Seed LiveInterpret 2.0: End-to-end Simultaneous Speech-to-speech Translation with Your Voice
abstract
- 基于文本模型,加入音频模态,能够同时做speech2speech translation,asr,tts
- 通过强化学习的方法,在翻得快(不用src 整句说完)和翻得准方面都取得提升
- 可以在翻译的同时clone your voice,但是这部分没有介绍。
method
- Q: 具体怎么实现“是否应该听(不抢话)、是否应该说(不拖沓)"
- SFT阶段:组织的是 < a u d i o 0 , y 0 , a u d i o 1 , y 1 > <audio_0,y_0, audio_1, y_1> <audio0,y0,audio1,y1>的序列串,其中y是翻译目标。不仅教会了模型翻译的基础能力,也教会了它初步的、模仿性的时机决策能力。—依赖高质量的同传数据,audio_0和y_0的音频片段需要语义一致;
- RL 阶段:每一个token输入都通过策略函数进行决策,
- 是否倾听—当前音频输入对应的输出预测为EOS,只有【真值=0,预测=0】—0: 沉默倾听,才给奖励 1*1,其他case都给惩罚;【真值=1,预测=1】也给惩罚是因为何时说话有另外的决策判断,简化单个决策的任务复杂度;
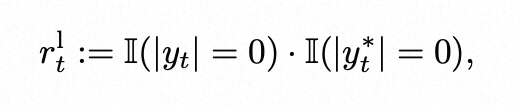
- 是否该说话—输出预测是真实的translation speech token(隐式的决策),公式表示在 audio_t 这个时间点,真值和预测都是有内容的;
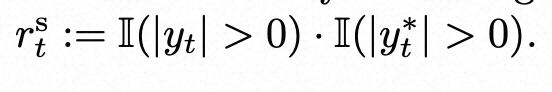
- 是否倾听—当前音频输入对应的输出预测为EOS,只有【真值=0,预测=0】—0: 沉默倾听,才给奖励 1*1,其他case都给惩罚;【真值=1,预测=1】也给惩罚是因为何时说话有另外的决策判断,简化单个决策的任务复杂度;
奖励函数
单轮奖励 (Single-turn Reward)
这类奖励提供即时的、细粒度的反馈,在每个翻译小步骤(t-chunk)后进行评估,主要目标是保证内部段落的一致性 (intra-segment consistency)。
它包含了以下 5个 独立的奖励函数:
-
rl - Detection Accuracy Reward (侦测准确性奖励)
目标: 教会模型**“何时该沉默”**。
机制: 当参考答案是“沉默”而模型也“沉默”时,给予奖励。
作用: 防止模型在信息不足时“抢话”。 -
rs - Translation Initiative Reward (翻译主动性奖励)
目标: 教会模型**“何时该说话”**。
机制: 当参考答案是“有内容”而模型也“有内容”时,给予奖励。
作用: 鼓励模型在语义单元形成后,及时开始翻译,避免“拖沓”。 -
rq - Translation Quality Reward (翻译质量奖励)—降维到文本域进行处理
目标: 教会模型**“说得对”**。
机制: 衡量模型输出的翻译 y_t 与参考翻译 y*_t 之间的质量/相似度。
作用: 保证翻译的核心——准确性。 -
rc - Time Compliance Reward (时间合规性奖励)
目标: 教会模型**“说话速度要合适”**。
机制: 比较模型生成语音的时长与参考语音的时长。时长越接近,奖励越高。
作用: 防止模型为了说全内容而语速过快,或者为了省事而说得太短。 -
rf - Format Consistency Reward (格式一致性奖励)
总结一下:rf 就是用正则表达式等基于规则的方法,来检查模型的输出是否存在不完整、不合语法、格式错误等问题,从而保证生成内容的结构化和规范性。不关心内容对不对,只关心形式好不好。它与 rq 形成互补,共同引导模型生成既准确又结构良好、听起来自然的翻译。目标: 教会模型**“说话要合乎规范”**。
机制: 通过正则表达式匹配,检查模型的输出是否符合预定义的结构或格式。
作用: 保证输出的结构正确,例如避免产生不合语法的句子片段。
多轮奖励 (Multi-turn Reward)
这类奖励在整个翻译序列结束后进行评估,提供全局的、宏观的反馈,主要目标是保证跨段落的连贯性 (inter-segment coherence)。
它包含了以下 2个 独立的奖励函数:
- rL - Lagging Reward (延迟奖励)
目标: 控制累积延迟,防止翻译越来越慢。
机制: 惩罚长时间的等待。计算在每次翻译输出前,模型“等待”了多少个音频块,如果等待时间过长(超过阈值 l 或平均等待时间过长),则给予负奖励(惩罚)。
作用: 解决单轮奖励无法捕捉到的“积压延迟”问题,保证全局的实时性。 - rQ - Sequence-level Translation Quality Reward (序列级翻译质量奖励)
目标: 保证整段话翻译得好。
机制: 在整个序列结束后,评估完整的翻译输出 y 与源语音 audio 之间的对齐/质量。
作用: 弥补单轮奖励的“短视”,从全局视角确保翻译的连贯性和完整性。
整体设计
- 常规的PPO 算法的缺点:
- 容易被模型钻奖励函数的空子,比如最优化长度策略,但是整体翻译质量并不高;
- 多项奖励函数之间优化难度不一,导致失衡,仅通过调loss weight的方式费劲且效果不好;
- 优化设计
-
自适应KL惩罚 :在语音+文本混合序列中,序列通常很长,KL散度值会自然累积得很高。因此,固定的KL惩罚系数 β 很难设定。
作者采用了一种自适应调整 β 的方法:设定一个目标KL散度值 KL_target。在每个训练步骤后,检查实际的KL散度值。如果实际值高于目标,就增大 β,加强惩罚,把策略“拉回来”。如果实际值低于目标,就减小 β,放松约束,给模型更多探索空间。
-
课程学习:用 “两阶段训练” 这种先易后难的课程,先训练单轮惩罚,再训练多轮奖励。引导模型循序渐进地掌握从基础规则到复杂权衡的各项技能。
-

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐


 29
29 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)