Transformer、GPT、BERT 到底啥区别?
一、Transformer、GPT 和 BERT 的共同点与区别
在近年来,Transformer、GPT 和 BERT 成为了自然语言处理(NLP)领域的三大革命性技术。这三种模型,都基于深度学习,并在各种语言任务中取得了惊人的成绩。它们是如何工作的?它们之间有哪些异同?这篇文章将带你全面解析这三者的原理和特点,帮助你理解它们的异同之处以及它们各自的应用场景。
二、Transformer:开启语言处理新纪元
Transformer 是 2017 年由 Vaswani 等人提出的模型架构,成功地解决了传统 RNN 模型在处理长文本时遇到的性能瓶颈。Transformer 的最大特点是使用了自注意力机制(Self-Attention),使得模型可以并行处理输入序列中的所有词汇,而不需要像 RNN 那样按顺序处理文本。
1. Transformer 模型架构
Transformer 由**编码器(Encoder)和解码器(Decoder)**两部分组成。编码器负责接收输入文本并提取特征,解码器则负责生成输出。每一层的编码器和解码器中都有自注意力机制和前馈神经网络。
图示:Transformer 模型架构
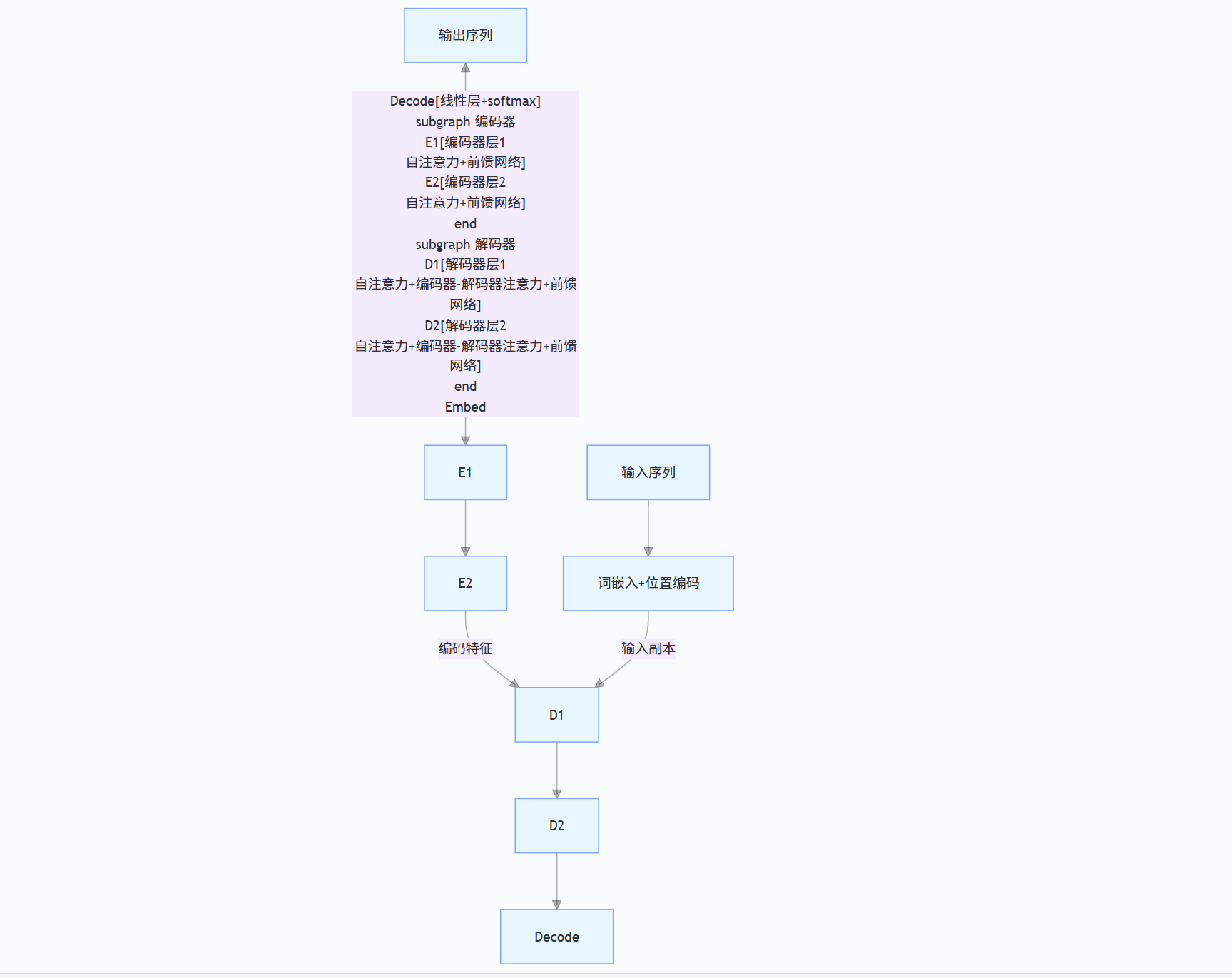
图解:Transformer 的核心是自注意力机制,它通过捕捉句子中不同词语之间的关系来处理文本。
推荐链接:
-
Transformer 模型介绍
2. 自注意力机制:计算词汇间的关系
在 Transformer 中,最重要的创新之一是自注意力机制(Self-Attention),它通过计算序列中各个词之间的相关性来获得每个词的表示。
自注意力机制让模型能够在输入文本的每个位置都能看到整个输入序列,从而理解上下文的关系。
推荐链接:
-
自注意力机制
三、GPT:自回归模型引领生成任务
GPT(Generative Pre-trained Transformer) 是由 OpenAI 提出的一个自回归生成模型,它基于 Transformer 架构,但与原始的 Transformer 模型不同,GPT 只使用了 Transformer 的解码器部分,专注于生成任务。
1. GPT 的自回归生成特性
GPT 模型在训练阶段使用自回归语言建模(Autoregressive Language Modeling),即根据前面的词生成下一个词。这种训练方式使得 GPT 特别擅长生成连贯的自然语言文本。
2. GPT 的训练与微调
与传统的深度学习模型不同,GPT 通过先进行预训练,然后通过微调(Fine-Tuning)来适应特定任务。在预训练阶段,GPT 会在大规模的文本数据上学习语言模型,然后根据特定任务进行微调,例如情感分析、翻译等。
推荐链接:
-
GPT-3 介绍与应用
四、BERT:双向编码器的上下文理解
BERT(Bidirectional Encoder Representations from Transformers) 是 Google 提出的一个基于 Transformer 编码器的模型,它的独特之处在于它使用了**双向(Bidirectional)**的训练方式,使得模型能够同时理解上下文的前后信息。
1. BERT 的双向上下文理解
BERT 通过掩蔽语言建模(Masked Language Modeling)方法来训练,即随机遮蔽输入文本中的一些词,然后让模型预测这些被遮蔽的词。这种训练方式使得 BERT 在理解上下文的含义时能够考虑前后文的信息,而不像传统的单向语言模型只关注从左到右的序列。
2. BERT 的应用:预训练和微调
BERT 通过预训练和微调的方式,能够应用于多种 NLP 任务,包括文本分类、命名实体识别、问答等。
推荐链接:
-
BERT 模型介绍
图示:BERT 和 GPT 的区别
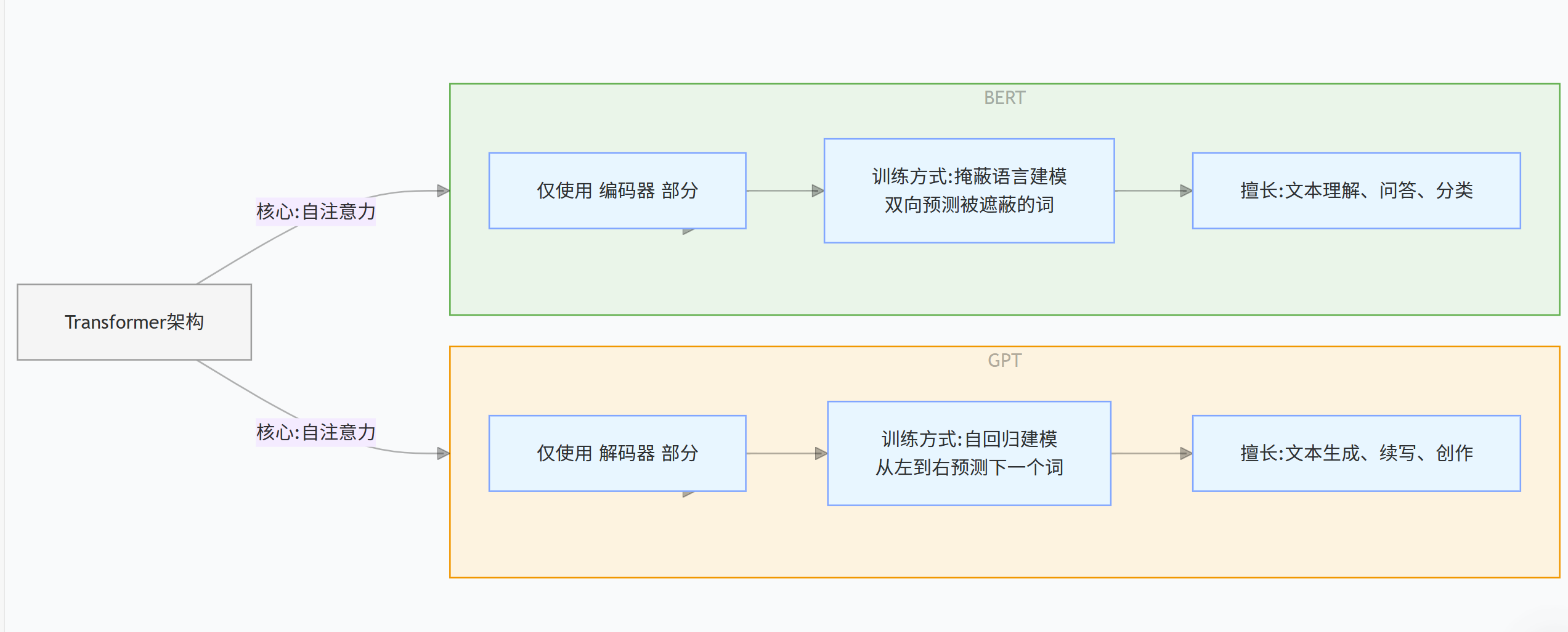
图解:BERT 和 GPT 在结构上的区别,GPT 只使用解码器,而 BERT 使用编码器并进行双向训练。
五、Transformer、GPT 和 BERT 的区别
1. 模型架构的不同
-
Transformer:包含编码器和解码器,适用于多种任务。
-
GPT:只使用解码器,适用于生成任务,如文本生成。
-
BERT:只使用编码器,采用双向训练,擅长理解任务,如问答、分类。
2. 训练方式的不同
-
Transformer:可以用来处理翻译任务等多种 NLP 任务,训练时不局限于特定任务。
-
GPT:自回归模型,通过预测下一个词来进行生成任务的训练。
-
BERT:双向训练,通过掩蔽语言建模来同时理解上下文的前后信息。
推荐链接:
-
BERT与GPT对比分析
六、总结
Transformer、GPT 和 BERT 都是当前 NLP 领域最重要的模型,它们在架构、训练方法和应用上有所不同。Transformer 提出了强大的自注意力机制,GPT 专注于自回归文本生成,而 BERT 则通过双向训练提升了语言理解能力。随着这些模型的不断优化和创新,它们在各类自然语言处理任务中都取得了巨大的成功。
本篇文章深入对比了 Transformer、GPT 和 BERT 的原理及区别,希望你能够通过本篇了解这三者在 NLP 中的应用。如果你对某个模型感兴趣,或者有更多问题,欢迎在评论区留言!

中国智能体开发者社区,聚焦智能体与大模型开发,提供前沿资讯、实用工具链、开源项目及行业案例。通过技术沙龙、开发者大赛等活动,促进经验交流与协作,助力开发者快速构建创新智能应用。
更多推荐



 9
9 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)