基于opencv的苹果识别模型
·
import cv2
import numpy as np
from sklearn.svm import SVC
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.feature_selection import SelectKBest, f_classif
import os
import random
def preprocess(img_path):
"""增强版图像预处理"""
img = cv2.imread(img_path)
if img is None:
print(f"警告:无法读取图像 {img_path}")
return None
# 数据增强
# 随机旋转
angle = random.uniform(-15, 15)
M = cv2.getRotationMatrix2D((128, 128), angle, 1)
img = cv2.warpAffine(img, M, (256, 256))
# 随机缩放
scale = random.uniform(0.9, 1.1)
img = cv2.resize(img, None, fx=scale, fy=scale)
# 灰度转换
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 自适应阈值
thresh = cv2.adaptiveThreshold(gray, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C,
cv2.THRESH_BINARY_INV, 15, 3)
# 形态学优化
kernel = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (7, 7))
closed = cv2.morphologyEx(thresh, cv2.MORPH_CLOSE, kernel)
# 轮廓提取
contours, _ = cv2.findContours(closed, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
if not contours:
return None
return max(contours, key=cv2.contourArea)
def extract_features(contour):
"""增强特征提取"""
# 基础特征
rect = cv2.minAreaRect(contour)
w, h = rect[1]
aspect_ratio = max(w, h) / (min(w, h) + 1e-6)
epsilon = 0.02 * cv2.arcLength(contour, True)
approx = cv2.approxPolyDP(contour, epsilon, True)
sharp_points = len(approx)
# 新增特征
area = cv2.contourArea(contour)
perimeter = cv2.arcLength(contour, True)
circularity = (4 * np.pi * area) / (perimeter ** 2 + 1e-6)
area_ratio = area / (256 * 256)
# 凸包缺陷检测
hull = cv2.convexHull(contour, returnPoints=False)
defects = cv2.convexityDefects(contour, hull)
defect_count = 0 if defects is None else len(defects)
return [aspect_ratio, sharp_points, circularity, area_ratio, defect_count]
def load_dataset(data_dir):
"""数据加载与验证"""
X, y = [], []
classes = ['apple', 'unapple']
# 数据分布检查
for label, class_name in enumerate(classes):
class_path = os.path.join(data_dir, class_name)
if not os.path.exists(class_path):
raise FileNotFoundError(f"目录不存在: {class_path}")
img_count = len(os.listdir(class_path))
print(f"{class_name} 样本数: {img_count}")
# 加载数据
for img_name in os.listdir(class_path):
contour = preprocess(os.path.join(class_path, img_name))
if contour is not None:
X.append(extract_features(contour))
y.append(label)
if len(X) == 0:
raise ValueError("未加载到有效数据,请检查路径和图像格式")
return np.array(X), np.array(y)
# 主程序
if __name__ == "__main__":
# 数据集配置
data_dir = "./" # 包含apple和unapple子目录
X, y = load_dataset(data_dir)
# 特征选择
selector = SelectKBest(f_classif, k=3)
X_selected = selector.fit_transform(X, y)
# 数据标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X_selected)
# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, stratify=y)
# 参数调优
param_grid = {
'C': [0.5, 1, 5],
'gamma': ['scale', 'auto'],
'class_weight': [None, 'balanced']
}
grid = GridSearchCV(SVC(kernel='rbf', probability=True), param_grid, cv=5)
grid.fit(X_train, y_train)
best_model = grid.best_estimator_
# 模型评估
print(f"最优参数: {grid.best_params_}")
print(f"测试集准确率: {best_model.score(X_test, y_test):.2%}")
# 预测函数(带阈值)
def predict_image(img_path, threshold=0.7):
contour = preprocess(img_path)
if contour is None:
print("未检测到有效轮廓")
return
features = selector.transform([extract_features(contour)])
scaled_features = scaler.transform(features)
proba = best_model.predict_proba(scaled_features)[0]
result = "苹果" if proba[0] >= threshold else "非苹果"
print(f"{img_path}: {result} (置信度: {max(proba):.2%})")
# 批量测试
test_images = ["img.png", "img_1.png", "img_4.png",'img_2.png']
for img in test_images:
predict_image(img)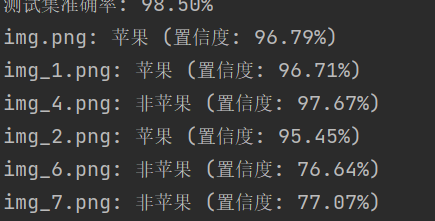
1-6分别为红苹果,绿苹果,香蕉,火龙果,西瓜和雪梨
可见对于区分度较为明显的水果还是有较高的准确率,但是容易把一些形状颜色都及其相似的水果识别为苹果

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐


 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)