从Kimi Linear一作张宇的分享看大模型训练的秘密:数据专家如何成为AI核心力量
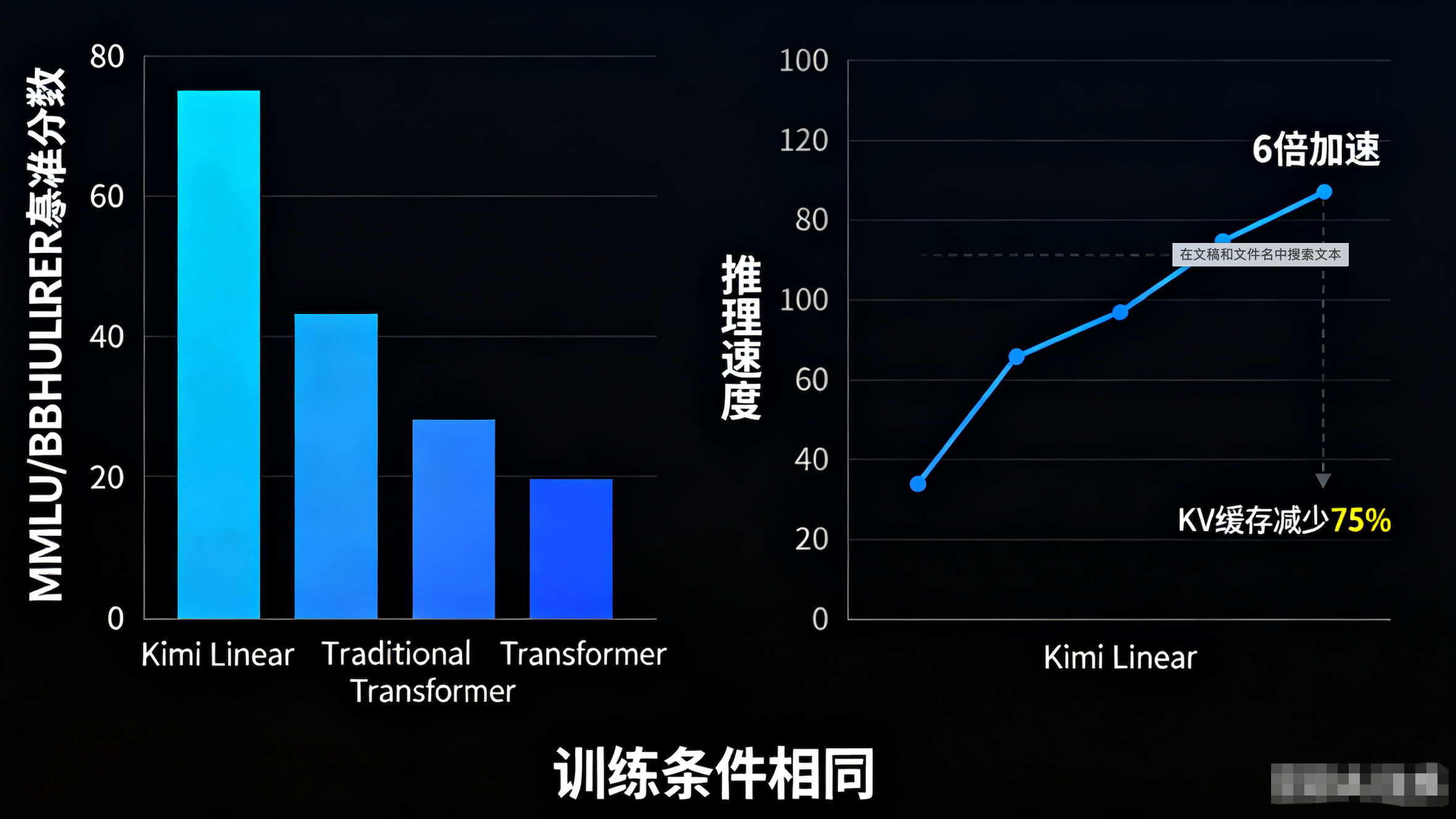
在AI大模型时代,Transformer架构正面临颠覆性挑战。月之暗面(Moonshot AI)最新开源的Kimi Linear模型,以线性注意力机制为核心,首次在相同训练条件下超越传统全注意力模型,并在长上下文任务中实现高达6倍的推理加速。这不仅仅是技术突破,更是模型训练实践的宝贵案例。
作为Kimi Linear的一作,张宇在知乎上分享了他的个人感想,从模型架构到训练过程,再到数据策略的深度思考。这篇分享不只为技术爱好者提供了灵感,更为从事大模型数据工作的专业人士指明了方向。今天,我们基于张宇的原文,结合Kimi Linear的技术报告,提炼出一份实用指南:如何从“数据喂养者”转型为AI价值的创造者。无论你是数据工程师、算法专家还是AI从业者,这篇文章都能给你带来启发。
1. Kimi Linear:线性注意力的革命性突破
Kimi Linear延续了Moonlight的设计思路,但将MoE(Mixture of Experts)的稀疏度从8提升到32,核心创新在于Kimi Delta Attention(KDA)。KDA基于GDN(Gated Delta Network)融入GLA(Gated Linear Attention)的细粒度门控,确保模型在长序列中稳定运行。
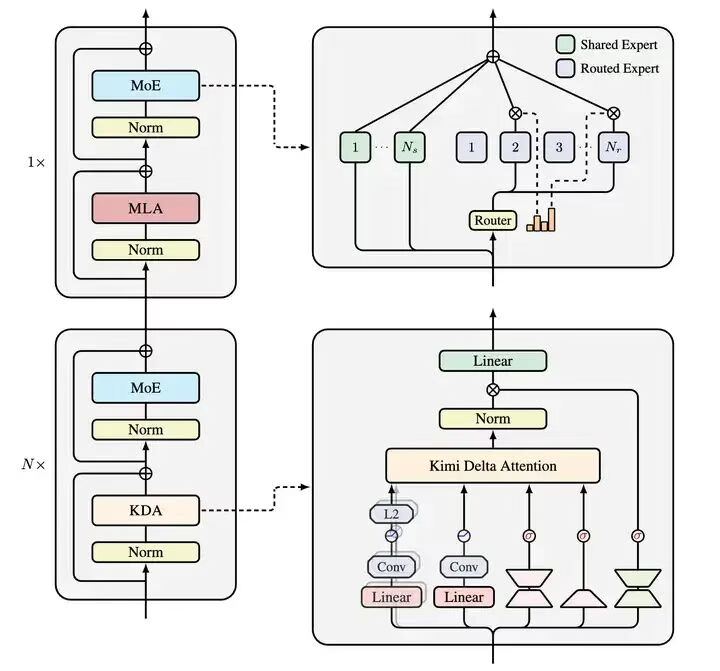
模型采用Hybrid架构:KDA(线性注意力)与MLA(全注意力)的层混合比例为3:1。经过Ablation Study验证,这个比例在效率和性能间达到了最佳平衡。最终,在5.7T Token的训练量和3B激活参数下,Kimi Linear在MMLU、BBH、RULER等基准上大幅领先传统Transformer。
为什么这么牛?因为KDA引入了Delta Rule的改进,确保梯度稳定;同时砍掉RoPE位置编码,转而用时间衰减核函数学习序列信息。结果:KV缓存减少75%,解码速度提升6倍。在数学、代码任务上虽因规模限制稍逊一筹,但模型的“Personality”(个性)出色,Reddit用户反馈称它有“小K2感”——生动、实用。
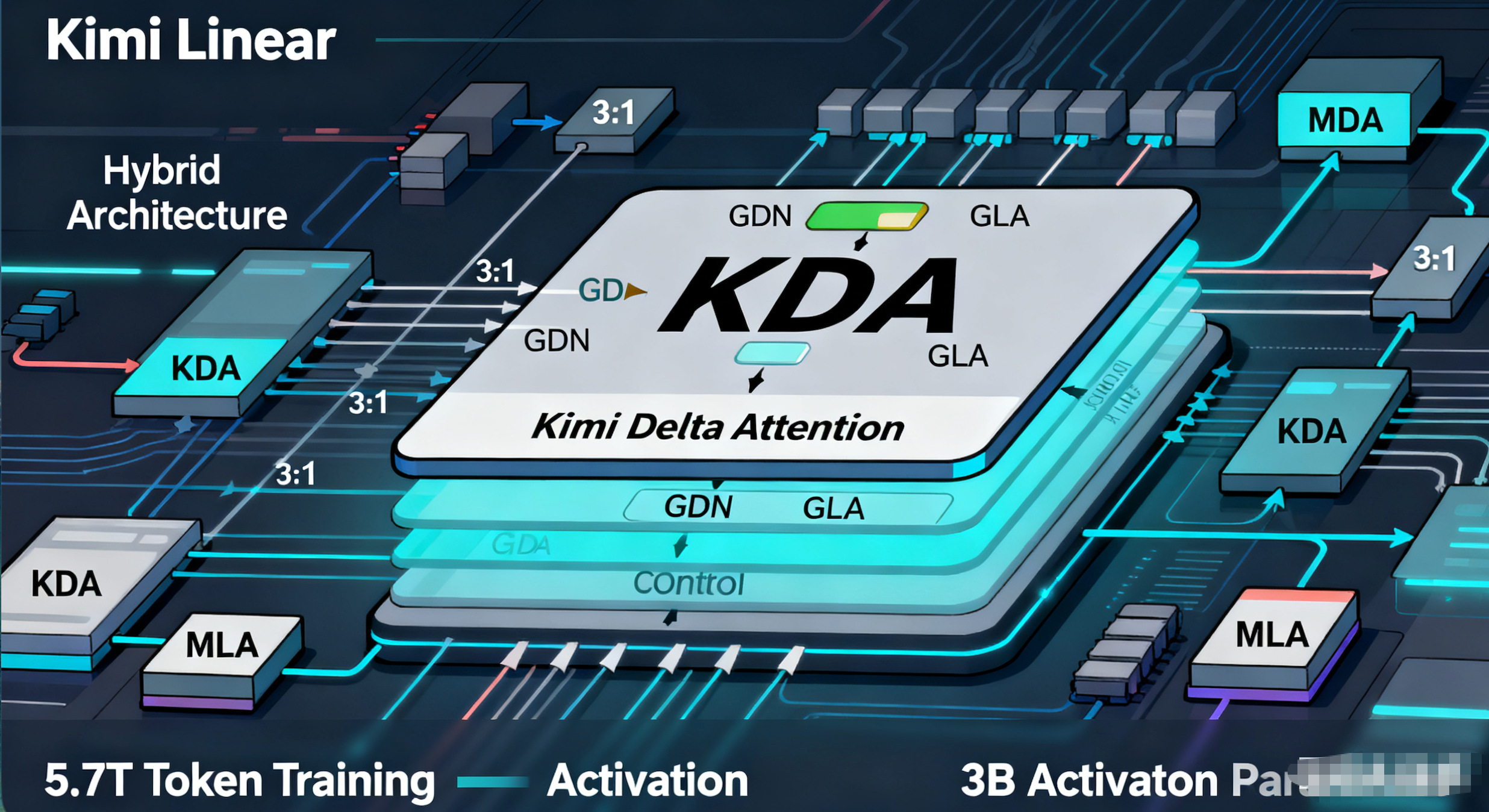
技术报告中提到,Kimi Linear在1.4T Tokens训练下全面超越基线,证明线性注意力不再是“快但傻”的代名词。它无缝对接vLLM框架,一键升级现有系统。这预示着AI架构正从Transformer路径依赖转向多元创新,如Mamba、MoR等。
2. 张宇的训练心得:从小卡拉米到旗舰模型的跨越
张宇坦言,这是他首次作为核心成员Scale到48B MoE规模的模型,训练量达5.7T Tokens。过去,他最多玩7B Dense模型,100B Tokens就够了。这次升级,让他深刻体会到管理大模型的痛点:分布式训练频繁中断,需要人盯;作息颠倒,与湾区团队跨时区协作。
Ablation过程漫长:从NoPE vs RoPE的选择,到Forget Gate的Pure Sigmoid vs GDN风格,再到Output Gate的作用,都经过反复实验。Kimi内部的“Scaling Ladder”传统功不可没:从小规模(1B参数)起步,逐层通关Benchmark,同时监控“内科”指标(如Loss曲线、A_log参数变化)。长文Benchmark如MRCR、RULER是拦路虎,任何掉点都需Revert排查——是推理Bug、数据问题,还是Linear本身?
Post-Training阶段同样挑战:直接迁移K2方案失效,团队尝试几十种数据配方。观察到有趣现象:Math/Code分数高时,模型Vibe差(太“Thinking”)。最终,选择平衡榜单与体验的方案。
Bitter Lesson:最初目标是SOTA,但资源限制造成调整。焦点转向1T公平比较,作为K3前奏。张宇强调,失败是常态,但从中学习是关键。
3. 数据工作的方向启发:成为什么样的专家?
张宇的分享揭示:数据在大模型中不是辅助,而是决定成败的核心。数据从业者不再是“喂数据”的执行者,而是策略制定者。以下是三个专家方向:
3.1. 数据策略师与架构师
数据使用需精心规划,而非越多越好。Post-Training的“几十种数据配方”证明:需平衡榜单与Vibe。
- 规划数据配方:研究Pre-Train、SFT、RLHF/DPO阶段的数据来源、类型、质量配比。
- 设计评估体系:超越Benchmark,纳入Vibe、Personality等主观指标。
- 成本效益分析:全链路ROI负责,从采集到计算。
3.2. 数据质量与根因分析专家
模型失败往往源于数据。张宇的沮丧源于排查难题:是Bug、内科炸,还是Linear不行?
- 内科监控:追踪数据分布、Loss波动,预警中毒/跑偏。
- 数据溯源:快速定位Bad Case根源,如清洗不足或偏见。
- 脏数据攻防:构建噪声/对抗数据集,提升鲁棒性。
3.3. 大规模数据系统工程师
5.7T训练的稳定性需求凸显系统重要性。
- 高效ETL管道:处理多模态数据清洗、去重。
- 存储与版本控制:数据湖方案,确保复现。
- 优化Data Loader:减少IO瓶颈,最大化GPU利用。
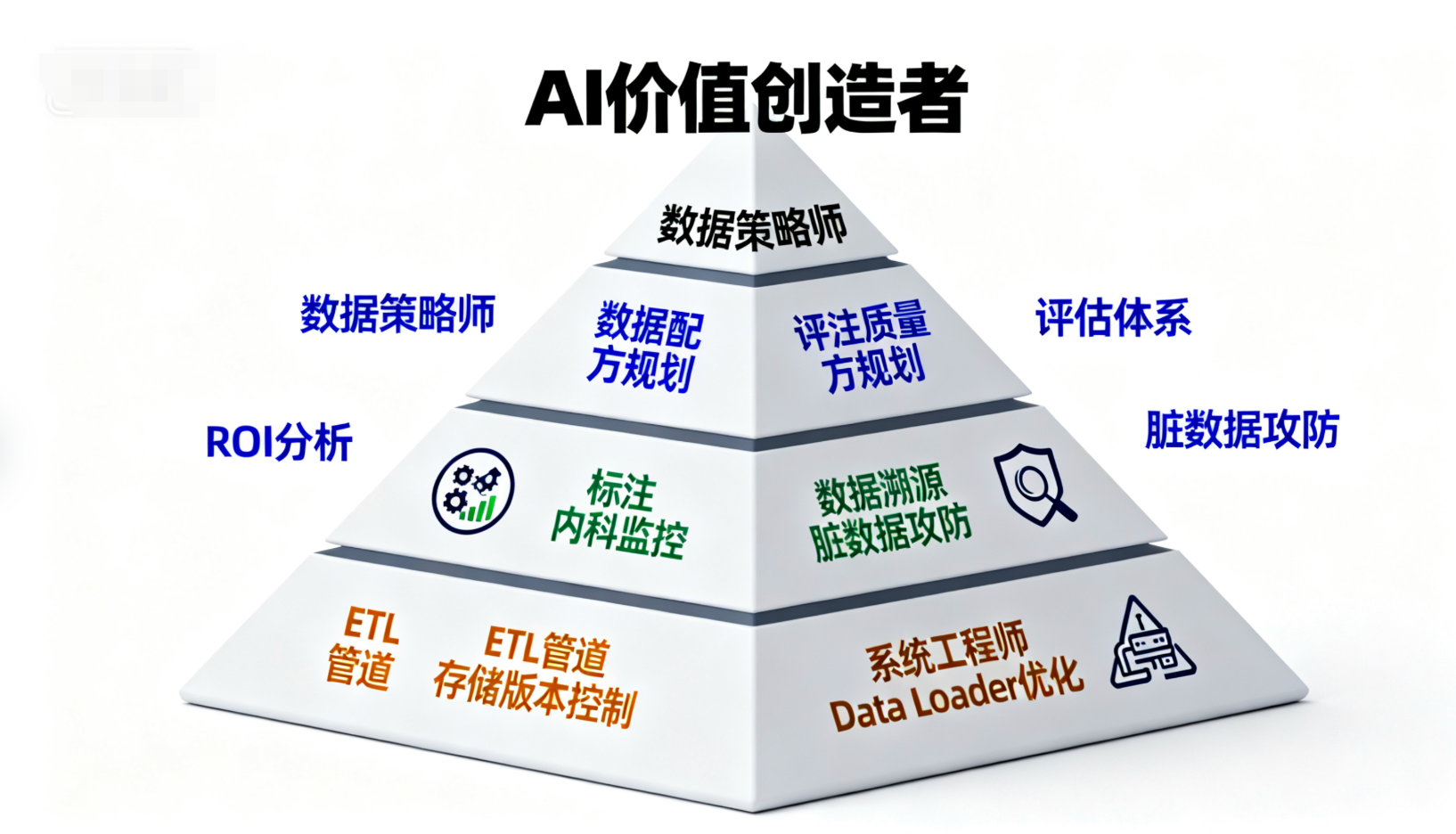
4. 工作沉淀指导:如何把数据做到极致?
从执行到核心,张宇的成长提供方法论:
4.1. 系统化实验思维
- 借鉴Scaling Ladder:从小规模验证数据策略,再扩展。
- 坚持Ablation:量化每个环节影响,如去重参数。
4.2. 理解数据-模型交互
- 关注内科:Loss形态、A_log变化与数据关联。
- 从失败学习:分析Bad Case,迭代数据。
4.3. 文档化与流程化
- 记录配方:详细实验细节,避免踩坑。
- 标准化流程:自动化工具,确保一致性。
4.4. 开放合作心态
- 跨团队协作:理解算法/推理痛点。
- 拥抱开源:参与FLA/NSA,站在巨人肩上。
5. 结语:数据从业者的黄金时代
张宇的分享描绘蓝图:通过精细策略、实验方法和模型理解,数据工作者将成为AI推动者。Kimi Linear不仅是技术验证,更是行业启发——线性注意力路线正收敛,Efficient Attention成焦点。
如果你在大模型领域奋斗,不妨从张宇的经验起步:Scale自己的东西,而不是对线。欢迎评论你的数据心得,一起推动AI前进!
参考资源:
(本文基于公开分享整理,如有疑问欢迎讨论。)

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐

 30
30 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)