Qwen 技术报告解读:QWEN TECHNICAL REPORT
Qwen Technical Report 技术报告解读,自留使用,欢迎交流。
" QWEN "一词源于汉语"qianwen",意为"成千上万的提示",表达了"包罗万象"的意思。
摘要
目录
QWEN 系列,它包含不同参数规模的模型,有基础预训练语言模型 QWEN,还有经人类对齐技术微调的聊天模型 QWEN - CHAT。基于基础语言模型开发了专业的代码模型 CODE - QWEN、CODE - QWEN - CHAT 以及数学模型 MATH - QWEN - CHAT,这些模型与开源模型相比性能显著提升,但略逊于专有模型。
Qwen 系列基于 Transformer 架构,主要采用decoder - only
介绍
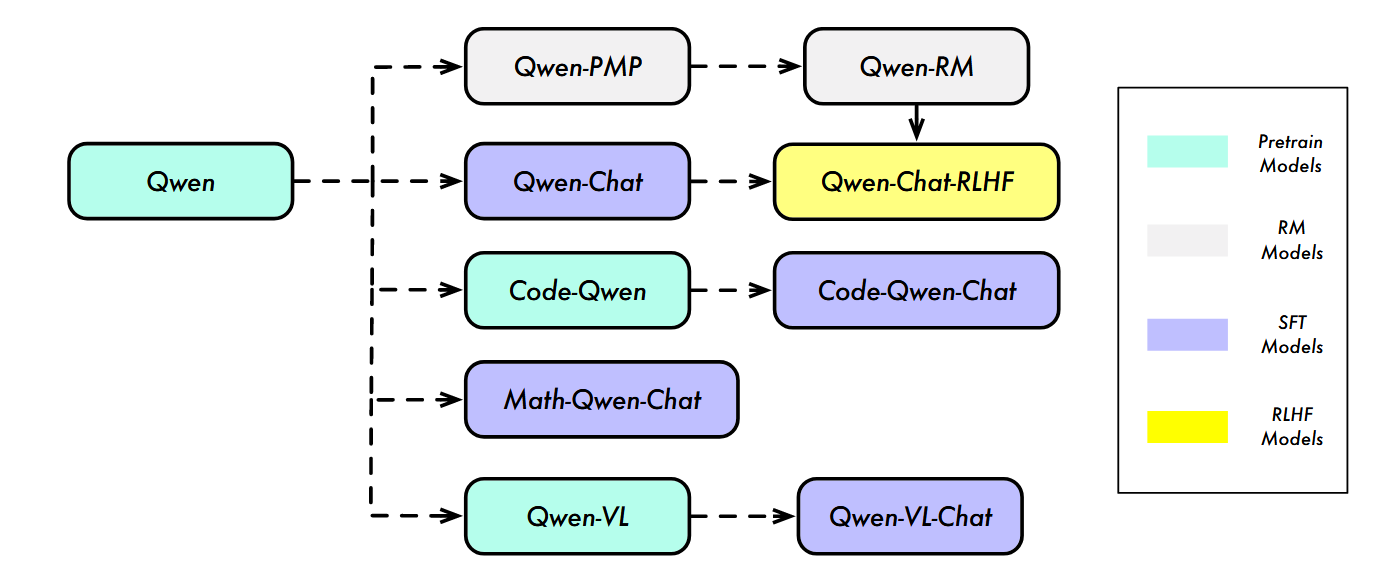
Qwen 系列并非单一模型,而是包含 “基础模型 + 对齐模型 + 专项模型” 的分层架构,各模块职责明确且相互衔接,具体结构如下:
- 基础预训练模型(Qwen):作为整个系列的核心底座,提供通用语言理解与生成能力,参数规模涵盖 1.8B、7B、14B,后续所有模型均基于此迭代。
- 对齐模型(Qwen-Chat):在基础模型上通过 SFT 和 RLHF 优化,使其符合人类偏好,具备对话交互、工具使用等助手能力,包括普通 SFT 版本和性能更优的 RLHF 版本。
- 专项模型:针对特定任务优化的衍生模型,包括:
- CODE-Qwen/CODE-Qwen-Chat:聚焦代码生成、调试与解释,在基础模型上补充代码数据训练。
- MATH-Qwen-Chat:专注数学推理,通过数学指令数据集微调,提升算术、竞赛题求解能力。
- Qwen-VL/Qwen-VL-Chat:多模态模型,融合视觉编码器与语言模型,支持图文理解、文本识别等。
预训练
数据预处理流程
公开的web数据:从HTML中提取文本,并使用语种识别工具来确定语言
如何提升数据质量
去重(精确去重 + 模糊去重)
低质量过滤(规则 + 机器学习模型评分)
高质量指令数据注入
已有研究表明,使用多任务指令预训练语言模型可以提高其零样本和少样本性能。
什么叫多任务?推理类、问答类、理解类、生成类任务
最后,构建了一个高达3万亿tokens的数据集
分词 TOKENIZATION
使用字节对编码(BPE) 作为分词核心方法。
低效的分词器可能将本可合并的语义单元拆成多个 Token(如将 “人工智能” 拆成 “人”“工”“智”“能” 4 个 Token),导致 Token 的 “信息密度” 低(单个 Token 承载的语义少)。
而高效的分词(如 QWEN)能将 “人工智能” 作为 1 个 Token,用 1 个单元传递完整语义,既减少 Token 数量(压缩),又提升信息传递效率,避免模型在冗余 Token 上浪费计算资源。
结构
结构和 LLaMA非常相似,差异在于训练数据和tokenizer中文支持更好。
用 RMSNorm ,在保持性能的同时提升计算效率。
采用 SwiGLU,将前馈网络(FFN)维度从 “4 倍隐藏层大小” 缩减至 “8/3 倍”,降低计算成本。
使用 RoPE。
加入 QKV 层偏置(Bias)提升长文本外推能力
训练
采用自回归语言建模任务,训练上下文长度初始为 2048,使用 AdamW 优化器(β₁=0.9,β₂=0.95),配合余弦学习率调度与 BF16 混合精度训练。
长上下文扩展
通过 “动态 NTK-aware 插值、LogN-Scaling、分层窗口注意力” 三种无训练技术,将上下文长度扩展至 16384,且保持低困惑度(PPL),支持长文本理解。
模型对齐(Alignment)
有监督微调 SFT
数据
构建 “人类对话式数据集”,涵盖任务执行、闲聊、工具使用、安全防护等场景,采用 ChatML 格式(含<im_start>/<im_end>特殊 token)区分角色,避免歧义。
训练
以 “下一个 token 预测” 为任务,为防止过拟合,采用权重衰减,取值为0.1,dropout设置为0.1
RLHF
分为 “奖励模型训练” 和 “PPO 策略优化” 两步:
奖励模型(RM)
以同规模 Qwen 基础模型为初始化,加入池化层提取句子奖励;用 “偏好对比数据”(单查询 + 两个不同回复 + 人类偏好标注)训练。
PPO 优化
Proximal Policy Optimization,近端策略优化算法
引入 “策略模型、价值模型、参考模型、奖励模型” 四模型架构
- 策略模型:负责生成文本回复,在训练过程中进行参数更新,不断学习更优的策略以生成符合人类偏好的回复。它是从 SFT(监督微调)之后的大语言模型初始化而来。
- 参考模型: 不更新参数,用于限制策略模型的更新幅度,防止更新过程中过度偏离预训练和监督微调赋予的能力。
- 奖励模型(RM):用于评估模型生成回复的质量,模拟人类偏好,作为 PPO 优化的目标。Qwen 中通常是先训练好一个奖励模型,在 PPO 优化过程中,这个奖励模型不更新参数。
- 价值模型:用于估计策略模型生成动作的价值,判断当前更新对长期收益的影响,帮助策略模型避免只追求短期高奖励,而能从长期视角优化回复生成策略 。
专项模型与工具能力
代码专项模型(CODE-Qwen)
训练流程:在 Qwen 基础模型上补充 900 亿 token 代码数据继续预训练.
数学专项模型(MATH-Qwen-Chat)
训练特点:针对数学数据短的特性,将训练上下文长度设为 1024,对题目输入做损失掩码,仅优化解题回复。
工具使用与智能体
工具调用:通过 ReAct prompting 支持未见过的工具调用,。
Hugging Face Agent:可调用多模态工具(语音识别、图像生成)。
结论
本报告介绍了QWEN系列大型语言模型,展示了自然语言处理领域的最新进展。以14B、7B和1 . 8B参数,这些模型已经在海量数据上进行了预训练,包括数万亿的令牌,并使用SFT和RLHF等前沿技术进行了微调。此外,QWEN系列还包括专门的编码和数学模型,如CODE - QWEN、CODE - QWEN - CHAT和MATH - QWENCHAT,它们已经在特定领域的数据上进行了训练,以在各自的领域中表现优异。我们的结果表明,QWEN系列与现有的开源模型具有竞争力,甚至与一些专有模型在综合基准和人类评估上的表现相匹配。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 31
31 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)