GLM-TTS 发布:3 秒音色复刻 + 工业级语音合成,模型权重已开源
工业级语音合成系统 GLM-TTS 正式发布,并已开放模型权重。它用约 10 万小时数据训练,实现了“3 秒”音色复刻与更强的文本理解能力,并在多个开源测试集上把字错误率与情感表达做到了开源SOTA
智谱 AI 正式发布工业级语音合成系统 GLM-TTS,并宣布在Hugging Face和ModelScope 上开放模型权重 。
作为智谱在语音领域的最新力作,GLM-TTS 基于在数据筛选、基础模型结构、精品音色监督微调(SFT)及强化学习(RL)等多方面的技术创新 。仅在 10w 小时数据上训练,便具备了“3秒”音色复刻和超强文本理解能力,在多个开源测试集上实现 SOTA 。
效果炸裂:情感SOTA与3秒克隆
-
全能情感复刻: 模型能根据文本内容的情绪,自动匹配对应的语音情感 。在权威测试集(CV3-eval-emotion)中,GLM-TTS 在 Happy(开心)、Sad(悲伤)、Angry(愤怒)三类情感维度均取得“最佳表现” 。
-
碾压商用模型: 数据显示,相比 Qwen3-TTS、豆包 TTS-2.0 等商用模型在负向情感(如悲伤、愤怒)上得分多为 0 的情况,GLM-TTS 的平均情感得分高达 0.51,展现了极强的拟人化能力 。
-
方言与极速克隆: 支持四川话、东北话等方言克隆,且仅需3秒提示音频即可完成高保真音色复刻 。
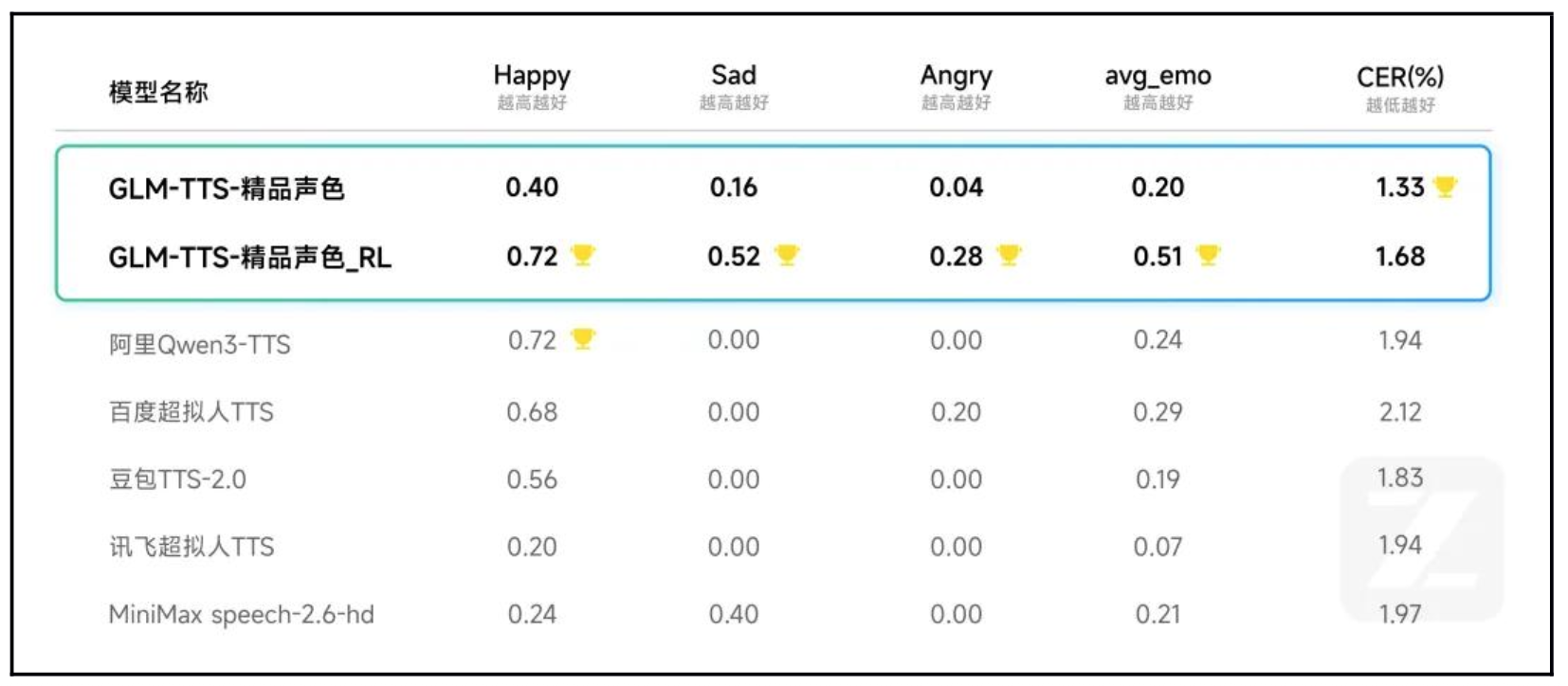
评测数据显示,GLM-TTS在悲伤、愤怒等高难度负向情感上全面领先商用模型
硬核架构:RL强化学习+LoRA定制
GLM-TTS 是一套基于两阶段生成范式(Text-to-token & Token-to-wav)的高质量系统 。为了解决传统 TTS 的痛点,智谱此次带来了多项“黑科技”:
-
引入强化学习 (RL): 这是本次最大的技术亮点之一。GLM-TTS 创新引入 GRPO 算法框架,融合了 CER(字错误率)、相似度、情感及笑声(Laughter)的多维度奖励机制 。通过动态采样与梯度裁剪,显著提升了语音的拟人化程度,让 AI 学会了“呼吸”和“笑” 。
-
低成本 LoRA 定制: 传统全参微调成本高昂,而 GLM-TTS 优化的 LoRA 范式仅需微调 15% 的参数,配合约 1 小时的单一说话人数据,即可达到与全参微调相当的效果 。
-
精准发音控制 (Phoneme-in): 针对“行(xíng/háng)”等多音字和生僻字难题,提出了“Hybrid Phoneme + Text”混合输入形式,实现了对发音的精准定向控制,完美适配教育评测等高精度场景 。
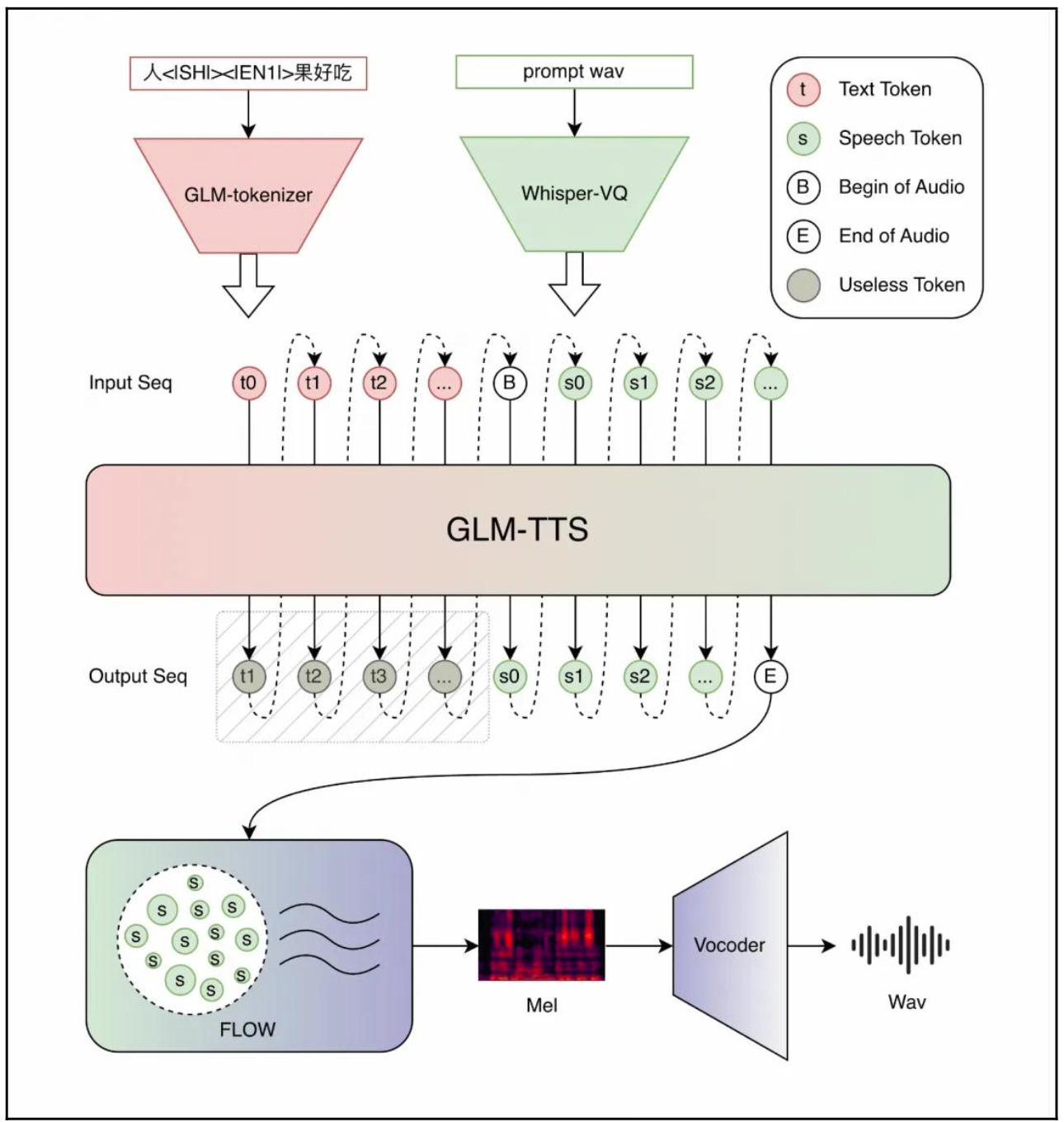
系统采用“Text-to-token + Token-to-wav”两阶段生成范式,配合自研2D-Vocos声码器,确保了高保真的语音合成效果
数据说话:开源模型中的新标杆
一切用数据说话。在各项权威评测中,GLM-TTS 均展现出了“霸榜”级的实力:
-
CER 击穿底线: 在 seed-tts-eval 中文测试集中,GLM-TTS_RL 的字错误率(CER)低至 0.89% 。
-
超越开源 SOTA: 这一成绩显著优于 CosyVoice2 (1.38%)、VoxCPM (0.93%)、IndexTTS2 (1.03%) 等主流开源模型,甚至逼近闭源模型的顶尖水平 。
-
音色高保真: 在保证极低错误率的同时,音色相似度(Sim)提升至 76.4,实现了“发音精准+音色相似”的双重领先 。
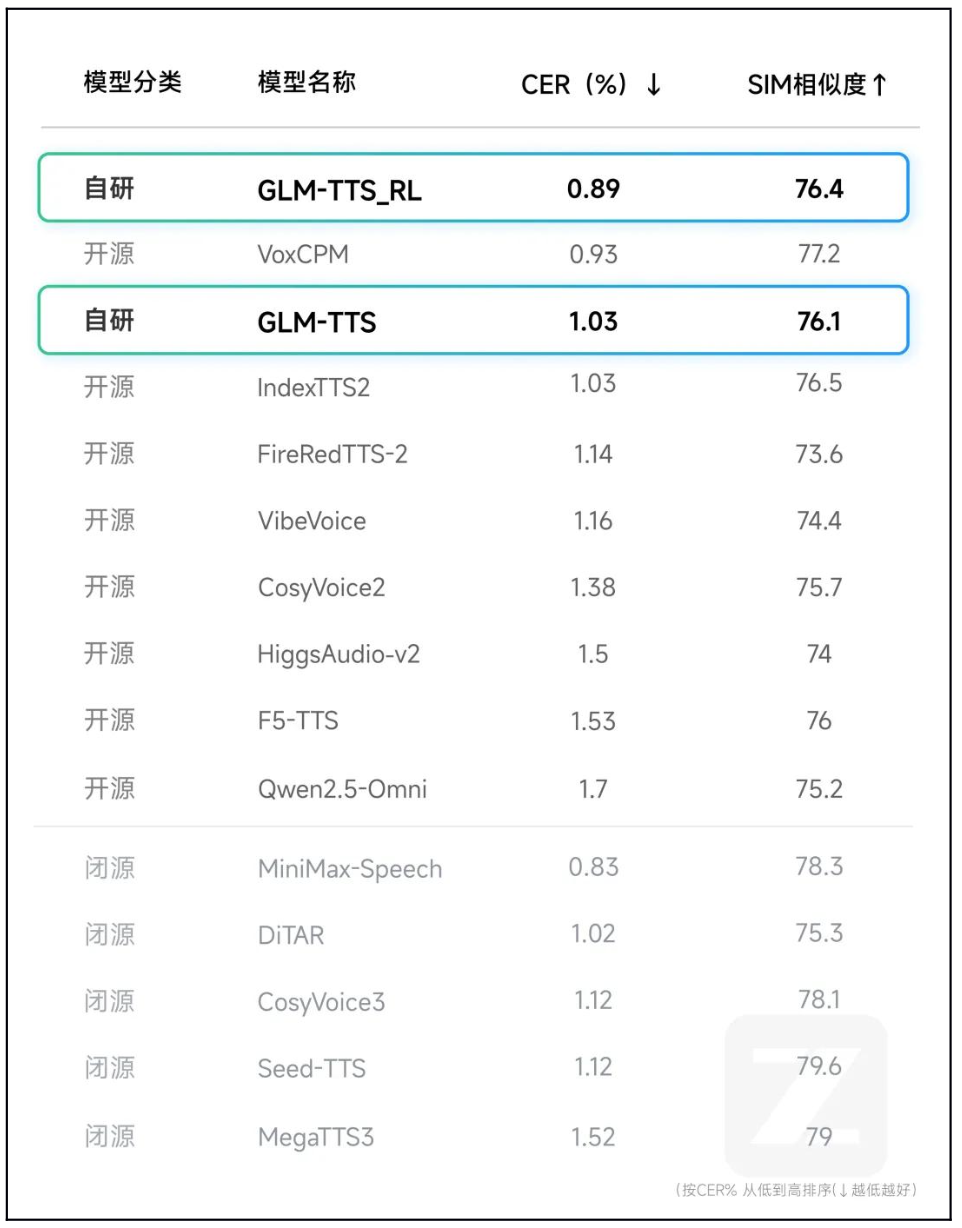 GLM-TTS_RL以0.89%的极低字错误率(CER)超越CosyVoice2等主流模型,成功刷新开源 SOTA 记录
GLM-TTS_RL以0.89%的极低字错误率(CER)超越CosyVoice2等主流模型,成功刷新开源 SOTA 记录
立即体验与下载
GLM-TTS 现已全面开放,开发者和企业用户可以通过以下方式即刻上手:
💻 在线体验:
-
Z.ai平台: audio.z.ai
-
智谱清言:APP 或网页版 (chatglm.cn)
👨💻 模型下载与开源:
-
GitHub:https://github.com/zai-org/GLM-TTS
-
Hugging Face:https://huggingface.co/zai-org/GLM-TTS
-
魔搭社区: https://modelscope.cn/models/ZhipuAI/GLM-TTS
☁️ API 调用: 企业用户可通过开放平台 BigModel 直接调用模型 API,支持从 Demo 试用到生产级大规模调用的多种配置


火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 18
18 0
0- 0



 已为社区贡献36条内容
已为社区贡献36条内容

所有评论(0)