王树森深度强化学习 DRL(六)连续控制 DDPG + 随机策略
本文聚焦深度确定性策略梯度(DDPG) 在连续控制任务(倒立摆)中的理论与实践。对比离散 / 连续动作强化学习差异,并阐释 DDPG 作为 Actor-Critic 框架,通过确定性策略突破连续动作空间局限的核心机制。代码层面,一方面基于 Stable-Baselines3 快速实现 DDPG 训练、测试及可视化;另一方面手动构建 DDPG 核心组件,包括经验回放、Actor/Critic 网络(
1. 离散控制与连续控制区别
之前的问题:像超级玛丽,动作空间只有三种动作,DQN的输出维度为 3 。
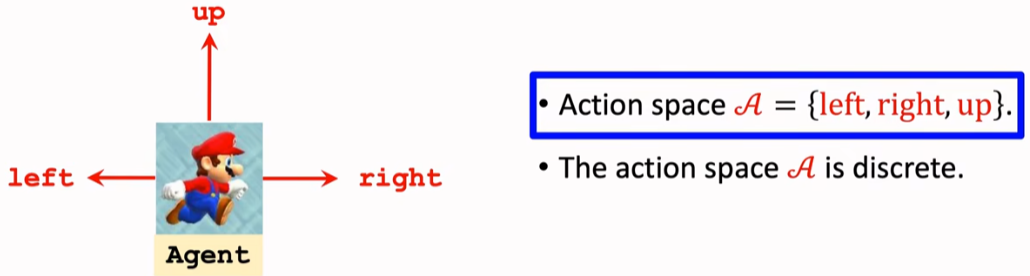
像机械臂控制问题,两个自由度对应两个维度的角度,
但角度是一个连续的量(连续动作空间)。

想法1:连续量离散化:划分小间隔为一个单位。
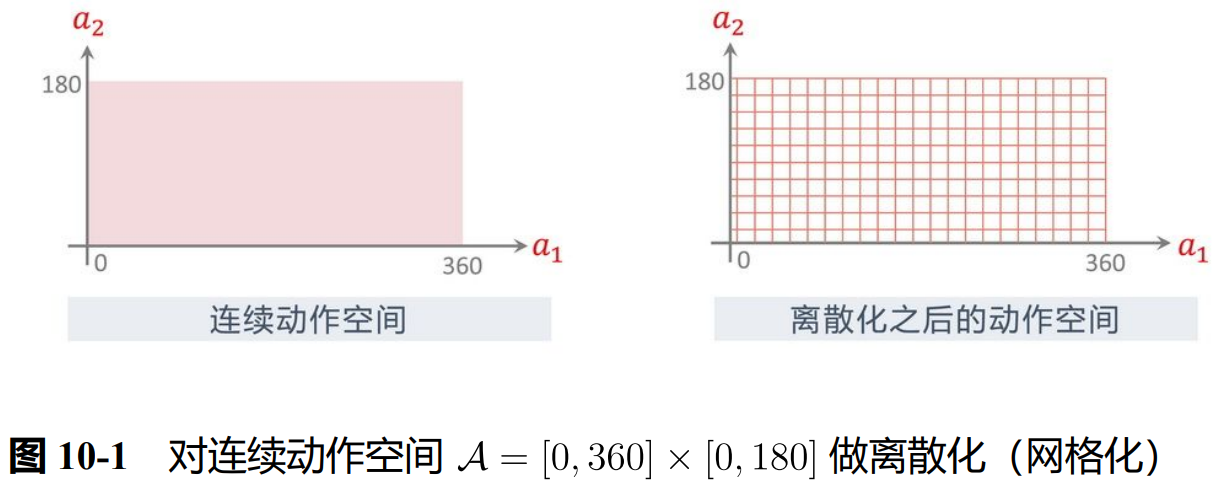
(但这么操作 会随着维度升高而指数爆炸)
2. Deterministic Policy Gradient (DDPG) 深度确定性策略梯度
https://arxiv.org/pdf/1509.02971
属于一种 actor-critic 方法,策略网络直接输出连续动作的确定性取值
(而非离散动作的概率分布),突破了传统强化学习在连续动作空间的局限。
![]()
确定性策略
![]()
期望仅依赖于环境(与策略无关) 所以可以 off-policy
梯度由链式法则 Q -> a -> μ
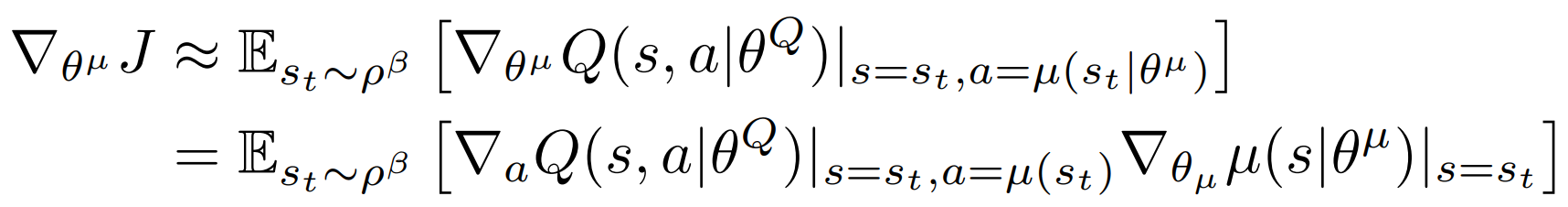
TD 算法更新价值网络,下一步的 a' 由策略网络得到。
同价值学习部分优化手段(使用目标网络、经验回放、多步TD损失)

使得 q 打分更高,训练策略网络;链式法则 q -> a -> θ
代码实现的时候:损失设置为 q(s,π(s)) 的相反数。
actor_loss = -self.critic(s, self.actor(s)).mean()
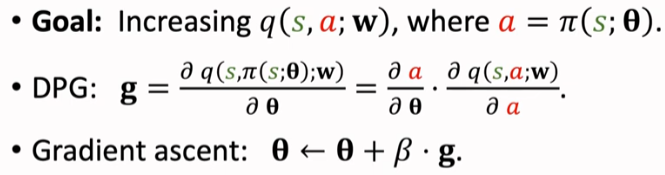
伪代码:先把目标网络参数设置为 = 主网络,后续每一次的循环中
π(s) + 扰动 -> 动作 a -> (s,a,r,s') 存入经验回放;
经验回放取一个 Batch;价值网络和策略网络更新;目标网络软更新

3. 随机策略连续控制 -- 正态分布 学均值方差

用正态分布的概率密度函数 作为策略函数进行抽样:
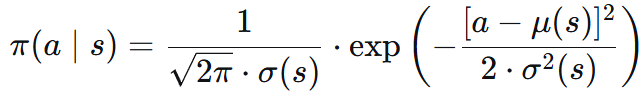
因为标准差 σ 必须非负,如果把 σ 作为优化变量,那么优化模型有约束条件,给求解造成困难。
于是我们用 方差对数 ρ = ln(σ²) 和 均值 μ,并且拿神经网络拟合。
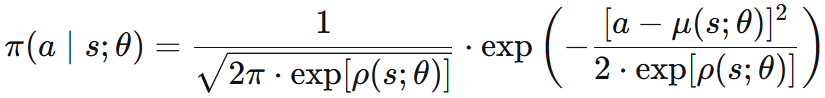
辅助网络 f() = ln π() + C
![]()
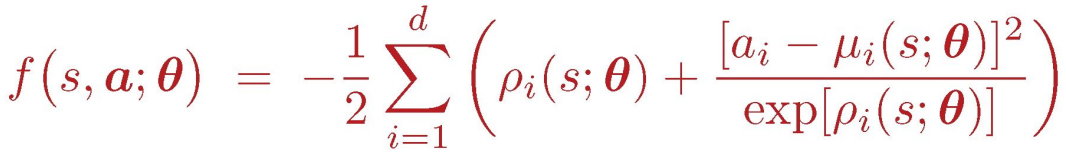
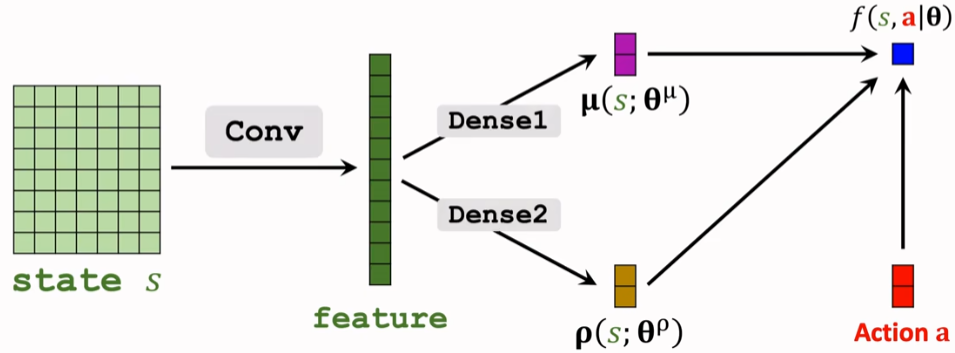
故随机策略梯度可写为:
![]()
再使用 REINFORCE 或 actor-critic 的方法训练。
4. 倒立摆代码实践 stable-baselines3
https://stable-baselines3.readthedocs.io/en/v2.7.0/modules/ddpg.html
环境的目标:将倒立摆从随机位置摆动到竖直向上(倒立)的状态,并尽可能地保持住。
奖励在每个时间步的计算公式如下:
reward = -(θ² + 0.1 * θ'² + 0.001 * τ²)
θ: 摆杆角度与竖直向上位置的偏差
θ': 摆杆的角速度。 τ: 施加在摆杆铰链上的扭矩(动作)。
理想稳定状态:角度偏差小,角速度小,尽量少施加外力。
最后返回 200 步的总奖励值,reward 越接近 0 表现越好。
Policy 网络参数:
MlpPolicy:状态观测空间是向量的环境;多层感知机策略;Pendulum-v1, CartPole 经典控制
CnnPolicy:状态观测空间是图像的环境;卷积神经网络策略;Atari 游戏,机器人视觉导航
MultiInputPolicy:同时接收图像和向量信息的环境
# pip install stable-baselines3
import gymnasium as gym
import numpy as np
from stable_baselines3 import DDPG
from stable_baselines3.common.noise import NormalActionNoise
# 1. 创建训练环境:关闭渲染,提升训练效率
env_train = gym.make("Pendulum-v1")
# 创建DDPG需要的动作噪声
n_actions = env_train.action_space.shape[-1]
action_noise = NormalActionNoise(mean=np.zeros(n_actions), sigma=0.1 * np.ones(n_actions))
# 初始化DDPG模型,传入训练环境
model = DDPG("MlpPolicy", env_train, action_noise=action_noise, verbose=1)
model.learn(total_timesteps=10000, log_interval=10) # 10000步训练,10个episode输出一次日志
model.save("ddpg_pendulum")
env_train.close()日志输出示例:
| rollout/ | |
| ep_len_mean | 200 | # 平均每个episode长度 = 200步
| ep_rew_mean | -649 | # 平均每个episode总奖励 = -649(默认是最近100个episode平均)
| time/ | |
| episodes | 30 | # 已完成的episode总数
| fps | 192 | # 每秒处理的帧数/步数
| time_elapsed | 31 | # 已训练时间(秒)
| total_timesteps | 6000 | # 总训练步数 = 30 episodes × 200步
| train/ | |
| actor_loss | 62.7 | # Actor网络损失值
| critic_loss | 1 | # Critic网络损失值
| learning_rate | 0.001 | # 学习率
| n_updates | 5899 | # 网络参数更新次数2. 测试阶段:创建支持 human 渲染的环境
env_test = gym.make("Pendulum-v1", render_mode="human")
# 加载训练好的模型
model = DDPG.load("ddpg_pendulum")
for test_ep in range(5):
obs, _ = env_test.reset()
test_reward = 0
done = False
while not done:
# 确定性预测(关闭噪声,使动作更稳定)
action, _states = model.predict(obs, deterministic=True)
obs, reward, terminated, truncated, info = env_test.step(action)
test_reward += reward
done = terminated or truncated
print(f"测试轮{test_ep + 1} 总奖励:{test_reward:.1f}")
env_test.close()plus:使用 callback 追踪 episode 和日志里的两个网络损失。
from stable_baselines3.common.callbacks import BaseCallback
class SimpleTrainingCallback(BaseCallback):
def __init__(self, verbose: int = 0):
super().__init__(verbose)
self.episode_rewards = [] # 每个episode的总奖励
self.actor_losses = [] # Actor网络损失
self.critic_losses = [] # Critic网络损失
self.current_episode_reward = 0 # 当前episode累计奖励
def _on_step(self) -> bool:
# 累加当前episode的奖励
self.current_episode_reward += self.locals['rewards'][0]
# 记录网络损失(如果有)
log_data = self.logger.name_to_value
if "train/actor_loss" in log_data:
self.actor_losses.append(log_data["train/actor_loss"])
if "train/critic_loss" in log_data:
self.critic_losses.append(log_data["train/critic_loss"])
# episode结束 记录总的奖励
if self.locals.get('dones', [False])[0]:
self.episode_rewards.append(self.current_episode_reward)
self.current_episode_reward = 0
return True
callback = SimpleTrainingCallback()
model = DDPG("MlpPolicy",env,action_noise=action_noise,verbose=1,learning_starts=1000,train_freq=(1, "episode"))并画出奖励和网络损失的折线图。发现 30 个 episode 后 reward就比较稳定。
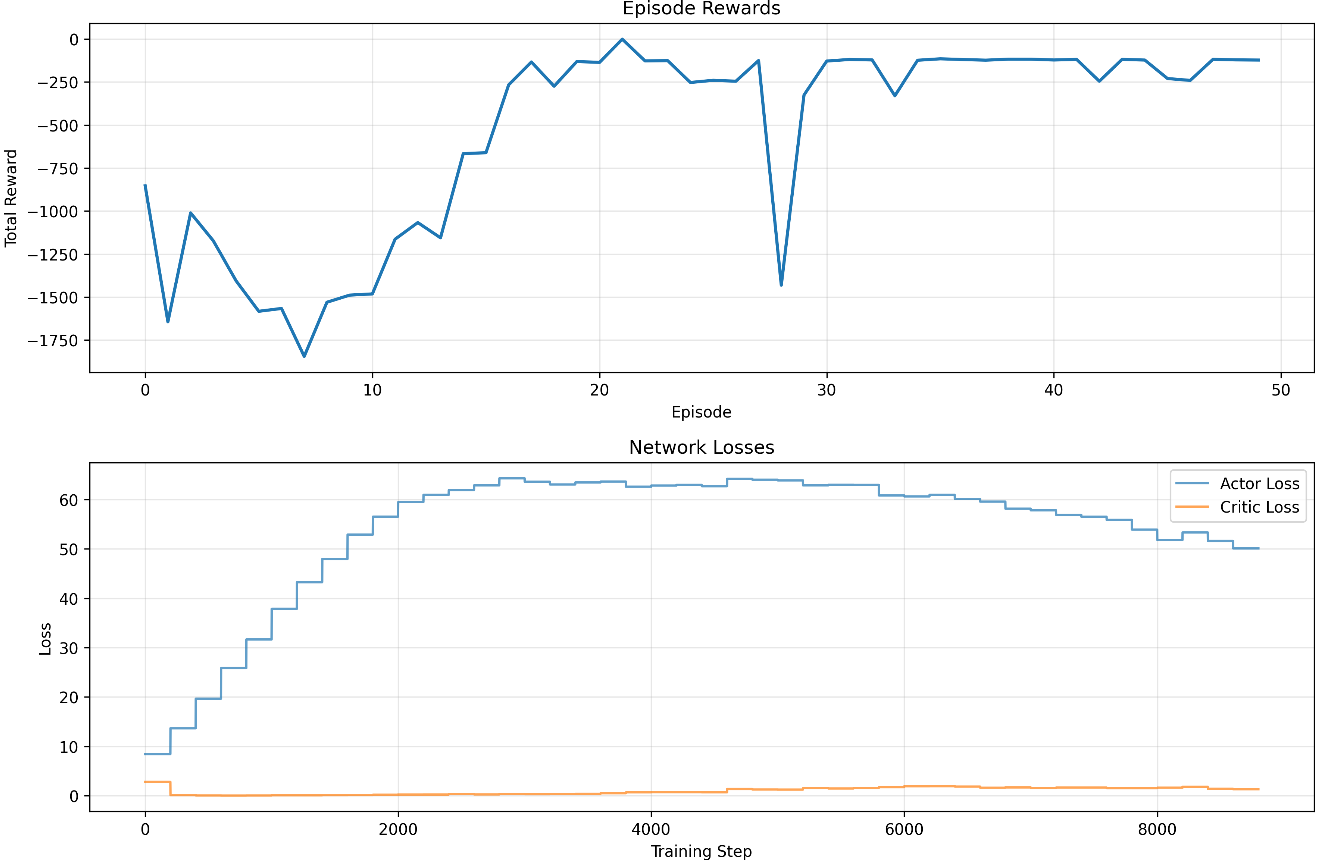
5. 手搓 DDPG
1. 两个 net
Actor 网络:激活函数 tanh 放缩到 [-1,1],再乘以 action_bound 到 [-2,2];
Q 网络:(s, a) 拼接作为输入 的价值。
class PolicyNet(torch.nn.Module):
def __init__(self, state_dim, hidden_dim, action_dim, action_bound):
super(PolicyNet, self).__init__()
self.fc1 = torch.nn.Linear(state_dim, hidden_dim)
self.fc2 = torch.nn.Linear(hidden_dim, action_dim)
self.action_bound = action_bound # action_bound是环境可以接受的动作最大值
def forward(self, x):
x = F.relu(self.fc1(x))
return torch.tanh(self.fc2(x)) * self.action_bound
class QValueNet(torch.nn.Module): # 动作价值 输入(s,a)
def __init__(self, state_dim, hidden_dim, action_dim):
super(QValueNet, self).__init__()
self.fc1 = torch.nn.Linear(state_dim + action_dim, hidden_dim)
self.fc2 = torch.nn.Linear(hidden_dim, hidden_dim)
self.fc_out = torch.nn.Linear(hidden_dim, 1)
def forward(self, x, a):
cat = torch.cat([x, a], dim=1) # 拼接状态和动作
x = F.relu(self.fc1(cat))
x = F.relu(self.fc2(x))
return self.fc_out(x)2. DDPG Agent 初始化四个网络,并复制权重;
软更新:tau 滑动平均;动作选择 训练时加噪声。
class DDPG:
''' DDPG算法 '''
def __init__(self, state_dim, hidden_dim, action_dim, action_bound, sigma, actor_lr, critic_lr, tau, gamma, device):
# 2*2个网络:目标网络初始化为与原网络相同的参数
self.actor = PolicyNet(state_dim, hidden_dim, action_dim, action_bound).to(device)
self.critic = QValueNet(state_dim, hidden_dim, action_dim).to(device)
self.target_actor = PolicyNet(state_dim, hidden_dim, action_dim, action_bound).to(device)
self.target_critic = QValueNet(state_dim, hidden_dim, action_dim).to(device)
self.target_critic.load_state_dict(self.critic.state_dict())
self.target_actor.load_state_dict(self.actor.state_dict())
self.actor_optimizer = torch.optim.Adam(self.actor.parameters(), lr=actor_lr)
self.critic_optimizer = torch.optim.Adam(self.critic.parameters(), lr=critic_lr)
self.gamma = gamma
self.sigma = sigma # 高斯噪声的标准差,均值直接设为0
self.tau = tau # 目标网络软更新参数
self.action_dim = action_dim
self.device = device
def take_action(self, state):
state = torch.tensor([state], dtype=torch.float).to(self.device)
action = self.actor(state).item()
return action + self.sigma * np.random.randn(self.action_dim) # 给动作添加噪声,增加探索
def soft_update(self, net, target_net): # 软更新目标网络
for param_target, param in zip(target_net.parameters(), net.parameters()):
param_target.data.copy_(param_target.data * (1.0 - self.tau) + param.data * self.tau)先更新原网络(critic TD,actror 用 critic 打的 Q 值)再软更新
def update(self, transition_dict):
states = torch.tensor(transition_dict['states'], dtype=torch.float).to(self.device)
actions = torch.tensor(transition_dict['actions'], dtype=torch.float).view(-1, 1).to(self.device)
rewards = torch.tensor(transition_dict['rewards'], dtype=torch.float).view(-1, 1).to(self.device)
next_states = torch.tensor(transition_dict['next_states'], dtype=torch.float).to(self.device)
dones = torch.tensor(transition_dict['dones'], dtype=torch.float).view(-1, 1).to(self.device)
next_q_values = self.target_critic(next_states, self.target_actor(next_states))
q_targets = rewards + self.gamma * next_q_values * (1 - dones)
critic_loss = torch.mean(F.mse_loss(self.critic(states, actions), q_targets)) # TD
self.critic_optimizer.zero_grad()
critic_loss.backward()
self.critic_optimizer.step()
actor_loss = -torch.mean(self.critic(states, self.actor(states))) # 策略目标为最大化Q值
self.actor_optimizer.zero_grad()
actor_loss.backward()
self.actor_optimizer.step()
self.soft_update(self.actor, self.target_actor) # 软更新策略网络
self.soft_update(self.critic, self.target_critic) # 软更新价值网络
火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 18
18 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)