Dify 工作原理与应用实例
Dify 工作原理与应用实例
Dify.AI 是一款开源的 LLM(大语言模型)应用开发平台。它融合了后端即服务(Backend as a Service, BaaS)和 LLMOps 的理念,允许开发者(甚至非技术人员)通过可视化界面快速构建生成式 AI 应用。
本文将从 核心工作原理 和 实战应用实例 两个维度,带你深入了解 Dify。
第一部分:Dify 的核心工作原理
Dify 的核心价值在于抹平了模型 API 与实际应用之间的鸿沟。它不仅仅是一个“套壳”,而是一个完整的 编排(Orchestration) 引擎。
1.1 系统架构概览
Dify 的架构设计旨在处理从模型接入、数据处理到应用发布的全流程。
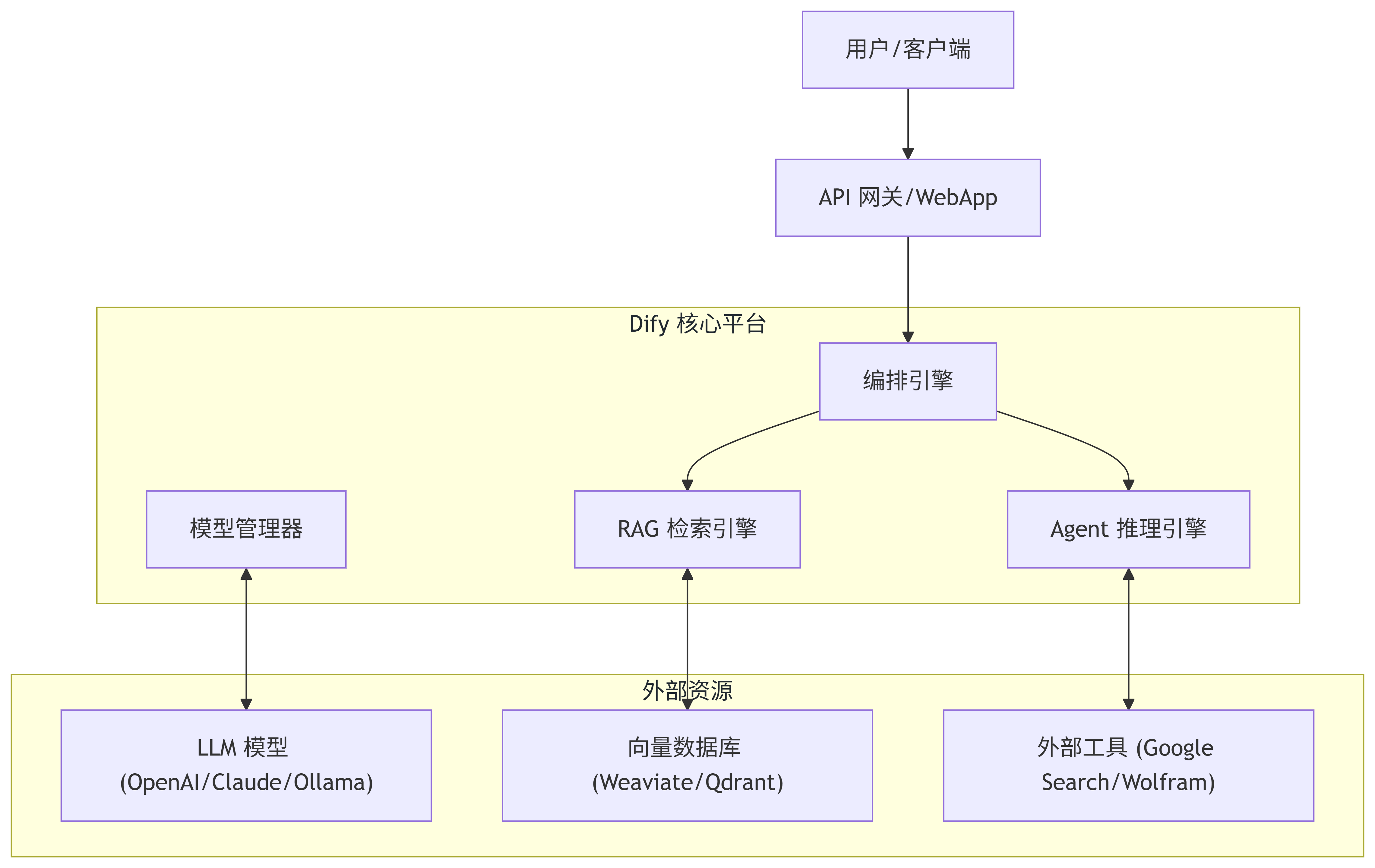
1.2 核心模块解析
A. RAG(检索增强生成)引擎原理
Dify 处理私有数据的能力是其一大亮点。其工作流程如下:
- ETL (Extract, Transform, Load):上传 PDF/TXT/MD 文件,Dify 解析文本。
- 分段(Chunking):将长文本切割成适合 LLM 上下文的小块(Chunk)。
- 向量化(Embedding):调用 Embedding 模型(如 text-embedding-3-small)将文本块转化为向量。
- 存储:存入向量数据库(默认内置 Weaviate,支持扩展)。
- 检索与生成:用户提问 -> 转化为向量 -> 在数据库中查找相似文本块 -> 将文本块作为“上下文”喂给 LLM -> LLM 生成答案。
B. Workflow(工作流)编排原理
Dify 的工作流不仅仅是线性对话,它基于 DAG(有有向无环图) 结构。
- 节点(Node):执行单元。包括 LLM 请求、代码执行(Python/JS)、条件分支、HTTP 请求等。
- 边(Edge):数据流向。前一个节点的输出(Output)作为后一个节点的输入(Input)。
- 变量池:数据在节点间传递的载体。
C. 模型与工具抽象
Dify 能够统一管理不同供应商的模型(OpenAI, Azure, LocalLLM via Ollama),并支持 Function Calling(工具调用),让 LLM 具备联网搜索、查数据库的能力。
第二部分:应用实例实战
我们将通过三个不同复杂度的场景,展示如何使用 Dify。
实例一:构建企业级私有知识库客服 (RAG)
场景:你需要一个能够回答公司内部 HR 政策(如请假、报销)的 AI 助手,且不能编造事实。
步骤 1:创建知识库
- 进入 Dify 顶部导航栏的 “知识库”。
- 点击 “创建知识库”,上传公司的《员工手册.pdf》。
- 分段设置:选择“自动分段与清洗”。
- 索引方式:选择“高质量”(使用 Embedding 模型)。
- 点击“保存并处理”,等待向量化完成。
步骤 2:创建对话应用
- 回到 “工作室”,选择 “创建空白应用” -> “聊天助手”。
- 提示词编排(Prompt Engineering):
- 在“前缀提示词”中输入:
你是一个专业的 HR 助手,请仅依据上下文内容回答用户问题。如果上下文中没有答案,请说不知道。
- 在“前缀提示词”中输入:
- 关联知识库:
- 在“上下文”区域,点击“添加”,选择刚才创建的《员工手册》知识库。
- 调试:
- 在右侧预览框输入:“年假有多少天?”
- 观察:你会看到 Dify 引用了文档中的具体段落,并输出了准确回答。
实例二:全自动 SEO 文章生成器 (Workflow)
场景:你需要输入一个“关键词”,AI 自动完成:大纲生成 -> 内容撰写 -> SEO 优化 -> 翻译成英文。这是一个典型的链式处理。
步骤 1:创建工作流应用
- 创建应用时选择 “工作流 (Workflow)” 类型。
步骤 2:编排节点
我们需要在画布上拖拽并连接以下节点:
- 开始节点 (Start):添加一个输入变量
topic(文本)。 - LLM 节点 A (生成大纲):
- 模型:GPT-4o / Claude 3.5 Sonnet。
- Prompt:
请为主题 {{topic}} 写一个详细的文章大纲。
- LLM 节点 B (撰写正文):
- 输入:引用
LLM节点A的输出。 - Prompt:
根据以下大纲:{{#LLM节点A.text#}},撰写一篇 1000 字的深度文章。
- 输入:引用
- LLM 节点 C (SEO 优化):
- 输入:引用
LLM节点B的输出。 - Prompt:
优化这篇文章的 SEO,添加 meta description 和 h1/h2 标签。文章内容:{{#LLM节点B.text#}}
- 输入:引用
- 结束节点 (End):输出
LLM节点C的结果。
流程图示:
步骤 3:运行与发布
- 点击右上角 “运行”,输入
Topic: "Dify 的未来"。 - 系统将依次执行三个 LLM 任务,最终吐出一篇格式完美的文章。
实例三:具备联网能力的 AI 搜索 Agent
场景:你需要一个 AI,它不仅能聊天,还能实时查询当天的股票、天气或新闻(ChatGPT 的 Browse 功能)。
步骤 1:配置工具
- 在 Dify 导航栏点击 “工具”。
- 找到 Google Search (SerpApi) 或 Tavily Search(推荐,专为 AI 优化)。
- 申请 API Key 并授权。
步骤 2:创建 Agent 应用
- 创建应用,选择 “Agent” 模式。
- 在 “工具” 栏,添加刚才配置的搜索工具。
- 模型选择:建议使用具备 Function Calling 能力的模型(如 GPT-3.5/4 或 Qwen-Max)。
步骤 3:测试
- 用户提问:“今天 Nvidia 的股价是多少?相比昨天涨了没?”
- 原理:
- LLM 分析用户意图,发现需要外部数据。
- LLM 暂停生成,向 Dify 发出“调用搜索工具”的指令。
- Dify 执行搜索,将搜索结果(Context)返回给 LLM。
- LLM 结合搜索结果生成最终回复。
第三部分:最佳实践与部署建议
3.1 部署方式
- Cloud 版本:直接访问
cloud.dify.ai,注册即用,适合快速验证。 - 开源自托管 (Docker):适合数据隐私要求高的企业。
git clone https://github.com/langgenius/dify.git cd dify/docker docker compose up -d
3.2 提示词编写技巧 (Prompt Engineering)
在 Dify 中,利用 “结构化提示词” 至关重要。建议使用 Markdown 格式在系统提示词中分隔不同指令:
# Role
你是一个资深 Python 程序员。
# Constraint
- 必须输出可执行代码
- 代码需要包含中文注释
# Workflow
1. 分析用户需求
2. 编写代码
3. 解释代码逻辑
3.3 调试与日志
Dify 提供了强大的 “日志与标注” 功能。
- 每次对话的 Token 消耗、耗时、中间步骤(Thoughts)都会被记录。
- 你可以对 AI 的回答进行“改进标注”,并在后续微调或 RAG 检索中优化效果。
总结
Dify 通过 可视化编排 将复杂的 LLM 开发过程简化为了“搭积木”。
- 对于开发者:它是一个完善的 LLMOps 平台,提供了 API、监控和插件机制。
- 对于业务人员:它是一个无代码/低代码神器,能快速把文档变成知识库,把想法变成 Workflow。
掌握 Dify,本质上就是掌握了 AI 原生应用(AI-Native Apps) 的构建逻辑。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 21
21 0
0- 0



 已为社区贡献29条内容
已为社区贡献29条内容

所有评论(0)