规模架构设计:支撑亿级数据与千万并发
本文系统解析了亿级规模架构设计全链路,针对数据量、并发量和节点规模三大核心挑战,重点介绍了多引擎协同存储架构(TDSQL+Elasticsearch+ClickHouse)、四级缓存与流量治理机制、分布式协调与云原生编排等关键技术方案~
摘要
本文从 “规模架构核心挑战→关键技术→实战落地” 全链路拆解亿级规模架构设计。涵盖数据分片、负载均衡、分布式协调、全局管控四大核心模块,配套 TDSQL 分布式分区、ZooKeeper 分布式锁、雪花算法 ID 生成等生产级代码与配置说明,助力 Java 后端工程师、架构师构建支撑 “亿级数据存储、千万并发承载” 的稳健架构,从容应对节点扩容、数据倾斜等规模难题。
一、规模架构的核心挑战:三大维度的压力突破
规模架构的本质是在 "数据量大、并发高、节点多" 的三重压力下,保障系统的高性能、高可用与可扩展性。结合商品中台等实战项目,核心挑战主要体现在三个层面:
1. 数据规模挑战:亿级数据的存储与查询难题
某电商商品中台商品数据量突破 80 亿条,日均处理商品变更事件超 10 亿次。此时单库单表的存储模式完全无法满足需求,核心痛点包括:
- 单表数据量超千万后,查询性能呈指数级下降;
- 海量数据的写入峰值导致数据库 IO 瓶颈;
- 多维度交叉查询(如渠道 + 品类 + 会员等级)需扫描全量数据,响应时间长达分钟级。
2. 并发规模挑战:千万级请求的承载与分发
电商大促场景下,商品详情查询、订单创建等核心接口的并发峰值可达千万级。若缺乏有效的流量治理机制,将面临:
- 瞬时流量冲击导致服务集群雪崩;
- 热点数据查询(如爆款商品)引发缓存穿透与 DB 压力突增;
- 跨服务调用链过长,并发场景下超时率飙升。
3. 节点规模挑战:百台级集群的管理与容错
商品中台微服务节点突破 100+,ClickHouse、Redis 等中间件集群节点达数十台。此时集群管理的核心痛点是:
- 节点故障概率增加,需快速感知与自动恢复;
- 数据分片不均导致的 “数据倾斜” 问题;
- 跨节点调用链路复杂,故障定位难度指数级提升。
4. 规模架构的三大设计原则
- 分片存储原则:将海量数据按规则拆分至多节点,避免单节点存储压力(如按用户 ID 哈希分片);
- 负载均衡原则:请求均匀分发至集群节点,避免单点过载(如网关层加权轮询路由);
- 容错自愈原则:节点故障时自动隔离、数据自动迁移,保障系统可用性(如副本机制、故障自动切换)。
二、规模架构关键技术:从单点优化到全局协同
针对上述挑战,需构建 “数据分层存储 + 分布式协调 + 弹性伸缩” 的技术体系,以下是经过实战验证的核心技术方案,配套架构图及详细说明:
1. 数据规模突破:分布式分区与多引擎协同
面对 80 亿条商品数据的存储需求,单一数据库无法支撑,需采用 “核心数据 + 搜索数据 + 分析数据” 的多引擎存储架构,形成互补协同的存储体系。
(1)多引擎数据存储架构图
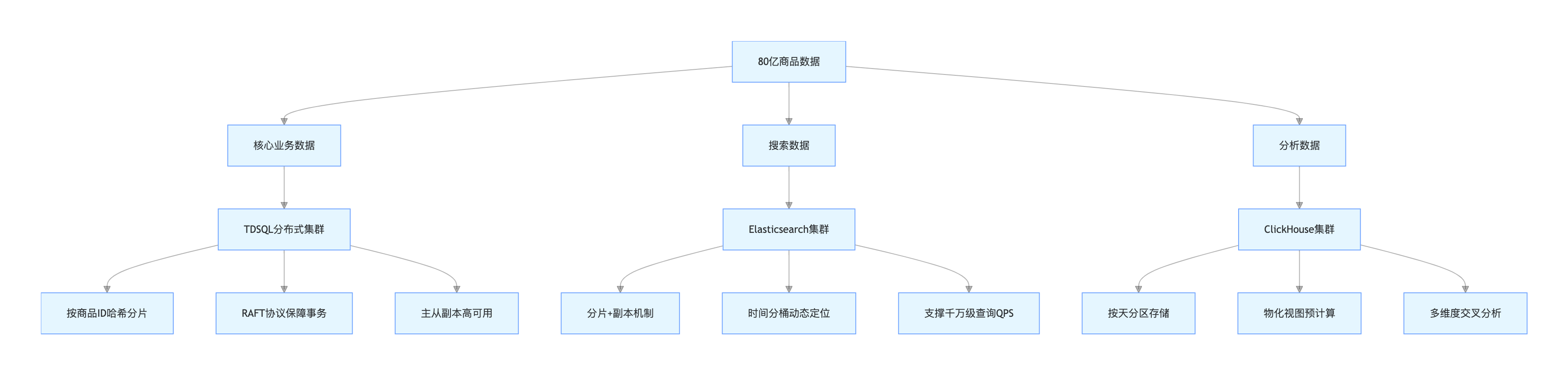
架构图说明:该架构实现数据按 “业务场景” 分层存储 ——TDSQL 承载核心交易数据,保障事务一致性;Elasticsearch 支撑商品搜索场景,提升查询效率;ClickHouse 负责数据分析,满足多维度统计需求。各引擎通过数据同步工具实现数据实时流转,确保数据一致性,同时各自发挥技术优势,解决单一存储引擎的能力短板。
(2)核心技术落地细节
- 核心业务数据(TDSQL):采用 TDSQL 分布式分区,数据库内核原生支持数据分片,物理上多节点存储,逻辑上呈现为单表,用户无感知。基于 RAFT 协议保障分布式事务的 ACID 特性,解决分库分表带来的一致性难题,同时支持线性水平扩展,新增节点自动平衡数据。配套分区表创建 SQL 如下:
-- 商品核心表:按商品ID哈希分16个分区,单分区数据量控制在500万内
CREATE TABLE product_core (
product_id BIGINT NOT NULL,
product_name VARCHAR(100) NOT NULL,
price DECIMAL(18,2) NOT NULL,
category_id BIGINT NOT NULL,
create_time DATETIME NOT NULL
) ENGINE=InnoDB
PARTITION BY HASH(product_id)
PARTITIONS 16; -- 分片数量,建议16-64个- 搜索数据(Elasticsearch):通过分片与副本机制,支撑千万级查询 QPS。针对深度分页性能问题,采用 “时间分桶动态定位算法”,将查询耗时从秒级降至 100ms 内,适配商品列表页、搜索结果页等高频查询场景。
- 分析数据(ClickHouse):按 “天” 分区存储,结合物化视图预计算复杂指标,支撑 5000+QPS 的多维度交叉分析,查询延迟控制在 200ms 内,满足商品销售统计、用户行为分析等业务需求。
2. 并发规模突破:多级缓存与流量治理
通过 “全链路缓存 + 精细化流量管控”,实现千万级并发请求的平稳承载,避免系统被峰值流量击垮。
(1)多级缓存与流量分发架构图
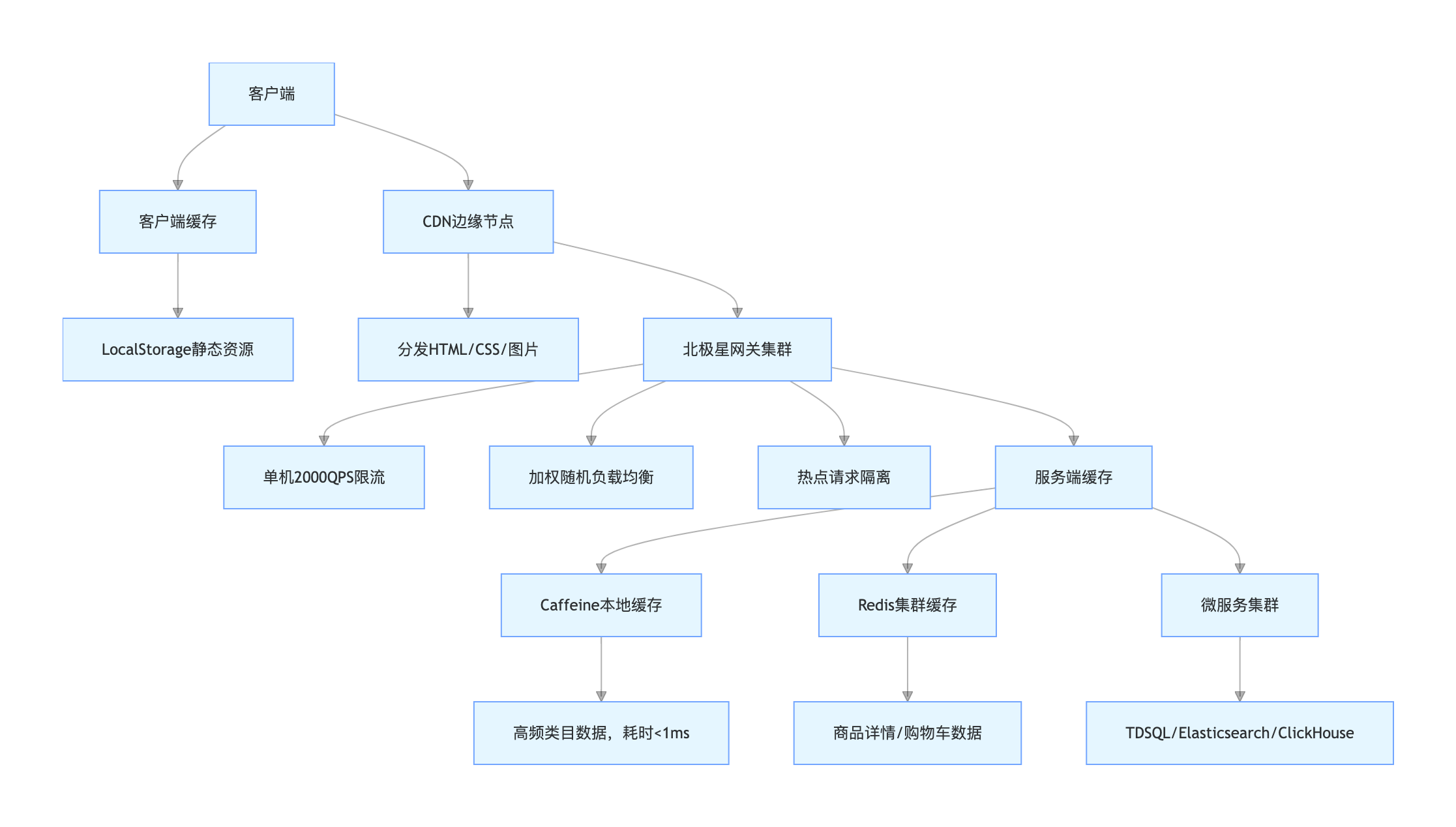
架构图说明:架构从 “客户端→CDN→网关→服务端” 构建四级缓存与流量治理体系。客户端与 CDN 拦截 80% 静态资源请求,减少源站压力;网关层实现限流、负载均衡与热点隔离,过滤无效流量并均匀分发请求;服务端通过本地缓存 + 分布式缓存,加速核心数据访问,最终实现全链路流量减压,支撑千万级并发。
(2)核心技术落地细节
- 多级缓存架构:客户端缓存(浏览器 LocalStorage)+CDN 缓存(静态资源)+ 服务端本地缓存(Caffeine)+ 分布式缓存(Redis),形成全链路加速。同时通过空值缓存 + 布隆过滤器解决缓存穿透,过期时间随机化避免缓存雪崩,延迟双删保障缓存与 DB 一致性。
- 流量分发与限流:网关作为流量入口,对商品详情查询等接口设置单机 2000QPS 限流阈值;服务调用采用加权随机策略,根据节点性能分配权重;对爆款商品等热点数据单独部署服务实例,实现热点隔离。
3. 节点规模突破:分布式协调与云原生编排
(1)集群管控架构图
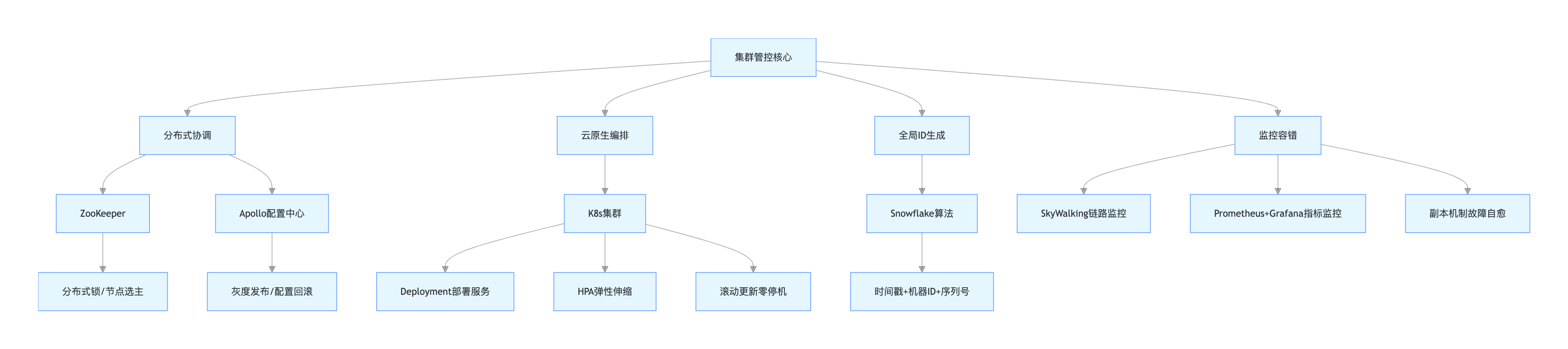
架构图说明:该架构构建集群管控 “神经中枢”——ZooKeeper 保障分布式一致性,解决锁、选主等问题;Apollo 实现配置全局管控;K8s 负责服务部署、弹性伸缩与滚动更新,提升集群运维效率;Snowflake 算法生成全局唯一 ID,支撑亿级数据标识;监控容错体系实现链路追踪、指标告警与故障自愈,保障集群稳定运行。
(2)核心技术落地细节
- 分布式协调:基于 ZooKeeper 实现缓存更新锁与 Redis 主从切换选主;Apollo 配置中心管理所有服务配置,支持灰度发布与配置回滚。ZooKeeper 分布式锁(防止缓存雪崩)核心代码如下:
import org.apache.zookeeper.*;
import org.apache.zookeeper.data.Stat;
import java.util.Collections;
import java.util.List;
import java.util.concurrent.CountDownLatch;
public class ZkDistributedLock {
private static final String LOCK_ROOT_PATH = "/distributed_lock";
private static final String LOCK_NODE_PREFIX = "/lock_";
private ZooKeeper zooKeeper;
private String lockPath;
private CountDownLatch countDownLatch = new CountDownLatch(1);
// 初始化ZooKeeper连接
public ZkDistributedLock(String zkAddress) throws Exception {
zooKeeper = new ZooKeeper(zkAddress, 5000, watchedEvent -> {
if (Watcher.Event.KeeperState.SyncConnected == watchedEvent.getState()) {
countDownLatch.countDown();
}
});
countDownLatch.await();
// 创建根节点(永久节点)
Stat stat = zooKeeper.exists(LOCK_ROOT_PATH, false);
if (stat == null) {
zooKeeper.create(LOCK_ROOT_PATH, new byte[0], ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
}
}
// 获取分布式锁
public void lock() throws Exception {
// 创建临时有序节点
lockPath = zooKeeper.create(LOCK_ROOT_PATH + LOCK_NODE_PREFIX, new byte[0],
ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL);
// 获取所有子节点
List<String> children = zooKeeper.getChildren(LOCK_ROOT_PATH, false);
Collections.sort(children);
String firstNode = children.get(0);
// 若当前节点是第一个子节点,则获取锁成功
if (lockPath.endsWith(firstNode)) {
return;
}
// 否则,监听前一个节点
String prevNode = firstNode;
for (String node : children) {
if (lockPath.endsWith(node)) {
zooKeeper.exists(LOCK_ROOT_PATH + "/" + prevNode, watchedEvent -> {
if (Watcher.Event.EventType.NodeDeleted == watchedEvent.getType()) {
try {
lock(); // 前一个节点删除,重新尝试获取锁
} catch (Exception e) {
e.printStackTrace();
}
}
});
break;
} else {
prevNode = node;
}
}
}
// 释放分布式锁
public void unlock() throws Exception {
zooKeeper.delete(lockPath, -1);
zooKeeper.close();
}
}- 云原生编排(K8s):通过 Deployment 部署服务,指定 3 个副本保障可用性;基于 HPA 配置 CPU 利用率阈值(70% 扩容,30% 缩容),应对流量波动;服务版本更新采用滚动策略,实现零停机部署,资源利用率提升 80%。
- 全局 ID 生成:采用雪花算法生成全局唯一商品 ID,结构包含 41 位时间戳 + 5 位数据中心 ID+5 位机器 ID+12 位序列号,确保分布式环境下 ID 不重复,支撑每日亿级 ID 创建需求,且具备时序性便于排序查询。
- 集群监控与容错:SkyWalking 追踪跨节点调用链路,Prometheus+Grafana 采集系统与业务指标;ClickHouse 通过副本机制容错,TDSQL 主从架构支持 30 秒内自动故障转移,RTO<30 秒,保障系统稳定运行。
三、实战踩坑与深度复盘:从故障中提炼的架构优化
结合项目实战,总结 4 个核心踩坑点及优化方案,助力架构落地少走弯路:
- 数据倾斜问题:ClickHouse 集群初期因类目数据倾斜(部分类目占比超 60%)导致查询瓶颈,通过 “哈希分片 + 动态负载均衡” 调整,使各节点数据量差异控制在 10% 以内,查询性能提升 3 倍。
- 缓存一致性问题:初期采用 “更新 DB 后更新缓存” 方案,出现缓存更新失败导致的数据不一致,改为 “先更 DB 再删缓存”+ 延迟双删,彻底解决该问题,数据一致性达 99.99%。
- 集群扩容问题:分库分表架构扩容时需手动迁移数据,耗时且易出错,后期替换为 TDSQL 分布式分区,支持新增节点自动平衡数据,扩容效率提升 10 倍,运维成本降低 50%。
- 资源优化问题:ClickHouse 集群初期部署 3 个副本,经压测验证 2 个副本即可支撑 99.99% 可用性,减少副本后存储成本降低 33%,同时降低节点间数据同步压力。
四、架构演进思考:从「当前可用」到「未来可扩展」
1. 规模架构的演进路径
- 第一阶段(百万级):单库分表 + 本地缓存 + 物理机部署,核心目标「解决数据存储瓶颈」;
- 第二阶段(千万级):分布式数据库 + Redis 集群 + K8s 部署,核心目标「提升并发承载能力」;
- 第三阶段(亿级):多引擎协同 + 全链路缓存 + 云原生弹性伸缩,核心目标「平衡性能、一致性、可用性」;
- 第四阶段(十亿级):Serverless 架构 + 智能调度 + 全域监控,核心目标「降本增效 + 自动化运维」。
2. 技术选型的底层逻辑
- 不盲目追求「新技术」:如 ClickHouse 虽适合分析,但核心交易数据仍需 TDSQL(强一致性保障);
- 优先选择「生态完善」的技术:如 K8s+Prometheus+Grafana 的监控体系,比单一工具更易扩展;
- 预留「技术降级」方案:如 Redis 集群故障时,可快速切换至本地缓存 + DB 的降级方案,保障核心业务可用。
3. 未来技术趋势
- AI 辅助运维:通过 AI 算法预测节点故障、数据倾斜,提前触发优化策略,减少人工干预;
- Serverless 架构:函数计算 + 对象存储,按需付费,降低闲置资源成本,适合流量波动大的场景。
五、核心复习要点
1. 核心矛盾:规模架构的本质是「性能、一致性、可用性、成本」的四者平衡,而非单一维度最优;
2. 技术关键:
- 存储:分片算法决定扩展性,多引擎协同决定灵活性,数据同步决定一致性;
- 并发:缓存架构决定性能上限,流量治理决定稳定性,锁机制决定一致性;
- 集群:分布式协调决定可用性,弹性伸缩决定扩展性,监控容错决定运维效率;
3. 落地原则:先解决「核心痛点」,再优化「边缘场景」;先保障「可用」,再追求「最优」;
4. 演进逻辑:架构需「向前兼容」(支持存量数据迁移)、「向后扩展」(支持业务增长)、「向下降级」(支持故障兜底)。
🔥 互动讨论:
本文结合真实项目实战,拆解了支撑亿级数据与千万并发的技术体系,配套架构图详解与核心代码。如果你的项目正面临数据量暴增、并发压垮系统、集群管理混乱等问题,或在多引擎存储、缓存设计、K8s 伸缩等方面有疑问,欢迎在评论区留言讨论~
扩展阅读
- 《ClickHouse 核心优势分析与场景实战》:深入理解列式存储与分布式架构的性能优势;
- 《Redis 集群下的数据流及核心问题权衡》:掌握分布式缓存的集群部署与问题解决方案;
- 《Kubernetes 脉络:从基础概念到核心架构的认知框架》:系统学习云原生集群编排技术;
- 《Elasticsearch 深度分页:时间分桶动态定位算法实战》:解决大规模搜索场景的分页性能难题。
📚 我的技术博客导航:[点击进入一站式查看所有干货]

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 16
16 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)