AI智能体 - RAG
本文深入探讨了检索增强生成(RAG)技术的演进与应用,将传统LLM的闭卷考试模式转变为开卷考试的智能知识检索系统。文章分为三大部分: RAG基础架构:解析嵌入向量化、文档分块和向量数据库的核心原理,强调混合搜索(语义+关键词)的重要性。 进阶模式: GraphRAG通过知识图谱实现多跳推理,解决跨文档关联问题 Agentic RAG引入智能体思维,具备规划、反思和工具调用能力 实战演示:包含文档索
🚀 从“背书”到“开卷考试”:RAG 与智能体式检索的终极指南
AI 智能体设计模式系列(第十四篇)
📖 引言:打破 LLM 的认知围墙
大语言模型(LLM)是当今科技界最伟大的“通才”。它们博古通今,能写诗、能编码、能通过律师资格考试。然而,在企业级应用中,我们常常撞上一堵无形的“认知围墙”:
- 时效性黑洞:GPT-4 可能不知道昨天发布的 iPhone 16 参数。
- 数据孤岛:LLM 无法访问你公司内网的 PDF、Jira 工单或私有数据库。
- 幻觉风险:当被问及它不知道的细节时,它可能会自信地胡编乱造。
如果把 LLM 比作一个才华横溢的学生,传统的 LLM 模式就像是在进行一场“闭卷考试”——完全依赖记忆(训练权重)。
知识检索(RAG, Retrieval-Augmented Generation) 则是将这场考试变成了“开卷考试”。我们允许这个学生携带一本“教科书”(外部知识库),在回答问题前先查阅相关资料。这不仅提高了准确性,更重要的是,它赋予了 AI 引用来源、核实事实的能力。
本篇将带你从 RAG 的基本原理出发,深入探索 GraphRAG 和 Agentic RAG(智能体式 RAG) 的前沿架构,并使用最新的 LangChain v0.3 和 LangGraph 构建一个具有自我修正能力的检索智能体。
第一部分:RAG 的解剖学——从向量到生成
要构建一个高效的 RAG 系统,我们必须深入理解其底层的“三驾马车”:索引(Indexing)、检索(Retrieval)与生成(Generation)。
1.1 数据的数字灵魂:嵌入(Embeddings)
RAG 的魔法始于向量化。计算机不理解“猫”和“狗”的生物学联系,但它理解数字。
- 原理:嵌入模型(Embedding Model)将文本转化为高维空间中的向量(一串数字,如
[0.1, -0.5, 0.8...])。 - 语义空间:在这个高维空间中,含义相近的词距离更近。
- 示例:Vector("King")−Vector("Man")+Vector("Woman")≈Vector("Queen")\text{Vector}(\text{"King"}) - \text{Vector}(\text{"Man"}) + \text{Vector}(\text{"Woman"}) \approx \text{Vector}(\text{"Queen"})Vector("King")−Vector("Man")+Vector("Woman")≈Vector("Queen")
- 这就是为什么当我们搜索“毛茸茸的家养宠物”时,向量搜索引擎能找到“猫”,即使这两个词在字面上完全不重叠。
1.2 知识的碎片化:文档分块(Chunking)
我们不能把一本 500 页的操作手册直接塞进 Prompt,原因有二:
- 上下文窗口限制:虽然 Gemini 2.5 支持 1M+ Token,但成本昂贵且速度慢。
- 信噪比:过多的无关信息会干扰 LLM 的推理。
因此,我们需要分块:
- 固定大小分块:每 500 个字符切一刀。简单但容易切断上下文。
- 递归字符分块:基于段落、换行符智能切分,保留语义完整性。
- 语义分块:基于内容含义的变化点进行切分(高效)。
1.3 向量数据库:语义检索引擎
一旦文本被转化为向量,我们需要一个专门的数据库来存储和查询它们。这就是 Vector Database(如 Pinecone, Weaviate, Chroma, Milvus)。
- HNSW 算法:大多数向量库使用“分层可导航小世界”算法。它不像传统 SQL 那样扫描全表,而是在高维空间中快速“跳跃”到最近的邻居。
- 混合搜索(Hybrid Search):这是生产环境的标配。
- 向量搜索:擅长理解概念(“好吃的意大利面” -> 匹配“肉酱千层面”)。
- 关键字搜索 (BM25):擅长匹配专有名词(“错误代码 0x8004” -> 必须精准匹配)。
- RAG 系统:通常结合两者,使用 Reciprocal Rank Fusion (RRF) 算法重新排序结果。
第二部分:RAG 的进化——从被动检索到主动推理
传统的 RAG(Naive RAG)是一个线性的管道:查询 -> 检索 -> 生成。但在复杂场景下,它经常失效。于是,两种进阶模式应运而生。
2.1 GraphRAG:连接知识的孤岛
痛点:如果你问“史蒂夫·乔布斯和比尔·盖茨在商业策略上有哪些共同的合作伙伴?”,传统 RAG 可能会失败。因为它只能找到提到乔布斯的文档和提到盖茨的文档,却很难发现它们之间隐晦的“跨文档”联系。
解决方案:知识图谱(Knowledge Graph)。
- 原理:GraphRAG 不仅存储文本片段,还提取实体(节点)和关系(边)。
- 节点:Apple, Microsoft, Steve Jobs.
- 边:Founded_by, Competes_with, Partnered_with.
- 优势:LLM 可以沿着图的路径进行“多跳推理”(Multi-hop Reasoning),综合分散在不同文档中的信息片段,构建出完整的答案。
2.2 Agentic RAG:智能体式检索
这是 RAG 的终极形态。我们不再把检索看作一个简单的函数调用,而是由一个智能体来主导整个过程。
核心差异:
- 传统 RAG:一次性检索。如果查不到,就说“不知道”。
- Agentic RAG:
- 规划(Planning):将“分析 Apple 2024 年 Q3 财报”拆解为“查找营收”、“查找净利润”、“查找大中华区数据”三个子任务。
- 反思(Reflection):检索回来的数据是 2023 年的?智能体自我纠错:“数据过时,我需要重新搜索 2024 年的数据。”
- 工具使用(Tool Use):不仅能查向量库,还能调用 Google Search 补充实时信息,甚至调用 Python 计算器处理财报数据。
图解架构: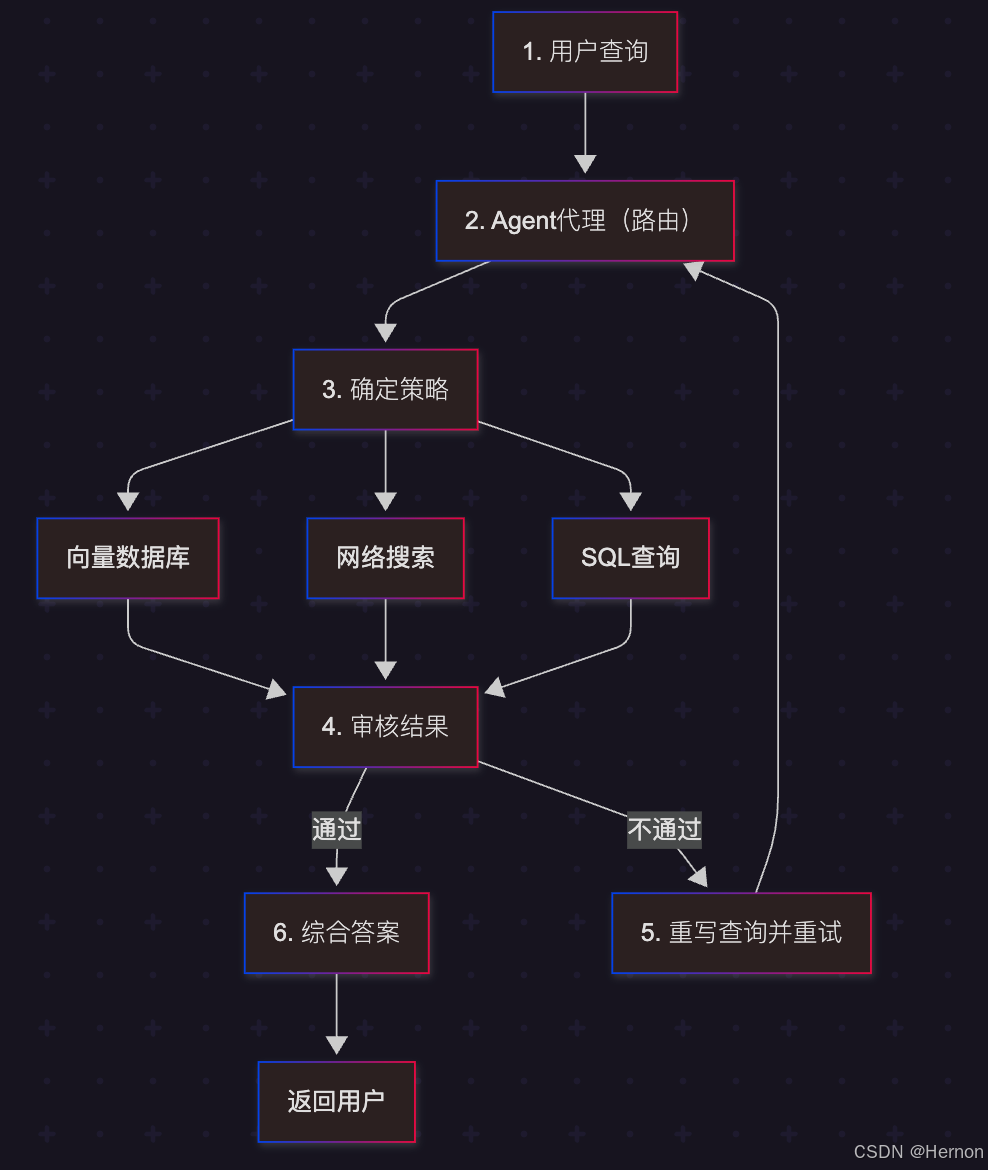
第三部分:实战架构与代码实现
我们将使用 Python 生态中最前沿的 LangChain v0.3 和 LangGraph 来构建一个具备自我修正能力的 RAG 智能体。
3.1 场景定义:私有法律顾问 Bot
我们需要构建一个 AI 助手,它基于一套私有的法律合同文档回答用户问题。
挑战:法律术语晦涩,用户提问往往不准确,且通过一次检索很难找到完整条款。
3.2 步骤一:数据索引管道 (Indexing Pipeline)
首先,我们需要将文档加载并存入向量库。这里使用 Chroma 作为本地向量库。
# 依赖安装
# pip install langchain-chroma langchain-openai langchain-community pypdf
import os
from langchain_community.document_loaders import PyPDFLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_chroma import Chroma
from langchain_openai import OpenAIEmbeddings
# 1. 加载文档
file_path = "./contracts/service_agreement.pdf"
loader = PyPDFLoader(file_path)
docs = loader.load()
# 2. 文档分块 (Chunking)
# 法律文档上下文强,我们设置较大的块和重叠
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
add_start_index=True
)
splits = text_splitter.split_documents(docs)
# 3. 嵌入并存储 (Indexing)
vectorstore = Chroma.from_documents(
documents=splits,
embedding=OpenAIEmbeddings(),
collection_name="legal_docs"
)
# 4. 创建检索器 (Retriever)
retriever = vectorstore.as_retriever(search_kwargs={"k": 5})
3.3 步骤二:构建自我修正 RAG (Self-Corrective RAG) with LangGraph
我们将构建一个基于图的智能体,包含以下节点:
- Retrieve:检索文档。
- Grade Documents:评估检索到的文档是否相关。如果不相关,触发查询重写。
- Generate:生成答案。
- Hallucination Check:检查生成的答案是否产生幻觉(是否基于检索内容)。
from typing import Annotated, List, Dict
from typing_extensions import TypedDict
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Field
from langchain_core.output_parsers import StrOutputParser
from langgraph.graph import END, StateGraph
# --- 状态定义 ---
class GraphState(TypedDict):
question: str
generation: str
documents: List[str]
# --- 核心组件初始化 ---
llm = ChatOpenAI(model="gpt-4o", temperature=0)
# --- 1. 评分器 (Grader) ---
# 用于评估检索到的文档是否与问题相关
class GradeDocuments(BaseModel):
"""Binary score for relevance check."""
binary_score: str = Field(description="Documents are relevant to the question, 'yes' or 'no'")
structured_llm_grader = llm.with_structured_output(GradeDocuments)
system_prompt = """你是一个评分员,负责评估检索到的文档与用户问题的相关性。
如果文档包含与问题相关的关键词或语义,请评为 'yes',否则评为 'no'。"""
grade_prompt = ChatPromptTemplate.from_messages(
[("system", system_prompt), ("human", "Retrieved document: \n\n {document} \n\n User question: {question}")]
)
retrieval_grader = grade_prompt | structured_llm_grader
# --- 2. 生成器 (Generator) ---
prompt = ChatPromptTemplate.from_template(
"""你是一个法律顾问助手。利用以下检索到的上下文回答问题。
如果你不知道答案,直接说不知道,不要编造。
答案需简明扼要。
Question: {question}
Context: {context}
Answer:"""
)
rag_chain = prompt | llm | StrOutputParser()
# --- 3. 查询重写器 (Query Rewriter) ---
# 当检索质量差时,重写查询
rewrite_system = """你是一个查询优化器。请分析输入的问题,将其重写为一个更能被向量数据库理解的版本。
只需输出重写后的问题,不要解释。"""
rewrite_prompt = ChatPromptTemplate.from_messages(
[("system", rewrite_system), ("human", "Original Question: {question}")]
)
question_rewriter = rewrite_prompt | llm | StrOutputParser()
# --- 节点函数定义 ---
def retrieve(state):
print("---RETRIEVE---")
question = state["question"]
documents = retriever.invoke(question)
return {"documents": documents, "question": question}
def grade_documents(state):
print("---CHECK RELEVANCE---")
question = state["question"]
documents = state["documents"]
filtered_docs = []
web_search = "No"
for d in documents:
score = retrieval_grader.invoke({"question": question, "document": d.page_content})
if score.binary_score == "yes":
print("---GRADE: DOCUMENT RELEVANT---")
filtered_docs.append(d)
else:
print("---GRADE: DOCUMENT NOT RELEVANT---")
# 如果文档都不相关,我们标记需要 web_search (或重写)
continue
if not filtered_docs:
# 如果没有相关文档,触发重写机制
web_search = "Yes"
return {"documents": filtered_docs, "question": question, "web_search": web_search}
def transform_query(state):
print("---TRANSFORM QUERY---")
question = state["question"]
documents = state["documents"]
# 重写问题
better_question = question_rewriter.invoke({"question": question})
print(f"---MODIFIED QUESTION: {better_question}---")
return {"documents": documents, "question": better_question}
def generate(state):
print("---GENERATE---")
question = state["question"]
documents = state["documents"]
# RAG Generation
generation = rag_chain.invoke({"context": documents, "question": question})
return {"documents": documents, "question": question, "generation": generation}
# --- 构建图 (The Graph) ---
workflow = StateGraph(GraphState)
# 添加节点
workflow.add_node("retrieve", retrieve)
workflow.add_node("grade_documents", grade_documents)
workflow.add_node("generate", generate)
workflow.add_node("transform_query", transform_query)
# 定义边
workflow.set_entry_point("retrieve")
workflow.add_edge("retrieve", "grade_documents")
# 条件边:决定下一步是生成还是重写查询
def decide_to_generate(state):
web_search = state.get("web_search") # 这里复用变量名作为标志位
if web_search == "Yes":
print("---DECISION: ALL DOCUMENTS ARE NOT RELEVANT, TRANSFORM QUERY---")
return "transform_query"
else:
print("---DECISION: GENERATE---")
return "generate"
workflow.add_conditional_edges(
"grade_documents",
decide_to_generate,
{
"transform_query": "transform_query",
"generate": "generate",
},
)
# 转换查询后,重新检索
workflow.add_edge("transform_query", "retrieve")
workflow.add_edge("generate", END)
# 编译应用
app = workflow.compile()
3.4 运行与观测
# 运行示例
inputs = {"question": "关于服务终止的违约金条款是怎样的?"}
for output in app.stream(inputs):
for key, value in output.items():
print(f"Finished running: {key}")
print("\n=== Final Answer ===")
# 最终结果通常在最后的 generation 状态中
# (此处需从 stream 结果或 get_state 中获取)
代码解析:
这个 LangGraph 应用展示了 Agentic RAG 的核心思想:不盲目信任检索结果。
- 它首先检索。
- 然后有一个专门的 LLM (Grader) 像老师改卷子一样,检查检索回来的文档是否真的回答了问题。
- 如果文档都不相关(可能是因为用户问题写得不好),它不会强行生成幻觉,而是进入
transform_query节点,重写问题,然后重新检索。 - 这形成了一个闭环,大大提高了 RAG 的鲁棒性。
第四部分:Google ADK 的企业级 RAG 实战
如果你是 Google Cloud 用户,ADK (Agent Developer Kit) 提供了更原生的 RAG 支持,特别是与 Vertex AI Search 的集成。
4.1 Vertex AI Memory Service
ADK 不仅仅把 RAG 看作检索,而是将其封装为 Memory Service。
from google.adk.memory import VertexAiRagMemoryService
from google.adk.agents import Agent
# 1. 配置 RAG 服务
# 这里指向 Google Cloud 上的托管 RAG 语料库
RAG_CORPUS_ID = "projects/my-project/locations/us-central1/ragCorpora/123456"
memory_service = VertexAiRagMemoryService(
rag_corpus=RAG_CORPUS_ID,
similarity_top_k=5,
vector_distance_threshold=0.6 # 过滤掉相关度低的结果
)
# 2. 将 RAG 集成到智能体
# 在 ADK 中,RAG 通常作为一种“工具”或“记忆检索”能力赋予智能体
rag_agent = Agent(
name="EnterpriseSearchBot",
model="gemini-2.0-flash",
instruction="""
你是一个企业知识助手。
当用户提问时,请始终首先查询 RAG 记忆库。
仅基于检索到的上下文回答问题。
""",
# ADK 会自动将 memory_service 的检索能力注入上下文
memory=memory_service
)
# 3. 运行
# ... (Runner 初始化代码同前几章)
第五部分:生产环境的挑战与最佳实践
构建一个 Demo RAG 很容易,但要在生产环境中落地,必须解决以下“隐形”问题:
5.1 数据清洗:Garbage In, Garbage Out
最先进的模型也救不了糟糕的数据。
- 解析难题:PDF 中的表格、多栏排版、页眉页脚是 RAG 的噩梦。使用高级解析工具(如 Unstructured.io 或 LlamaParse)至关重要。
- 元数据增强:不要只存文本。存入
{"file_name": "Q3报告", "author": "Finance", "year": 2024}。这样在检索时可以进行元数据过滤(Metadata Filtering),例如:“只在 2024 年的文档里搜索”。
5.2 延迟优化 (Latency)
RAG 增加了额外的检索步骤,会导致响应变慢。
- 语义缓存 (Semantic Cache):如果用户问了类似的问题(语义接近),直接返回之前的缓存答案,跳过检索和生成。
- 流式输出 (Streaming):LangGraph 支持
stream(),确保用户在检索完成后立即看到第一个字,而不是等待整个答案生成。
5.3 评估体系 (RAGas)
你怎么知道你的 RAG 系统变好了还是变坏了?
- RAG Triad (RAG 三元组指标):
- Context Relevance:检索到的文档真的和问题相关吗?
- Groundedness (Faithfulness):生成的答案真的来自检索文档吗?(防幻觉)
- Answer Relevance:生成的答案真的回答了用户的问题吗?
- 使用自动化评估框架(如 Ragas 或 DeepEval)在 CI/CD 流程中持续监控这些指标。
结语:RAG 是智能体的“外脑”
RAG 技术正在经历从“简单的向量搜索”向“复杂的智能体推理”转变的过程。
通过 GraphRAG,我们让 AI 看到了数据间的隐秘联系;通过 Agentic RAG,我们赋予了 AI 像人类研究员一样“反思、重试、综合”的能力。
在未来,AI 智能体的强大与否,不仅取决于它的大脑(LLM)有多大,更取决于它的外脑(RAG Knowledge Base)有多丰富、检索机制有多智能。掌握了 RAG,你就掌握了将通用 AI 转化为垂直领域专家的金钥匙。
参考资料
1.Lewis, P., et al. (2020). Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. https://arxiv.org/abs/2005.11401
2.Google AI for Developers Documentation. Retrieval Augmented Generation - https://cloud.google.com/vertex-ai/generative-ai/docs/rag-engine/rag-overview
3.Retrieval-Augmented Generation with Graphs (GraphRAG), https://arxiv.org/abs/2501.00309
4.LangChain and LangGraph: Leonie Monigatti, “Retrieval-Augmented Generation (RAG): From Theory to LangChain Implementation,” https://medium.com/data-science/retrieval-augmented-generation-rag-from-theory-to-langchain-implementation-4e9bd5f6a4f2
5.Google Cloud Vertex AI RAG Corpus https://cloud.google.com/vertex-ai/generative-ai/docs/rag-engine/manage-your-rag-corpus#corpus-management
6.Antonio Gulli 《Agentic Design Patterns》

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 17
17 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)