论文项目:DCM代码阅读 | Dual-Expert Consistency Model for Efficient and High-Quality Video Generation
本文(Dual-Expert Consistency Model, DCM):其中。DCM 在的同时,仍能,验证了双专家机制在视频扩散模型蒸馏中的有效性。
论文地址:https://arxiv.org/pdf/2506.03123
项目地址:https://github.com/Vchitect/DCM.
简读地址:https://baijiahao.baidu.com/s?id=1835258565315131045&wfr=spider&for=pc
提出背景:
本文通过分析一致性模型的训练动态,发现蒸馏过程中存在一个关键的冲突性学习机制:在不同噪声水平的样本上,优化梯度和损失贡献存在显著差异。这种差异使得蒸馏得到的学生模型难以达到最优状态,最终导致时序一致性受损、画面细节下降。
解决思路:
本文提出了一种参数高效的双专家一致性模型(Dual-Expert Consistency Model, DCM):其中 Semantic Expert 负责学习语义布局和运动信息,Detail Expert 则专注于细节的合成。此外,引入了 Temporal Coherence Loss 以增强语义专家的运动一致性,并引入 GAN Loss 与 Feature Matching Loss 以提升细节专家的合成质量。
有益效果:
DCM 在显著减少采样步数的同时,仍能达到当前相当的视觉质量,验证了双专家机制在视频扩散模型蒸馏中的有效性。
1、算法设计
DCM将模型蒸馏分为两步实现,先进行sem阶段蒸馏,再进行det阶段蒸馏
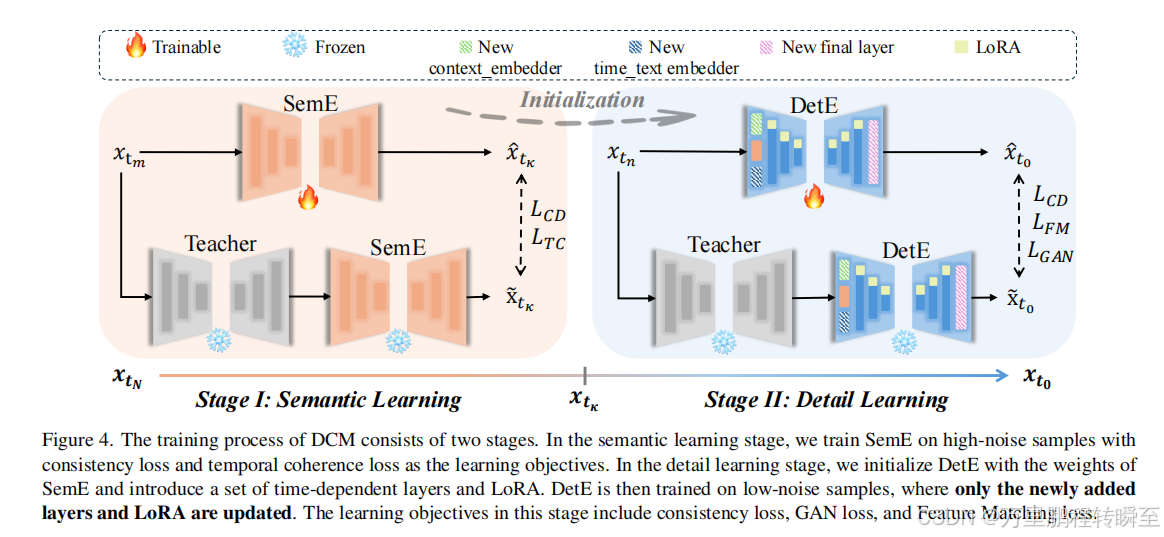
1.1 Sem蒸馏
Sem蒸馏时,SemE模型与Teacher模型保持相同的模型结构,基于 L C D L_{CD} LCD、 L T C L_{TC} LTCloss进行全量参数蒸馏。
Consistency Distillation
L C D L_{CD} LCD==》Consistency Distillation( 一致性蒸馏)采用预训练模型ϵθ作为tescher,将知识蒸馏到以ϵθ初始化的SemE中,从而实现更少步骤的快速采样[54]。具体而言,该方法通过训练SemE,使其能够直接将ODE求解器Φ解轨迹上的任意点xtn映射至其终点xtend。学习目标可表述为:

公式里面的Fs为SemE,及学生模型。 F S − F^{-}_S FS−为指数移动平均下的student模型,其输入为tescher模型的输出。
这里可以看出,上下两个链路经历的去噪过程有差异。上面链路,进行一次性去噪;下面的双模型链路,先基于教师模型去除一个时间步的噪声,再由EMA 学生模型进行n-1次去噪。两次的差异的L2距离为 L C D L_{CD} LCD
Temporal Coherence Loss
L T C L_{TC} LTC==》Temporal Coherence Loss( 时序连续性loss),为了增强语义专家去噪器SemE合成视频的时间一致性,引入了时间一致性损失函数 L T C L_{TC} LTC,该函数能够强调并引导SemE关注不同帧之间对应位置的动态变化和运动特征:
其中 x l : L t κ x^{t_κ}_{l:L} xl:Ltκ:L表示沿时间轴从第l到第L个通道的视频潜在特征。这种时间相干性损失机制促使语义专家去噪器FSemE能够保持帧间运动和空间关系的一致性,从而确保视频合成过程更加流畅自然。
这里主要是,将latent在时间维度进行切片,然后进行做差。让学生模型的差,与教师模型的差保持一致。
1.2 Det蒸馏
Det蒸馏时,DetE模型与Teacher模型结构有一定差异,有多个新增参数,基于 L C D L_{CD} LCD、 L F M L_{FM} LFM、 L G A N L_{GAN} LGANloss进行lora。
Generative Adversarial Loss Gan损失在多种分布匹配蒸馏方法中,已得到验证。我们将GAN损失引入细节专家降噪器的训练过程中,并结合特征匹配损失来稳定训练过程。首先通过细节专家降噪器DetE、教师模型FT和ODE求解器Φ获取初始数据xt0和xˆt0:
然后执行前向过程,并对其施加噪声以生成的伪造样本 x f a k e x_{fake} xfake和真实样本 x r e a l x_{real} xreal。
采用冻结的教师模型作为特征提取主干网络Ω,通过固定步长提取中间特征来计算GAN损失和特征匹配损失LFM。在训练过程中,我们迭代更新FDetE和判别器头部fD的参数。

1.3 消融实验
作者进行了6个消融实验。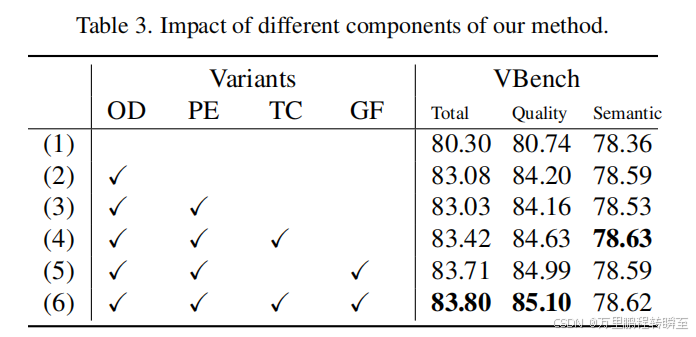
通过实验(1)和(2)验证优化解耦(OD)效果:将语义建模与细节建模的优化过程分离,能显著提升语义质量与画质评分。如图7所示,经过优化的解耦模型生成的视频在语义表达和细节呈现上表现更优,人物动作与面部细节都显得更加自然逼真。

通过实验(2)和(3),我们观察到,与简单地将优化过程拆分为两个独立的模型训练过程相比,参数高效双专家蒸馏(PE)具有显著优势。双专家蒸馏技术在显著降低参数需求和内存占用的同时,保持了图像质量,且计算开销极小。图7的最后两行数据也表明,我们这种参数优化的双专家方法不会导致视觉效果出现明显下降。
时间相干性损失(TC)的影响通过对比实验(3)与(4)、或(5)与(6),我们发现引入时间相干性损失能显著提升合成视频的质量评分。如图8所示,采用TC损失可使视频运动更加自然流畅,并增强画面一致性。
生成对抗网络(GAN)与特征匹配损失(GF)的作用通过对比实验(3)与(5)、或(4)与(6),我们观察到引入GAN损失能有效提升合成视频的质量评分。如图9所示,添加GAN损失和特征匹配项可增强合成视频细节的真实感。
κ的选取。我们基于推理过程的分析确定了κ的值。图10(左)展示了HunyuanVideo在采样过程中相邻时间步长采样结果之间的L1距离变化。可以观察到,从大约第37步开始,L1距离逐渐下降至极小值。我们认为这是语义内容与布局确定的关键节点,后续步骤主要集中在高频细节的合成上。因此我们将κ设为默认值37。为评估不同κ值的影响,我们分别测试了κ = 28、35、37、39、46。如图10(右)所示,结果表明当κ偏离语义合成与细节合成的过渡点时,视频质量会逐渐下降。这进一步验证了我们优化解耦策略的有效性。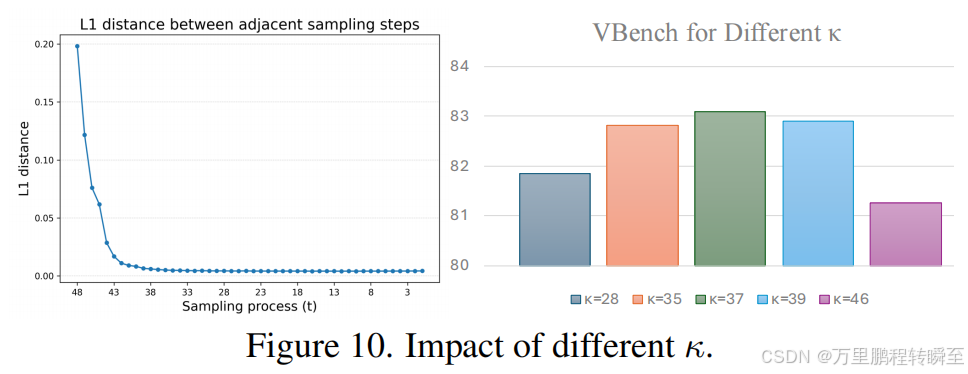
2、相关代码
2.1 Sem蒸馏
distill_dcm_wan_semantic_expert.py 中 distill_one_step函数
模型初始化,三个模型基于相同的参数进行初始化
学生模型参数可更新,教师模型、ema模型不需要梯度。
forward流程 学生链路(euler_step,单步噪声;euler_style_multiphase_pred,多步噪声;)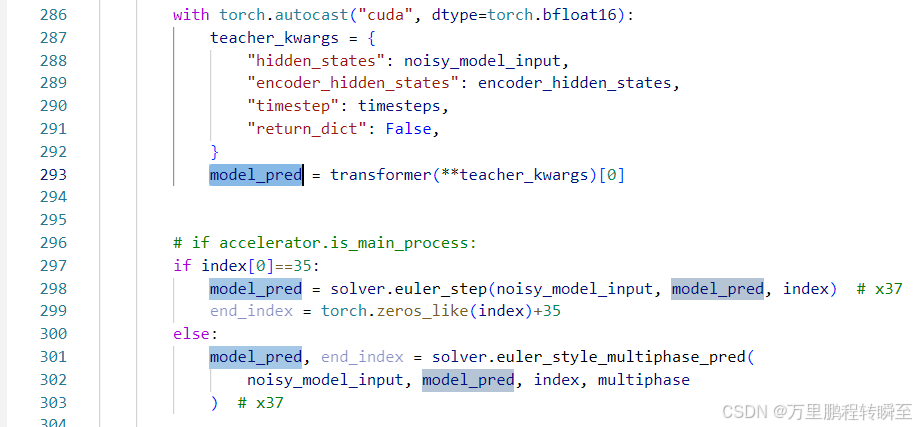
forward流程 教师链路(先由教师模型进行一次去噪,若时间步为35,则为target;否则,由ema_transformer进行第二次去噪)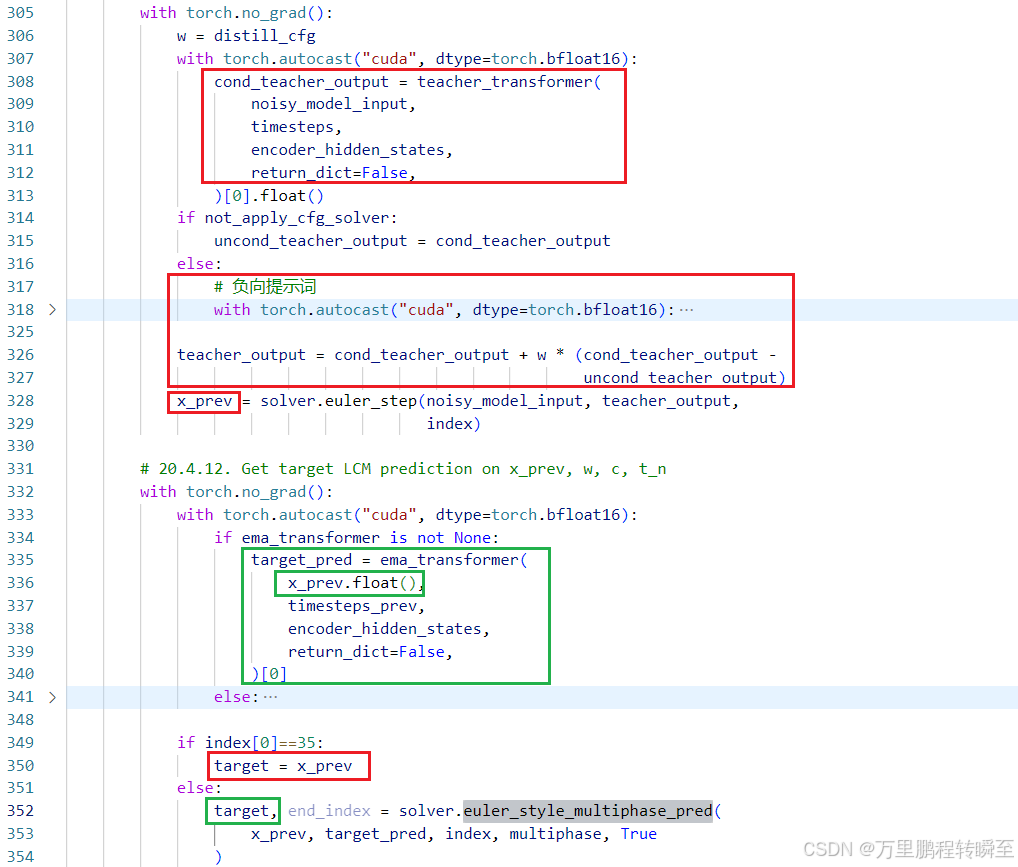
loss TC
if model_pred.shape[2]>3:
loss_tc = torch.nn.functional.mse_loss((model_pred[:,:,3:]-model_pred[:,:,:-3]), (target[:,:,3:]-target[:,:,:-3]))
else:
loss_tc = 0
loss CD
model_pred为学生模型输出求解后的噪声,target为教师模型=》ema_transformer模型输出求解后的噪声
loss = (torch.mean(
torch.sqrt((model_pred.float() - target.float())**2 + huber_c**2) -
huber_c) / gradient_accumulation_steps) + loss_tc
ema模型参数更新
# update ema
if ema_transformer is not None:
reshard_fsdp(ema_transformer)
for p_averaged, p_model in zip(ema_transformer.parameters(),
transformer.parameters()):
with torch.no_grad():
p_averaged.copy_(
torch.lerp(p_averaged.detach(), p_model.detach(),
1 - ema_decay))
2.2 Det蒸馏
distill_dcm_wan_detail_expert.py中distill_one_step_adv函数。
det阶段蒸馏时,模型引入额外参数,同时forward流程也被调整。整个代码中,只看到了gan loss。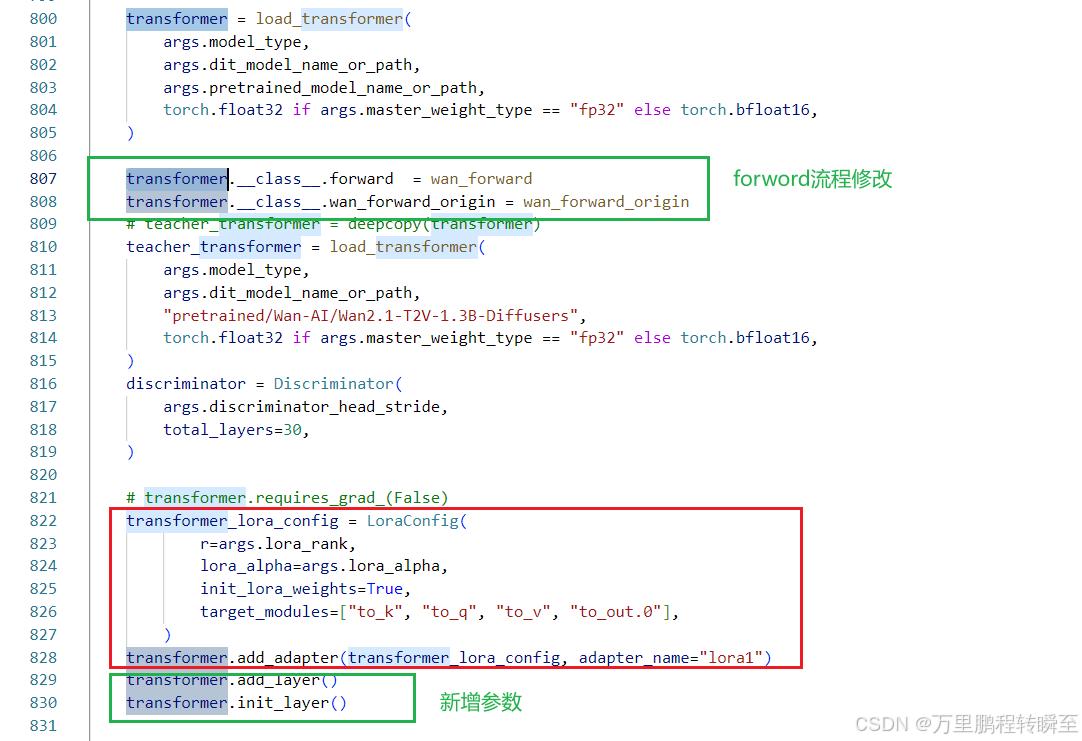
新增参数如下,condition_embedder_lora是对输入变量进行处理,norm_out_lora与proj_out_lora是对输出变量进行处理。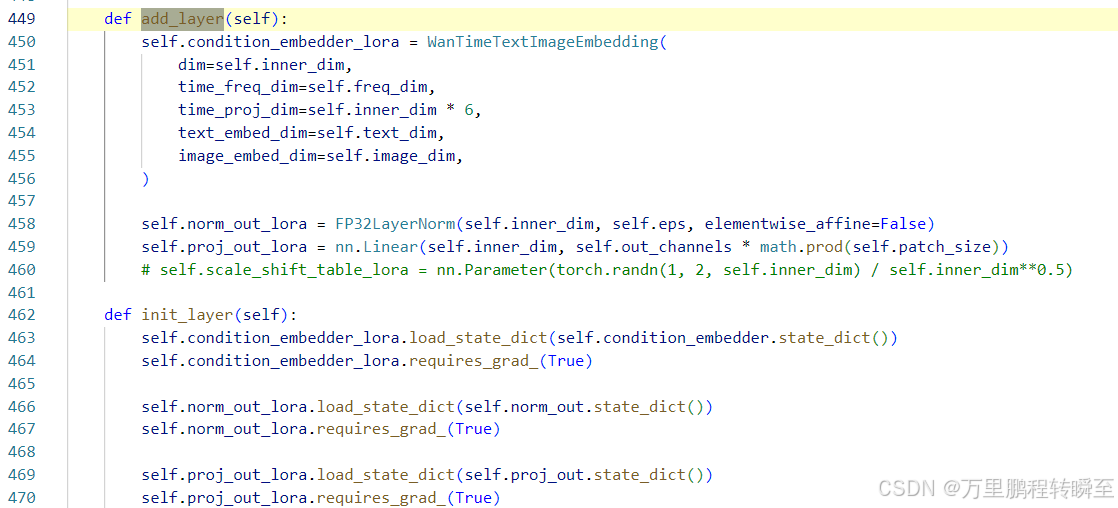
调整后的forward流程如下,教师模型按照原来的链路走;学生模型 且 timestep小于981时,走新链路(及前面的新增参数+lora)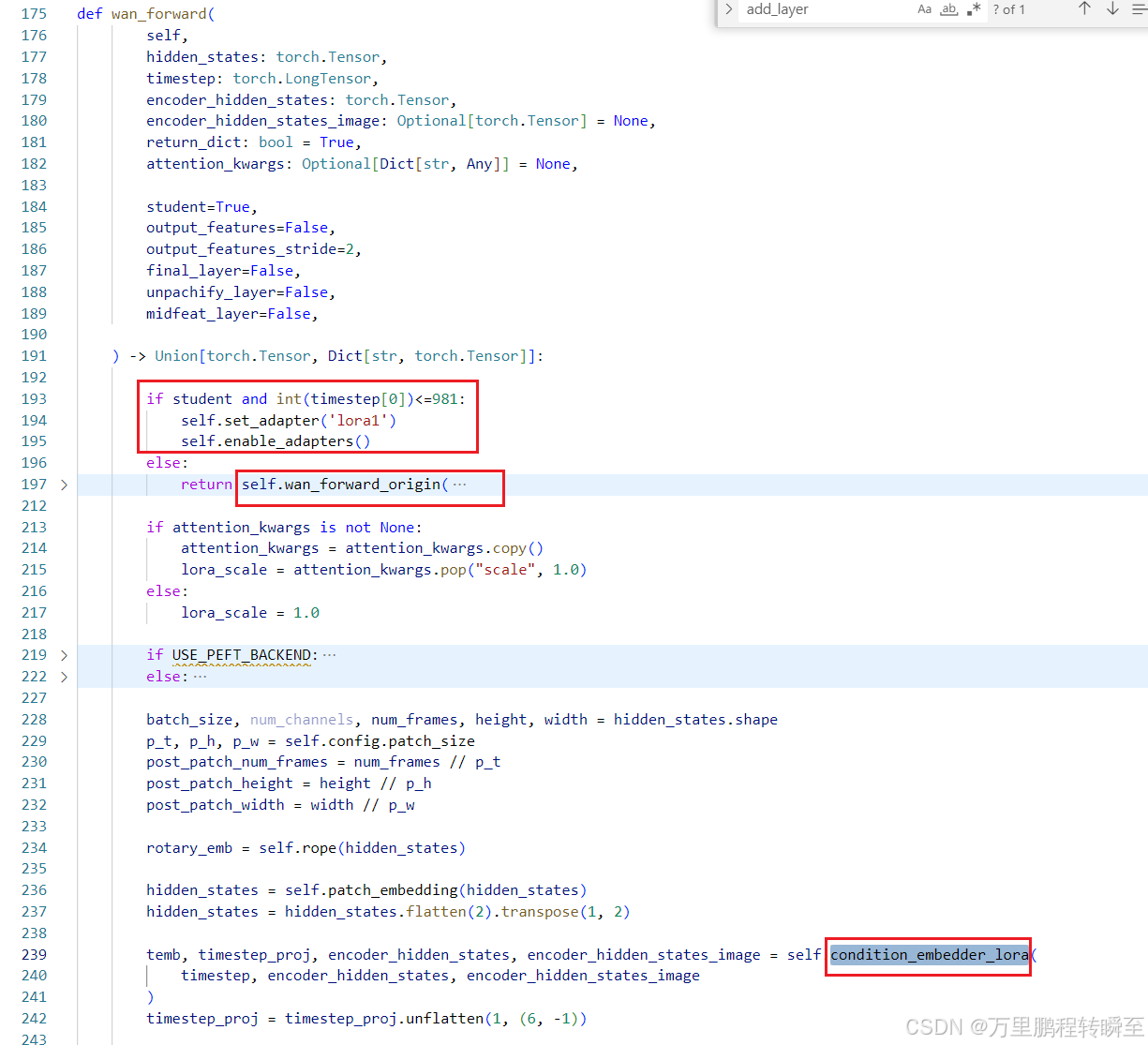
学生模型输出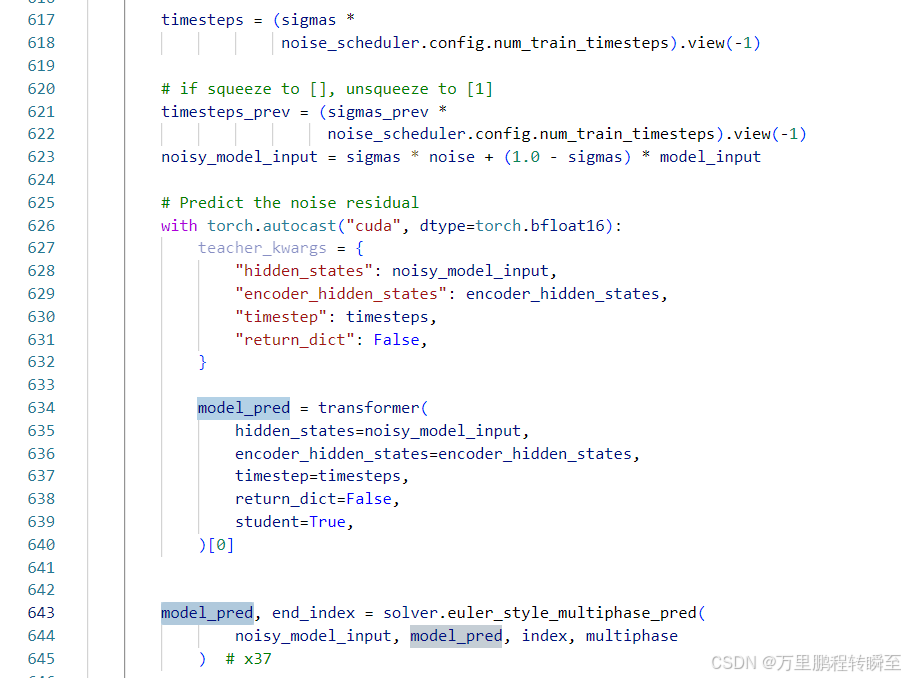
教师模型输出 先由教师模型对输出进行一步去噪,再由学生模型进行n-1步的噪声预测。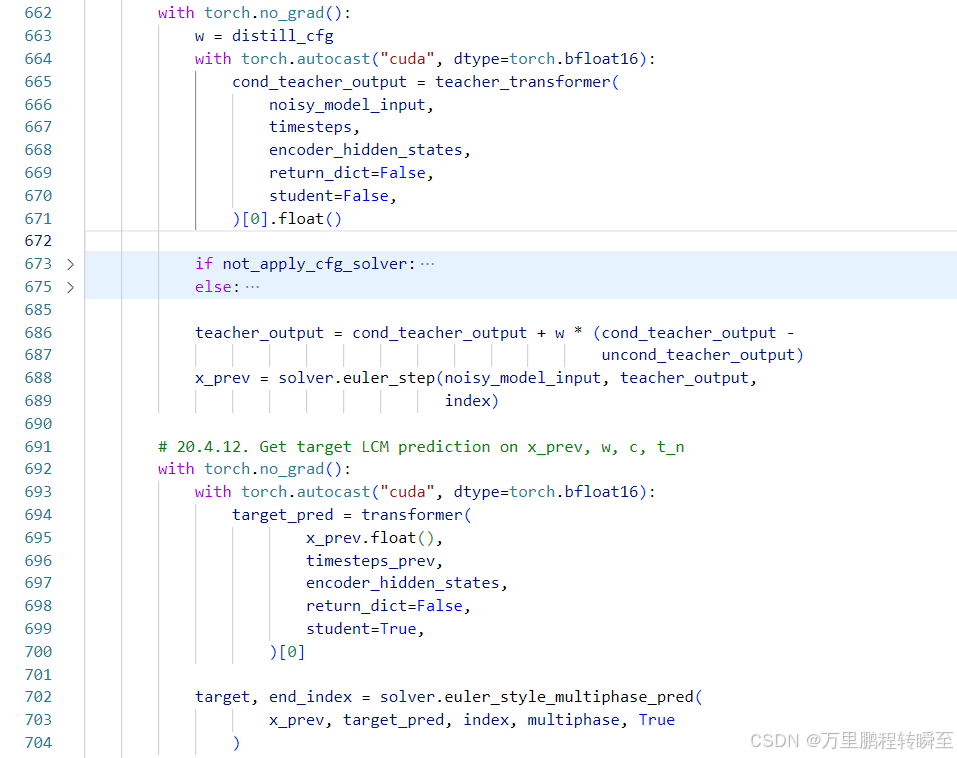
Gan 优化 先基于判别器计算loss,更新生成器。然后再次优化判别器。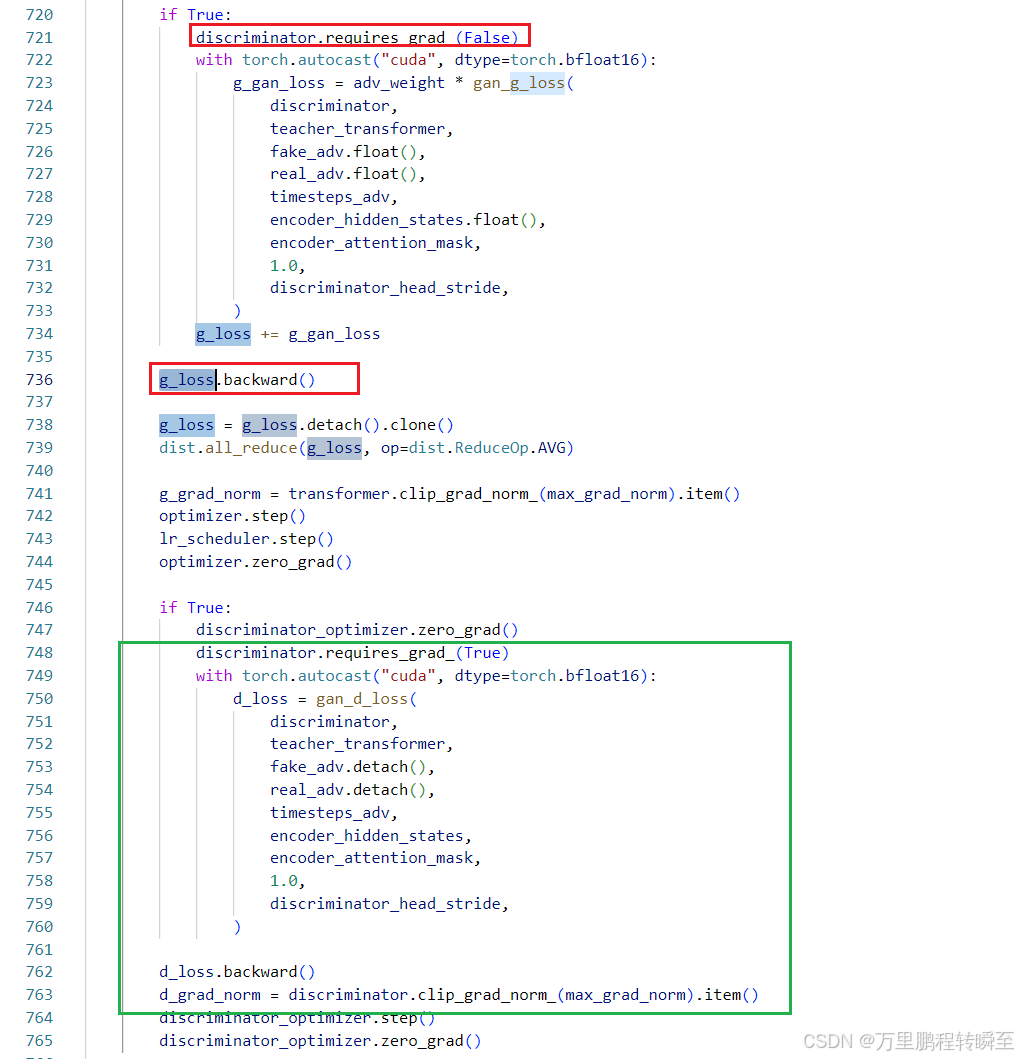
生成器loss 让判别器对于sample_fake==》teacher_transformer处理链路===》输出的features_ori接近1,即通过梯度链路,调节teacher_transformer输入数据中对于学生模型的参数;同时使基于sample_fake,sample_real 生成features,features_real mseloss最小化。
def gan_g_loss(
discriminator,
teacher_transformer,
sample_fake,
sample_real,
timestep,
encoder_hidden_states,
encoder_attention_mask,
weight,
discriminator_head_stride,
):
loss = 0.0
(_, features, features_ori) = teacher_transformer(
sample_fake,
timestep,
encoder_hidden_states,
output_features=True,
output_features_stride=2,
return_dict=False,
final_layer=True,
unpachify_layer=True,
student=False,
)
with torch.no_grad():
(_, features_real,features_real_ori) = teacher_transformer(
sample_real,
timestep,
encoder_hidden_states,
output_features=True,
output_features_stride=2,
return_dict=False,
final_layer=True,
unpachify_layer=True,
student=False,
)
loss_feat = torch.nn.functional.mse_loss(features,features_real) * 10.0
fake_outputs = discriminator(features_ori,)
for fake_output in fake_outputs:
loss += torch.mean(weight * torch.relu(1 - fake_output.float())) / (
discriminator.head_num * discriminator.num_h_per_head
)
loss = loss * 5.0
return loss + loss_feat
判别器loss 让fake_output接近0(-1),让real_output接近1。即,拉开discriminator对于fake_features_ori,real_features_ori的判别距离。
def gan_d_loss(
discriminator,
teacher_transformer,
sample_fake,
sample_real,
timestep,
encoder_hidden_states,
encoder_attention_mask,
weight,
discriminator_head_stride,
):
loss = 0.0
# collate sample_fake and sample_real
with torch.no_grad():
(_, fake_features, fake_features_ori) = teacher_transformer(
sample_fake,
timestep,
encoder_hidden_states,
output_features=True,
output_features_stride=2,
return_dict=False,
final_layer=True,
unpachify_layer=True,
student=False,
)
(_, real_features, real_features_ori) = teacher_transformer(
sample_real,
timestep,
encoder_hidden_states,
output_features=True,
output_features_stride=2,
return_dict=False,
final_layer=True,
unpachify_layer=True,
student=False,
)
fake_outputs = discriminator(fake_features_ori)
real_outputs = discriminator(real_features_ori)
for fake_output, real_output in zip(fake_outputs, real_outputs):
loss += (
torch.mean(weight * torch.relu(fake_output.float() + 1))
+ torch.mean(weight * torch.relu(1 - real_output.float()))
) / (discriminator.head_num * discriminator.num_h_per_head)
return loss
2.3 推理链路代码
这里跟Det阶段的forward是高度一致的。先添加layer,然后加载权重,最后替换forward函数。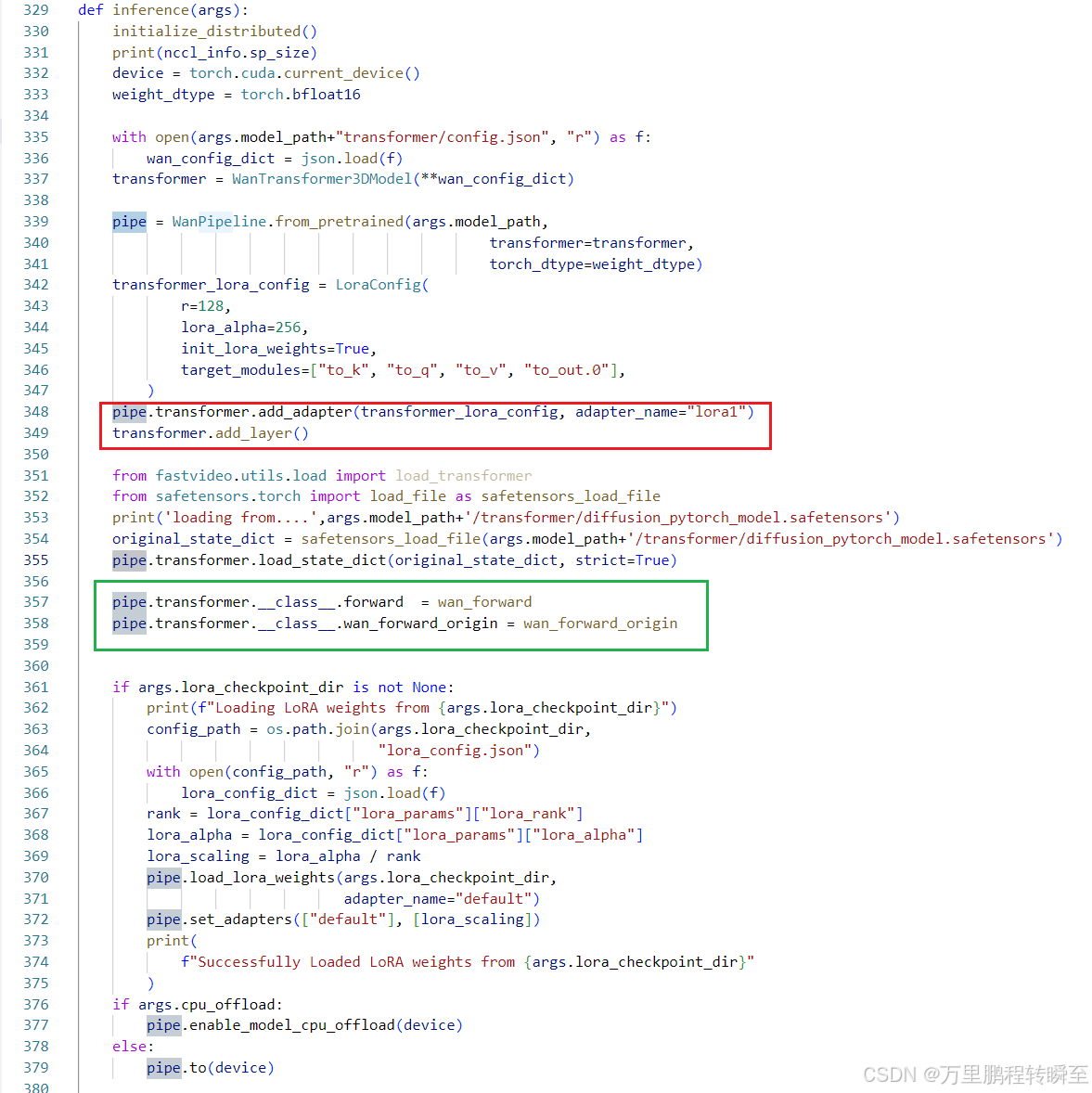
同时对cus_timesteps进行约束。
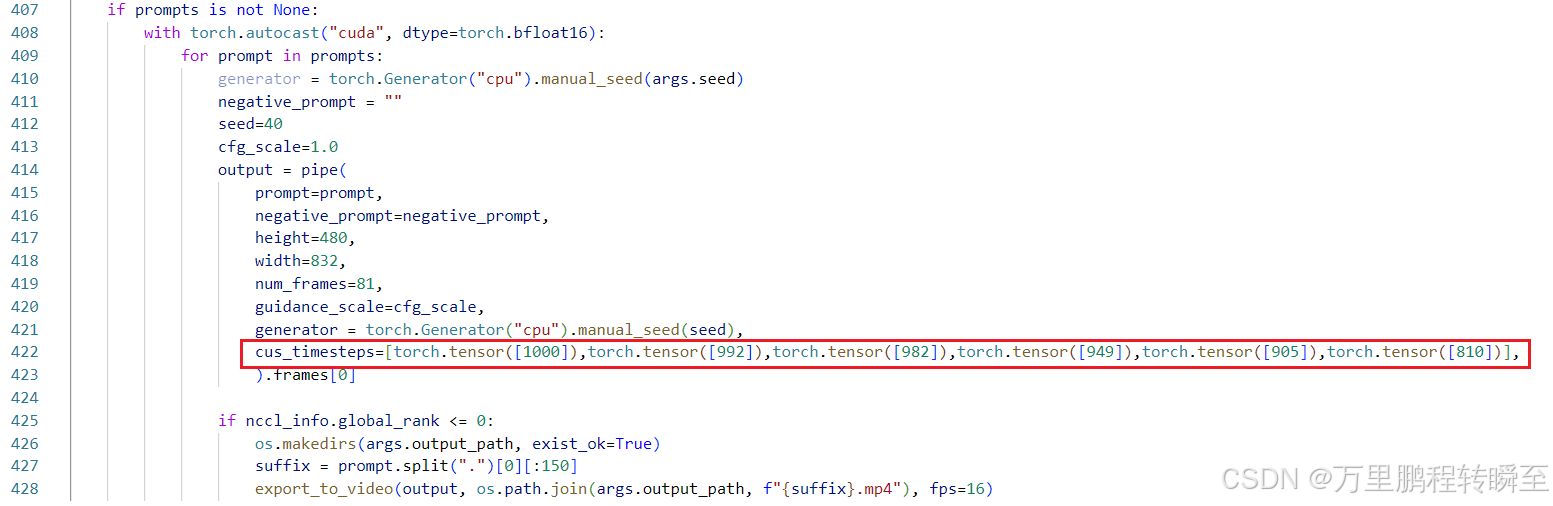
3、算法效果
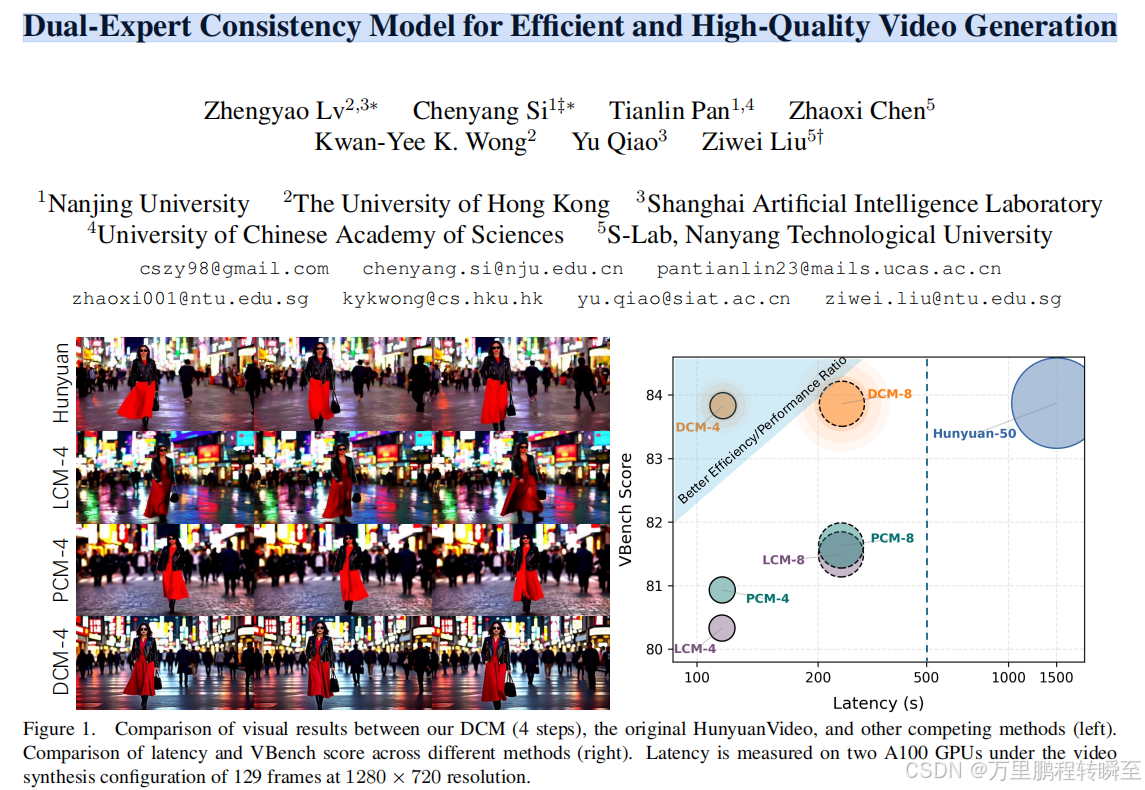
3.1 耗时优化
以hunyuan模型为例,可以发现DCM技术蒸馏后的模型,将推理耗时从1500s降低到100s内(两个A100显卡,129帧720p视频)

可以发现,DCM 4步推理对于hunyuan与CogVideoX模型的速度增益是不一致的。对于CogVideoX模型,4步推理,速度提升20倍以上。但对于Hunyuan模型,只提升了7倍。
3.2 构图对比
同时DCM蒸馏后的模型输出,在构图上(主体出现的形态与位置,)与原始模型输出是高度一致的。

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 14
14 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)