大模型面试必问知识:Transformer、BERT、GPT
是时候准备面试和实习了。不同以往的是,当前职场环境已不再是那个双向奔赴时代了。求职者在变多,HC 在变少,岗位要求还更高了。最近,我们又陆续整理了很多大厂的面试题,帮助一些球友解惑答疑,分享技术面试中的那些弯弯绕绕。。今天来聊一聊BERT和GPT的架构,从而了解大模型的第三步:Transformer。Transformer作为现代大语言模型的基石,其编码器-解码器架构为BERT和GPT提供了截然不
是时候准备面试和实习了。
不同以往的是,当前职场环境已不再是那个双向奔赴时代了。求职者在变多,HC 在变少,岗位要求还更高了。
最近,我们又陆续整理了很多大厂的面试题,帮助一些球友解惑答疑,分享技术面试中的那些弯弯绕绕。
喜欢本文记得收藏、关注、点赞。

今天来聊一聊BERT和GPT的架构,从而了解大模型的第三步:Transformer。
Transformer作为现代大语言模型的基石,其编码器-解码器架构为BERT和GPT提供了截然不同的技术路径。BERT是Encoder-only架构,通过双向编码器捕捉上下文信息,适合需要深度理解的任务;而GPT是Decoder-only架构,通过自回归生成机制,逐步生成文本,适合生成式任务。
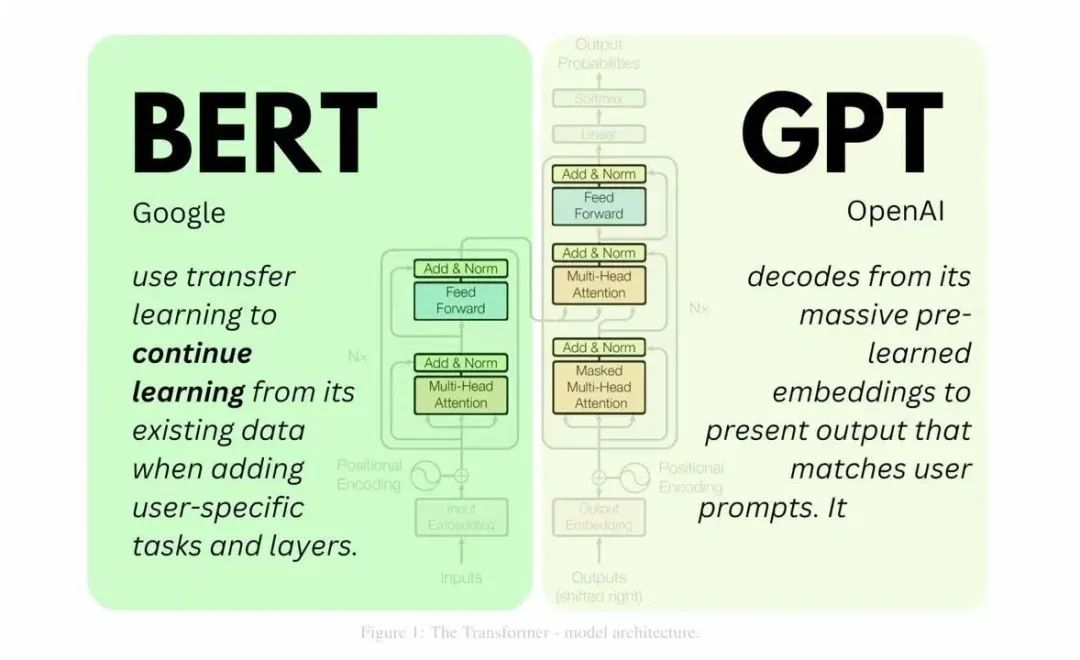
一、BERT(Encoder-only)
BERT的架构:双向理解的编码器
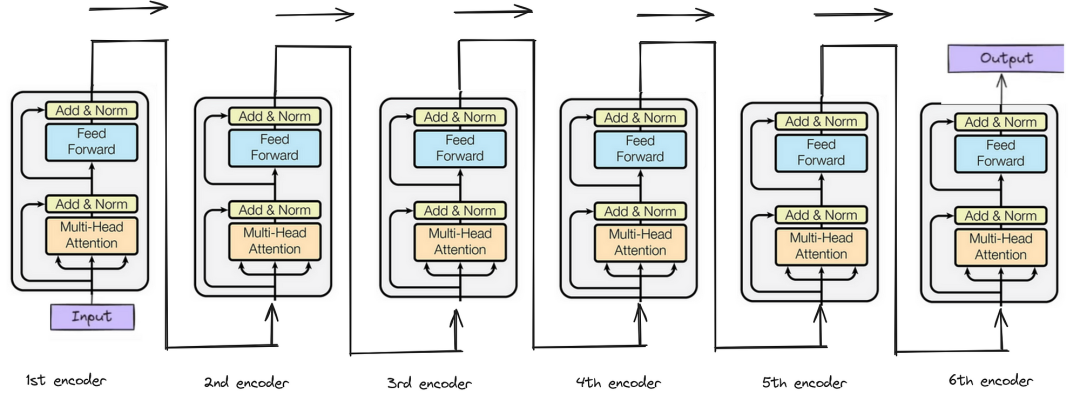
一、Transformer编码器(Encoder):
Transformer编码器(Encoder)由 N 个相同层堆叠而成(通常 N=6 或 12),每个层包含两个核心子层:多头自注意力子层(Multi-Head Self-Attention)和前馈神经网络子层(Feed-Forward Network, FFN)。
每个子层均通过残差连接(Residual Connection)与层归一化(Layer Normalization)优化训练稳定性。
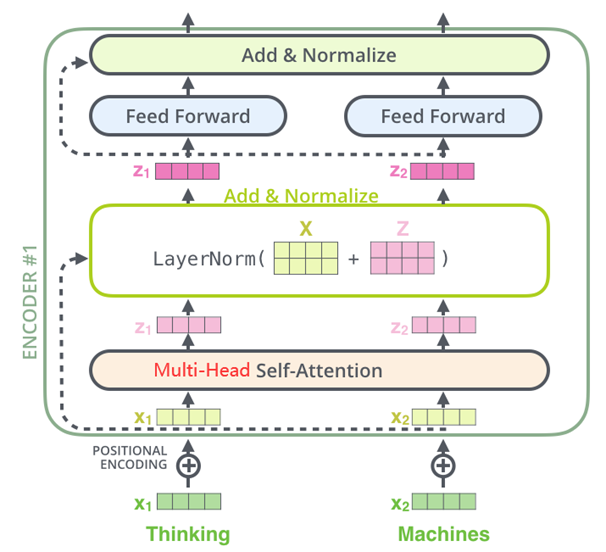
(1)多头自注意力(Multi-Head Self-Attention)
输入向量通过线性变换生成查询(Q)、键(K)、值(V)向量;每个注意力头通过缩放点积(Scaled Dot-Product)独立计算词与词之间的注意力权重;多个注意力头的输出拼接后通过线性层融合。
(2)前馈神经网络(Feed-Forward Network, FFN)
多头自注意力层后,每个位置独立通过前馈神经网络(FFN)进行非线性变换;FFN是一个多层感知机,由两层全连接层组成,中间使用 ReLU 激活函数。
(3)残差连接(Residual Connection)
残差连接由何凯明团队在ResNet中首次提出,将子层输入直接叠加到输出,避免多层叠加后性能反而下降,解决模型在训练过程中的梯度消失和网络退化问题。
(4)层归一化(Layer Normalization)
残差连接后接层归一化(LayerNorm),标准化输出分布,加速收敛并稳定训练。
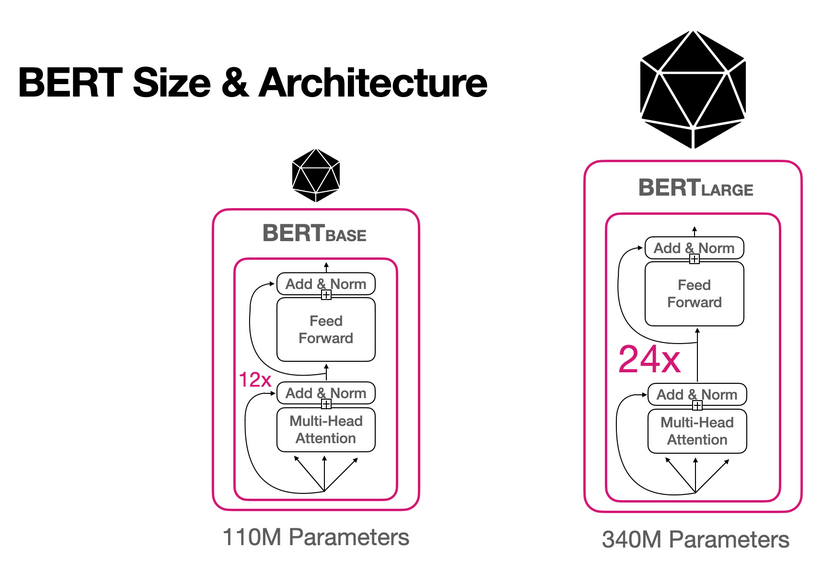
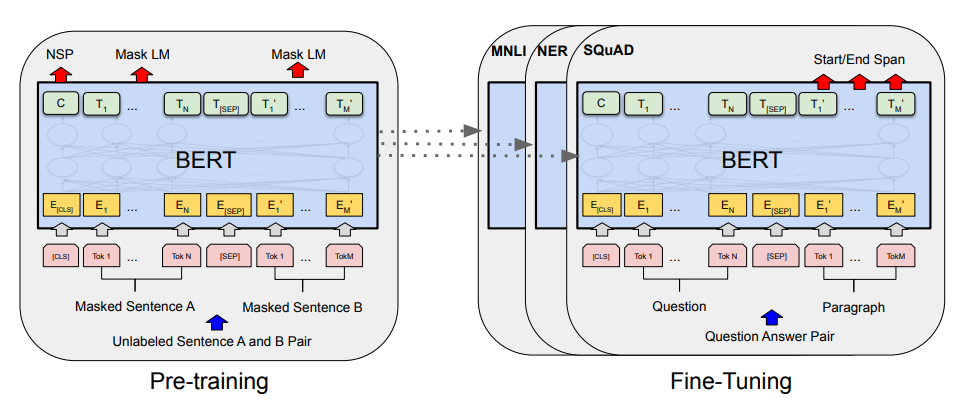
二、BERT架构:
BERT仅使用Transformer的编码器部分,通过双向编码器全面理解上下文,适合需要深度语义理解的任务(如问答、文本分类)。其核心任务包括:
(1)掩码语言模型(MLM)
随机遮蔽输入序列中的部分单词,要求模型预测这些单词。
(2)下一句预测(NSP)
判断两个句子是否连续。
三、专业术语:
忽略:掩码语言模型(MLM)、下一句预测(NSP)
关注:自注意力(Self-Attention)、多头自注意力(Multi-Head Self-Attention)

二、GPT(Decoder-only)
GPT的架构:自回归生成的解码器
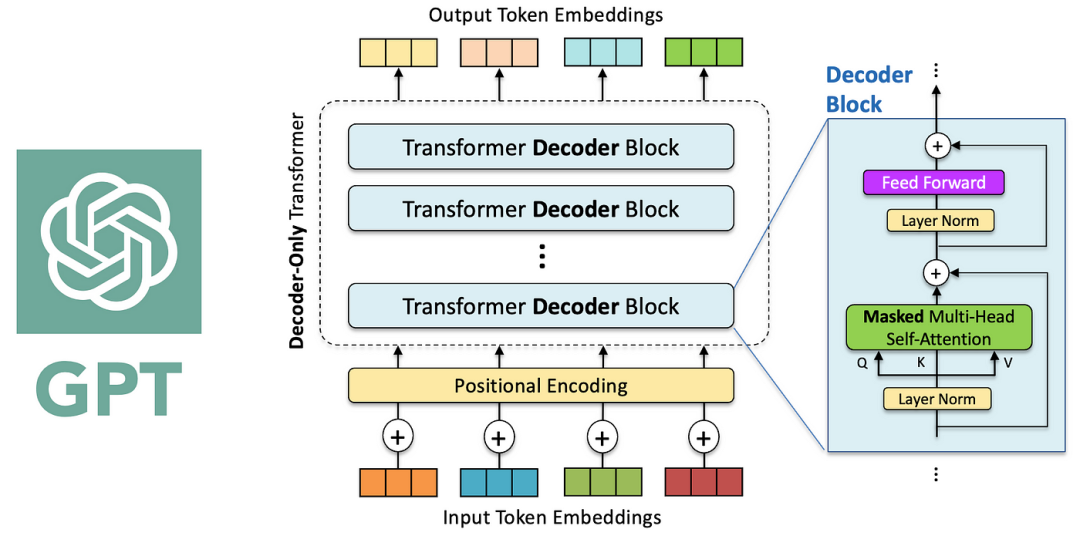
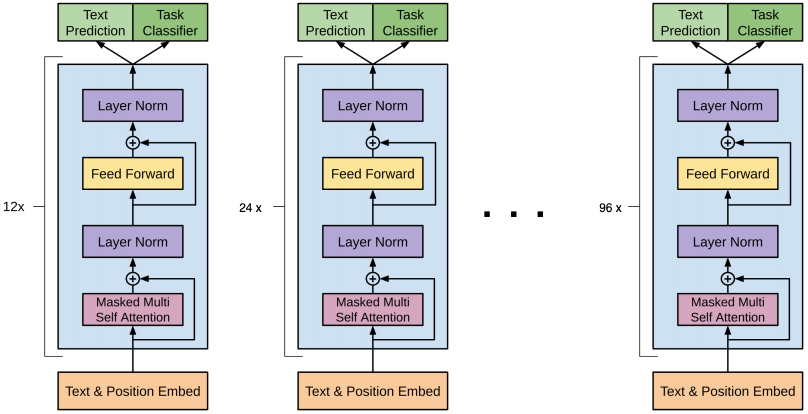
一、Transformer解码器(Decoder):
Transformer解码器(Decoder)由 N 个相同层堆叠而成(通常 N=6 或 12),每层包含三个关键子层:掩码自注意力层(Masked Self-Attention)、编码器-解码器注意力层(Encoder-Decoder Attention)和前馈神经网络子层(Feed-Forward Network, FFN)。
每个子层也均通过残差连接(Residual Connection)与层归一化(Layer Normalization)优化训练稳定性。
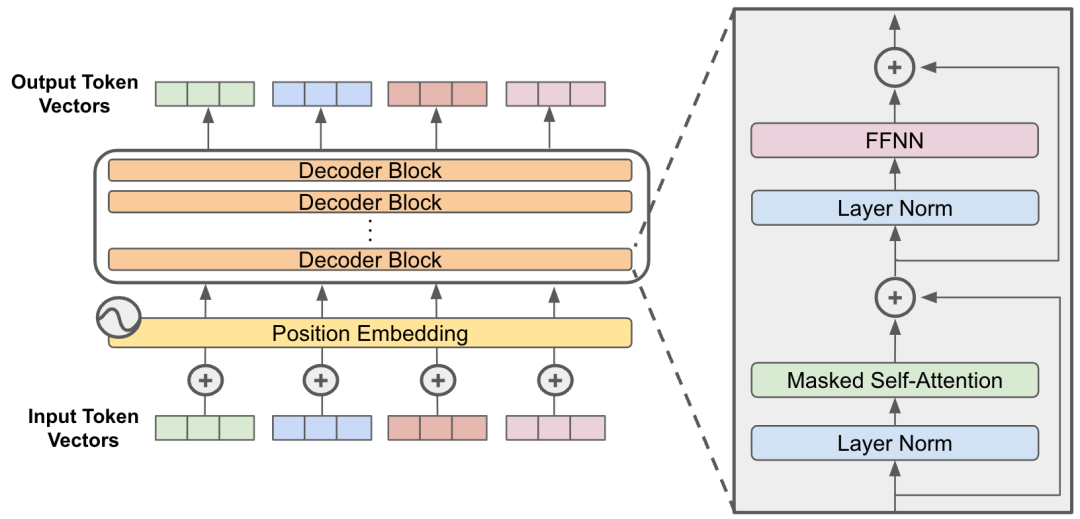
(1)掩码自注意力层(Masked Self-Attention)
通过掩码机制限制模型仅关注当前位置之前的词,这样在计算注意力权重时,将未来位置的权重设为负无穷(softmax后趋近于0),确保生成顺序正确性。例如生成第3个词时,仅允许关注前两个词。
(2)编码器-解码器注意力层(Encoder-Decoder Attention)
解码器的自注意力输出作为查询(Query),编码器的输出作为键(Key)和值(Value),通过注意力权重筛选关键信息。这样可以整合编码器的语义信息,指导解码器生成与源序列相关的输出。
(3)前馈神经网络(Feed-Forward Network, FFN)
多头自注意力层后,每个位置独立通过前馈神经网络(FFN)进行非线性变换;FFN是一个多层感知机,由两层全连接层组成,中间使用 ReLU 激活函数。
(4)残差连接(Residual Connection)
残差连接由何凯明团队在ResNet中首次提出,将子层输入直接叠加到输出,避免多层叠加后性能反而下降,解决模型在训练过程中的梯度消失和网络退化问题。
(5)层归一化(Layer Normalization)
残差连接后接层归一化(LayerNorm),标准化输出分布,加速收敛并稳定训练。
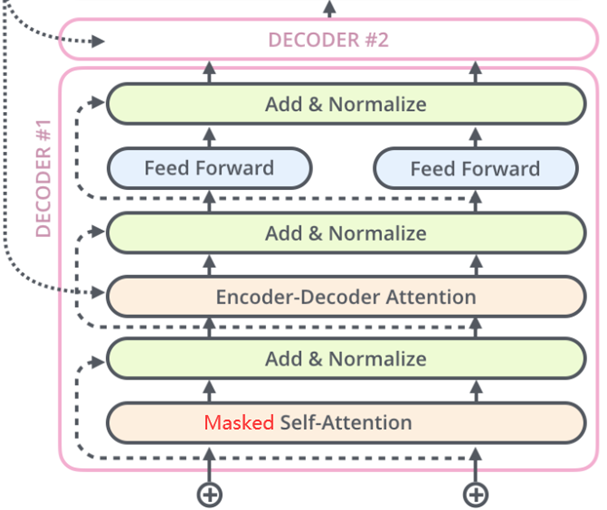
二、GPT架构:
GPT仅使用Transformer的解码器部分,只需要掩码自注意力层(Masked Self-Attention),不需要编码器-解码器注意力层(Encoder-Decoder Attention)。
GPT通过自回归方式从左到右生成文本,适合生成式任务(如对话生成、文章续写)。其核心任务是:语言建模:预测下一个词。
(1)逐词生成模式
GPT的生成过程严格遵循从左到右的顺序,每个新词仅基于已生成的历史内容预测。
这一过程模仿人类“边写边想”的思维逻辑,确保上下文的连贯性。
例如,生成句子“今天天气很热”时:输入初始Token序列“[今天]”,模型预测下一个词为“天气”;输入更新为“[今天, 天气]”,预测“很”;输入扩展为“[今天, 天气, 很]”,最终预测“热”并结束生成。
(2)掩码注意力机制
掩码自注意力通过屏蔽未来位置的Token(如生成第3个词时禁止访问第4个词),强制模型仅依赖历史信息生成当前词。这种设计防止模型“偷看”未来数据,维持生成过程的逻辑自洽。
(3)动态输入更新
生成过程中,模型每一步将新预测的Token加入输入序列,形成滚雪球式信息累积。
例如,GPT-3生成长文本时,输入序列从短句逐步扩展至完整段落,实现开放式内容创作。
三、专业术语:
忽略:编码器-解码器注意力层(Encoder-Decoder Attention)
关注:掩码自注意力层(Masked Self-Attention)
…(img-PEPnjdm1-1748067112157)]
三、专业术语:
忽略:编码器-解码器注意力层(Encoder-Decoder Attention)
关注:掩码自注意力层(Masked Self-Attention)

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 11
11 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)