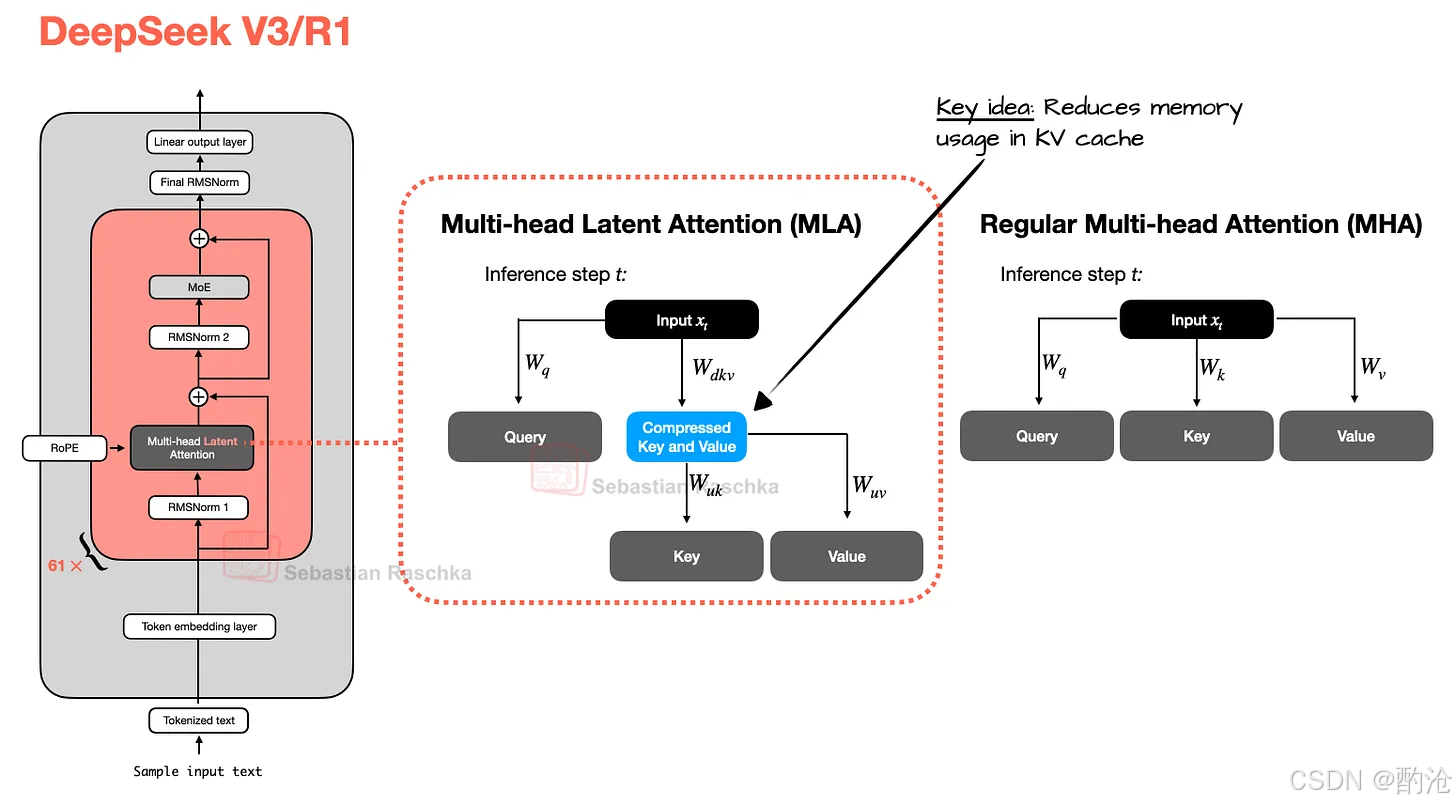
Multi-Head Latent Attention(MLA,多头潜在注意力)
不再让多个 head 共享 K/V(那是 GQA 的思路),而是:先把 K/V 压缩到低维,再存进 KV cache
-
推理时,再投影回原来维度参与注意力计算
-
多了一次矩阵乘法,但KV cache 体积明显减小
训练时,Q 也会被压缩,但推理阶段只压缩 K/V。
DeepSeek-V2 论文中做了对比:GQA 性能略逊于 MHA;MLA 不仅省 KV cache,而且建模性能反而比 MHA 还好一点
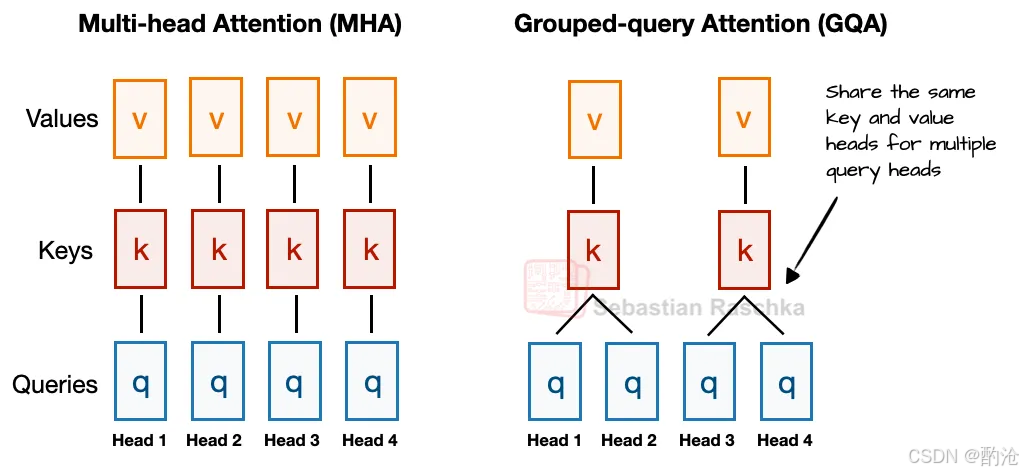
传统 MHA:每个 head 都有自己的 Q/K/V 投影
GQA:多个 head 共享 K/V,只保留更多的 Q head
-
例如 4 个 head,2 个 KV 组:head1、2 用同一组 K/V,head3、4 用另一组
-
好处:K/V 参数更少;KV cache 存储和访问更省显存;性能几乎不掉(实验表明和 MHA 差不多)
GQA 本质上是为了推理效率和显存对 MHA 的工程折中。
外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传
MLA / GQA / MHA 的本质区别
MHA:每个头都有自己的 Q/K/V,表达力强,但参数多、KV cache 大。
GQA:Q 多头,K/V 少头,多个 Q 头共用同一组 K/V。
- 优点:KV cache 减少,推理显存占用减少,算力下降,性能基本不变。
- 代价:结构简单,但从表达力角度看,K/V 的多样性降低。
MLA:
- 每个 token 的 K/V 向量先被压缩到潜在低维空间,存储的就是这个压缩表示;
- 用到时再反投影成完整 K/V。
- 优点:KV cache 从宽向量变成瘦向量,极度节省显存;同时由于投影也是可学习的,整体表达力甚至能超过原始 MHA。
Mixture-of-Experts(MoE,专家混合)
Transformer 的 FFN(前馈层)通常占了大部分参数。MoE 的核心想法是:用多个专家 FFN替换一个 FFN,但每个 token 只激活其中一小部分专家。
具体到 DeepSeek-V3:每个 MoE 层里有 256 个专家;总参数:671B(6710 亿);但推理时:每个 token 只用 1 个 shared expert + 8 个由 router 选择的专家,实际被激活的参数约 37B
Shared Expert:一个永远激活的共享专家
好处:常见模式由共享专家统一记忆;其他专家可以更专注于专项领域模式;DeepSpeedMoE 和 DeepSeekMoE 都发现:加共享专家 → 性能提升
2 OLMo 2
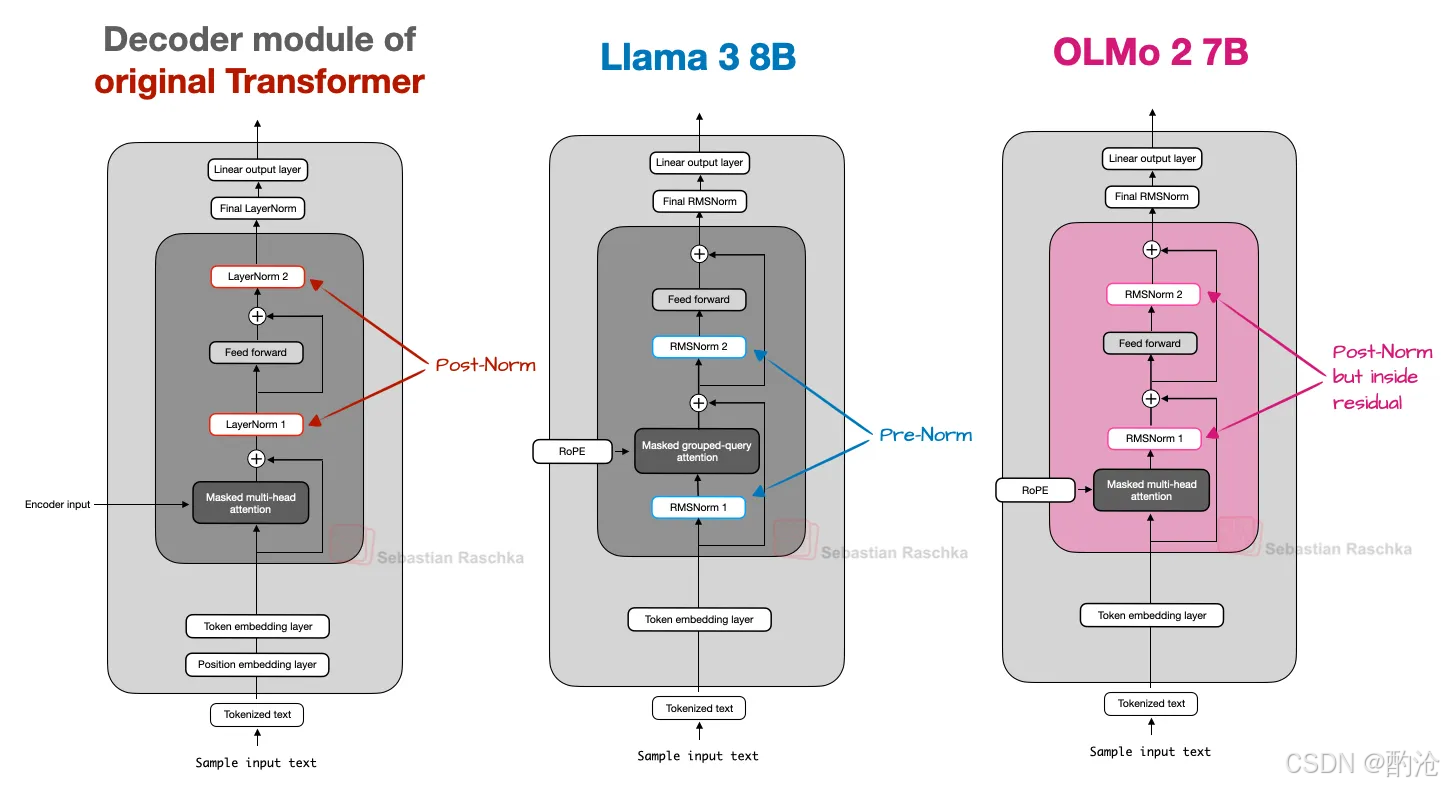
归一化层的位置(Pre-Norm vs Post-Norm 的变体)
Transformer 里归一化有几种典型位置:
-
原始 Transformer(Attention is All You Need):Norm 在 Attention + FFN 之后(Post-LN)
-
GPT / Llama 系:Norm 在 子层之前(Pre-LN)
Xiong 等人在 2020 年证明:Pre-LN:梯度更稳定,训练更容易,不太依赖精细的 warmup 策略。OLMo 2 做了一个有趣的选择:
-
使用 RMSNorm
-
但采用了一种改良版的 Post-Norm:Norm 放在 Attention/FFN 后面;但仍然保留在 residual 分支内部。
他们发现这样的布局,在他们的训练设置下,稳定性更好。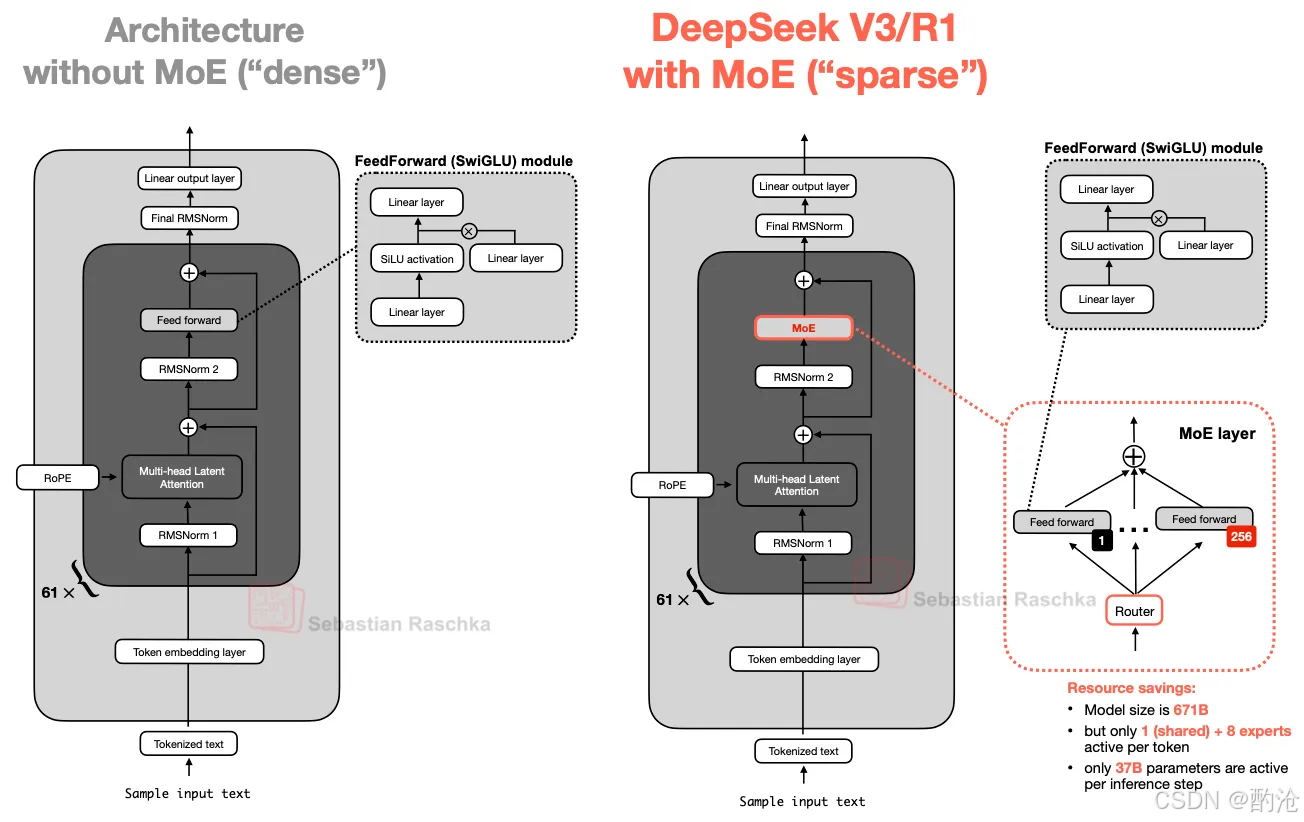
QK-Norm:对 Q、K 单独做 RMSNorm
在 Attention 里,对 Q、K 向量再各自做一次 RMSNorm。放置位置:
- 线性层算出 Q/K 向量
- 先做 RMSNorm
- 再做 RoPE(旋转位置编码)
- 再做注意力点积
目的:
- 稳定注意力分布
- 控制 Q/K 的尺度,避免个别 token 的 attention score 爆炸或塌缩
- 与Post-Norm + QK-Norm组合起来,整体训练损失更平滑
3 Gemma 3
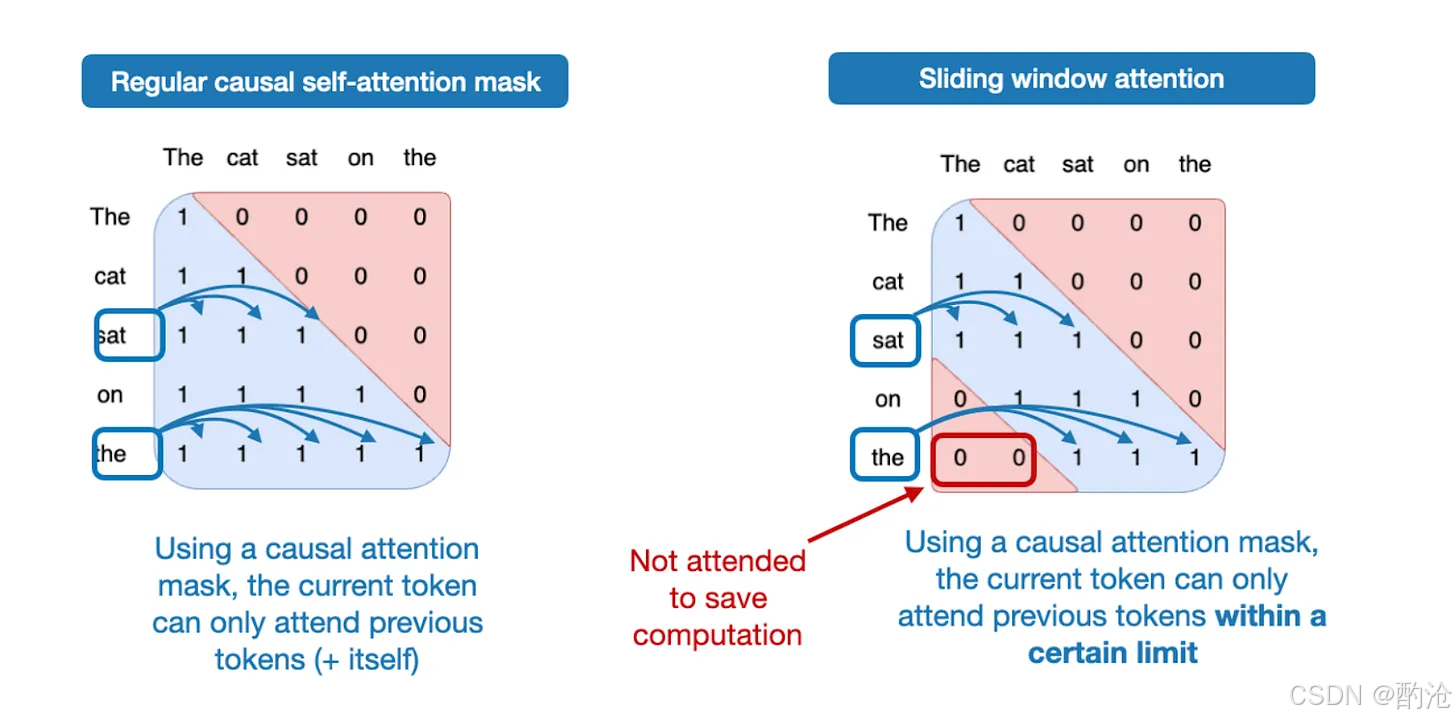
滑动窗口注意力(Sliding Window Attention)
-
普通自注意力:全局 Attention,每个 token 可以访问序列中所有其他 token
-
滑动窗口注意力:局部 Attention,每个 token 只关注自己附近的一段窗口,类似一块滑动的窗口围绕当前 query
Gemma 3 的做法:每 5 层用局部(滑动)注意力,配 1 层全局注意力。窗口缩小到 1024。注意力类型:GQA + Sliding Window
在语言任务里,一个重要假设是:很多 token 的有效依赖其实是局部的,不需要每一层都对全序列全局感知。
Gemma 2/3 的设计逻辑就是:不完全放弃全局注意力(每隔几层保留一层),大多数层只看局部窗口 → 显存/速度收益。这类设计对长上下文对话、代码阅读非常有意义。
4 Qwen3
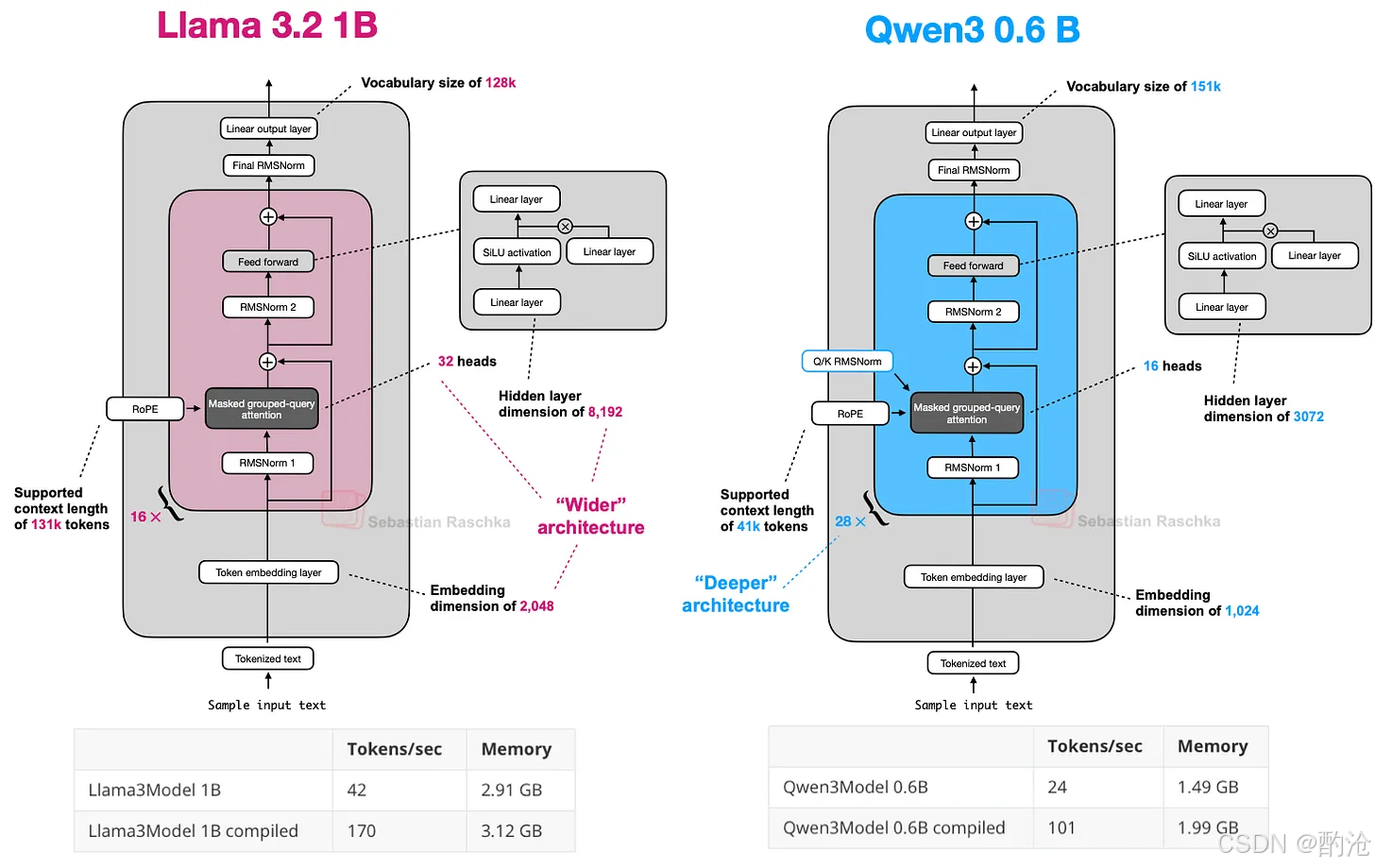
Qwen3 稠密系列:0.6B / 1.7B / 4B / 8B / 14B / 32B。其中 0.6B 非常小,适合本地跑和教学用。
对比 Llama 3 1B:
-
Qwen3 0.6B:更深(层数多)、更窄(每层宽度小、头少)
-
Llama 3 1B:更浅、但更宽
-
Qwen3 0.6B 虽然更小,但因为深度和良好的优化,实际表现相当实用
-
这也体现了深 vs 宽架构调优的一个维度:深:收敛稳定性难一点,但表达层次感强;宽:推理更快、更利于并行,但可能需要更强正则和稳定策略
Qwen3 的 MoE 型号:30B-A3B(3B 活跃参数);235B-A22B(22B 活跃参数)
Dense vs MoE 的产品线逻辑:
-
Dense:结构简单、调优容易、部署适配广;适合 finetune、多场景推理
-
MoE:训练时容量大,推理时活跃参数少 → 高性价比;适合大规模在线服务(节省资源)
与 DeepSeek-V3 对比:
-
整体结构非常像(Decoder-only Transformer + MoE + GQA/MLA + RoPE + RMSNorm)
-
不同点:Qwen3 235B-A22B 取消了 shared expert。可能在提高专家个数到 8 后,共享专家带来的收益不明显,反而复杂化推理优化
5 GPT-OSS
OpenAI 在 2019 年 GPT-2 之后久违地重新开放权重:gpt-oss-20b 和 120b。架构上:
-
Decoder-only Transformer
-
MoE(20b 是稠密,120b 是 MoE)
-
GQA + Sliding Window(隔层使用)
-
RMSNorm + RoPE + QK-Norm(类似前文)
与 Qwen3 30B-A3B 对比时,有两个观察维度:
1 宽 vs 深
Qwen3:48 层,隐藏维 2048 → 深而窄
gpt-oss:24 层,隐藏维 2880 → 浅而宽
宽模型:推理更快(并行友好),但显存更高;深模型:表达层次丰富,但训练稳定性更难,需要更细的归一化/优化设计。
2 专家数量:少大专家 vs 多小专家
gpt-oss:32 专家,激活 4 个(大专家)
Qwen3:128 专家,激活 8 个(小专家)
DeepSeekMoE 的研究趋势:多小专家更好,但 OpenAI 在 gpt-oss 中仍然采用较少的大专家,可能是工程与推理系统权衡。
有两个复古但有意思的点:
1 Attention 线性层里重新引入 bias 项(GPT-2 时代常见,后面大多去掉)
理论和实验都表明:对性能影响很小,更多是代码风格选择。
2 Attention Sink(注意力水库)
设计一类总是能被注意到的(高 attention score)位置
目的是在长上下文时,始终有一块区域存储全局信息
gpt-oss 采用的是每个 head 的 learnable bias logit来模拟 sink,而不是改 token 序列本身。
6 思想总结
1 2025 年的大模型仍然是Decoder-only Transformer 主体 + 一堆结构插件
主干结构没变:自回归、因果 mask、残差、归一化、注意力 + FFN。
创新集中在:注意力变体(GQA、MLA、滑动窗口、线性注意力)、MoE、归一化布局、位置编码、KV cache 压缩。
2 MoE 已经从研究玩具变成旗舰模型标配
DeepSeek-V3、Llama 4、Qwen3-MoE、GLM-4.5、MiniMax-M2、Grok 2.5 等大模型都采用 MoE。
总参数巨大(几百 B 到 1T),但活跃参数控制在 10B–40B 级别。
是否用 shared expert、专家数量与大小的 trade-off,成为各家架构的关键不同点。
3 KV cache 优化是架构设计的重要驱动力
MLA:压缩 K/V → 显存收益显著 GQA:共享 K/V → 减少 KV head 数
Sliding Window:限制每层可见上下文窗口 → KV cache 成本随 n·w 而不是 n² 增长
线性注意力(DeltaNet、KDA 等):试图从根本上把复杂度变成 O(n)。
4 归一化(Norm)的位置与形式是训练稳定性工程的核心
Pre-Norm vs Post-Norm vs Pre+Post(Gemma 3)
QK-Norm / per-head QK-Norm / zero-centered RMSNorm
这些看起来很小,但直接决定:大模型能不能稳稳训到收敛。
5 位置编码从必须显式注入到可以部分/甚至不注入
RoPE 成为主流,相对位置编码的标准方案。Partial RoPE:只对部分维度加旋转,缓解极长上下文时的过度旋转。
NoPE(SmolLM3、Kimi Linear):探索完全不显式注入位置,依赖结构+训练学习顺序。
6 深 vs 宽、少大专家 vs 多小专家,不再是理论,而是工程与评测问题
宽:推理快、显存大 深:表达力强、训练不稳定
MoE:多小专家 + shared expert 越来越被证明有优势
+Post(Gemma 3)
QK-Norm / per-head QK-Norm / zero-centered RMSNorm
这些看起来很小,但直接决定:大模型能不能稳稳训到收敛。
5 位置编码从必须显式注入到可以部分/甚至不注入
RoPE 成为主流,相对位置编码的标准方案。Partial RoPE:只对部分维度加旋转,缓解极长上下文时的过度旋转。
NoPE(SmolLM3、Kimi Linear):探索完全不显式注入位置,依赖结构+训练学习顺序。
6 深 vs 宽、少大专家 vs 多小专家,不再是理论,而是工程与评测问题
宽:推理快、显存大 深:表达力强、训练不稳定
MoE:多小专家 + shared expert 越来越被证明有优势

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐



 30
30 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)