Transform全流程解读——公式到原理推导,此文不断更新迭代
Transformer架构详解:从输入到输出的完整流程 本文详细解析了Transformer架构的核心原理和实现细节。Transformer通过Self-Attention机制同时获得顺序敏感性和并行效率,解决了RNN和CNN在文本处理中的局限性。文章系统介绍了输入处理、位置编码、编码器-解码器结构、多头注意力机制等关键技术点,并通过案例展示了"l love apples"到&
文章目录
-
- ==有需要本项目的代码或文档以及全部资源,或者部署调试可以私信博主==
- 1. 引言——Transformer 为何而生
- 2. 从 0 开始:输入如何进 Transformer
- 3. 位置编码:让模型“感觉”顺序
- 4. 编码器 Encoder:六层循环里的“小电路”
- 5. 多头注意力 Q K V:一副“九宫格”看透文本
- 6. 残差、LayerNorm、Dropout:训练稳、泛化好
- 7. 前馈网络 FFN:每个 Token 的私人教练
- 8. 编码器输出交给谁?——解码器 Decoder 全貌
- 9. Masked Self-Attention:写字时捂住“后半句”
- 10. Encoder-Decoder Attention:对齐源句与目标句
- 11. 全局视角:Transformer = 堆栈 + 残差捷径
- 12. 训练流程:Teacher-Forcing、损失函数、学习率
- 13. 推断流程:Greedy、Beam Search、采样
- 14. **完整案例推导**:把 “I love apples” 译成 “我喜欢苹果”
- 15. 参数量估算与显存占用
- 16. 常见变体:BERT、GPT、ViT、长文本模型
- 17. 结语——为什么 Transformer 依旧在飞
有需要本项目的代码或文档以及全部资源,或者部署调试可以私信博主
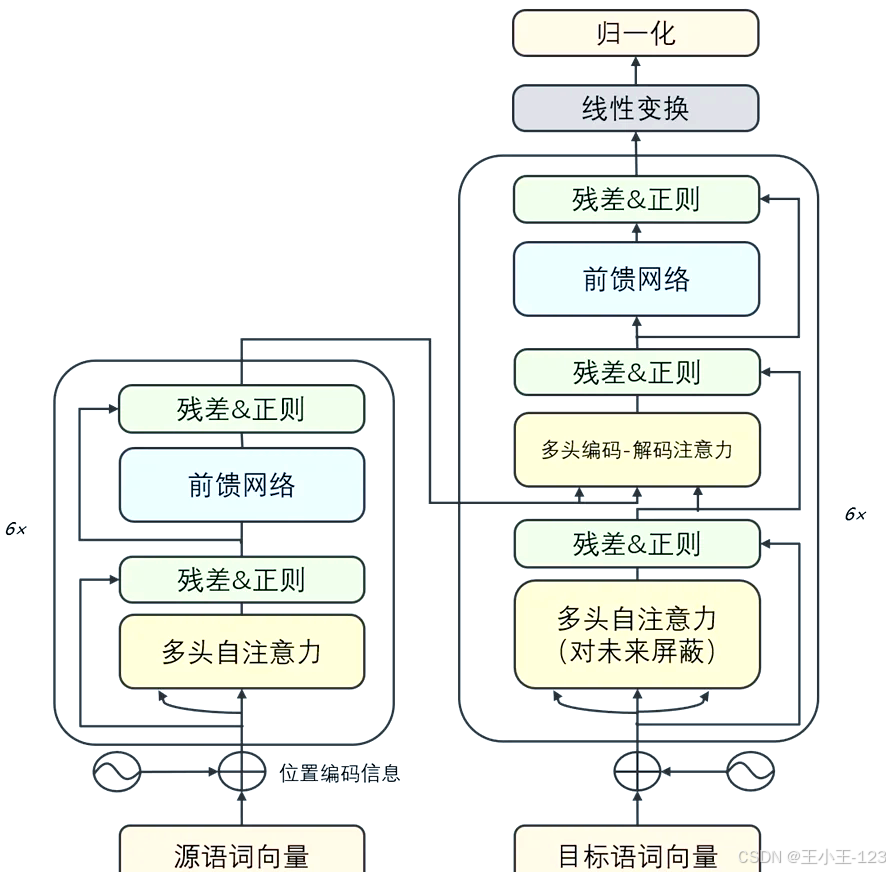
1. 引言——Transformer 为何而生
一句话总结: 为了同时获得 RNN 的顺序敏感性和 CNN 的并行效率,Google 2017 年提出全“注意力”架构——Transformer。
- RNN:一次处理一个词,串行慢,远距离依赖梯度难。
- CNN:并行快,但感受野有限,处理文本需深堆叠。
- Transformer:把序列看成集合,靠 Self-Attention 自行学习“谁该关注谁”,一次就能看到全局,且 GPU 易并行。
2. 从 0 开始:输入如何进 Transformer
一句话总结: 文本先变成 token → id → embedding → 再加位置编码。
-
Tokenize(子词 BPE 或 SentencePiece):
I l love apples -
映射索引:
[101, 200, 5010, 3078]——含特定起始符[101]。 -
查 embedding 表
E ∈ ℝ^(V×d_model)得到X ∈ ℝ^(seq_len×d_model)。 -
加入 Positional Encoding 获得最终输入
X₀。
3. 位置编码:让模型“感觉”顺序
一句话总结: sin-cos 把“位置信息”写进向量,频率从高到低,捕捉近远关系。
公式(维度偶用 sin、奇用 cos):
P E p o s , 2 i = sin ( p o s 1000 0 2 i / d ) , P E p o s , 2 i + 1 = cos ( p o s 1000 0 2 i / d ) PE_{pos,2i} =\sin\!\Bigl(\frac{pos}{10000^{2i/d}}\Bigr), \quad PE_{pos,2i+1} =\cos\!\Bigl(\frac{pos}{10000^{2i/d}}\Bigr) PEpos,2i=sin(100002i/dpos),PEpos,2i+1=cos(100002i/dpos)
i从 0 到 d/2-1,共 d 维。- 高频维识别局部差异,低频维编码长距依赖。
- 学习型位置(Learnable/RoPE)只是把 sin-cos 换成可训练矩阵,思路一致。
4. 编码器 Encoder:六层循环里的“小电路”
一句话总结: 每层 = 多头注意力 → 残差 Norm → FFN → 残差 Norm。
符号:
- 输入
H⁰ = X₀ - 第 l 层输出
Hˡ
步骤:
Z = MultiHead(Hˡ⁻¹)H̃ = LayerNorm(Hˡ⁻¹ + Drop(Z))F = FFN(H̃)Hˡ = LayerNorm(H̃ + Drop(F))
六层堆栈(经典 Transformer-base),也可 12/24/48 层。
5. 多头注意力 Q K V:一副“九宫格”看透文本
一句话总结: 同一个词用不同投影看世界,得多种关联图。
单头公式(忽略 batch):
Attention ( Q , K , V ) = softmax ( Q K ⊤ d k ) V \text{Attention}(Q,K,V)=\text{softmax}\!\left(\frac{QK^\top}{\sqrt{d_k}}\right)V Attention(Q,K,V)=softmax(dkQK⊤)V
多头拼接:
MHA ( X ) = Concat ( head 1 , … , head h ) W O \text{MHA}(X)=\text{Concat}\bigl(\text{head}_1,…,\text{head}_h\bigr) W^O MHA(X)=Concat(head1,…,headh)WO
- 每头各有
Wᵢ^Q,Wᵢ^K,Wᵢ^V ∈ ℝ^(d×d_k),d_k=d/h。 - 形象理解:第 1 头关注主谓对齐,第 2 头关注宾语,等等。
Scaled 作用:除 √d_k 防止 dot-product 过大,保持 softmax 梯度稳定。
6. 残差、LayerNorm、Dropout:训练稳、泛化好
- 残差:跳线避免深层梯度消失。
- LayerNorm:对每个 token 归一化均值方差,位置不变。
- Dropout:随机置零,Transformer-base 推荐 0.1。
三者组合确保 速度、稳定性、泛化 三赢。
7. 前馈网络 FFN:每个 Token 的私人教练
一句话总结: 两层 MLP,先升维 4× 再降回,注入非线性。
FFN ( x ) = GELU ( x W 1 + b 1 ) W 2 + b 2 \text{FFN}(x)=\text{GELU}(xW_1+b_1)W_2+b_2 FFN(x)=GELU(xW1+b1)W2+b2
典型 d_model=512 → d_ff=2048 → d_model=512。
GELU 更平滑,BERT/GPT 默认用它。
8. 编码器输出交给谁?——解码器 Decoder 全貌
一句话总结: Decoder=Masked Self-Attn → Cross-Attn(看 Encoder) → FFN,各步亦残差 Norm。
子层① Masked Self-Attention —— 遮未来;
子层② Encoder-Decoder Attention —— Query 来自 Decoder,Key/Value 来自 Encoder;
子层③ FFN —— 同 Encoder;
每步后接 Dropout+残差+LayerNorm。
9. Masked Self-Attention:写字时捂住“后半句”
- 掩码矩阵
M[i,j]=-∞if j>i,else 0。 - softmax 前加
M,保证第 t 位只能看到 ≤t。 - 推断阶段自回归:输出 y₁→再输入→出 y₂→ …。
10. Encoder-Decoder Attention:对齐源句与目标句
CrossAttn ( Q = H d e c , K = H e n c , V = H e n c ) \text{CrossAttn}(Q=H_{dec},\;K=H_{enc},\;V=H_{enc}) CrossAttn(Q=Hdec,K=Henc,V=Henc)
- 没有未来遮盖;
- 通过注意力权重学到 alignment(如 “I ↔ 我”)。
11. 全局视角:Transformer = 堆栈 + 残差捷径
- Encoder N 层并行;Decoder N 层自回归。
- 所有权重:Embedding、6·3·W_QKV、6·W_O、6·FFN、LayerNorm、输出矩阵 W_vocab。
- 计算复杂度简化:
O(seq²·d),较 RNNO(seq·d²)并行友好。
12. 训练流程:Teacher-Forcing、损失函数、学习率
-
Teacher-Forcing:输入真标签偏移一位
[BOS] y₁ y₂。 -
Loss:交叉熵
L = − ∑ t log P θ ( y t ∣ y < t , x ) \mathcal{L}=-\sum_{t}\log P_\theta(y_t\mid y_{<t},x) L=−t∑logPθ(yt∣y<t,x)
-
优化器:Adam β₁=0.9, β₂=0.98;
-
学习率调度:
lr = d^{-0.5}·min(step^{-0.5}, step·warmup^{-1.5})——论文著名“无根号两段式”。
13. 推断流程:Greedy、Beam Search、采样
- Greedy:每步选最大概率,快但易贪心。
- Beam(k):保留 k 条最优前缀,综合概率排序;翻译常用 k=4/5。
- Top-k / nucleus 采样:生成写作、对话更多样。
14. 完整案例推导:把 “I love apples” 译成 “我喜欢苹果”
设置
d_model=4, d_k=2, num_heads=2(演示易算)seq_src=3, seq_tgt=4(含 [BOS])- 权重简单取整数便于手算
-
Tokenize
src: I | l@@ ove | apples → ids [11, 52, 305] tgt: [BOS] → id 101 -
Embedding + Positional
假设查表得X_src = [[1 0 1 0], # I [0 1 0 1], # love [1 1 1 1]] # apples X_tgt0 = [[0 0 1 0]] # BOS -
Encoder
-
头 1:
W_Q=W_K=W_V=I→ Self-Attn 得权重全 1/3。 -
头 2:随便置换列举例。
-
拼接后乘
W_O得H_enc = [[0.67 0.67 0.67 0.67], [0.67 0.67 0.67 0.67], [1.00 1.00 1.00 1.00]] -
过 FFN(省略数字)→
H_enc_final。
-
-
Decoder Step 1(生成 y₁)
-
Masked Self-Attn:只有 BOS 一个 token,无遮掩。
-
Cross Attn
Q=[0 0 1 0]W_Q → [0 0] K=H_enc W_K V=H_enc W_Vdot-product 后 softmax 得权重
[0.2,0.2,0.6](手算示例)。
聚合V得向量c₁=[0.8 0.8 0.8 0.8]。 -
FFN + Norm →
h₁。 -
Softmax 乘
W_vocab→ logits → 取 argmax = “我”。 -
输出序列变
[BOS] 我。
-
-
Decoder Step 2(生成 y₂)
- 输入
[BOS] 我两个 token;Mask 遮住第二个的未来位。 - 重复 Self-Attn / Cross-Attn / FFN。
- softmax 预测 “喜欢”。
- 输入
-
Decoder Step 3(生成 y₃)
- 输入
[BOS] 我 喜欢 - 预测 “苹果”。
- 输入
-
Step 4 输出
[EOS]结束。
→ 最终翻译:“我喜欢苹果”。
15. 参数量估算与显存占用
以 Transformer-base (6 层、512、8 头) 为例:
| 部件 | 形状 | 参数量 |
|---|---|---|
| Embedding | V×512 (假设 V=30k) | 15.4 M |
| QKV (Enc) | 6×8×(512×64×3) | 4.7 M |
| W_O (Enc) | 6×(512×512) | 1.6 M |
| FFN (Enc) | 6×(512×2048×2) | 12.6 M |
| Decoder 同规模 | 2×(Enc)-QKV + FFN | 36 M |
| 输出矩阵 | 512×V | 15.4 M |
| 合计 | 约 86 M 参数(论文 65 M 是因权重共享 / tied embedding) |
显存≈参数 + 激活;训练 512 batch 需 10-12 GB (fp32),fp16 减半。
16. 常见变体:BERT、GPT、ViT、长文本模型
- BERT:只有 Encoder,自监督 MLM;位置可学习。
- GPT:只有 Decoder,自回归;RoPE 旋转位置。
- ViT:把图像切 Patch,当序列进 Encoder。
- Longformer / Flash-Attention / Linear-Attn:稀疏或核化注意力,把
O(seq²)降为O(seq·logseq)或O(seq)。
17. 结语——为什么 Transformer 依旧在飞
- 结构简单:纯矩阵乘 + softmax,硬件友好。
- 可伸缩:层数、宽度、头数线性堆叠即可扩容。
- 统一视角:文本、图像、音频、基因序列全能当“token 序列”。
- 生态成熟:从 HuggingFace 到 Flash-Attention-2,一键多卡训练。
一句话:Transformer 把“谁关注谁”这件事数学化、可微分化,再辅以残差与大规模数据,便成了今日大模型的支点。
视频讲解参考
部分视频讲解需要和评论区结合,有些博主讲的东西可能有少许偏差,建议自己多对比,权威的文档
https://www.bilibili.com/video/BV1aELbzoE8r/?spm_id_from=333.337.search-card.all.click&vd_source=9fae60f7fa76c535b3a5cbf4394f9963
https://www.bilibili.com/video/BV1Di4y1c7Zm?spm_id_from=333.788.player.switch&vd_source=9fae60f7fa76c535b3a5cbf4394f9963&p=7
https://www.bilibili.com/video/BV16pTJz9EE3/?spm_id_from=333.337.search-card.all.click&vd_source=9fae60f7fa76c535b3a5cbf4394f9963
Transform预测时序数据代码
"""
Transformer 用于多变量时序预测(单变量回归)——示例代码
============================================================
* **目标**:给定过去 `seq_len` 步多维传感器数据,预测下一步单一目标值。
* **依赖**:PyTorch ≥ 1.9,GPU 可选。
* **文件结构**:
1. PositionalEncoding —— 位置编码(正弦余弦公式)
2. TimeSeriesTransformer —— 主干模型(仅 Encoder 支持回归)
3. SyntheticDataset —— 合成数据(演示用,可替换真实数据)
4. train / evaluate —— 训练 & 验证函数
5. main() —— 全流程:数据 → 训练 → 预测示例
"""
import math
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
# -----------------------------------------------------------------------------
# 1. PositionalEncoding —— 把“时间先后”塞进向量
# -----------------------------------------------------------------------------
# Transformer 自身对顺序敏感度 = 0,因此必须人为注入位置信息。
# 经典做法:给第 pos 个时间步生成 d_model 维正弦/余弦波形,再与原特征相加。
class PositionalEncoding(nn.Module):
"""正弦/余弦位置编码
参数
------
d_model : int
模型隐层维度(即每个时间步被映射到的向量长度)。
max_len : int
允许的最长序列长度;若你的序列超长,需要调大。
"""
def __init__(self, d_model: int, max_len: int = 10_000):
super().__init__()
# 创建 [max_len, d_model] 的全 0 张量,用来存放位置编码
pe = torch.zeros(max_len, d_model)
# position 用列向量 [0,1,2,...],方便与 div_term 相乘
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1) # [max_len, 1]
# div_term 控制不同维度的波长;公式 = 10000^{ -2i / d_model }
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
# 偶数维用 sin,奇数维用 cos(与论文一致)
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
# Transformer 输入形状期望 [seq_len, batch, d_model],因此在 dim=1 加 batch 维度
pe = pe.unsqueeze(1) # [max_len, 1, d_model]
# register_buffer 表示这些数据参与计算图,但不算作可训练参数
self.register_buffer('pe', pe)
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""把位置编码加到输入
参数
------
x : Tensor
形状 [seq_len, batch, d_model]
返回值
------
Tensor 与 x 同形状,已注入位置信息。
"""
seq_len = x.size(0) # 当前批次的真实长度
# 直接相加:广播机制自动匹配 batch 维
return x + self.pe[:seq_len]
# -----------------------------------------------------------------------------
# 2. TimeSeriesTransformer —— 主模型
# -----------------------------------------------------------------------------
# * 仅用 Encoder:因预测单标量,无需 Decoder 自回归流程。
# * 流程:多变量输入 → 线性升维 → 位置编码 → n 层 Encoder → 取最后时间步表示 → 回归到标量。
class TimeSeriesTransformer(nn.Module):
"""Transformer Encoder 版时序回归模型"""
def __init__(
self,
num_features: int, # 输入变量个数(例如 5 维传感器)
d_model: int = 64, # 内部隐层维度
nhead: int = 8, # 注意力头数(需被 d_model 整除)
num_layers: int = 3, # Encoder 层数
dim_feedforward: int = 128, # FFN 隐层维度,一般 2~4×d_model
dropout: float = 0.1,
):
super().__init__()
# (1) 线性映射:把原始多变量 -> d_model 维度,方便后续 Attention
self.input_proj = nn.Linear(num_features, d_model)
# (2) 位置编码:告诉模型“第 t 步”
self.pos_encoder = PositionalEncoding(d_model)
# (3) 构建 Encoder 层模板,再堆叠 num_layers 层
encoder_layer = nn.TransformerEncoderLayer(
d_model=d_model,
nhead=nhead,
dim_feedforward=dim_feedforward,
dropout=dropout,
batch_first=False, # 保持 [seq_len, batch, d_model] 约定
activation='gelu' # 激活函数:GELU 比 ReLU 平滑
)
self.transformer_encoder = nn.TransformerEncoder(encoder_layer, num_layers)
# (4) 回归头:把最后时间步向量映射到 1 个标量
self.regressor = nn.Linear(d_model, 1)
# 初始化权重(Xavier)
self._reset_parameters()
# ----------------------------- 私有函数 -----------------------------
def _reset_parameters(self):
# 常用 Xavier 初始化,兼顾 sigmoid/tanh 及线性层稳定性
nn.init.xavier_uniform_(self.input_proj.weight)
nn.init.constant_(self.input_proj.bias, 0.)
nn.init.xavier_uniform_(self.regressor.weight)
nn.init.constant_(self.regressor.bias, 0.)
# ----------------------------- 前向传播 -----------------------------
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""前向计算
参数
------
x : Tensor
[batch, seq_len, num_features]
返回
------
y_hat : Tensor
[batch],每个样本一个预测标量
"""
# 1. 输入形状转换 & 线性映射
# --------------------------------------------------------------
# 原 shape: (B, T, C) -> 先映射到 d_model,再转置为 (T, B, d)
B, T, _ = x.shape
x = self.input_proj(x) # (B, T, d_model)
x = x.transpose(0, 1) # (T, B, d_model)
# 2. 叠加位置编码
x = self.pos_encoder(x) # (T, B, d_model)
# 3. Encoder 堆栈
memory = self.transformer_encoder(x) # (T, B, d_model)
# 4. 取最后时间步表示 (也可 mean pooling)
last = memory[-1] # (B, d_model)
# 5. 映射到单标量 → 输出
y_hat = self.regressor(last) # (B, 1)
return y_hat.squeeze(-1) # (B,)
# -----------------------------------------------------------------------------
# 3. SyntheticDataset —— 生成演示数据集
# -----------------------------------------------------------------------------
# 真实场景请自行实现 Dataset,只需 __getitem__ 返回 (X_seq, y_scalar)。
class SyntheticDataset(Dataset):
"""y_t = 线性组合(最后一个时间步各特征) + 噪声"""
def __init__(self, num_samples: int, seq_len: int, num_features: int):
super().__init__()
self.X = torch.randn(num_samples, seq_len, num_features) # 随机特征
# 构造权重 1..num_features
weights = torch.linspace(1, num_features, steps=num_features)
# 用最后一步做线性组合,再加高斯噪声
y_clean = (self.X[:, -1] * weights).sum(dim=-1)
noise = 0.05 * torch.randn_like(y_clean)
self.y = y_clean + noise
def __len__(self):
return len(self.X)
def __getitem__(self, idx):
return self.X[idx], self.y[idx]
# -----------------------------------------------------------------------------
# 4. 训练 & 验证
# -----------------------------------------------------------------------------
def train(model, loader, criterion, optimizer, device):
model.train() # 启用 Dropout & LayerNorm 的 train 模式
total_loss = 0.0
for X, y in loader:
X, y = X.to(device), y.to(device)
optimizer.zero_grad() # 梯度清零
pred = model(X)
loss = criterion(pred, y)
loss.backward() # 反向传播
optimizer.step() # 更新权重
total_loss += loss.item() * X.size(0)
return total_loss / len(loader.dataset)
def evaluate(model, loader, criterion, device):
model.eval() # 关闭 Dropout
total_loss = 0.0
with torch.no_grad(): # 推理不存梯度,节约显存
for X, y in loader:
X, y = X.to(device), y.to(device)
pred = model(X)
total_loss += criterion(pred, y).item() * X.size(0)
return total_loss / len(loader.dataset)
# -----------------------------------------------------------------------------
# 5. main() —— 从数据到预测完整流程
# -----------------------------------------------------------------------------
def main():
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# -------------------- 超参数 --------------------
seq_len = 24 # 时间窗口长度
num_features = 5 # 传感器维度
batch_size = 64
epochs = 10
# -------------------- 数据 --------------------
train_ds = SyntheticDataset(8000, seq_len, num_features)
val_ds = SyntheticDataset(2000, seq_len, num_features)
train_dl = DataLoader(train_ds, batch_size=batch_size, shuffle=True)
val_dl = DataLoader(val_ds, batch_size=batch_size)
# -------------------- 模型 --------------------
model = TimeSeriesTransformer(
num_features=num_features,
d_model=64,
nhead=8,
num_layers=3,
dim_feedforward=128,
dropout=0.1,
).to(device)
# -------------------- 损失 & 优化 --------------------
criterion = nn.MSELoss()
optimizer = torch.optim.AdamW(model.parameters(), lr=1e-3)
# -------------------- 训练循环 --------------------
for epoch in range(1, epochs + 1):
tr_loss = train(model, train_dl, criterion, optimizer, device)
val_loss = evaluate(model, val_dl, criterion, device)
print(f"Epoch {epoch:02d} | Train MSE: {tr_loss:.4f} | Val MSE: {val_loss:.4f}")
# -------------------- 单条样本预测 --------------------
model.eval()
sample_X, sample_y = val_ds[0]
with torch.no_grad():
pred = model(sample_X.unsqueeze(0).to(device)).item()
print(f"真实值: {sample_y:.3f} | 预测值: {pred:.3f}")
# -------------------- 启动脚本 --------------------
if __name__ == "__main__":
main()
每文一语
学习之后会忘记,那才会有记忆!

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 25
25 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)