WebRTC音频模块详细介绍第二部分-发送端
音频模块是WebRTC非常重要的部分,音频模块中的NetEq是WebRTC的三大核心技术(NetEq/GCC/音频3A)之一,我们分四部分介绍该模块,本文是第二部分(整体介绍)。WebRTC音频模块详细介绍第一部分-整体介绍WebRTC音频模块详细介绍第二部分-发送端WebRTC音频模块详细介绍第三部分-接收端WebRTC音频模块详细介绍第二部分-体验保障WebRTC支持G.722、iLBC、Op
1. 前言
音频模块是WebRTC非常重要的部分,音频模块中的NetEq是WebRTC的三大核心技术(NetEq/GCC/音频3A)之一,我们分七部分介绍该模块,本文是第二部分(发送端)。这个专题包括:
- WebRTC音频模块详细介绍第一部分-整体介绍
- WebRTC音频模块详细介绍第二部分-发送端
- WebRTC音频模块详细介绍第三部分-接收端
- WebRTC音频模块详细介绍第四部分-NetEq核心原理
- WebRTC音频模块详细介绍第五部分-NetEq音频决策
- WebRTC音频模块详细介绍第六部分-NetEq数字信号处理
- WebRTC音频模块详细介绍第七部分-体验保障
2. 音频采集&编码&发送
2.1. 调用堆栈
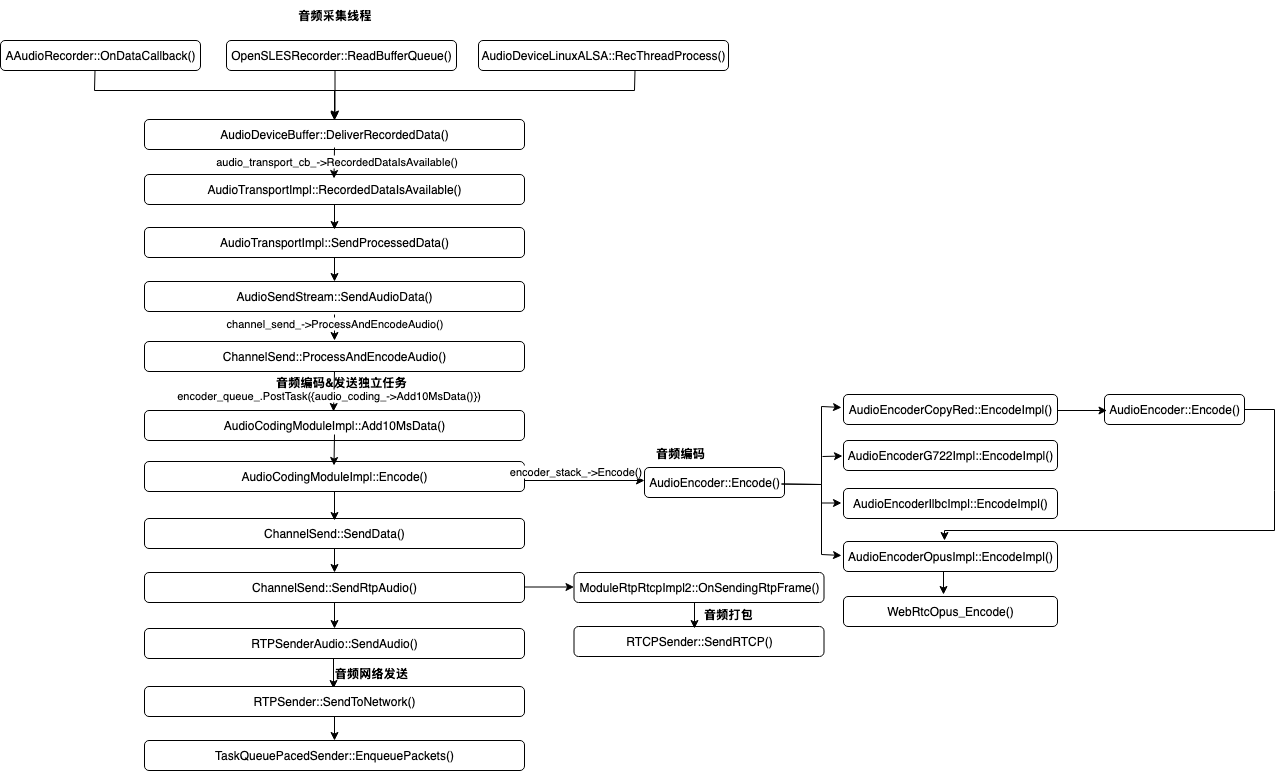
2.2. RTP报文的数据生成和发送
WebRTC支持多种平台的音频采集能力,包括Android的OpenSL ES、AAudio,也支持Linux的ALSA。OpenSL ES是Android最早商用、最为成熟的原生库,而AAudio是在 Android O 版本中引入的全新 Android C API,此API 专为低延迟的高性能音频应用而设计。音频应用,特别是在线KTV等对时延要求特别高的场景,都会优先使用AAudio。Alsa是Advanced Linux Sound Architecture的缩写,即高级Linux声音架构,Alsa在Linux操作系统上提供了对音频的支持。当前WebRTC还支持IOS、Windows、Mac。
这些音频库在采集到音频后,都会调用AudioDeviceBuffer::DeliverRecordedData(),进入到编码、发送环节。函数第11行用到的audio_transport_cb_是在WebRtcVoiceEngine::Init()中完成注册的,真实调用的是AudioTransportImpl::RecordedDataIsAvailable(),该函数最终执行encoder_queue_.PostTask()。简言之,录制线程将录制的麦克风音频数据抛上来之后,送进编码线程,后者完成音频编码和网络发送的工作。
int32_t AudioDeviceBuffer::DeliverRecordedData() {
if (!audio_transport_cb_) {
RTC_LOG(LS_WARNING) << "Invalid audio transport";
return 0;
}
const size_t frames = rec_buffer_.size() / rec_channels_;
const size_t bytes_per_frame = rec_channels_ * sizeof(int16_t);
uint32_t new_mic_level_dummy = 0;
uint32_t total_delay_ms = play_delay_ms_ + rec_delay_ms_;
/*Call AudioTransportImpl::RecordedDataIsAvailable()*/
int32_t res = audio_transport_cb_->RecordedDataIsAvailable(
rec_buffer_.data(), frames, bytes_per_frame, rec_channels_,
rec_sample_rate_, total_delay_ms, 0, 0, typing_status_,
new_mic_level_dummy, capture_timestamp_ns_);
if (res == -1) {
RTC_LOG(LS_ERROR) << "RecordedDataIsAvailable() failed";
}
return 0;
}void WebRtcVoiceEngine::Init() {
...
// Connect the ADM to our audio path.
adm()->RegisterAudioCallback(audio_state()->audio_transport());
...
}int32_t AudioDeviceBuffer::RegisterAudioCallback(
AudioTransport* audio_callback) {
...
audio_transport_cb_ = audio_callback;
return 0;
}int32_t AudioTransportImpl::RecordedDataIsAvailable(
const void* audio_data,
size_t number_of_frames,
size_t bytes_per_sample,
size_t number_of_channels,
uint32_t sample_rate,
uint32_t audio_delay_milliseconds,
int32_t /*clock_drift*/,
uint32_t /*volume*/,
bool key_pressed,
uint32_t& /*new_mic_volume*/,
absl::optional<int64_t>
estimated_capture_time_ns) { // NOLINT: to avoid changing APIs
int send_sample_rate_hz = 0;
size_t send_num_channels = 0;
bool swap_stereo_channels = false;
{
MutexLock lock(&capture_lock_);
send_sample_rate_hz = send_sample_rate_hz_;
send_num_channels = send_num_channels_;
swap_stereo_channels = swap_stereo_channels_;
}
std::unique_ptr<AudioFrame> audio_frame(new AudioFrame());
InitializeCaptureFrame(sample_rate, send_sample_rate_hz, number_of_channels,
send_num_channels, audio_frame.get());
voe::RemixAndResample(static_cast<const int16_t*>(audio_data),
number_of_frames, number_of_channels, sample_rate,
&capture_resampler_, audio_frame.get());
ProcessCaptureFrame(audio_delay_milliseconds, key_pressed,
swap_stereo_channels, audio_processing_,
audio_frame.get());
if (estimated_capture_time_ns) {
audio_frame->set_absolute_capture_timestamp_ms(*estimated_capture_time_ns /
1000000);
}
if (async_audio_processing_){
async_audio_processing_->Process(std::move(audio_frame));
}else{
SendProcessedData(std::move(audio_frame));
}
return 0;
}void AudioTransportImpl::SendProcessedData(
std::unique_ptr<AudioFrame> audio_frame) {
MutexLock lock(&capture_lock_);
if (audio_senders_.empty())
return;
auto it = audio_senders_.begin();
while (++it != audio_senders_.end()) {
auto audio_frame_copy = std::make_unique<AudioFrame>();
audio_frame_copy->CopyFrom(*audio_frame);
(*it)->SendAudioData(std::move(audio_frame_copy));
}
// Send the original frame to the first stream w/o copying.
/*Call AudioSendStream::SendAudioData()*/
(*audio_senders_.begin())->SendAudioData(std::move(audio_frame));
}void AudioSendStream::SendAudioData(std::unique_ptr<AudioFrame> audio_frame) {
...
/*Call ChannelSend::ProcessAndEncodeAudio()*/
channel_send_->ProcessAndEncodeAudio(std::move(audio_frame));
}void ChannelSend::ProcessAndEncodeAudio(
std::unique_ptr<AudioFrame> audio_frame) {
...
encoder_queue_.PostTask(
[this, audio_frame = std::move(audio_frame)]() mutable {
...
// This call will trigger AudioPacketizationCallback::SendData if
// encoding is done and payload is ready for packetization and
// transmission. Otherwise, it will return without invoking the
// callback.
/*Call AudioCodingModuleImpl::Add10MsData()*/
if (audio_coding_->Add10MsData(*audio_frame) < 0) {
RTC_DLOG(LS_ERROR) << "ACM::Add10MsData() failed.";
return;
}
});
}音频编码线程执行AudioCodingModuleImpl::Add10MsData(),完成了3个阶段的工作:
- 采用特定的音频格式实现音频原始数据(PCM数据)的编码,这部分的细节参考音频编码章节;
- 基于RTP格式生成合适的RTP Header,并将音频编码后的数据作为Payload封装到RTP报文中,这部分工作参考RTPSenderAudio::SendAudio();
- 将RTP报文送入网络线程,然后进入统一的QoS控制,包括BWE估计、音频带宽分配、平滑发送,这部分工作参考RTPSender::SendToNetwork()及后续流程。
// Add 10MS of raw (PCM) audio data to the encoder.
int AudioCodingModuleImpl::Add10MsData(const AudioFrame& audio_frame) {
MutexLock lock(&acm_mutex_);
int r = Add10MsDataInternal(audio_frame, &input_data_);
return r < 0
? r
: Encode(input_data_, audio_frame.absolute_capture_timestamp_ms());
}int32_t AudioCodingModuleImpl::Encode(
const InputData& input_data,
absl::optional<int64_t> absolute_capture_timestamp_ms) {
...
// Clear the buffer before reuse - encoded data will get appended.
encode_buffer_.Clear();
/*Call AudioEncoder::Encode()*/
encoded_info = encoder_stack_->Encode(
rtp_timestamp,
rtc::ArrayView<const int16_t>(
input_data.audio,
input_data.audio_channel * input_data.length_per_channel),
&encode_buffer_);
...
{
MutexLock lock(&callback_mutex_);
if (packetization_callback_) {
/*Call ChannelSend::SendData*/
packetization_callback_->SendData(
frame_type, encoded_info.payload_type, encoded_info.encoded_timestamp,
encode_buffer_.data(), encode_buffer_.size(),
absolute_capture_timestamp_ms.value_or(-1));
}
}
previous_pltype_ = encoded_info.payload_type;
return static_cast<int32_t>(encode_buffer_.size());
}ChannelSend::ChannelSend(
...)
: ...{
audio_coding_ = AudioCodingModule::Create();
...
rtp_rtcp_ = ModuleRtpRtcpImpl2::Create(configuration);
rtp_rtcp_->SetSendingMediaStatus(false);
rtp_sender_audio_ = std::make_unique<RTPSenderAudio>(configuration.clock,
rtp_rtcp_->RtpSender());
// Ensure that RTCP is enabled by default for the created channel.
rtp_rtcp_->SetRTCPStatus(RtcpMode::kCompound);
int error = audio_coding_->RegisterTransportCallback(this);
...
}int AudioCodingModuleImpl::RegisterTransportCallback(
AudioPacketizationCallback* transport) {
MutexLock lock(&callback_mutex_);
packetization_callback_ = transport;
return 0;
}int32_t ChannelSend::SendData(AudioFrameType frameType,
uint8_t payloadType,
uint32_t rtp_timestamp,
const uint8_t* payloadData,
size_t payloadSize,
int64_t absolute_capture_timestamp_ms) {
rtc::ArrayView<const uint8_t> payload(payloadData, payloadSize);
...
return SendRtpAudio(frameType, payloadType, rtp_timestamp, payload,
absolute_capture_timestamp_ms);
}
int32_t ChannelSend::SendRtpAudio(AudioFrameType frameType,
uint8_t payloadType,
uint32_t rtp_timestamp,
rtc::ArrayView<const uint8_t> payload,
int64_t absolute_capture_timestamp_ms) {
...
// Push data from ACM to RTP/RTCP-module to deliver audio frame for
// packetization.
/*Call ModuleRtpRtcpImpl2::OnSendingRtpFrame()*/
if (!rtp_rtcp_->OnSendingRtpFrame(rtp_timestamp,
// Leaving the time when this frame was
// received from the capture device as
// undefined for voice for now.
-1, payloadType,
/*force_sender_report=*/false)) {
return -1;
}
// This call will trigger Transport::SendPacket() from the RTP/RTCP module.
if (!rtp_sender_audio_->SendAudio(/*Call RTPSenderAudio::SendAudio*/
frameType, payloadType, rtp_timestamp + rtp_rtcp_->StartTimestamp(),
payload.data(), payload.size(), absolute_capture_timestamp_ms)) {
RTC_DLOG(LS_ERROR)
<< "ChannelSend::SendData() failed to send data to RTP/RTCP module";
return -1;
}
return 0;
}bool RTPSenderAudio::SendAudio(AudioFrameType frame_type,
int8_t payload_type,
uint32_t rtp_timestamp,
const uint8_t* payload_data,
size_t payload_size) {
return SendAudio(frame_type, payload_type, rtp_timestamp, payload_data,
payload_size,
// TODO(bugs.webrtc.org/10739) replace once plumbed.
/*absolute_capture_timestamp_ms=*/-1);
}
bool RTPSenderAudio::SendAudio(AudioFrameType frame_type,
int8_t payload_type,
uint32_t rtp_timestamp,
const uint8_t* payload_data,
size_t payload_size,
int64_t absolute_capture_timestamp_ms) {
...
/*创建RTP报文缓冲区并设置包头字段,包括M/PT/Timestamp/SSRC/CSRC*/
std::unique_ptr<RtpPacketToSend> packet = rtp_sender_->AllocatePacket();
packet->SetMarker(MarkerBit(frame_type, payload_type));
packet->SetPayloadType(payload_type);
packet->SetTimestamp(rtp_timestamp);
packet->set_capture_time(clock_->CurrentTime());
// Update audio level extension, if included.
packet->SetExtension<AudioLevel>(
frame_type == AudioFrameType::kAudioFrameSpeech, audio_level_dbov);
...
/*调整RTP报文的缓冲区大小,并将音频编码后的数据拷贝到RTP Payload指向的内存区*/
uint8_t* payload = packet->AllocatePayload(payload_size);
if (!payload) // Too large payload buffer.
return false;
memcpy(payload, payload_data, payload_size);
{
MutexLock lock(&send_audio_mutex_);
last_payload_type_ = payload_type;
}
packet->set_packet_type(RtpPacketMediaType::kAudio);
packet->set_allow_retransmission(true);
/*Call RTPSender::SendToNetwork*/
bool send_result = rtp_sender_->SendToNetwork(std::move(packet));
if (first_packet_sent_()) {
RTC_LOG(LS_INFO) << "First audio RTP packet sent to pacer";
}
return send_result;
}bool RTPSender::SendToNetwork(std::unique_ptr<RtpPacketToSend> packet) {
auto packet_type = packet->packet_type();
if (packet->capture_time() <= Timestamp::Zero()) {
packet->set_capture_time(clock_->CurrentTime());
}
std::vector<std::unique_ptr<RtpPacketToSend>> packets;
packets.emplace_back(std::move(packet));
//call TaskQueuePacedSender::EnqueuePackets
/*将RTP报文送入网络线程,然后进入统一的QoS控制,包括BWE估计、音频带宽分配、平滑发送*/
paced_sender_->EnqueuePackets(std::move(packets));
return true;
}2.3. RTCP报文的发送
ChannelSend::SendRtpAudio()在将音频RTP报文加入到网络线程(实现统一的带宽分配和平滑发送)之前,尝试将积攒的RTCP报文汇聚在一个UDP Packet中,一次发送出去。由于UDP Packet有max packet size的限制(不能超过1500-28=1472,其中1500是以太网报文的最大长度,28是IP Header+UDP Header的总长度),如果UDP Packet的当前长度到达上限了,后面的RTCP报文会被丢弃(除非is_volatile这个Flag设置为False,这种情况下该类型的RTCP报文会在下次时机到来时继续发送)。
bool ModuleRtpRtcpImpl2::OnSendingRtpFrame(uint32_t timestamp,
int64_t capture_time_ms,
int payload_type,
bool force_sender_report) {
if (!Sending()) {
return false;
}
// TODO(bugs.webrtc.org/12873): Migrate this method and it's users to use
// optional Timestamps.
absl::optional<Timestamp> capture_time;
if (capture_time_ms > 0) {
capture_time = Timestamp::Millis(capture_time_ms);
}
absl::optional<int> payload_type_optional;
if (payload_type >= 0)
payload_type_optional = payload_type;
auto closure = [this, timestamp, capture_time, payload_type_optional,
force_sender_report] {
rtcp_sender_.SetLastRtpTime(timestamp, capture_time, payload_type_optional);
// Make sure an RTCP report isn't queued behind a key frame.
if (rtcp_sender_.TimeToSendRTCPReport(force_sender_report)){
/*Call RTCPSender::SendRTCP*/
rtcp_sender_.SendRTCP(GetFeedbackState(), kRtcpReport);
}
};
if (worker_queue_->IsCurrent()) {
closure();
} else {
worker_queue_->PostTask(SafeTask(task_safety_.flag(), std::move(closure)));
}
return true;
}int32_t RTCPSender::SendRTCP(const FeedbackState& feedback_state,
RTCPPacketType packet_type,
int32_t nack_size,
const uint16_t* nack_list) {
int32_t error_code = -1;
auto callback = [&](rtc::ArrayView<const uint8_t> packet) {
/*Call TransportForMediaChannels::SendRtcp()*/
if (transport_->SendRtcp(packet.data(), packet.size())) {
error_code = 0;
if (event_log_) {
event_log_->Log(std::make_unique<RtcEventRtcpPacketOutgoing>(packet));
}
}
};
absl::optional<PacketSender> sender;
{
MutexLock lock(&mutex_rtcp_sender_);
sender.emplace(callback, max_packet_size_);
auto result = ComputeCompoundRTCPPacket(feedback_state, packet_type,
nack_size, nack_list, *sender);
if (result) {
return *result;
}
}
sender->Send();
return error_code;
}我们看下RTCPSender::ComputeCompoundRTCPPacket()的实现细节。函数开头通过SetFlag()将RTCP报文类型设置到了report_flags_。除了该函数,其他地方也会调用SetFlag(),所以在这里统一做了处理,对report_flags_做了遍历,为每个类型的RTCP报文找到对应的序列化方案并执行。注意3个细节:
- 执行序列化时,由于是尝试将所有的RTCP报文放在一个UDP Packet中,而后者是有Size上限的,在达到上限后,序列化会失败,但这里并没有判断这个失败,所以这些RTCP报文被默默地丢弃;
- 在ModuleRtpRtcpImpl2::OnSendingRtpFrame()设置的kRtcpReport本身不属于任何类型的RTCP报文,其作用是触发所有已在report_flags_登记的RTCP报文尽快创建和发送。
- 所有可以被序列化的RTCP报文的create方法都在RTCPSender::RTCPSender()中指定了,例如:
builders_[kRtcpPli] = &RTCPSender::BuildPLI;
builders_[kRtcpFir] = &RTCPSender::BuildFIR;
builders_[kRtcpNack] = &RTCPSender::BuildNACK;
absl::optional<int32_t> RTCPSender::ComputeCompoundRTCPPacket(
const FeedbackState& feedback_state,
RTCPPacketType packet_type,
int32_t nack_size,
const uint16_t* nack_list,
PacketSender& sender) {
if (method_ == RtcpMode::kOff) {
RTC_LOG(LS_WARNING) << "Can't send rtcp if it is disabled.";
return -1;
}
// Add the flag as volatile. Non volatile entries will not be overwritten.
// The new volatile flag will be consumed by the end of this call.
SetFlag(packet_type, true);
...
auto it = report_flags_.begin();
while (it != report_flags_.end()) {
uint32_t rtcp_packet_type = it->type;
if (it->is_volatile) {
report_flags_.erase(it++);
} else {
++it;
}
// If there is a BYE, don't append now - save it and append it
// at the end later.
if (rtcp_packet_type == kRtcpBye) {
create_bye = true;
continue;
}
auto builder_it = builders_.find(rtcp_packet_type);
if (builder_it == builders_.end()) {
RTC_DCHECK_NOTREACHED()
<< "Could not find builder for packet type " << rtcp_packet_type;
} else {
BuilderFunc func = builder_it->second;
(this->*func)(context, sender);
}
}
...
return absl::nullopt;
}void RTCPSender::SetFlag(uint32_t type, bool is_volatile) {
if (type & kRtcpAnyExtendedReports) {
report_flags_.insert(ReportFlag(kRtcpAnyExtendedReports, is_volatile));
} else {
report_flags_.insert(ReportFlag(type, is_volatile));
}
}RTCPSender::RTCPSender(Configuration config)
: ... {
builders_[kRtcpSr] = &RTCPSender::BuildSR;
builders_[kRtcpRr] = &RTCPSender::BuildRR;
builders_[kRtcpSdes] = &RTCPSender::BuildSDES;
builders_[kRtcpPli] = &RTCPSender::BuildPLI;
builders_[kRtcpFir] = &RTCPSender::BuildFIR;
builders_[kRtcpRemb] = &RTCPSender::BuildREMB;
builders_[kRtcpBye] = &RTCPSender::BuildBYE;
builders_[kRtcpLossNotification] = &RTCPSender::BuildLossNotification;
builders_[kRtcpTmmbr] = &RTCPSender::BuildTMMBR;
builders_[kRtcpTmmbn] = &RTCPSender::BuildTMMBN;
builders_[kRtcpNack] = &RTCPSender::BuildNACK;
builders_[kRtcpAnyExtendedReports] = &RTCPSender::BuildExtendedReports;
}2.4. 音频编码
2.4.1. 预备知识
2.4.1.1. 主流音频编码介绍
WebRTC支持G.722、iLBC、Opus三种音频编码格式。
G.722.1是由Polycom提出的一套低码率低复杂度的宽带语音编码算法,可以对语音(300~4000Hz)和7kHz以内的音乐进行编码,采样率为16kHz。由于算法复杂度低,非常适合CPU性能不高的嵌入式平台。
iLBC (internet Low Bitrate Codec)是由GIPS开发的基于低带宽的语音编码(speech),码率为13.3 kb/s (每帧30ms)和15.2 kb/s (每帧20ms), 采样率为8K。iLBC的语音质量比G.711、G.722等都要好,更难得的是,丢包率越高,iLBC在语音质量上的优势就越明显。抗丢包能力强是iLBC最大的特点,解码算法支持PLC(Packet loss concealment,网络丢包消除),通过该技术,iLBC可忍受15%的丢包损失。
下面介绍下PLC的原理。在网络正常情况下,iLBC会记录下当前数据的相关参数和激励信号,以便在之后的数据丢失的情况下进行处理;在当前数据接收正常而之前数据包丢失的情况下,iLBC会对当前解码出的语音和之前模拟生成的语音进行平滑处理,以消除不连贯的感觉;在当前数据包丢失的情况下,iLBC会对之前记录下来的激励信号作相关处理并与随机信号进行混合,以得到模拟的激励信号,从而得到替代丢失语音的模拟语音。
Opus编码是是有损音频编码中的后进者,但表现不俗:从Opus官网的报告(https://opus-codec.org/comparison/)可以看出,Opus在各种码率/频宽下的音质表现均好于同类产品,同时在时延上也有明显优势;另一方面,Opus内部自带了FEC和PLC能力,抗丢包能力不逊于iLBC。再加上Opus是一个开源项目,没有任何专利问题,所以从诞生后很快成为了音频有损压缩领域的王者,被广泛应用于VoIP、视频会议、游戏喊麦等场景。
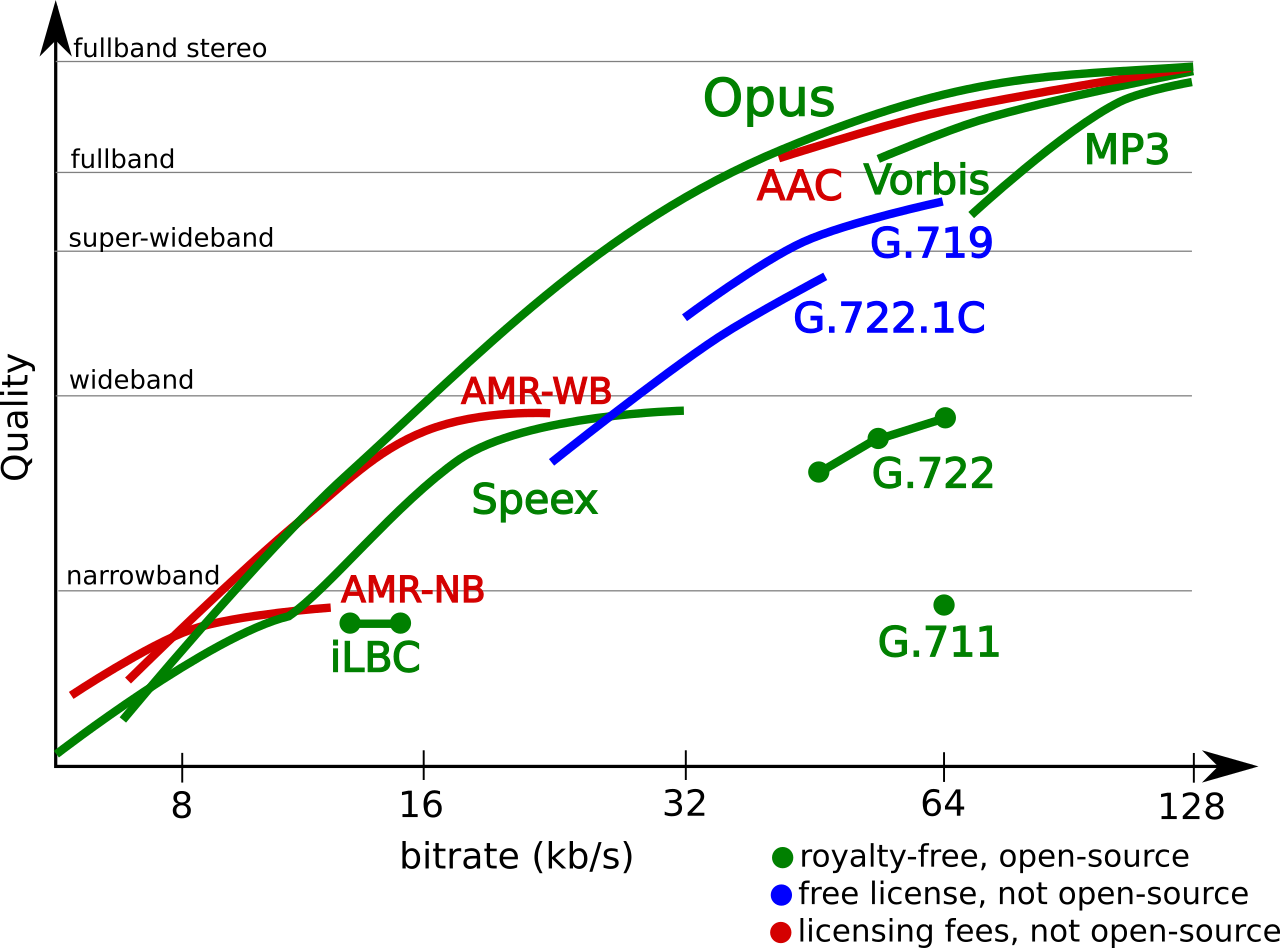
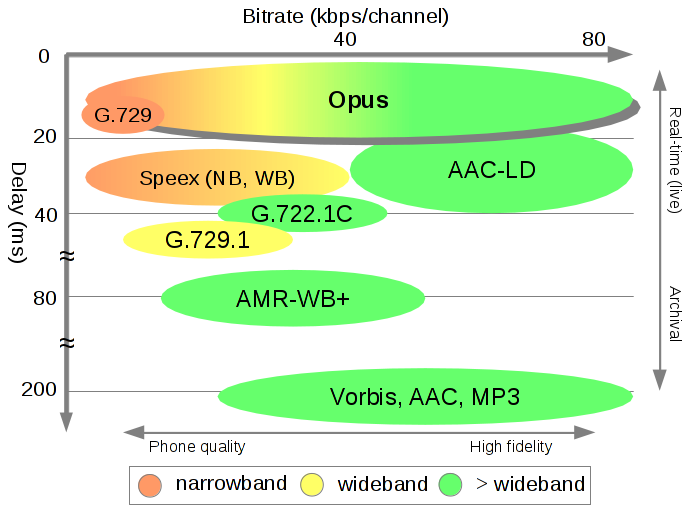
Opus支持如下特性:
- 支持从8KHz(窄带)到48KHz(全频段)的采样率;
- 支持从6Kbps到510Kbps的码率;
- 单帧编码周期从2.5ms到60ms;
- 支持演讲和音乐模式;
- 支持单声道、立体声;
- 支持带内FEC和丢包隐藏算法(PLC);
- 支持恒定码率(CBR)和可变码率(VBR)。
2.4.1.2. Opus编码和RTP封装
在RFC 6716 “Frame Duration”(https://datatracker.ietf.org/doc/html/rfc6716#section-2.1.4)一节介绍了一个RTP报文可以承载的音频数据量:
- 一个RTP报文可以承载多个Opus Frame;
- 一个Opus Frame的编码周期包括:2.5, 5, 10, 20, 40, or 60 ms。
编码周期越长,单个Opus Frame纳入的采样点越多,1秒内需要的RTP报文个数越少,IP(20字节)+UDP(8字节)+RTP(12字节)头部的累计开销越少,同时编码压缩率越高(当编码周期超过20ms时,编码收益变得很小),带宽利用率也越高;另一方面,编码周期会影响时延,例如60ms的编码周期比10ms的编码周期在时延上要多出50ms,而一个RTP报文承载的Opus Frame越多,端到端的延迟越大(报文需要累积一段时间后才能发送)。
假设Opus的码率是48Kbps,20ms的编码周期下一共产生48*20=960字节的数据,外加至少40字节的头部开销,一共需要1000字节。假设Opus的码率为64K,20ms的编码周期下一共产生64*20=1280字节,此时以及超出UDP报文1200字节的总长度限制,此时需要将Opus数据存入多个RTP报文中。
通过RTP分片机制(RFC 7587),一个Opus Frame可以拆分为多个RTP分片单元(Fragmentation Units,FUs),此时第一个分片包含原始RTP头部和部分载荷,后续分片仅包含分片头(4 字节)和剩余载荷。
基于以上因素考虑,我们会在时延、弱网对抗能力和带宽利用率之间平衡,一般的选择是:
- 一个RTP报文里面存放一个Opus Frame;
- 一个Opus Frame的编码周期为20ms;
- 若Opus的码率过大,则通过RTP分片机制,以多个RTP报文发送一帧音频数据。
2.4.2. 代码解析
2.4.2.1. 编码器设置
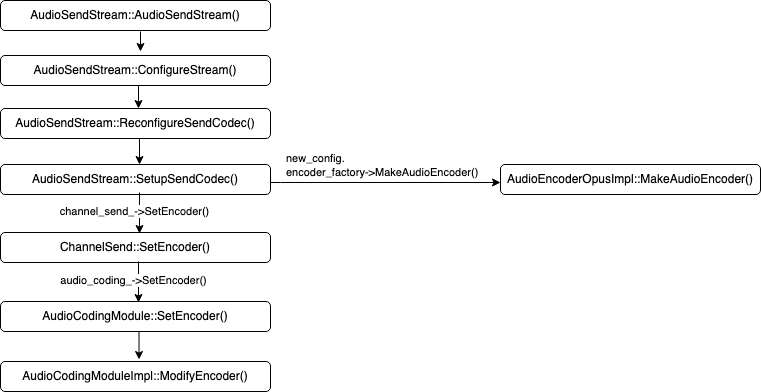
在创建AudioSendStream时,会根据SDP中协商的编码器类型创建Audio Encoder,WebRTC在具体实现时采用了工厂模式,如果指定的是Opus,则会调用AudioEncoderOpusImpl::MakeAudioEncoder()创建AudioEncoderOpusImpl实例,该实例负责Opus Encoding的工作。
创建了Audio Encoder之后,经过逐层调用,最终将AudioCodingModuleImpl::encoder_stack_设置为该编码器。
如果配置中指定了RED(Redundant Encoding),则会创建AudioEncoderCopyRed实例,该实例通过上面创建的Audio Encoder实现对PCM数据的编码,得到Primary Data,再根据RED协议创建Redundant Data。从这一点上我们可以看出WebRTC在RED实现上的另一个问题:RED是通过SDP协商的,一旦协商好之后,RED就是无条件触发的,也就是在任何时候都会按相同的冗余度发送冗余数据,这一点和FEC的实现不同,后者可以实时监测丢包率情况,根据丢包率大小来选择是否开启FEC以及开启后的冗余度。
// Apply current codec settings to a single voe::Channel used for sending.
bool AudioSendStream::SetupSendCodec(const Config& new_config) {
const auto& spec = *new_config.send_codec_spec;
std::unique_ptr<AudioEncoder> encoder =
new_config.encoder_factory->MakeAudioEncoder(
spec.payload_type, spec.format, new_config.codec_pair_id);
if (!encoder) {
RTC_DLOG(LS_ERROR) << "Unable to create encoder for "
<< rtc::ToString(spec.format);
return false;
}
// If a bitrate has been specified for the codec, use it over the
// codec's default.
if (spec.target_bitrate_bps) {
encoder->OnReceivedTargetAudioBitrate(*spec.target_bitrate_bps);
}
...
// Wrap the encoder in a RED encoder, if RED is enabled.
if (spec.red_payload_type) {
AudioEncoderCopyRed::Config red_config;
red_config.payload_type = *spec.red_payload_type;
red_config.speech_encoder = std::move(encoder);
encoder = std::make_unique<AudioEncoderCopyRed>(std::move(red_config),
field_trials_);
}
...
StoreEncoderProperties(encoder->SampleRateHz(), encoder->NumChannels());
channel_send_->SetEncoder(new_config.send_codec_spec->payload_type,
std::move(encoder));
return true;
}template <typename... Ts>
class AudioEncoderFactoryT : public AudioEncoderFactory {
public:
explicit AudioEncoderFactoryT(const FieldTrialsView* field_trials) {
field_trials_ = field_trials;
}
/*...*/
std::unique_ptr<AudioEncoder> MakeAudioEncoder(
int payload_type,
const SdpAudioFormat& format,
absl::optional<AudioCodecPairId> codec_pair_id) override {
return Helper<Ts...>::MakeAudioEncoder(payload_type, format, codec_pair_id,
field_trials_);
}
const FieldTrialsView* field_trials_;
};std::unique_ptr<AudioEncoder> AudioEncoderOpusImpl::MakeAudioEncoder(
const AudioEncoderOpusConfig& config,
int payload_type) {
if (!config.IsOk()) {
RTC_DCHECK_NOTREACHED();
return nullptr;
}
return std::make_unique<AudioEncoderOpusImpl>(config, payload_type);
}2.4.2.2. 音频编码
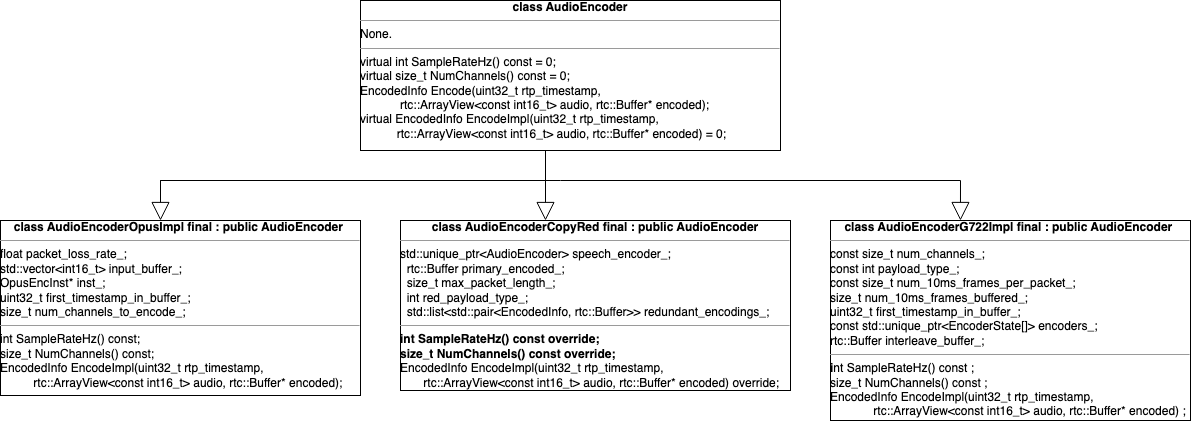
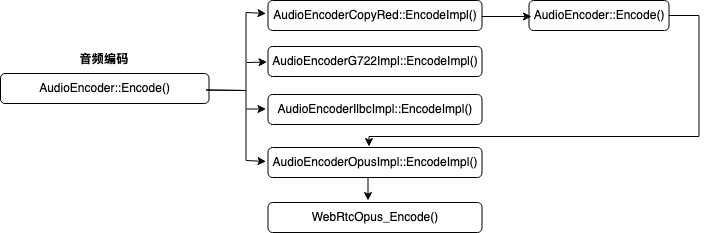
音频编码由AudioEncoder及其继承类完成,继承类包括:AudioEncoderG722Impl&AudioEncoderIlbcImpl&AudioEncoderOpusImpl,同时也包括AudioEncoderCopyRed。
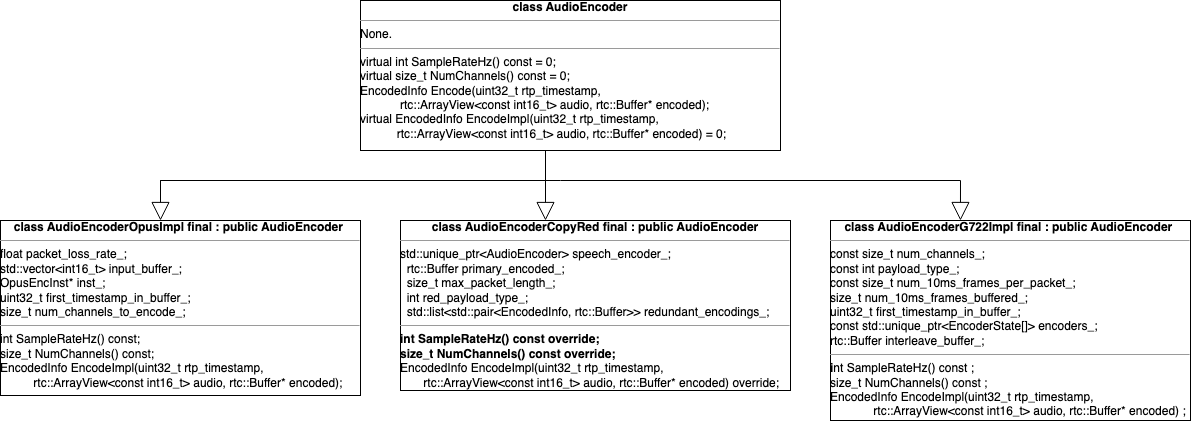
Red编码本质上属于网络层面的冗余编码,和G722/iLBC/Opus有本质不同,前者将编码后的数据做简单地复制,后者是将PCM原始音频数据做有损压缩编码;同时两者的调用流程也不一样。这里先不考虑RED,只关注音频的有损压缩编码。
AudioEncoder::EncodedInfo AudioEncoder::Encode(
uint32_t rtp_timestamp,
rtc::ArrayView<const int16_t> audio,
rtc::Buffer* encoded) {
...
EncodedInfo info = EncodeImpl(rtp_timestamp, audio, encoded);
...
return info;
}AudioEncoderG722Impl&AudioEncoderIlbcImpl&AudioEncoderOpusImpl都实现了EncodeImpl()虚函数,其中AudioEncoderOpusImpl::EncodeImpl()调用了WebRtcOpus_Encode(),在该函数内部实现了Opus编码,并在rtc::Buffer* encoded指向的内存块中存入编码后的数据。
AudioEncoder::EncodedInfo AudioEncoderOpusImpl::EncodeImpl(
uint32_t rtp_timestamp,
rtc::ArrayView<const int16_t> audio,
rtc::Buffer* encoded) {
MaybeUpdateUplinkBandwidth();
if (input_buffer_.empty())
first_timestamp_in_buffer_ = rtp_timestamp;
input_buffer_.insert(input_buffer_.end(), audio.cbegin(), audio.cend());
if (input_buffer_.size() <
(Num10msFramesPerPacket() * SamplesPer10msFrame())) {
return EncodedInfo();
}
const size_t max_encoded_bytes = SufficientOutputBufferSize();
EncodedInfo info;
info.encoded_bytes = encoded->AppendData(
max_encoded_bytes, [&](rtc::ArrayView<uint8_t> encoded) {
int status = WebRtcOpus_Encode(
inst_, &input_buffer_[0],
rtc::CheckedDivExact(input_buffer_.size(), config_.num_channels),
rtc::saturated_cast<int16_t>(max_encoded_bytes), encoded.data());
return static_cast<size_t>(status);
});
input_buffer_.clear()
...
return info;
}2.5. RED编码
在3.1章节给出的堆栈中,我们注意到进入音频编码环节时,WebRTC调用了AudioEncoder::Encode(),该函数会调用EncodeImpl(),这是一个纯虚函数,继承类AudioEncoderCopyRed实现了该函数。AudioEncoderCopyRed::EncodeImpl()通过调用真实的编码器AudioEncoderOpusImpl(或AudioEncoderG722Impl)实现对PCM数据的编码,还基于该编码数据实现了RED冗余。本章节讨论RED协议和编码。
2.5.1. RED的价值、实现原理及缺陷
2.5.1.1. RED的价值
在WebRTC中,RED(Redundant Encoding,冗余编码)是一种前向纠错(FEC, Forward Error Correction)技术,其核心作用是通过在音视频数据包中添加冗余信息,提升网络传输的可靠性和抗丢包能力。对于RED,我们关注两个核心技术点:
- 冗余数据保护:RED通过将编码后的音频报文与冗余数据包打包在一起,放在同一个RTP报文中。当网络丢包发生时,接收端可以利用冗余数据恢复丢失的原始数据,无需依赖重传机制(NACK)。
- 降低对重传的依赖:传统NACK机制需要接收端请求丢失数据的重传,但重传会引入额外延迟(尤其在高丢包率且高RTT的场景)。RED通过本地冗余数据恢复,避免了重传的延迟,适合对实时性要求高的场景(如语音通话、视频会议)。
2.5.1.2. RED的实现原理
WebRTC用一个冗余报文队列存储需要发送的Encoded Redundant Data,新来的冗余数据插入到该队列的头部,队列的长度等于设定的RED冗余度。当队列满的时候,要先将队列中已有元素全部向后移动一格,在淘汰掉最老的数据的同时腾出队列头部来存放新数据。
另一方面,RED报文会将Encoded Primary Data和Encoded Redundant Data放在一起作为RTP Payload发送,只要包括IP Header+UDP Header+RTP Header+RTP Payload小于UDP的MTU(WebRTC设置为1200)就可以。所以当Encoded Primary Data足够小的时候,可以将冗余报文队列中的所有数据和原始数据放在一个RTP报文中直接发送出去。我们就先讨论这种情况,我们假定RED冗余度为3。
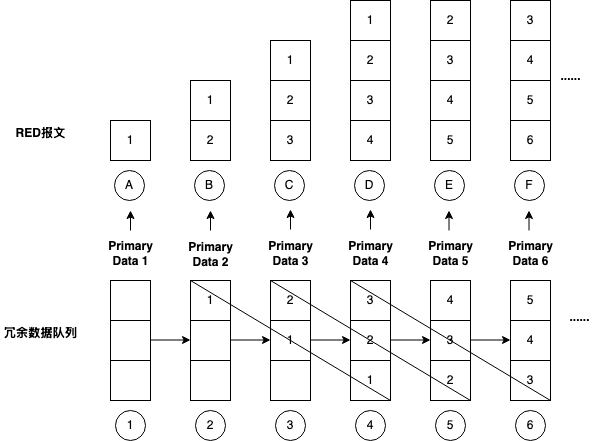
当冗余报文队列为空时,新来Primary Data 1,此时发送的RED报文中只有1,同时1被插入冗余队列头部;
新来Primary Data 2后,发送的RED报文中包含1和2,同时2被插入到冗余队列头部;
新来Primary Data 3后,发送的RED报文中包含1/2/3,同时3被插入到冗余队列头部;
新来Primary Data 4后,发送的RED报文中讨论1/2/3/4,同时1被淘汰出冗余队列,4插入到队列头部;
后续新来的Primary Data 5,6等,都会包含在RED报文中,且都会引起冗余队列的右移和淘汰机制。
每个Primary Data在刚插入到冗余队列时,位于队列头部,在被淘汰之前位于队列尾部,被送到RED报文中的次数有1+N次,N=RED冗余度。
当Primary Data很小的时候,以上逻辑成立。例如当我们将Opus的码率设置为16Kbps,同时将编码周期设置为20ms时,Primary Data=16*20/8=320/8=40字节,RTP Payload Length = RED Header Length*4+1+Primary Data Length + Redundant Data Length = 4*4+1+40+40*3=177, RTP Packet Size = IP Header Length + UDP Header Legnth+ RTP Header Length + RTP Payload Length = 10+8+12+177 = 207 < 1200。
当Primary Data很大的时候,以上逻辑可能就不成立了。例如当Opus的码率被设置为128Kbps时,20ms编码周期下的Primary Data = 128*20/8=320字节,此时RTP Payload Length = RED Header Length*4+1+Primary Data Length + Redundant Data Length = 4*4+1+320+320*3=1297 > 1200了。在这种情况下冗余队列中的3份冗余数据就无法一次存入同一个RTP报文了。此时虽然设定的冗余度是3,但实际上每份音频编码数据作为Redundant Data只发送了2次(还有一次是作为原始数据发送),具体行为如下图:
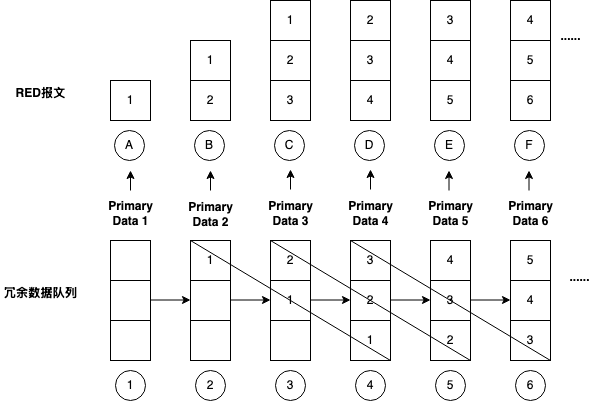
2.5.1.3. RED的缺陷
RED作为一种前向纠错机制,在冗余度的设置上只允许设为100%的整数倍,如1倍冗余、2倍冗余等。对比FEC可以设置30%、50%的冗余度,RED的冗余度显得非常的粗糙。而且,根据上述讨论,受限于WebRTC将冗余数据和原始数据放到同一个RTP报文的实际约束,填充报文时实际的冗余度可能要小于设定值。
RED的开启是通过SDP协商的,一旦协商通过后就会无条件开启,在任何时候都会按照相同的冗余度发送冗余数据,这一点又区别于FEC。FEC可以实时监测丢包率,根据丢包率大小选择开启或关闭FEC,还可以设置FEC的冗余度,所以FEC在效果上要远好于RED。在实际商用时,很多RTC厂商都会尝试修改该约束,让RED冗余度随着丢包率动态调整,以节约带宽(笔者曾在一家RTC厂商做商业推广,曾有语聊App的客户抱怨实际收费的带宽远高于设定的音频码率)。
最后,RED在实现原理上只是简单地将音频数据多次发送,不涉及复杂的数学运算。对比RSFEC,M个原始报文+N个冗余报文发送出去之后,只要收到的报文总数(包括原始报文和冗余报文)不小于M,就可以将M个原始报文全部恢复回来,丢包对抗能力远高于RED,原因就在于原始报文和冗余报文之间存在着数学约束(矩阵运算)。
2.5.2. SDP协商
在使用RED时,我们需要为RED指定一个动态的Payload Type,为此我们用到了SDP的协商机制,通过关键字rtpmap,我们为一种动态的Payload Type指定编码器类型、采样率和声道数。例如:
m=audio 12345 RTP/AVP 121 0 5
a=rtpmap:121 red/8000/1
a=fmtp:121 0/5以上SDP协商指定了当前Audio Stream使用的Payload Type包括121 (a dynamic payload type), 0 (PCM,脉冲编码调制) and 5 (DVI,自适应差分脉冲编码调制),rtpmap将121的Payload Type和RED绑定在一起,标识这种类型的报文为冗余报文(在RED报文的RTP Header的PT字段中设置)。fmtp则标识冗余报文首选的编码对象为PCM数据,其次为DVI数据(在RED Header的block PT中设置)。
2.5.3. RED协议
RED协议在RFC 2198(https://datatracker.ietf.org/doc/html/rfc2198)中定义,RED Header的格式如下:
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
|F| block PT | timestamp offset | block length |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+各字段含义如下:
F:标识后面是否还有新的头部,1表示还有新的头部,0表示这是最后一个头部。
block PT:标识RTP Payload Type,这个标识和RTP Header的PT字段不同,前者标识原始音频数据的Payload Type,如0和5(分别对应PCM和DVI),后者对于RED报文而言,就是SDP协商出来的RED对应的Payload Type(如上文中协商出来的121)。
timestamp offset:冗余数据相对于RTP Header中给出的时间戳的偏移量,是一个14bite的无符号整数。这就要求冗余数据必须晚于原始数据发出。
block length:冗余数据块的长度,不包括头部长度。
当F为0时,RED Header精简为只有F和block PT字段:
0 1 2 3 4 5 6 7
+-+-+-+-+-+-+-+-+
|0| block PT |
+-+-+-+-+-+-+-+-+以下是一个具体的实例,从这个实例我们看到:在报文长度允许的情况下,RED报文其实是将原始报文和冗余报文放在一个RTP Payload中的。如果原始报文超过了1200字节,则一个RED报文就只能存放原始报文或冗余报文了。
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
|V=2|P|X| CC=0 |M| PT | sequence number of primary |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| timestamp of primary encoding |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| synchronization source (SSRC) identifier |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
|1| block PT=121| timestamp offset | block length |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
|0| block PT=121| |
+-+-+-+-+-+-+-+-+ +
| encoded redundant data (PT=0) |
+ +
+ |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
| |
+ encoded primary data(PT=0) +
/ /
+ +
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+2.5.4. 代码解析
AudioEncoderCopyRed::EncodeImpl()是实际执行RED编码的函数,这个函数首先调用了一次AudioEncoder::Encode(),启动编码器(如Opus)对PCM数据进行编码,得到Primary Data,然后将redundant_encodings_中包含的所有冗余数据和primary_encoded_所包含的原始数据按照RED协议规范写入RTP Payload,再调整冗余数据队列,将primary_encoded_插入到redundant_encodings_指向的队列头部并淘汰队列尾部数据。
大家注意该函数第106~108行代码,音频编码后的原始数据被纳入冗余数据队列,由此可知该队列元素的payload_type就是真实编码时设置的Payload Type(例如PCM数据对应的Payload Type为0)。再看第70行代码,我们就可以知道RED Header的block PT其实就是真实编码时设置的Payload Type。
大家先看第99~113行代码,原始数据primary_encoded_在插入到冗余数据队列redundant_encodings_的头部之后,Payload Type被更新为red_payload_type_。所以我们回过头看第70~73行代码:
encoded->data()[header_offset] = it->first.payload_type | 0x80;
rtc::SetBE16(static_cast<uint8_t*>(encoded->data()) + header_offset + 1,
(timestamp_delta << 2) | (it->first.encoded_bytes >> 8));
encoded->data()[header_offset + 3] = it->first.encoded_bytes & 0xff;
可以看到,所有RED Header的F字段被设置为1,block PT被设置为red_payload_type_,同时还设置了timestamp offset和block length。
再看第92~93行代码:
encoded->AppendData(primary_encoded_);
encoded->data()[header_offset] = info.payload_type;
这段代码将原始报文追加到冗余数据的后面,共同作为RTP Payload的一部分。由于这是RED报文的最后一个Block,所以RED Header简化为1个字节且F字段为0(info.payload_type的最高比特位为0)。
AudioEncoder::EncodedInfo AudioEncoderCopyRed::EncodeImpl(
uint32_t rtp_timestamp,
rtc::ArrayView<const int16_t> audio,
rtc::Buffer* encoded) {
primary_encoded_.Clear();
/*call AudioEncoder::Encode()
*在编出RED报文之前,先对原始报文执行编码,编码后的内容存入primary_encoded_中
*/
EncodedInfo info =
speech_encoder_->Encode(rtp_timestamp, audio, &primary_encoded_);
if (info.encoded_bytes == 0 || info.encoded_bytes >= kRedMaxPacketSize/*1024*/) {
return info;
}
/*不管RED报文有几份,始终有一个Header标识这是最后一个RED Header*/
size_t header_length_bytes = kRedLastHeaderLength/*1*/;
/*计算在RED报文里面可以存放多少报文(一个原始报文+N个冗余报文),进而计算得到RED Header Length
*判断依据:1).总大小不能超过一个UDP报文的最大大小1200
* 2).每个冗余报文的时间戳和RTP Header中记录的时间戳的差值不能超过2^14
*/
size_t bytes_available = max_packet_length_ - info.encoded_bytes;
/*std::list<std::pair<EncodedInfo, rtc::Buffer>> redundant_encodings_;*/
auto it = redundant_encodings_.begin();
// Determine how much redundancy we can fit into our packet by
// iterating forward. This is determined both by the length as well
// as the timestamp difference. The latter can occur with opus DTX which
// has timestamp gaps of 400ms which exceeds REDs timestamp delta field size.
for (; it != redundant_encodings_.end(); it++) {
if (bytes_available < kRedHeaderLength/*4*/ + it->first.encoded_bytes) {
break;
}
if (it->first.encoded_bytes == 0) {/*如果冗余报文队列还未插满,则break*/
break;
}
if (rtp_timestamp - it->first.encoded_timestamp >= kRedMaxTimestampDelta/*2^14*/) {
/*red header的timestamp字段是14比特的无符号整形数,
*所以当前报文和原始报文之间的时间戳的差值不能超过2^14
*/
break;
}
bytes_available -= kRedHeaderLength/*4*/ + it->first.encoded_bytes;
header_length_bytes += kRedHeaderLength/*4*/;
}
// Allocate room for RFC 2198 header.
encoded->SetSize(header_length_bytes);
// Iterate backwards and append the data.
/*按RED协议将冗余报文存入RTP Payload中*/
/*RED协议格式(RFC 2198)
0 1 2 3
0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
|F| block PT | timestamp offset | block length |
+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
*/
size_t header_offset = 0;
while (it-- != redundant_encodings_.begin()) {
encoded->AppendData(it->second);
const uint32_t timestamp_delta =
info.encoded_timestamp - it->first.encoded_timestamp;
encoded->data()[header_offset] = it->first.payload_type | 0x80;
rtc::SetBE16(static_cast<uint8_t*>(encoded->data()) + header_offset + 1,
(timestamp_delta << 2) | (it->first.encoded_bytes >> 8));
encoded->data()[header_offset + 3] = it->first.encoded_bytes & 0xff;
header_offset += kRedHeaderLength/*4*/;
info.redundant.push_back(it->first);
}
// `info` will be implicitly cast to an EncodedInfoLeaf struct, effectively
// discarding the (empty) vector of redundant information. This is
// intentional.
if (header_length_bytes > kRedHeaderLength/*4*/) {
info.redundant.push_back(info);
}
/*将原始报文追加到RTP Payload中,由于这是RED报文的最后一个Block,
*所以RED Header简化为1个字节且F字段为0
0 1 2 3 4 5 6 7
+-+-+-+-+-+-+-+-+
|0| Block PT |
+-+-+-+-+-+-+-+-+
*/
encoded->AppendData(primary_encoded_);
encoded->data()[header_offset] = info.payload_type;
// Shift the redundant encodings.
/*将链表中的元素向后移动一格,淘汰掉最后一个冗余报文
*腾出链表头部并在头部存入原始报文作为新的冗余报文
*/
auto rit = redundant_encodings_.rbegin();
for (auto next = std::next(rit); next != redundant_encodings_.rend();
rit++, next = std::next(rit)) {
rit->first = next->first;
rit->second.SetData(next->second);
}
it = redundant_encodings_.begin();
if (it != redundant_encodings_.end()) {
it->first = info;
it->second.SetData(primary_encoded_);
}
// Update main EncodedInfo.
info.payload_type = red_payload_type_;
info.encoded_bytes = encoded->size();
return info;
}The End.

火山引擎开发者社区是火山引擎打造的AI技术生态平台,聚焦Agent与大模型开发,提供豆包系列模型(图像/视频/视觉)、智能分析与会话工具,并配套评测集、动手实验室及行业案例库。社区通过技术沙龙、挑战赛等活动促进开发者成长,新用户可领50万Tokens权益,助力构建智能应用。
更多推荐
 20
20 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)